
面向海量病毒样本家族聚类方法的研究
2014-07-19 15:10赵跃华林聚伟
计算机工程与应用 2014年18期
赵跃华,林聚伟
江苏大学计算机科学与通信工程学院,江苏镇江 212013
面向海量病毒样本家族聚类方法的研究
赵跃华,林聚伟
江苏大学计算机科学与通信工程学院,江苏镇江 212013
1 引言
如今,恶意程序是互联网遭受的主要威胁之一,僵尸网络、钓鱼网站、恶意邮件等等本质上都是恶意程序,通常也简单的将恶意程序称为病毒。安全厂商每天都能收到成千上万份病毒样本,为了尽快处理这些安全威胁,安全厂商需要快速而准确地从这些样本中提取共性并家族化,从而以病毒家族为单位提供解决方案。
针对海量病毒样本的家族聚类研究经历了三个阶段,第一个阶段重在时间效率,旨在短时间内完成聚类工作,如2000年T.H.Haveliwala等人提出针对网络海量数据的聚类方法[1],可以在有限时间内完成聚类工作,但准确度偏低;第二个阶段同时重视准确度因素,如2007年M.Bailey和J.Oberheide等人介绍的如何自动化鉴定以及分析互联网恶意程序[2],但文章也说明牺牲了部分时间效率;第三个阶段则倾向于使用多算法的聚类方法,如2009年U.Bayer和P.M.Comparetti等人提出的大规模的、基于行为分析的病毒聚类系统[3],具有一定的时间效率和准确度,但其对病毒行为特征提取的维度较低,并且时间效率仍有待提高。
本文在分析现有方法的基础上设计了一种面向海量病毒样本的家族聚类方法,以帮助安全厂商解决近年来日益严重的病毒聚类问题。该聚类方法特色在于设计并实现了一种二级聚类模型,能够继承单一算法的优点,从而快速高效地完成聚类工作。同时使用高维特征刻画病毒行为以增强聚类的准确性。
2 可伸缩性聚类方法
2.1 聚类算法的选择
聚类算法的发展已经比较成熟,常见的聚类算法如K均值、凝聚层次聚类、DBSCAN和局部敏感哈希等等。其中,K均值和局部敏感哈希算法是基于原型的、划分的聚类技术;凝聚层次聚类是一种层次聚类算法;DBSCAN则是一种产生划分聚类的基于密度的聚类算法,其属于不完全聚类算法。
本文需要处理的数据是安全厂商每天接收到的成千上万的病毒样本,这些样本需要在最短的时间内处理完,从而生成以病毒家族为单位的解决方案推送给用户。理想的,这些数据应该被完全划分聚类,即这些病毒样本应该被划分成不重叠的子集,使得每个样本恰好在一个子集中,同时,每个样本都被处理到。显然,K均值算法和局部敏感哈希算法符合这样的要求。另外,最重要的一点是聚类处理要快速。从目前常见的病毒聚类系统[1-3]中可以发现,使用局部敏感哈希算法的系统时间效率最高,文献[1]的实验表明,使用Pentium II 300 MHz的CPU和512 MB内存的计算机,能够在16 h内处理2千万的数据量。因此,选择局部敏感哈希算法作为本文的聚类算法比较合适。
文献[1]的实验同时也表明仅仅使用局部敏感哈希索引技术虽然具有很高的时间效率,但牺牲了准确度,实验结果表明在同一簇中,有少数点与其他点相似度甚至少于20%。
表1概述了常见聚类算法的特征。选择局部敏感哈希算法可以快速处理海量病毒样本,但无法保证较高的准确性。因此,本文在文献[1]的基础上,设计了一种由粗到细的聚类方法。使用局部敏感哈希算法快速、大规模地处理海量病毒样本后,再使用K均值算法进行边缘颗粒的细化处理,以提高准确度。

表1 常见聚类算法特征
2.2 可伸缩聚类方法的结构
该方法是一种由粗到细的双算法结构,首先使用局部敏感哈希索引技术进行初次快速聚类,然后使用扩展K均值算法进行二次细致聚类。方法结构如图1所示。
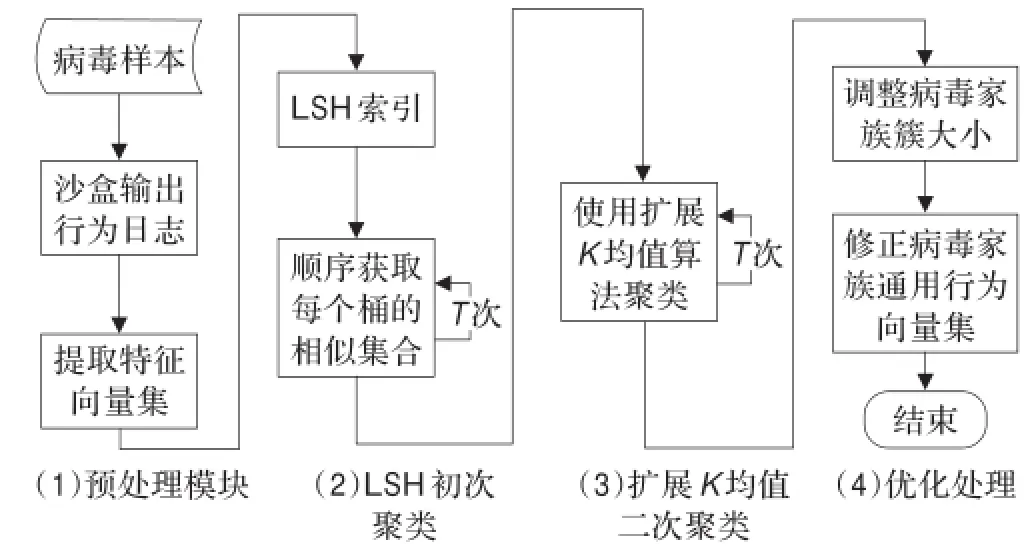
图1 可伸缩性聚类方法结构
图1描述了完整的用于病毒聚类的处理结构。首先使用沙盒技术从病毒样本中提取特征向量,然后将这些向量作为输入使用聚类模块进行聚类。聚类模块主要包括使用LSH(局部敏感哈希)索引技术进行初次快速聚类以及使用扩展K均值算法进行二次细致聚类。该聚类模块继承了单一LSH算法的优点:快速处理海量数据的能力;处理高维数据的能力。同时也继承了K均值算法高准确性的优点。
LSH算法[5]可以提供快速且支持高维度的聚类,极大地满足了近实时性的要求。初次聚类后,由于LSH算法只计算了近似度,并不能保证所有结果相似值都在阀值内,因此本文在进行LSH索引后又使用了具有高准确性的扩展K均值算法进行二次细致聚类。
3 实现描述
3.1 预处理
为有效地进行二级聚类处理,需作预处理。由于病毒样本经沙盒技术分析所得到的行为日志信息过于冗余且不能直接被后面的聚类模块识别,因此需要从行为日志中提取特征向量。
本文根据行为日志的内容定义了一个三级结构,而从这个三级结构中抽取的信息称之为特征。例如下面的三级结构代表了沙盒日志内容的一部分:

在这个例子中,本文定义的三级结构为dll_handling_ section,load_dll和filename,然后为此特征条目赋值一个特征ID。使用这种方法处理整个日志内容,可以得到一个特征ID集合作为二级聚类处理模块的输入。
3.2 二级聚类处理
LSH算法可以分为两个部分[6]:LSH模型建立和LSH结果检索。图1中的LSH索引模块实际上就是LSH模型建立的过程。LSH模型建立的过程如下:

在文献[7]中提到,LSH算法存在固有的缺点:索引结构依赖于r,ε和n的参数k和l。因此,建立LSH索引的过程需要对参数进行调整,并且随着数据的变化还需要对索引结构进行调整。本文使用文献[7]的方法实现LSH参数自动调整。
在使用LSH算法成功索引后,将会顺序获取每个桶的相似集合。首先选择该桶的一个元素作为查询元素进行查询,查询完毕即获得该桶的一个相似集合S。然后一边将集合S传给下一个模块继续处理,一边继续下一次查询,直到遍历完所有桶。
由于LSH索引只计算了相似度,并不能保证所有结果相似值都在理想阀值内,所以可伸缩性方法的第二个模块使用扩展K均值算法对S集合进行细致高准确度的处理。
文献[8]介绍了基本K均值算法,它是基于原型的、划分的聚类技术,也是一种使用最为广泛的聚类算法。基本K均值算法在处理高维的、大容量的数据时有其固有的缺陷,即时间效率低,不能满足近实时性的要求。而本文设计的可伸缩性方法在完成LSH索引后,只是采用K均值算法对边缘颗粒进行修正,因此不会由于重复地计算每个点和每个质心的相似度而明显降低整个算法的时间效率。本文在基本K均值的基础上作了一些扩展以满足对LSH索引的兼容以及对边缘颗粒修正的要求。扩展K均值算法定义如下:

在上述算法中,T即为LSH索引的桶的数量;Buffer集合是一个缓冲集合,用于保存离群点;J(*)即Jaccard系数,t为相似度阀值,由人工指定。该算法避免了基本K均值算法的大量重复计算,而只计算了每个桶和离群点的元素与该桶质心的距离,不会计算桶元素与其他桶质心的距离,即使用离群点规避了重复的大量计算。该算法的复杂度为O(Tn),其中T是初次聚类后病毒家族的数量,n是每个桶的元素数目。另外,此算法在选择初始质心时是确定的,不存在基本K均值选择初始质心的盲目性,即初始质心为J(*)≥t所有元素的均值。
图2显示了LSH索引后扩展K均值算法一个工作实例的部分过程。
在图2中,LSH索引首先输出一个集合S给扩展K均值模块处理,扩展K均值将相似度超过阀值的两个点(处理2中的黄点)判定为离群点划到Buffer集合中;接着LSH索引继续输出另一个集合S′给扩展K均值模块处理,这个时候Buffer和S′组成新的集合重新聚类,从处理3中可以看到,黄色的点已经被吸收进了第二个簇中,并重新生成了一个离群点(黑色)到Buffer中。重复此过程,直到LSH索引不再输出。最后删除Buffer集合。
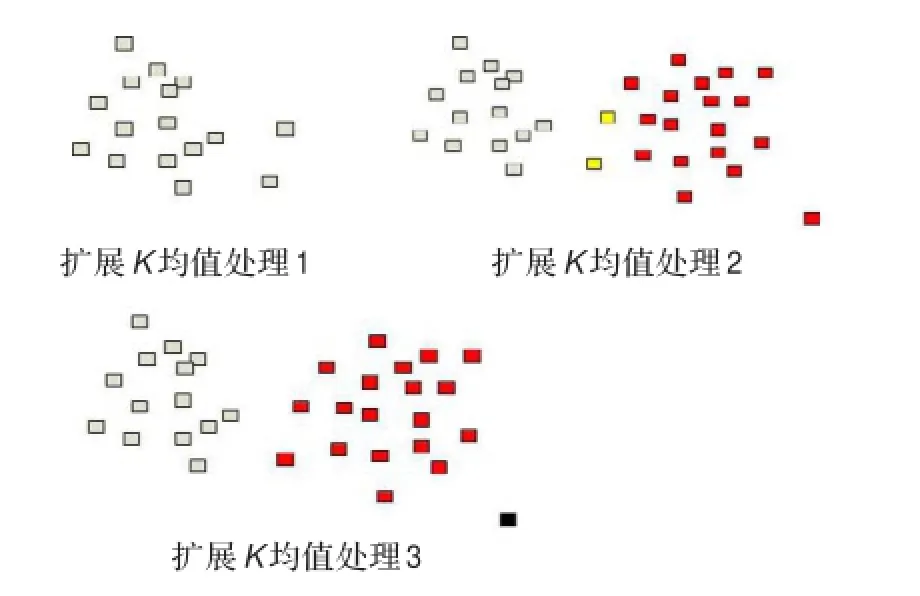
图2 扩展K均值一个实例的部分过程
LSH索引和扩展K均值共同组成可伸缩性方法的聚类核。样本经由聚类核处理完毕后,将由调整模块进行优化调整。
3.3 簇的优化
簇的优化包括两个部分:调整病毒家族的数量和修正病毒家族通用行为向量集。
为了防止病毒家族膨胀,以及特定需求下需要更广义的病毒家族,可以进一步聚类以控制病毒家族的总体数量。进一步聚类的方法是,从每一个病毒家族中选择一个具有代表性的项,然后计算每个代表项之间的相似度,根据给定阀值将相似度高于阀值的家族归并。经过大量实验发现,该阀值等于0.7时具有良好的聚类效果。
聚类完成后,还需要修正病毒家族的通用行为向量集。本文引入了冗余特征消除的算法——主成分分析[9],它是将多个变量通过线性变化以选出较少个数重要变量的一种多元分析方法,该方法的最优性是从n个样本中提取m个主要特征,达到降维的目的。
4 测试
为了测试本文所设计的可伸缩性方法,本文使用了2 704个已知样本作为测试输入,将测试输出同标准相比较。
测试环境为惠普xw4600计算机(主要配置为一个Intel酷睿2四核Q9550处理器,4 GB内存,Windows 2003操作系统)。被测软件是本文设计的聚类系统mcs(malware clustering system)和按文献[3]设计的凝聚层次聚类系统。
4.1 有效性测试
本文定义了纯度的概念来刻画可伸缩聚类方法的准确性,其定义:
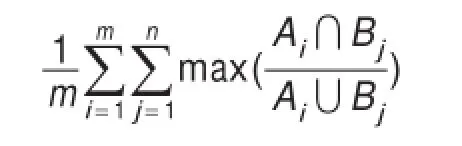
其中,集合A是测试输出,集合B是标准。在本次实验中共生成54个病毒家族,表2显示了测试结果中前8个病毒家族的纯度。
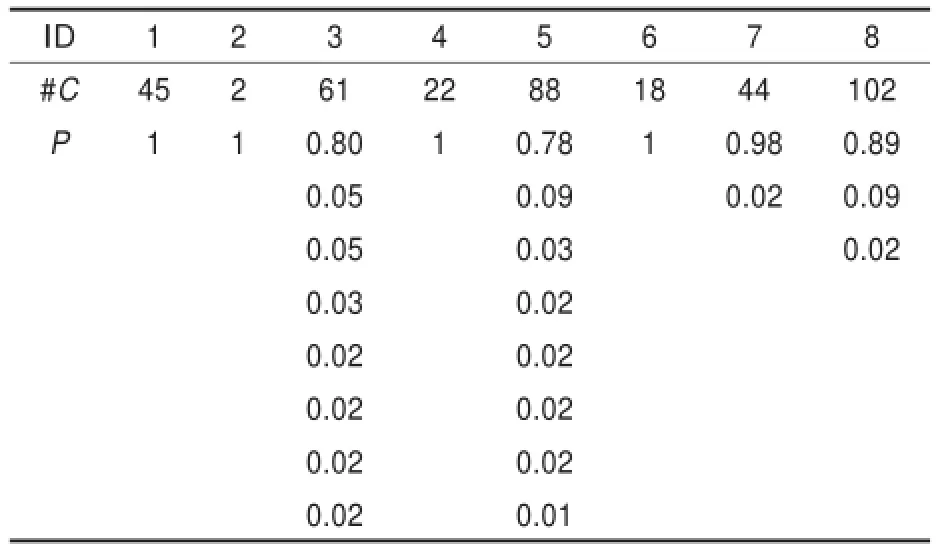
表2 测试输出纯度表
在表2中,第一行显示簇ID,第二行显示每个簇的大小,而下面的每一行显示该簇的组成中包含各种家族病毒的比例。例如,ID为7的簇,纯度为0.98,大小为44,即意味着该簇由43个家族A的病毒和1个家族B的病毒组成,显然,这1个家族B的病毒被误判进了簇7中。
本文将所有的2 704个样本聚类为54个病毒家族,平均纯度为0.91。实验数据证明了由于经过预处理时高维特征的选取与优化,二级聚类模块的扩展K均值聚类以及簇的优化,最终聚类达到一个较高的准确度。
4.2 对比测试
本节首先使用纵向对比测试,如图3所示。在均使用扩展K均值的前提下,分别在使用和不使用LSH索引的情况下计算聚类所花费的时间以及聚类的纯度。然后再通过横向对比测试将本文设计的聚类方法和文献[3]中设计的聚类方法作对比。
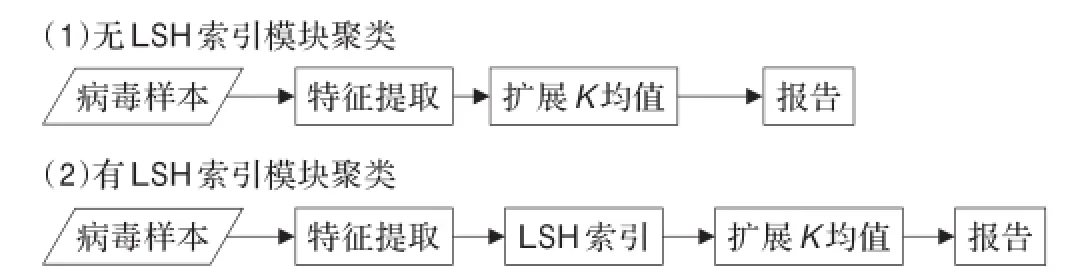
图3 纵向对比测试方法
经过计算,对比测试结果如表3所示。

表3 对比测试结果
从表3中可知,本文设计的病毒聚类方法使用LSH索引技术后,虽然聚类的纯度(即准确性)下降了4.2%,但时间消耗减少了94.5%,从而达到安全厂商近实时性处理的要求。另外,同文献[3]中的聚类系统相比,纯度下降了5.2%,但时间消耗减少了95.2%。因此,本文设计的方法在有限降低聚类准确度的情况下,大为提高了聚类的时间效率。实验数据同时也证明了二级聚类模块的有效性:由于使用了LSH索引技术,所以相比之下具有很高的时间效率;然而同时也降低了一定的准确度。
5 结束语
本文介绍了一种新的针对大量病毒样本聚类的方法。首先使用沙盒技术获取病毒行为日志,然后从日志中提取特征向量作为聚类模块的输入,接着聚类模块先后使用LSH索引和扩展K均值算法由粗到细地对输入的特征向量集聚类,最后由优化模块对结果进行优化处理。实验表明,这种双算法结构的可伸缩性聚类方法在牺牲有限准确性的同时极大提高了病毒家族聚类的时间效率。
本文所设计的可伸缩性聚类方法和所有基于行为分析的聚类方法一样具有一些局限性。获取病毒运行行为日志的前提是确保病毒完整地在沙盒中运行,然而,有些病毒的行为具有条件依赖性,例如某些逻辑只有在网络通顺或者接收到特定指令的情况下才会执行。
后期的工作是在确保时间效率的前提下进一步提高聚类的准确性,同时提高病毒样本在沙盒等模拟环境中的爆破率。
[1]Haveliwala T H,Gionis A,Indyk P.Scalable techniques for clustering the web[C]//WebDB(Information Proceedings),2000:129-134.
[2]Bailey M,Oberheide J,Andersen J,et al.Automated classification and analysis of internet malware[C]//Proceedings of the 10th International Symposium on Recent Anvances in Intrusion Detection,2007:178-197.
[3]Bayer U,Comparetti P M,Hlauschek C,et al.Scalable,behavior-based malware clustering[C]//Proceedings of the Network and Distributed System Security Symposium,2009.
[4]Weber R,Schek H,Blott S.A quantitative analysis and performance study for similarity search methods in high dimensional spaces[C]//Proceedings of the 24th Intl Conf on Very Large Data Bases(VLDB),1998:194-205.
[5]Indyk P,Motwani R.Approximate nearest neighbors:towards removing the curse of dimensionality[C]//Jeffrey V.Proc of the 30th Annual ACM Symp on Theory of Computing. New York:ACM Press,1988:604-613.
[6]蔡衡,李舟军,孙健,等.基于LSH的中文文本快速检索[J].计算机科学,2009,36(8):201-204.
[7]卢炎生,饶祺.一种LSH索引的自动参数调整方法[J].华中科技大学学报,2006,34(11):38-40.
[8]Tan Pangning,Steinbach M,Kumar V.数据挖掘导论[M].北京:人民邮电出版社,2006:310-311.
[9]朱明旱,罗大庸,易励群.一种广义的主成分分析特征提取方法[J].计算机工程与应用,2008,44(26):38-40.
ZHAO Yuehua,LIN Juwei
School of Computer Science and Telecommunication Engineering,Jiangsu University,Zhenjiang,Jiangsu 212013,China
Anti-malware companies receive thousands of malware samples every day,so it becomes more and more pressing to handle these samples timely and effectively.A scalable clustering approach is proposed to group these massive malware samples.LSH algorithm is used to cluster samples rapidly.ExtendedK-means algorithm is employed to perform accurately clustering.Experimental results show that this approach can improve malware clustering efficiency observably at the cost of little accuracy.
malware family;scalable clustering;Locality Sensitive Hash(LSH)algorithm;extendedK-means
计算机反病毒厂商每天接收成千上万的病毒样本,如何快速有效地将这些海量样本家族化是一个亟待解决的问题。提出了一种可伸缩性的聚类方法,面对输入海量的病毒样本向量化特征集,使用局部敏感哈希索引技术进行初次快速聚类,使用扩展K均值算法进行二次细致聚类。实验表明该聚类方法在有限牺牲准确度的情况下,大为提高了病毒聚类的时间效率。
病毒家族;可伸缩性聚类;局部敏感哈希;扩展K均值
A
TP309.5
10.3778/j.issn.1002-8331.1210-0202
ZHAO Yuehua,LIN Juwei.Research on familial clustering of massive malware samples.Computer Engineering and Applications,2014,50(18):118-121.
赵跃华(1958—),男,教授,主要研究方向为信息安全;林聚伟(1987—),男,硕士研究生,主要研究方向为计算机反病毒和漏洞挖掘。E-mail:zhaoyh@ujs.edu.cn
2012-10-19
2012-12-18
1002-8331(2014)18-0118-04
CNKI网络优先出版:2013-01-11,http://www.cnki.net/kcms/detail/11.2127.TP.20130111.0953.018.html
猜你喜欢
电脑爱好者(2020年20期)2020-10-22
小哥白尼(军事科学)(2019年9期)2019-12-21
电影(2019年3期)2019-04-04
少儿科学周刊·少年版(2017年3期)2017-06-29
工业设计(2016年8期)2016-04-16
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
数学年刊A辑(中文版)(2014年4期)2014-10-30
郑州大学学报(理学版)(2014年4期)2014-03-01
计算机工程(2014年6期)2014-02-28
