
基于基因组合模式挖掘的辅助诊断专家系统
2014-08-05 02:40:44贾奇男宝媛媛贺建峰
计算机工程与应用 2014年24期
马 磊,贾奇男,张 俊,宝媛媛,贺建峰,李 龙
1.昆明理工大学 信息工程与自动化学院 生物医学工程系,昆明 650500
2.昆明理工大学 信息工程与自动化学院 计算机科学与技术系,昆明 650500
3.昆明理工大学 信息工程与自动化学院 自动化系,昆明 650500
基于基因组合模式挖掘的辅助诊断专家系统
马 磊1,贾奇男2,张 俊2,宝媛媛1,贺建峰1,李 龙3
1.昆明理工大学 信息工程与自动化学院 生物医学工程系,昆明 650500
2.昆明理工大学 信息工程与自动化学院 计算机科学与技术系,昆明 650500
3.昆明理工大学 信息工程与自动化学院 自动化系,昆明 650500
1 引言
专家系统是一种以人工智能技术为基础,结合某个特殊领域内的知识与经验,利用计算机实现模拟专家进行决策,或为使用者提供决策依据和参考的智能信息系统。医学领域中,Ledley在1966年首次提出了“计算机辅助诊断”CAID这一概念;1976年,斯坦福大学的Shortliffe等人设计了用于协助诊断细菌感染性疾病的医学专家系统MYCIN。在该系统取得较好的诊断效果的基础上,Shortliffe等人还建立了一套医学专家系统的设计开发理论[1]。随后,在1990年Umbaugh在人工智能技术的基础上,针对皮肤癌多样化色彩的问题,设计了皮肤癌辅助诊断系统[2]。在国内,学者蔡东联等人在2005年也针对糖尿病设计了专门的专家系统[3]。而余帅帅等人则在2011年设计了自身免疫疾病的辅助诊断系统[4]。
医学领域的诊断工作一般可归纳为联想、推断、判断这样的一个思维过程。为模拟这一思维过程,大多数诊断专家系统均是基于规则推导。利用规则推导的方式来实现一个医学辅助诊断系统的优点在于:规则推导方式符合医务工作者对于疾病诊断的思维习惯。然而,基于规则的专家系统也存在不足:如果医务工作者试图利用基因芯片技术从基因的角度去诊断某一种疾病,则辅助诊断专家系统设计将花费大量工作在已知规则的建立上。另一方面,某种疾病的诊断研究,其本质也是发现某种致病规则的过程。而基于规则推导的辅助诊断专家系统显然是不能满足这样的功能的。因此,要设计满足利用基因诊断技术,并且能够为诊断研究提供辅助指导的专家系统,需要跳出传统规则推导的思维方式。
随着机器学习理论与技术的发展,越来越多的科研工作者开始利用机器学习算法来设计开发医学领域的专家系统。2002年杜建凤等研究了模糊神经网络在专家系统中的运用[5]。同年,蔡航设计了一个基于神经网络的医疗诊断专家系统[6]。2004年,李丙春等将径向基函数网络扩展到医学图像领域,用于对医学图像的分类[7]。H.L.Chen等于2011年设计了基于粗糙集特征选择并结合支持向量机的专家系统,用于对乳腺癌的诊断[8],同年Ali Keleş等也基于模糊神经规则设计了用于乳腺癌诊断的专家系统[9]。
这些用于诊断的专家系统无疑都是成功的。但在实际使用过程中,医务工作者更多地是将诊断系统用于辅助最终结论的产生。而利用传统的分类算法构建的专家系统通常都是直接给出诊断结论,却不提供结论依据。因此,在以往理论工作的基础上,根据以前所设计的算法,将算法进行工程化应用,设计并实现了一种基于挖掘基因组合模式的辅助诊断专家系统。这一专家系统方案,既满足了给出诊断结果的要求,同时也能够给出诊断的依据供使用者参考,或以此为依据研究新的诊断规则。
2 关键算法
从机器学习的角度来看,诊断可以抽象为一个分类问题,即将多维特征映射到一维空间中[10]。然而,机器学习领域存在很多分类算法。理论上,只要符合基本条件,这些算法均可以直接用于诊断。但是,考虑到医务从业者的思维习惯,分类算法必须能够提供分类依据,从而让使用者接受(或否定)辅助诊断结果,或发现新的规则模式以启示使用者发现新的诊断规则。因此,基于以往的工作设计了新的分类方法用以解决这一问题。
2.1 MORE算法—一种Apriori算法的改进
以肿瘤基因为例,在基因表达信息数据中,用规则或模式来定义一系列特征基因的组合,风险模式指的是与肿瘤产生具有相关性的模式;相应的,预防模式则指与肿瘤的产生不具有相关性的模式。通常,人们可以利用Apriori[11]算法或FP-growth[12]等算法来挖掘风险与预防模式。然而,由于基因表达数据的特殊性,直接利用传统的关联规则算法会产生大量的时间开销。针对这一情况李久勇等人对Apriori算法进行了改进并用于挖掘风险模式与预防模式[13]。以挖掘风险模式为例,首先引入局部支持度(local support,lsupp)代替全局支持度(support)来判断一个规则或模式是否为频繁的,其定义如下:
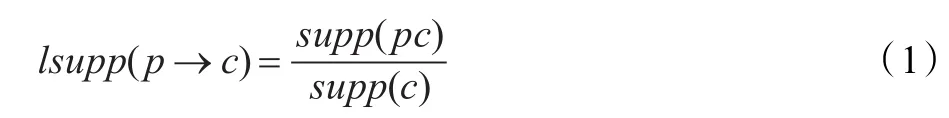
其中 pc是 p∧c的缩写,该规则为,如果一个模式的局部支持度大于给定的阈值,则这个模式是一个频繁模式。当确定一个模式是频繁模式之后,则需要确定该模式为风险模式的置信度。与传统的置信度指标不同,在MORE算法中以相对风险值作为置信度指标。
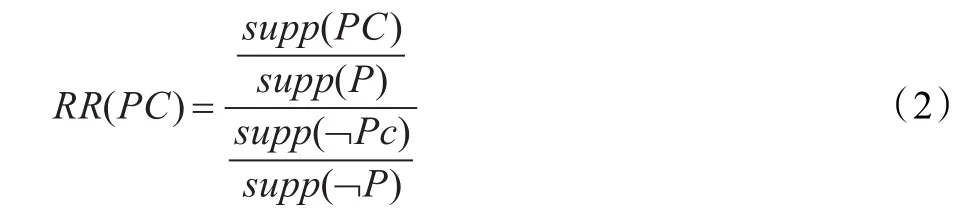
可以采用相对风险值对风险或预防模式进行定义。
定义1风险模式是频繁项集中的元素,相对风险值高于给定阈值;而预防模式也是频繁项集中的元素,其相对风险值小于给定阈值。
然而数据挖掘中的风险和预防模式会带来许多冗余的模式,这不利于观察结果。在获得风险模式与预防模式之后,利用模式的相对风险值排序等步骤,即可获得最优风险模式与预防模式。而最优风险模式和预防模式能够被挖掘的原因,也是由于所使用的局部支持度作为规则滤除阈值能够满足反单调性原则。
2.2 最优风险与预防模式赋权算法ORPWS
张俊鹏等人在MORE算法的启发下,针对挖掘最优风险模式和预防模式中可能出现特征交叉的问题,在MORE算法的基础上提出了ORPSW算法[14]。该算法基于MORE算法所挖掘出的典型风险集与典型预防集,计算出两个集合的期望阈值,而后计算出单个特征基因在所在集合中的经验分布概率并降序排序。设置模式探查长度L形成新的风险集与预防集。统计两个集合中单阶特征基因在总量为L的所属集合中的经验分布概率,按照其经验分布概率进行降序排列。根据所设定的概率阈值,从两个集合中滤去低概率基因,从而生成最优风险与预防集。相应的,基因所对应的经验分布概率值乘以基值100即为其所在集合中的权重。
定义2如果一个特征基因是一个在局部支持度条件下生成的风险或预防集中的元素,而它的经验分布概率大于等于期望阈值,那么它就属于最优风险或最优预防集。
通过积累的样本,利用ORPWS算法获得最优风险集与最优预防集,以及集合中模式的权重后,即完成了对风险预防模型的训练。对于新的待预测受试者样本,只需要根据模型计算出其所包含的特征基因的风险概率和预防概率。通过概率值的大小比较即可得出该受试者属于患病风险人群(风险概率大于预防概率)还是需要预防人群(预防概率大于风险概率),或是需要留院观察(风险概率等于预防概率)。
挖掘风险和预防集比挖掘最优风险和预防模式更加有效,原因之一在于只关心特征基因本身而不关心它们的组合。第二个原因是可以通过计算每个特征基因的频率,来了解每个特征基因的权重,从而可以确定每个特征基因对肿瘤的影响程度。
3 系统的实现与系统工作原理
3.1 系统的整体结构
目前实际上医疗机构的大部分系统均运行在其内部网络环境中。本文所提及的专家系统应作为医疗机构整体系统中的一个子系统。基于此,本文给出了辅助诊断专家系统的一种实现方案。图1是辅助诊断专家系统(100)的设计方案框图。
系统可以直接通过系统总线对本地肿瘤基因数据源(108)进行访问,本地肿瘤基因数据源为目前广泛使用的基因表达结构化数据文件。同时,可以通过网络接口(110)对远程肿瘤基因数据源(112)进行访问。
系统中数据清洗工具(122)对数据源进行清洗,涉及从数据中检测和去除错误及不一致的数据部分以改善数据质量,并且将数据源重新组织为挖掘过程中所使用的特殊格式文件。特征预处理(124)包括基于熵的离散化功能模块和基于CFS的特征提取功能模块,用于对数据进行特征基因提取。应用程序(120)同时也包括数据挖掘算法和从结构化数据源中挖掘最优风险模式(134)、最优预防模式(136)、最优风险权重集(140)和最优预防权重集(142)的算法程序。
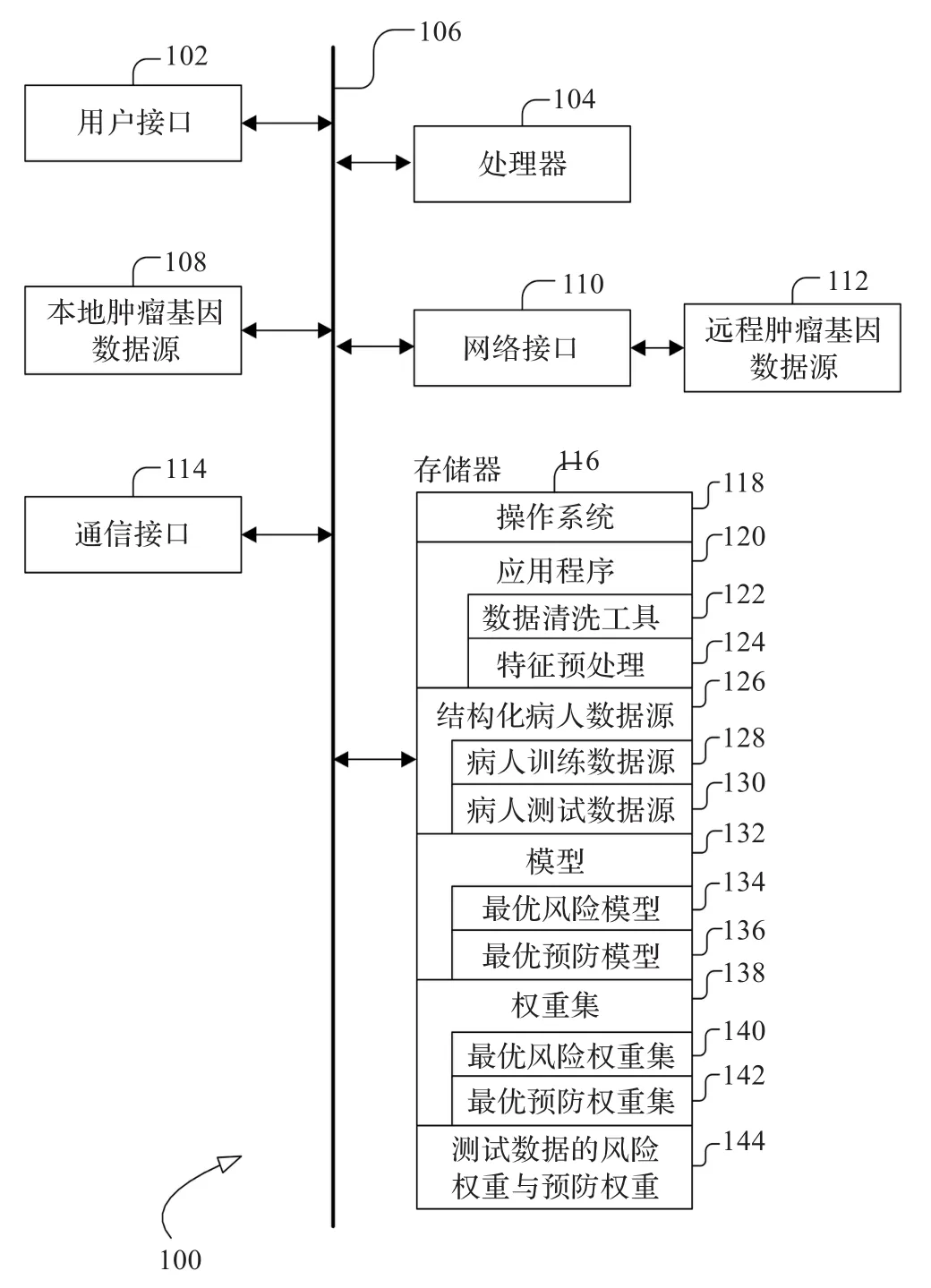
图1 诊断系统框架
另外,存储器(116)存储经过数据清洗后的结构化病人数据源(126),结构化病人数据源包括病人训练数据源(128)和病人测试数据源(130)。病人训练数据源(128)经过训练可以产生模型(132)存储在存储器中,这些模型有最优风险模式(134)和最优预防模式(136)。对模型进行约束和汇集,进而产生权重集(138)。权重集(138)分为最优风险权重集(140)和最优预防权重集(142)。利用所得到的权重集对病人测试数据源(130)进行打分,得到测试数据的风险权重和预防权重(144)。
3.2 诊断工作原理
图2是用于挖掘有用的肿瘤基因信息和对病人状况进行诊断的基本流程框架。该框架包括训练阶段(200)和测试阶段(204)。在训练阶段中,病人训练数据源(128)通过基于最小熵的离散处理和CFS特征基因提取(202)提取出与疾病有关的离散风险特征和预防特征。得到的离散特征基因通过数据挖掘算法挖掘出最优风险模式(134)和最优预防模式(136),又通过统计分析,得到最优风险权重集(140)和最优预防权重集(142)。在测试阶段(204),利用得到的最优风险和预防权重集,对病人测试数据源(130)进行权重打分,产生风险权重(206)和预防权重(208)。利用权重比较(210),来诊断病人患病的症状,如果风险权重显著大于预防权重,则症状判断为“患病”(212);如果风险权重与预防权重差异不大,则症状判断为“继续观察”(214);如果风险权重显著小于预防权重,则症状判断为“正常”(216)。训练阶段(200)负责从病人训练数据源(128)中提取模型,并将这些模型转化为权重集。所挖掘的模型分为风险模式和预防模式,风险模式为风险因子组成的模型,而预防模式为预防因子组成的模型。所转化的权重集是风险或预防因子导致患病和不患病的权重集合。测试阶段(204)负责将病人测试数据源(130)进行权重打分,比较患病的风险权重和不患病的预防权重,进而推断病人的状况。
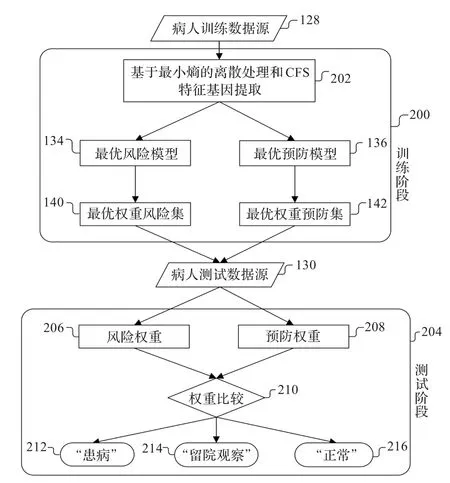
图2 诊断流程
4 实验验证
实验部分,以甲状腺肿瘤数据为例[15],展示专家系统的工作细节以及如何做出辅助诊断。
4.1 训练诊断模型
做出诊断前需要首先训练诊断模型。模型训练模块在系统的后台中,只需要将积累的样本数据上传至服务器,并告知系统管理员即可由系统管理员进行对应操作,即可完成模型的训练。图3所反映的即为训练数据源上传的管理页面。
图3 上传训练数据
在完成数据上传之后,就可以开始训练诊断模型。根据ORPWS算法的原理,此处需要设置两个参数用于模型的训练,它们分别是最小局部支持度与模式探寻长度L,如图4所示。
系统管理员可以根据要求,设置对应的参数。之后点击上传,模型就会在后台自动训练,这个过程对于系统管理员而言是透明的。训练完的模型会出现在上传管理页面中,图3中标记部分即为所训练出的模型。
4.2 利用训练出的模型进行辅助诊断
在模型训练完成之后,医生便可连入服务器对受试者样本进行诊断。只需将本地待诊断样本数据上传至服务器,点击对应的诊断按钮,系统将会自动跳转到对应的诊断结果页面。从训练样本数据源中抽取出一个确诊患有甲状腺癌的患者作为测试样本,通过辅助诊断系统得到了辅助诊断结果,如图5所示。诊断结果为多条记录。每一条记录对应一个模式,包含有以下几个信息:
(1)结果:该模式的类型,即风险或预防。
(2)模式长度:该模式的长度,即包含有几个特征基因。
(3)率比值:该模式的率比值指标。
(4)相对风险:该模式的相对风险值。
(5)致病因子:具体的模式内容。
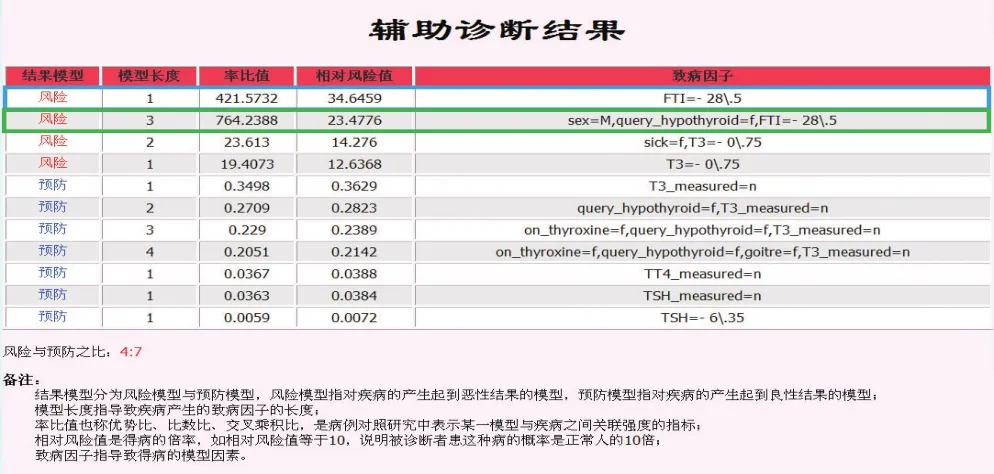
图5 诊断结果展示
可以通过计算风险模式的权重之和与预防模式的权重之和,来比较大小,从而得到受试者目前属于甲状腺癌风险人群或是预防人群,或是其他状态。
例如在本例中,可以计算该受试者的风险与预防权重:
(1)风险权重=34.645 9+23.446+14.276+12.636 8= 85.004 7
(2)预防权重=0.362 9+0.282 3+0.238 9+0.214 2+ 0.038 8+0.038 4+0.007 2=1.182 7
从权重来看,此受试者应当为风险人群。注意到,图5第一条记录中,包含有FTI=-28.5这一模式。该模式是传统诊断中用于判断甲状腺癌的一个指标。而通过辅助诊断系统,发现该模式还可以与其他模式相关联,所产生的模式也是高相对风险模式。如图5的第二条记录中,看到该模式与另外两个模式相结合,产生了一个长度为3的新模式。如果医生对于这样的新模式感兴趣,可以在未来的诊断或者研究中对其进一步探索和总结,如果从医学领域角度可证实该模式确系与甲状腺癌的发生有相关性,则可以将这一模式归入传统诊断方法的规则中,为未来的诊断提供参考依据。
5 结论与展望
本文描述了一种基于基因信息的辅助诊断专家系统。该系统是之前所提出的ORPWS分类算法的一个具体工程实践。系统克服了传统基于规则推断的诊断系统的不足,同时也弥补了其他基于分类器的诊断系统不利于发现规则的劣势。在一定程度上能够同时兼顾医务工作者的日常辅助诊断和对诊断学科研的需求。
下一步的主要工作将涉及两个方面:
(1)对算法进行改进。由于需要考虑到传统诊断中医务工作者更习惯于规则的推导,因此本文算法也是在关联规则分析的基础上进行分类的。然而,由于关联规则分析要求样本均为离散性特征,这样就导致了不得不在数据预处理阶段进行离散化处理。未来将研究如何将这种基于关联规则的诊断方法扩展到连续性特征数据上。同时,也需要从贝叶斯统计理论体系的角度对ORPWS算法进行改进,使其更加具备统计学的理论支撑。
(2)对专家系统的工程化应用及改进。目前的专家系统还只是一个雏形,虽然这个系统基本上能够实现辅助诊断的要求,但依旧有很大改进的空间。后续需要对其进行优化或局部重新设计,使得该系统使用更加便捷和完善。
致谢 本文作者感谢澳大利亚南澳大学李久勇教授的无私帮助与支持。
[1]Shortliffe E H.Computer-based medical consultations,MYCIN[M].[S.l.]:Elsevier Publishing Company,1976.
[2]Umbaugh,Scott E.Automatic color segmentation of images with application to detection of variegated coloring in skin tumors[J].Engineering in Medicine and Biology Magazine,1989,8(4):43-50.
[3]蔡东联,罗狄隐,耿珊珊,等.糖尿病治疗专家系统研制和应用[J].中国临床营养杂志,2005,13(5):289-293.
[4]余帅帅,叶云程,曾碧新.自身免疫疾病辅助诊断专家系统[J].计算机应用与软件,2011,28(1):89-91.
[5]杜建凤,宋梅,张璋,等.模糊神经网络在决策专家系统中的研究与应用[J].系统工程与电子技术,2002,24(2):45-47.
[6]蔡航.基于神经网络的医疗诊断专家系统[J].数理医药学杂志,2002,15(4):294-295.
[7]李丙春,耿国华,周明全,等.一个医学图像分类器的设计[J].计算机工程与应用,2004,40(17):230-232.
[8]Chen H L,Yang B,Liu J,et al.A support vector machine classifier with rough set-based feature selection for breast cancer diagnosis[J].Expert Systems with Applications,2011,38(7):9014-9022.
[9]Keleş A,Yavuz U.Expert system based on neuro-fuzzy rules for diagnosis breast cancer[J].Expert Systems with Applications,2011,38(5):5719-5726.
[10]Kononenko I.Machine learning for medical diagnosis:history,state of the art and perspective[J].Artificial Intelligence in Medicine,2001,23(1):89-109.
[11]Agrawal R,Mannila H,Srikant R,et al.Fast discovery of association rules[J].Advances in Knowledge Discovery and Data Mining,1996,12:307-328.
[12]Han J,Pei J,Yin Y.Mining frequent patterns without candidate generation[J].ACM SIGMOD Record,2000,29(2):1-12.
[13]Li J Y,Fu A W,Fahey P.Efficient discovery of risk patterns in medical data[J].Artificial Intelligence in Medicine,2009,45(1):77-89.
[14]张俊鹏,贺建峰,马磊.基于最优风险与预防模型的医疗数据挖掘算法[J].计算机工程,2011,37(22):32-34.
[15]Li J Y,Fu A W,He H,et al.Mining risk patterns in medical data[C]//Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD),2005:770-775.
MA Lei1,JIA Qinan2,ZHANG Jun2,BAO Yuanyuan1,HE Jianfeng1,LI Long3
1.Department of Biomedical Engineering,School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China
2.Department of Computer Science and Technology,School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China
3.Department of Automation,School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China
The development of effective nucleic acid analysis such as gene chip technology in the medical field makes clinical diagnosis and medical research be able to apply it to acquire a large number of genetic information of tumor genesis. Meanwhile,with the progress and application of machine learning theory and technology recently,plenty of expert systems based on artificial intelligence technology have occurred in various fields.Aiming to the characteristics of the analyzed gene information,this paper proposes the methods and implementation of a tumor auxiliary diagnostic expert system,and discusses the key techniques of data mining on the system implementation process.It also describes the structural framework, working mechanism and auxiliary diagnosis principle of the system.The experiment releases the test results by using clinical medical data,and the result indicates that system implementation discussed herein can meet the requirement of an auxiliary diagnosis in certain extent.
genetic data mining;association rules;classification;auxiliary diagnosis;expert system
在医疗领域中,基因芯片技术等高效核酸分析手段不断发展,使得临床诊断与医学研究中能够利用这一技术获取大量与肿瘤生成相关的基因信息。同时,近年来随着机器学习理论与技术的不断发展与应用,在各领域内出现了大量基于人工智能技术的专家系统。针对基因芯片信息的特点,描述了一种肿瘤辅助诊断专家系统的设计思路与实现方案;讨论了在专家系统实现过程中所采用的关键数据挖掘技术;重点叙述了系统的结构框架、工作机制与辅助诊断原理。在实验中,展示了临床获得的医疗数据在所论述系统中的测试结果。实验结果表明所论述的系统实现方案能够在一定程度上满足辅助诊断的需求。
基因数据挖掘;关联规则;分类;辅助诊断;专家系统
A
TP311
10.3778/j.issn.1002-8331.1305-0155
MA Lei,JIA Qinan,ZHANG Jun,et al.Study of auxiliary diagnostic expert system based on combined genetic patterns mining.Computer Engineering and Applications,2014,50(24):122-126.
国家自然科学基金(No.11265007);云南省基础应用研究基金(No.2009Zc049M)。
马磊(1978—),通讯作者,男,讲师,研究领域为生物信息学,数据挖掘,软件工程;贾奇男(1986—),男,在读硕士研究生,研究领域为数据挖掘,机器学习;张俊(1990—),男,在读硕士研究生,研究领域为数据挖掘,机器学习。E-mail:roy_murray@qq.com
2013-05-14
2013-06-30
1002-8331(2014)24-0122-05
CNKI网络优先出版:2013-09-12,http∶//www.cnki.net/kcms/detail/11.2127.TP.20130912.1433.010.html
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18 05:34:24
发明与创新(2021年39期)2021-11-05 07:15:28
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
计算机与生活(2018年3期)2018-03-12 08:38:11
电信科学(2017年6期)2017-07-01 15:44:57
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
材料科学与工程学报(2016年1期)2017-01-15 13:33:48
汽车文摘(2015年11期)2015-12-02 03:02:53
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
