
云计算中基于随机游走的数据查询方法研究
2014-07-24 15:29刘淑英
微型电脑应用 2014年9期
刘淑英
云计算中基于随机游走的数据查询方法研究
刘淑英
针对数字图书馆应用服务中的数据查询问题,提出了一种基于云计算的数据查询方法。首先,基于Random Walk方法找到查询请求的目标节点,然后,通过定义服务节点的相似节点集和等价节点集来进行二次搜索,返回具有最大评价值和最低负载的节点和数据作为所需的目标节点及数据。实验结果表明,在查询的数据质量、服务节点的负载能力以及查询的效率方法都优于传统的方法。
云计算;数字图书馆;Random Walk;数据查询;相似节点集;等价节点集
0 引言
云计算(Cloud Computing)[1]是近年来新兴的信息技术之一,它将能更好地使用计算资源,更智能地进行大规模的数据处理。基于高效的虚拟计算资源,应用程序能以一种灵活且安全的方式实现快速扩展和缩减.从而交付高品质服务。在面向用户的数字图书应用中,如何利用现有的图书馆资源,为读者或用户提供更快捷、更便利的图书数据查询服务是目前数字化图书馆建设中必须要考虑的问题,而云计算技术由于其高可靠性、通用性、高可扩展性、按需服务以及及其廉价的特点,使它成为解决数字图书馆中高效数据查询服务的一种有效手段,它能够极大的降低数字图书馆建设成本,实现图书馆资源的有效共享。因此,本文基于云计算技术,主要研究数字图书馆中的数据查询策略,从而为读者提供更为高效、可靠的服务。
1 相关工作
云计算及其应用研究是目前的热点问题,相继有众多的学者提出了一系列的面向数据应用的方法,如郑湃等[2]针对数据密集型应用中面临的时间开销较高、数据依赖性强以及无法有效实现全局的负载均衡等问题,文中在充分考虑了数据本身特性和网络因素的基础上,提出了一种有效的数据布局策略。实验结果表明该策略要优于已有的方法,能显著地降低数据传输的时间开销,然而文中基于遗传算法进行数据布局的实现过程比较复杂,且不能很好的解决大规模计算量问题;田冠华等[3]研究了动态资源的可靠性问题,提出了一种基于失效规律的策略来保证动态提供的节点资源的可靠性。实验结果表明该策略可以屏蔽掉大量节点资源的失效,与不考虑资源失效规律的策略相比,文中策略能够提供更高的可靠性。葛君伟等[4]针对云计算环境中现有的资源监测方法的不足,提出一种改进的资源监测模型,它通过虚拟机监测器和Java调用C/C++得到资源的状态信息。实验结果表明该模型能够有效获取资源监测信息;Rankova等人[5]提出了一种匿名数据搜索引擎,可以使得交互双方搜索对方的数据,获取自己所需要的部分,同时保证搜索询问的内容不被对方所知,搜索时与请求不相关的内容不会被获取。另外还有文献[6-11]探讨了云计算技术在数字图书馆建设方面的优势和挑战,并提出了应对挑战的一系列措施和方法,为进一步推动云计算技术的应用指明了方向。借鉴前人的工作,本文基于云计算技术,研究了数字图书馆中的数据查询服务,提出了一种改进的数据查询方法。模拟实验结果表明,本文提出的数据查询方法在数据查询质量和效率方面都能获得预期效果,满足用户对于数字图书馆搜索服务的目标。
2 问题描述与建模
2.1 相关定义
以数字图书馆中的图书搜索服务作为研究对象,假定云计算环境中提供数据的服务节点数为n,所有节点基于Internet构成一个无中心、非结构化的覆盖网络:令节点si上的数据对象集合用表示,数据对象的数目为对于S中的任意节点s,用Neighbor( s)表示节点s的邻节点,其获取、更新方法与P2P网络中节点的探测、感知相同。为了描述方便,下面给出几个相关定义:
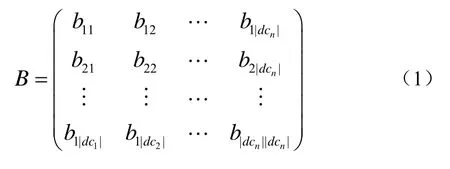
定义1 云计算环境(CC)可以表示为多个分布式数据中心组成的集合其中dci表示第i个数据中心,CC中各数据中心间网络带宽可以表示为[2]公式(1):
定义2 以图书数据为例,不失一般性,假定其中的数据是同构的。设每个数据对象包含m个属性,则可定义描述数据对象的元数据为:

其中Ei是包含iχ个属性成员的集合:。因此,每个数据对象可用一个m元组表示为公式(2):
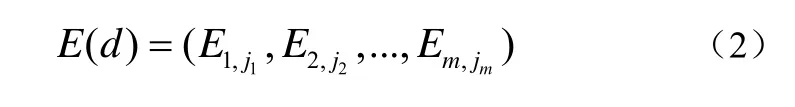
定义3 相似节点(SN, Similarity Nodes)。对于任意的两个不相同的数据对象x和y,当且仅当它们满足以下两条规则时,则认为它们互为相似节点。
规则1:x和y在它们的属性Ei上有相同的属性值ni;
规则2:x和y的属性间的相似度大于某一规定阈值;
对于满足以上规则的x和y,设x和y所在的服务节点为p和q,则两节点间的相似关系可以表示为公式(3):
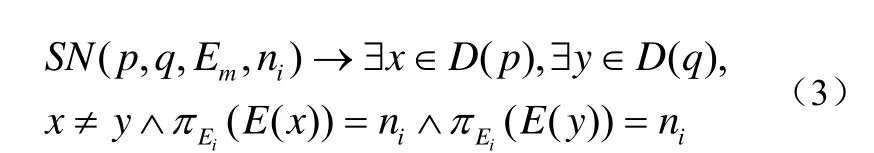
定义4 相似节点集(SNS, Similarity Nodes Set)。对于任意一个服务节点x的相似节点集是这样的一个节点集合:集合中的每个成员节点都与节点x是相似关系为公式(4):

在面向数字图书馆数据查询服务的云计算环境中,处于同一个SNS中的资源服务节点有更大的概率被同一搜索请求访问,以便返回更高质量的目标数据。为此,需要为每个节点的SNS附加上质量评价信息,我们用Q(x,t)表示在一段时间t内数据对象x的查询者对该数据质量的评价(如某一次查询服务中用户对该服务质量的评价)如公式(5):
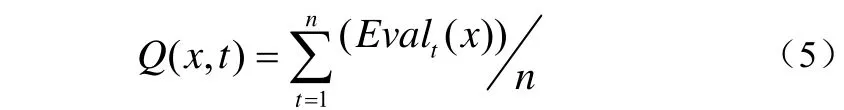
定义5 等价节点(ENy,Equivalent Nodes)对于任意的两个相同的数据对象x和,如果分别位于不同的服务节点p和q上,则称p和q互为x和y的等价节点。可以表示为公式(6):
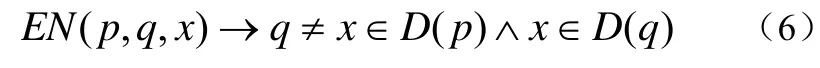
定义6 等价节点集(ENS, Equivalent Nodes Set) 对于任意一个服务节点x的等价节点集是这样的一个节点集合:集合中的每个成员节点都与节点x是等价关系为公式(7):

在面向数字图书馆数据查询服务的云计算环境中,某个数据对象的等价节点集(ENS)中的所有节点能够为发起查询请求的用户提供相同的数据(比如图书馆藏信息)。为此,在每个节点的ENS附加上负载信息[12],包括负载能力、实际负载等,用描述最近某段时间t内对节点p上的数据对象x的请求次数,Capacity(p,t))表示节点p的负载能力,它可以表示为公式(8):
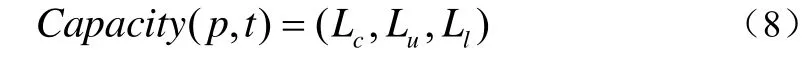
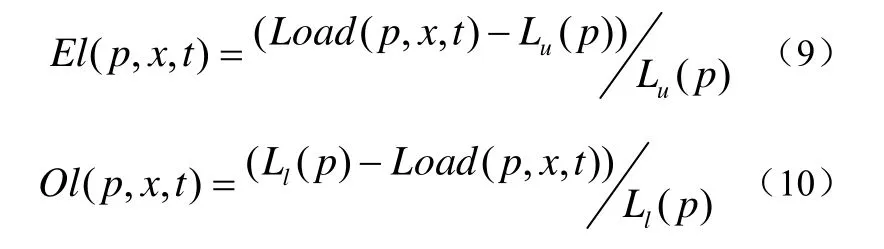
联立公式(8-10),包含了负载信息的等价节点集可以定义为公式(11):
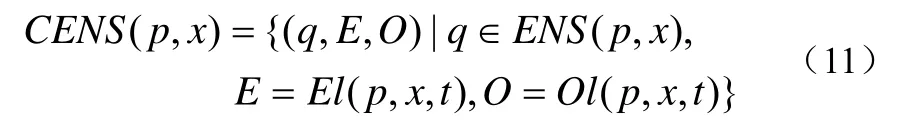
2.2 节点状态的更新
在面向数字图书馆应用的云计算环境中,每个服务节点的状态并非固定不变的,而是一个逐渐更新、优化的过程。为了得到更好的查询数据质量,需要对节点的状态进行更新,下面分别给出了相似节点集(SNS)和等价节点集(ENS)的更新算法。
算法1 SNS 更新算法
输入:当前节点p,更新周期t
输出:p的SNS
Step1. 遍历邻节点集合,搜索到当前服务节点p的相似节点集合,记为SNS( p);
Step3. 迭代执行Step2,直到SNS( p)中的每一个节点都处理完毕。
算法1基于当前节点的邻节点集合,因此并不需要在构成云计算环境(CC)的服务节点之间进行额外的消息传播[13],影响其时间复杂性的因素还有相似节点集的最大容量、图书数据的属性及其取值规模,在现实应用中这些数据都有较小上界并相对稳定。
算法2 ENS 更新算法
输入:当前节点p,更新周期t
输出:p的ENS
Step1. 对当前服务节点p上数据对象x的负载情况和负载能力进行评价,根据公式(11)可得CENS( p, x);
算法2的更新过程由各服务节点的请求负载超载或欠载事件触发,以便数据对象能够及时地在节点之间重新分配,达到使未来负载趋于平衡的目标。
3 基于节点状态的数据查询
基于2.1节给出的相关定义和2.2节给出的节点状态更新方法,本文提出了一种基于节点状态的数据查询策略。它的基本思想是:首先,对于一般意义的邻节点使用随机游走[14]方法,尽快定位到符合查询的目标节点;然后,基于目标节点的相似节点集,继续搜索到一个具有更好质量评价的目标节点;最后,基于新的目标节点的等价节点集,返回其中具有最小请求负载的服务节点,作为整个搜索服务的结果。
算法3 基于节点状态的数据查询算法
输入:查询请求qreq,查询开始节点p
输出:目标节点和目标数据
Step1. 对于任意节点q发送的查询请求q_qreq,如果节点p上存在能满足q_qreq的数据x(记为,q_qreq=x),则p即为q的目标节点,转Step3,否则转Step2;
Step3. 遍历节点q的相似节点集SNS( q, E, n),得到满足q_qreq的、具有最大Q( q, t)的节点β及其数据对象δ;
Step4. 遍历节点β的等价节点集ENS(β, δ),得到具有最小负载的节点及其数据对象,返回该目标节点和数据对象,算法结束。
从算法3中可以看到,它的效率主要取决于Step2的Random Walk方法。算法3的Step1和Step2的目标是获得一个满足查询请求的数据副本,然后在Step3和Step4分别基于相似节点集和等价节点集在数据质量、负载方面对查询结果进行优化,最终返回更好的服务节点和数据对象。而Step3和Step4时间复杂度为常数,这是因为在SNS 更新算法和ENS 更新算法中,对相似节点集和等价节点集中的节点分别按评价质量和负载进行了有序组织或建立索引。
4 实验结果与分析
在模拟实验中,我们使用进程实例模拟数字图书馆云计算环境中的服务节点,这样,可以在少数主机上执行大量Java进程模拟图书馆查询服务云环境;类似的,很多发出不同搜索请求的云用户通过随机创建的客户线程模拟。实验环境为Inter(R)Core(TM)2 Duo 2.93GHz,RAM 2GB,硬盘160GB,100MB网络带宽。基于此模拟实验环境,我们主要从查询服务返回结果的质量、负载和搜索路径等方面进行了相关实验,并与P2P中的Random Walk方法进行了比较,在每个实验中,不少于100个模拟云用户的线程发出搜索请求并通过日志对返回结果进行记录,每个搜索请求对目标数据在各属性上的限制是随机产生的。
查询目标数据的质量比较,如图1所示:
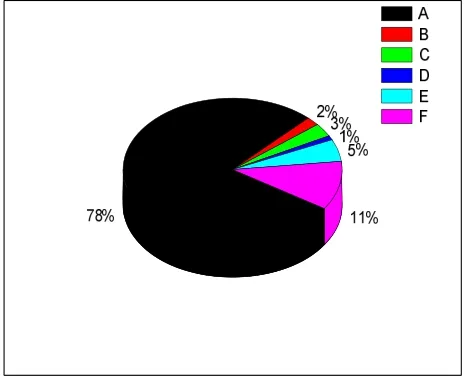
图1 不同查询方法的目标数据质量比较
从图1可以看到,本文提出的查询算法得到的目标数据的质量要好于Random Walk方法。而且随着服务节点数目的增加,本文方法对于提高查询质量的作用更为明显。这主要是因为本文方法定义了节点的相似节点集(SNS)和等价节点集(ENS),每次查询首先找到满足查询请求的目标节点,然后,分别从SNS和ENS出发找到具有最大Q值的数据,因此,得到的数据质量较好。
如图2所示:
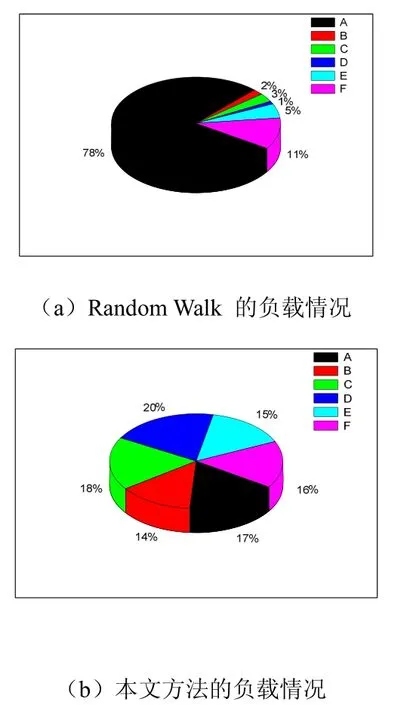
图2 不同方法的负载情况比较
图2(a)和(b)给出了两种方法查询目标节点的负载情况。从图2(a)可以看到,服务节点A,B,C,D,E,F的负载极不均衡,节点A承担了78%的数据,而其他5个节点的负载则不足10%。而图2(b)中6个节点的负载都在10%-20%之间,这表明本文提出的查询算法在大量服务节点间的负载更为均衡。这主要是因为本文方法对于服务节点的负载情况进行了衡量,通过定义超载因子和欠载因子,从而能够将负载相对较高的节点的数据转移到负载相对较低的节点上去,达到负载均衡的目的。
两种不同方法的查询路径长短比较如图3所示:
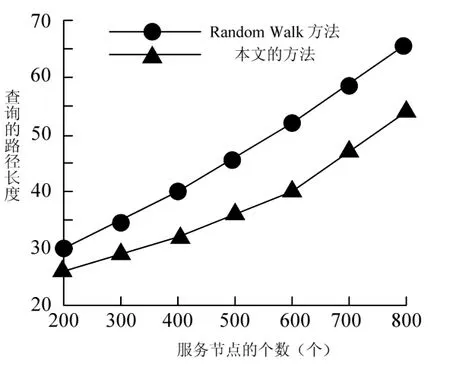
图3 不同查询方法的路径长度比较
从图3可以看到,两种方法的结果较为接近,本文方法略有优势。这主要是因为,在实际的数字图书馆云计算环境中,具有相似性的数据更有可能聚集在一起,因此本文的方法总是能够更快的查询到目标。
5 总结
云计算作为一种新的技术,在现实领域中有着广泛的应用,本文以数字图书馆的查询服务为研究对象,提出了一种基于云计算的数据查询方法。在该方法中,首先,通过定义相似节点集和相等节点集来衡量节点的状态,然后,通过Q值计算和负载大小比较,来为查询请求找到最适合的目标节点及数据。仿真实验结果表明,本文方法在查询的数据质量、服务节点的负载能力以及查询的效率方法要优于传统的方法。我们下一步研究工作的重点在于:面向数据密集型应用的数据分布方法研究,主要考虑如何减少跨数据中心的数据传输,如何在提供效率的同时兼顾全局的负载平衡。
[1] 陈康,郑纬民. 元计算:系统实例与研究现状[J]. 软件学报, 2009,20(5):1337-1348.
[2] 郑湃,崔立真,王海洋,徐猛. 云计算环境下面向数据密集型应用的数据布局策略与方法[J]. 计算机学报, 2010, 33(8):1472-1480.
[3] 田冠华,孟丹,詹剑锋. 云计算环境下基于失效规则的资源动态提供策略[J]. 计算机学报,2010,2008,33(10):1859-1871.
[4] 葛君伟,张博,方义秋. 云计算环境下的资源监测模型研究[J]. 计算机工程,2011,37(11):31-33
[5] Raykova M, Vo B, Bellovin SM, Malkin T. Secure anonymous database search[C]. In: Sion R, ed. Proc. of the 2009 ACM Workshop on Cloud Computing Security, CCSW 2009, Co-Located with the 16th ACM Computer and Communications Security Conf., CCS2009. New York: Association for Computing Machinery, 2009. 115−126. [doi: 10.1145/1655008.1655025]
[6] 胡小菁,范并思. 云计算给图书馆管理带来挑战[J]. 大学图书馆学报, 2009, 27(4):7-12.
[7] 朱一红. 云计算在图书馆的应用与潜在风险[J]. 图书馆理论与实践,2011,(3):32-35
[8] 潘文宇,段勇. 云计算在电信行业的应用研究[J]. 电信科学, 2010, 26(6):25-29
[9] 王长全, 艾棼. 云计算环境下的数字图书馆信息资源整合与服务模式创新[J]. 图书馆工作与研究, 2011 (001): 48-51
[10] 王长全, 艾雾, 姚建文. 云计算环境下数字图书馆信息资源安全策略研究[J]. 情报杂志, 2010, 3: 184-186
[11] 张凌超. 基于 “云计算” 的数字图书馆建设模式初探[J]. 图书馆学研究, 2010 (011): 39-42
[12] 姚婧, 何聚厚. 基于模糊聚类分析的云计算负载平衡策略[J]. 计算机应用, 2012, 32(1): 213-217
[13] 房晶, 吴昊, 白松林. 云计算安全研究综述[J]. 电信科学, 2011, 27(4): 37-42
[14] 郑伟, 王朝坤, 刘璋, 等. 一种基于随机游走模型的多标签分类算法[J]. 计算机学报, 2010, 33(8): 1418-1426
Research on Data Query Method Based on Random Walk in Cloud Computing
Liu Shuying
(The Institute of Information Engineering of XianYang normal university, xianyang 712000, China)
Aiming at the data query problem in the digital library application service, this paper propose a data query method based on cloud computing. Firstly, the target node of the query request is found based on the Random Walk, and then the second search is proceeded through defining the similarity nodes set and the equivalent nodes set of the service node, finally, the node and data with maximum evaluation value and the minimum load is returned. The experimental results show that the performance of our method is superior to the traditional methods in terms of the quality of data, the load capacity of service node and the efficiency of query method.
Cloud Computing; Digital Library; Random Walk; Data Query; Similarity Nodes set; Equivalent Nodes Set
TP391
A
2014.04.25)
1007-757X(2014)09-0030-04
咸阳师范学院基金项目(13XSYK054);陕西省教学改革项目(13BY90)
刘淑英(1982-),女,汉,陕西府谷人,咸阳师范学院信息工程学院,硕士,讲师,研究方向:信息检索、云计算,咸阳,712000
猜你喜欢
消费电子(2022年7期)2022-10-31
机械工业标准化与质量(2022年6期)2022-08-12
新高考·高三数学(2022年3期)2022-04-28
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
中文信息(2017年12期)2018-01-27
电子制作(2017年20期)2017-04-26
信息通信技术(2015年6期)2015-12-26
中国卫生(2015年12期)2015-11-10
中央民族大学学报(自然科学版)(2015年2期)2015-06-09