
一种语音加密器中密钥同步方案的设计与实现
2014-08-07 12:09滕广超郎建军杜奇才林嘉宇
微处理机 2014年6期
滕广超,郎建军,杜奇才,林嘉宇
(1.国防科学技术大学电子科学与工程学院,长沙410073;2.武警黄金一总队通信科,哈尔滨150086;3.特种作战学院侦查系,广州510500)
一种语音加密器中密钥同步方案的设计与实现
滕广超1,2,郎建军2,杜奇才3,林嘉宇1
(1.国防科学技术大学电子科学与工程学院,长沙410073;2.武警黄金一总队通信科,哈尔滨150086;3.特种作战学院侦查系,广州510500)
通信技术飞速发展的同时,语音通信的安全性和保密性也面临着极大的威胁,为满足语音保密的需要,设计一种语音加密器。使用语音加密器的通信双方间必然要实现密钥交换,这里对语音加密器密钥同步的方法做一讨论。
语音加密;密钥同步;双音多频
1 引 言
当今时代,通信技术飞速发展,对信息进行窃取和保护的手段也随之不断进步。将加密技术应用在语音通信上,在语音信号传输前对其进行加密,使第三方无法获得语音中的信息,是一种非常有效、非常实用的保密方法。
到目前为止,语音加密方式分为语音模拟置乱、语音数字加密以及介于两者之间的模拟-数字-模拟加密方式三种。由于数字加密方式对传输信道的带宽需求高于普通模拟信道,而一般的模拟加密又存在剩余可懂度高、加密效果不强的缺点[1],故选用模数模加密方式。此外,模数模加密体制还因其具有实现设备简单、语音解密后音质好等优点,故其非常适用于构造语音加密器。
2 密钥同步模块的必要性及设计
2.1 密钥同步的必要性
考虑到语音的特性,加解密操作采用类似于流密码的加密体制。要设计一款好的加解密算法,首先需要从安全性角度考虑密钥流的周期性、随机统计性和不可预测性[2],以此为出发点来确定密钥流产生器的设计原则,使密钥流能够达到“一次一密”的标准。具体设计原则如下[3]:
(1)密钥流的周期要大。出于安全性考虑,为了更好地掩盖明文信息,密钥流的周期要尽可能大。
(2)密钥流的统计特性要好,应该达到理想的分布标准。
(3)密钥流的线性复杂度要大,这样会使密钥流线性不可预测。
(4)密钥流生成速度快。这样可以提高整个系统的效率,减轻硬件在计算上的压力,使整个系统方便、快捷、实用。
因为在对语音的加密过程中,密钥按一定规律进行更换,所以在解密时,对于每一帧语音,都需要使用与其加密时使用的加密密钥对应的解密密钥来进行解密。若使用的解密密钥与加密密钥不是相对应的,就无法正常解密。因此,为保证语音可以正常被恢复,语音帧和密钥必须存在一种同步关系,使语音信号和密钥在通信双方间都是对应的。
2.2 密钥同步设计
语音加密器采用的是模数模加密方式,通信双方之间在信道内传输的是模拟信号。而其所涉及到的初始密钥、随机数和同步信号等均为数字信号。为使接收方能够正常进行解密操作,发送方需将初始密钥、同步信号等数据通过模拟信道传输给接收方,可以使用DTMF方式来完成密钥同步。
在解密过程中更换密钥时,使用DTMF音来传输发送方的更换密钥时密钥的偏移量和用新密钥加密帧的起始位置,接收方收到DTMF音后,计算出密钥偏移量和其对应帧的位置,在解密操作时对相应的密文用相应的密钥解密,就实现了DTMF音的密钥同步作用。
DTMF(Dual-Tone Multi Frequency)[4],也称双音多频,是一种编码技术,其特点是用两个不同频率的正弦信号互相叠加来代表数字信号。DTMF具有音质稳定,较强的抗干扰能力,在绝大多数信道都能进行传送的优点。DTMF的特点使其能在通信系统的许多领域得到广泛应用,如电话语音服务、信息传送、远程控制等等。
在语音通信中出现规则的0101序列的概率较低,又因为1的能量高,方便判断,所以我们选用01101010来作为同步序列的实验样本。将同步序列中每个码元分为128×8=1024个点,其所代表的帧的时长为16ms×8=128ms,那么整个同步码字的时长为128ms×8=1024ms,可分为1024×8=8192个点。这样做的目的是为确定搜索子窗口的长度和个数,搜索子窗口的长度为128。
3 密钥同步实现
同步序列搜索工作的目的是寻找同步码字的起始位置,即“01”序列。然后判断其后6个码元,以此来确定是否为同步码字。其过程如下。
首先设定128个点为一个子窗口的长度,一个搜索窗口组由17个连续的子窗口组成,即每个搜索窗口组的时长为272ms。从DTMF音起始端开始检测,计算得出每一个子窗口的能量值,从而得出该从窗口的状态[6]。如果连续的17个子窗口组成的窗口组中,前8个至少有7个判定为0,后8个至少7个判定为 1,中间窗口不计,即搜索窗口组为00000000Z11111111,则判断这17个连续的子窗口覆盖了一个“01”序列。如果没有出现这种情况,则整个窗口组后移一个子窗口的长度,也就是128个点,继续判断。由于这种方法以128个样点为单位进行搜索,其精度不高,故称之为粗搜索。
这种搜索是以128个样点为单位进行的,精度不高,容易出现误判现象,进而影响定位。在试验中,还尝试以1个样点为单位进行搜索,具体做法是使Z子窗口以每次1个样点分别向左和向右移动64次,Z子窗口共移动128次,并计算每次移动后Z子窗口中128个样点的能量值,再计算出后64个样点与前64个样点能量值的比值,这样就得到128个比值。1码元的起始样点就是比值最大样点,也就是Z子窗口中的第64个样点。以样点为单位,用比值来进行判定,虽然提高了搜索精度,但也存在一定的问题。比如,若Z子窗口的左64个样点的能量值为0,就不能进行比值运算。故搜索方法还要改进。尝试使用相关法。相关法的具体思路是:对01序列完成粗搜索后,从1码元的首个子窗口中选出一个较为合适的片段作为模板X,再从Z子窗口开始与接下来要搜索的数据Y进行相关运算。所得的相关系数最大值的位置也就是X起始点的位置。相关系数r的计算公式为[6]。

确定了模板的起始位置和长度就确定了一个模板。如果将模板的长度确定为64个样点而不是一个子窗口的长度,就可以减少一半的运算量。

图1 相关系数主瓣与旁瓣比值图
从相关性的角度来看,模板起始点的位置较为适合选取为0样点。这是因为信号的边缘在幅度上具有不平稳性,对计算所得的相关系数进行绘图,可以看出,主瓣与最大旁瓣的比值较大,说明相关性能较好。但在实际情况下,却不能将模板的起始位置选在0样点。这是因为,相关计算不仅需要考虑相关性能,还要考虑到信号的抗噪性能。在信号的幅度值较大时,具有较好的抗噪性能。信号的起始阶段,其边缘是上升趋势,幅度值较小,这时易被噪音干扰。综合考虑抗噪和相关两方面的性能和因素,选取子窗口后64个样点作为模板,在这个区间中,幅度值较大的同时也满足了不平稳性要求。
通过确定模板的长度和起始位置,也就确定了模板,然后进行相关计算,得出相关系数值,如图2所示。

图2 归一化相关系数数值图
图中开始部分的直线为0值,这说明粗搜索的精度不高,在Z子窗口中有较多0码元样点值。从图中可以看出,相关系数法能够准确定位模板的开始位置,表明这个方法是可行的。同时,也出现了另一个问题,相关峰的主瓣前有若干个高度与主峰相差不大的旁瓣,使得判断时容易出现误判,鲁棒性不高。研究后发现,这是因为DTMF信号的周期性很强,同时,对码元的边缘加窗,故边缘为上升趋势。
主瓣之前有几个值较大的旁瓣时,若继续进行相关运算,那么得出的相关系数值的主瓣同样会呈现周期性,旁瓣的相关值差别也较小。这是因为,当模板确定后,对模板样点是固定的,而待搜索信号值yi越大,值越大,导致相关系数r被限制缩小的程度越大。也就是说,用公式(1)进行相关系数计算时,对小信号比较宽松,对大信号比较严格,所以主瓣前面几个旁瓣的相关值差别较小。
准确找到第一主瓣的位置是用相关法进行细同步的关键,要提高检查的鲁棒性,需要压制旁瓣。根据上述分析,去掉,得到公式

根据标准模板,采用公式(2)来进行相关运算,得到结果如图3所示。
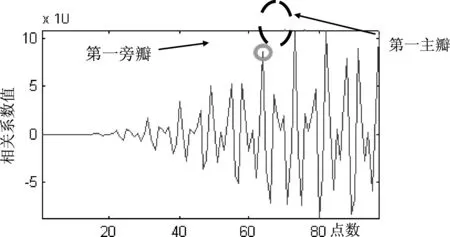
图3 优化后的相关计算值示意图
由图可得,第一主瓣前只剩一个较大旁瓣,此旁瓣值为8.582,第一主瓣的值为10.728,主瓣值比旁瓣值大出将近1/4,较大地提高了检测的鲁棒性,能够准确确定第一主瓣的位置。
相关计算法在精度和通用性上优于比值法,所以,在实验中,采用相关计算法。
搜索到“01”序列后,并不能断定这就是同步序列的起始位置,因为在整个DTMF音中“01”序列不止一个,还需要通过进一步分析才能判定。
同步判断中同样使用了子窗口。一个子窗口可以覆盖一个码元,也就是1024个点,8个紧邻的子窗口构成一个判断组,判断组长度正好覆盖一个同步序列。将判断组中首个窗口的结束位置与“01”序列中“1”的起始位置对齐,通过阈值得出这个判断组中8个子窗口的状态,并与01101010进行比对。如相同,则证实搜索到的信号是同步信号,否则继续寻找下一个“01”序列,再判断。
在进行同步信号搜索时,将所得的数据存储在硬件缓冲区中,搜素过程也在缓冲区中进行。同步序列的大小远远小于缓冲区空间,所以会出现三种影响判断的情况,需要分别处理。一是找到“01”序列后,硬件缓冲区的剩余空间不小于6bits,这时可以正常进行后续判断;二是找到“01”序列后,硬件缓冲区的剩余空间小于6bits,设为bits,此时无法进行判断,处理办法是将“01”和其后的bits写入一个新的缓冲区或寄存器,再将后续数据中的前bits填入新的缓冲区或寄存器的bits后面,在新缓冲区或寄存器中进行判断;三是在硬件缓冲区中没有搜索成功,但缓冲区的最后一位是“0”,这时可将“0”和后续数据的前7位写入新的缓冲区或寄存器,并在其中进行判断。
4 结束语
同步信号设计完成后,设计一个实验,将同步信号并入语音信号中进行传输,在传输过程中加入白噪声进行干扰,测试对同步信号的搜索和判断。实验采用五种样本:标准同步信号样本、错误同步信号样本、无同步信号样本、同步信号前存在数据样本、同步信号含有噪声样本(多种信噪比)。
经过实际测试,实验结果是:标准同步信号样本和同步信号前存在数据样本可以正常搜索到同步信号,不存在漏同步的情况,并且耗时较少;错误同步信号样本搜索不到同步信号,不存在假同步的情况,最后退出搜索;同步信号含有噪声样本能否搜索到同步信号与信噪比相关,大于-4db时能够搜索到,小于-4db时失败,表明本系统对同步信号的容错门限为-4db。通过一系列多样本的实际测试,说明这种同步方法是可行的。
[1]B Goldbug,S Sridharan,E Dawson.Cryptanalysis of frequeney domain analogue speech Scramblers[J].IEEE Proceedings-I.1993,140(4):235-239.
[2]Golomb SW.Shift Register Sequences[J].San Francisco:Holden-Day,1967.
[3]王育民,刘建伟.通信网的安全理论与技术[M].西安:西安电子科技大学出版社,1999.
[4]ITU.ITU-T recommendation Q.23 technical features of push-button telephone sets[S].[S.I.]:ITU,1988.
[5]周巍.基于智能手机的语音质量评估系统设计与实现[D].湖南:国防科学技术大学,2011.
[6]崔伟群.合成标准不确定度评定过程中相关系数的的数学和测量学意义[J].计量与测试技术,2011,38(9):53-55.
Design and Im plementation of A Key Voice Scrambler Synchronizationization
TENG Guang-chao1,2,LANG Jian-jun2,DU Qi-cai3,LIN Jia-yu1
(1.College of Electronic Science and Engineering,National Defense Technology University,Changsha 410073,China;2.Communications Department,Gold corps I,The Armed Police,Harbin 150086,China;3.Investigation Department of Special Operations School,Guangzhou 510500,China)
As the rapid development of communication technology,security and confidentiality of voice communications is facing a great threat.A voice encryption device is designed to meet the requirement of the voice confidentiality.The key exchange is conducted because of the voice encryption communication between the parties.The synchronizingmethod of the key to the voice encryption device is discussed.
Voice encryption;Key synchronization;DTMF
10.3969/j.issn.1002-2279.2014.06.010
TN918
:A
:1002-2279(2014)06-0030-03
滕广超(1984-),男,黑龙江鸡西市人,工程师,主研方向:电子信息与技术。
2014-04-03
猜你喜欢
湖北植保(2022年4期)2022-08-23
舰船科学技术(2022年11期)2022-07-15
土壤(2021年1期)2021-03-23
海军航空大学学报(2020年2期)2020-07-27
沈阳工业大学学报(2018年1期)2018-01-08
土壤学报(2017年5期)2017-11-01
电子技术与软件工程(2017年12期)2017-07-05
福建农业学报(2016年6期)2016-11-01
电测与仪表(2016年14期)2016-04-11
中国工程机械学报(2016年5期)2016-03-07
