
基于距离-信号模型的RFID数据清洗算法*
2014-07-19 12:33:33吴新淼李少波唐向红黄海松
组合机床与自动化加工技术 2014年5期
吴新淼,李少波,唐向红,黄海松
(贵州大学 a教育部现代制造技术重点实验室;b.机械工程学院 ,贵阳 550003)
基于距离-信号模型的RFID数据清洗算法*
吴新淼a,b,李少波a,b,唐向红a,b,黄海松a,b
(贵州大学 a教育部现代制造技术重点实验室;b.机械工程学院 ,贵阳 550003)
针对RFID数据读取不确定性造成的数据冗余和脏数据现象,文章通过标签不同时刻的信号强度估算标签移动的速度和过程时间,利用估算的结果清除冗余数据和脏数据,同时将数据处理和数据输出过程并行执行。该方法大大提升了冗余数据和脏数据清理效果,缩短了算法的执行时间,提高数据的准确性和有效性。仿真实验表明,文中提出的方法与传统RFID数据清洗算法相比,数据清洗效果优势显著,所需处理时间和空间大幅降低。证明了该算法的可行性。
RFID;数据清洗;数据处理;数据输出;并发执行
0 引言
无线射频识别( radio frequency identification)应用系统是由储存信息标签、采集设备阅读器、信息处理应用几个部分构成,是一种依靠射频信号产生感应电流激活标签向阅读器发射储存信息的无需接触的自动化识别技术[1]。在无线射频识别系统中,由于标签与阅读器的特性以及环境的影响,使RFID原始数据存在脏数据、冗余读等问题,并且这些数据都是海量的,因此对于RFID原始数据的处理是必须的,也是重要的。
文献[2]提出一种在线清洗框架系统,对多读和漏读具有一定的效果,但是由于算法在粒度和滑动窗口的设置给应用范围带来了一定的局限性,不利于算法的推广。文献[3]提出一种自适应确定窗口大小的方法 SMURF ,该方法根据每个纪元内标签的阅读率和概率论的方法动态调整滑动窗口的大小。但是该方法有可能会导致标签数据重复存储,消耗大量的系统内存,导致内存溢出,同时也可能造成多读和漏读数据的问题。文献[4]提出了一种KAL-RFID数据清洗算法,在一定上程度减少了单个阅读器消极读、积极读和延迟问题,但是该算法的随机性对结果带来一定的误差,同时也没有解决好冗余读问题。文献[5]提出了一种基于伪事件的数据清洗算法PSCleaning,该方法中滑动窗口大小的设置具有随机性,不利于算法的扩展同时有可能会导致冗余读。文献[6] 提出了基于噪音过滤算法和基于hashtable的有序噪音过滤算法,以及基于冗余过滤算法和基于hashtable的冗余过滤算法,虽然该算法对噪音和冗余数据有一定的效果,但是由于滑动窗口长度的设置会导致冗余数据。文献[7]提出了一种自适应时间阀值的RFID数据清洗算法,该算法中的平均阅读率的设置具有很大的随机性,不同的环境对阅读率有很大的影响,从而会造成标签冗余数据。
针对如上文献介绍方法的不足之处,本文提出了一种通过考虑标签在阅读器辐射范围中的过程时间(Process Time),同时将数据处理和数据输出分开并发执行的方法,解决了RFID原始数据存在的脏数据、冗余问题、缓存过大的问题,也提高了算法的运行效率。
1 相关定义
通常情况下,标签数据在预处理中,都是以一定的数据格式被传输,标准形式为S(SEPC,RID,timestamp),其中SEPC为标签的EPC编码,RID为阅读器ID,timestamp为标签被采集到的时间戳,本文针对不同缓存队列,采取不同的数据存储格式。
定义1 :RFID数据的不确定性。
①脏数据(DirtyData):由于周围环境的金属,水,以及标签间冲突的影响,导致了阅读器对标签的读取产生误差,出现了EPC值不正确的标签数据,即脏数据。
②数据冗余(DataRedundancy):阅读器对其读写范围内的标签进行多次读取操作,这样一个标签数据就产生了多个重复的数据,即数据冗余。
③漏读(NegativeRead):阅读器没有读到在其读写范围内的标签数据,即产生了标签数据漏读。
定义2 :过期性。描述的是标签数据在一个缓存队列中存在的时间长度,例如标签数据的过期时间是13点50分6秒2毫秒,现在时间是13点50分6秒3毫秒,此时标签数据就达到过期了,缓存队列就会删除这条过期的标签数据,有利于消除冗余数据问题,同时也有利于消除数据内存占有量。
定义3 :真实数据。指的是在读取缓存队列中,过期标签数据的读取次数大于或等于重复阀值μ的标签数据,其中重复阀值μ是一个标签数据被阅读器采集的次数,按照已有的经验,一般定义为2。
定义4:过程事件(Process Events)。描述的是贴标签物品从进入阅读器到离开阅读器移动的轨迹的过程。
图1表示了阅读器正常工作时,其工作辐射的垂直面映射,其中θ为阅读器读取范围的辐射角度,h为阅读器离贴标签物品的垂直距离,L是过程路程。
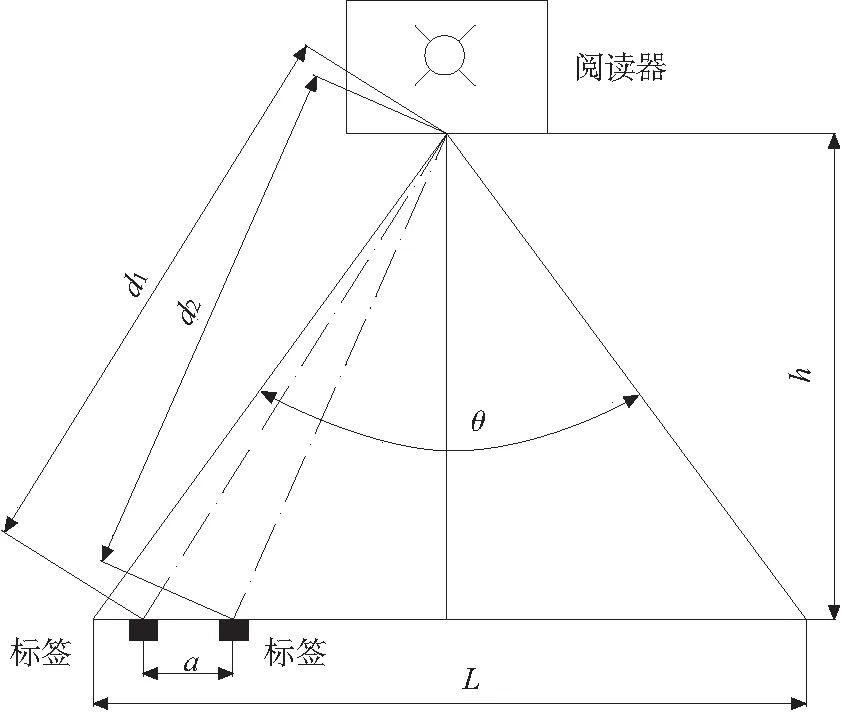
图1 阅读器辐射范围
定义5:过程速度(Process Speed)。描述的是贴标签物品在过程事件(Process Events)内移动速度V。
定义6:过程路程(Process Distance)。描述的是贴标签物品在过程事件(Process Events)中所移动的距离,如图1所示,L是过程路程,由几何关系可知L=2×h×tan(θ/2)。
定义7:过程时间(Process Time)。描述的是贴标签物品穿过过程路程(Process Distance)所需要的时间T,由s=v×t的关系,可知T=L/V= 2×h×tan(θ/2)/V,单位是毫秒。
2 距离-信号强度模型
目前,常用的传播路径损耗模型有自由空间传播模型,对数距离路径损耗模型和对数常态分布模型等。室内无线传播受室内环境变动和室内无线信号覆盖的距离的影响,因此本文用对数传播路径损耗模型来描述本文算法的无线信号传播模型[8]。
(1)
式中,PL(d)表示距离读写器为d的标签所接收到的信号强度,n是路径损耗指数,d0是近似地参考距离,d是读写器与标签之间的距离,∂是服从正态分布的随机变量。在实际的应用中我们一般采用简化的模型
(2)
通过公式(2)我们知道距离与信号强度的关系,为了简化计算,取d0的距离为1m,则进一步简化公式(2)得
PL(d)=PL(1)-10nlg(d)
(3)
式中,我们把PL(d)改写成RSSId,PL(1)改写成RSSI1,整理得
(4)
(4)式反应了信号强度与距离的关系,n是经验值,RSSI1是一个测量值,都是一个常数。根据已知获取的电子标签的信号强度值就能得到电子标签距离阅读器的距离。
3 自适应过期时间数据清洗算法
3.1 清洗框架
本算法清洗框架主要由数据处理和数据输出两部分组成,两部分是并发执行的。其中,数据处理是对阅读器读取的标签数据进行去脏数据处理、确定标签数据的过期时间的和冗余处理。数据输出是通过定时器定时对去读取缓存队列中的数据进行过期标签的检测以及真实数据的输出,当有过期标签数据时,通过比较器判断过期标签数据是否是真实标签,从而输出提交到上层应用系统。
3.2 数据处理
3.2.1 数据处理算法结构
数据处理由冲突检测机制、计算器、转换器、读取缓存队列构成,具体的清洗结构如图2
其中,读取队列用于存储经过去计算器处理的标签数据,存储的数据格式为(EPC,RSSI,timestamp,N,expiretime),其中EPC为标签的EPC编码值,RSSI为标签接受到阅读器发射的信号强度值,timestamp为标签被采集到的时间,expiretime为标签数据的过期时间。
冲突检测机制是检查有无相同标签数据,首先从阅读器获取一个标签数据Q,通过比较在读取缓存队列中是个含有该相同标签数据来判断是否冲突,首先,当有冲突时,获取读取缓存冲突标签数据P的N值,当N值为1时,新进入的标签数据Q必须经过计算器处理,然后修改读取缓存队列中P的expiretime时间,N值,使P(expiretime)=Q(expiretime)、P(N)=P(N)+1;当N值大于1时,通过修改读取缓存队列中冲突标签数据的N值,使P(N)=P(N)+1;无冲突时,将数据Q经过转换器处理读取缓存要求的格式直接插入读取缓存队列末尾,其中Q(expiretime)首先为默认一个适当值。
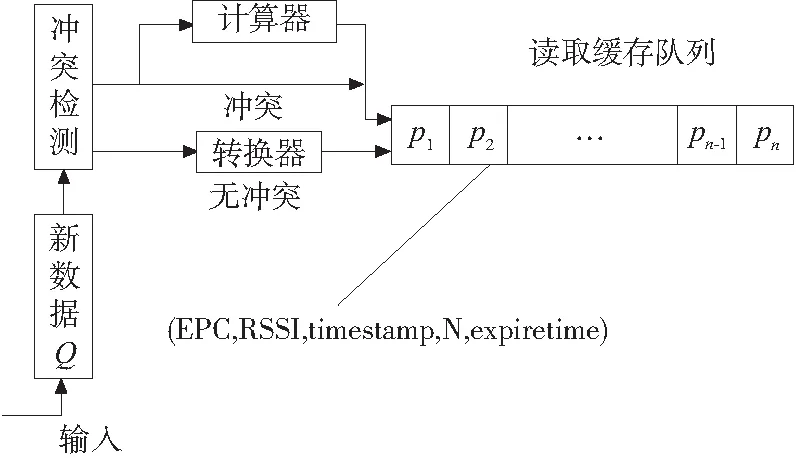
图2 数据处理结构
转换器是用于对阅读器读取的新数据进行格式转换处理,使之统一,利于标签数据的处理。
计算器是计算标签数据的过期时间expiretime,通过结合距离-信号强度传播模型,计算标签过程速度V和过程时间T。具体思想:首先取首次被连续采集两次标签数据的信号强度值RSSI,根据距离-信号强度传播模型中公式(4)计算出标签在t1时刻和t2时刻处分别离阅读器的距离d1和d2:
(5)
(6)
如图1,由图型几何知识,计算得标签首次被连续读取的不同位置的间隔距离a:
(7)

(8)
T=
然后由expiretime= timestamp+T,计算出expiretime,将计算出来的expiretime加入到(EPC, RSSI,timestamp,N,expiretime),然后保存到读取缓存队列的末尾。
3.2.2 数据处理算法描述
算法的流程图如图3,具体的流程步骤如下
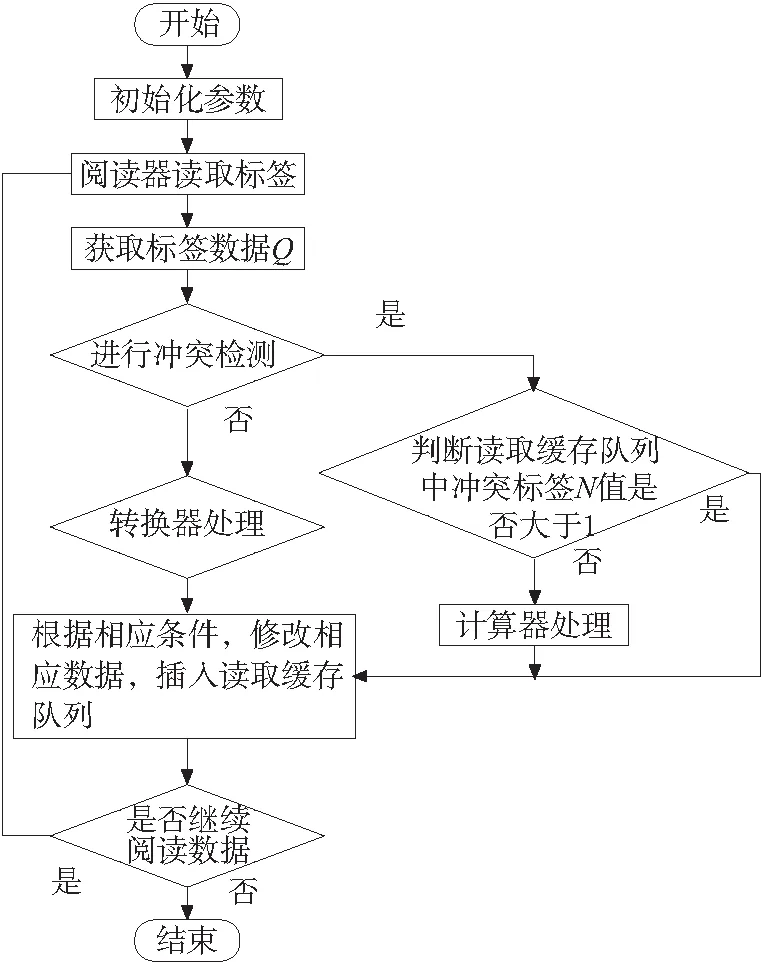
图3 数据处理流程
(1)开始。
(2)初始化参数数据。
(3)启动阅读器读取标签数据。
(4)获取阅读器读取的标签数据Q和RSSI值。
(5)Q数据经过去脏处理后进入到冲突检测机制进行检测,当有冲突时,转至步骤(6),否则,转至步骤(8)。
(6)判断读取缓存队列中和Q数据是冲突标签数据P的N值,当N值大于1时,转至步骤(9),当N值等于1时,转至步骤(7)。
(7)将获得的Q数据以及和P数据进行计算器处理,计算标签数据的过期时间expiretime,转至步骤(9)。
(8)Q数据经过转换器处理,转换成读取缓存队列要求的数据格式(EPC,RSSI,timestamp,N,expiretime),其中expiretime在标签首次被采集到时设置一个足够大的默认时间,转至步骤(9)。
(9)根据相应的条件,增加数据或者修改读取缓存队列中的标签数据,转至步骤(10)。
(10)是否继续读取标签数据,如果是继续读取,转至步骤(3),否则转至步骤(11)。
(11)结束。
3.3 数据输出
3.3.1 数据输出算法结构
数据输出有定时器、去冗余缓存队列、过期检测、比较器组成。具体的数据输出结构如图4
定时器是用来控制定时从读取缓存队列中获取过期的标签数据,并输出到过期检测机制进行处理,从而将达到要求的数据输出到应用系统的一个过程。
过期检测机制是处理读取缓存队列中数据的过期性,具体的处理过程是获取系统当前时间NowTime,通过比较当前数据与读取缓存队列中标签数据的expiretime的大小来判定标签数据的过期,当NowTime大于或者等于expiretime,输出此数据,否则不输出。
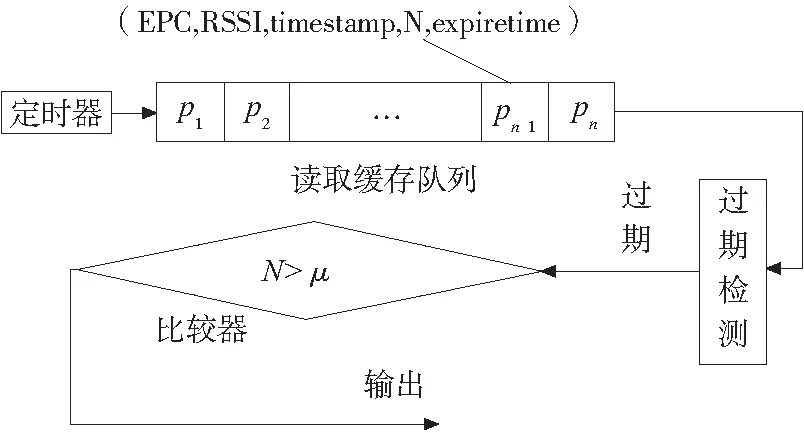
图4 数据输出结构
比较器主要判断从过期检测机制输的标签数据N与规定阀值μ比较,从而判断标签数据是否是真实的标签数据,是真实数据就输出并提交到上层应用系统,不是真实数据,则不输出到上层应用系统。
3.3.2 数据输出算法描述
算法的流程图如图5,具体的流程步骤如下:
(1)开始。
(2)初始化数据设置。
(3)判断去冗余噪音缓存队列是否有数据,当没有数据时,转至步骤(9),当有数据时,转至步骤(4)。
(4)读取缓存队列中标签数据经过过期检测,如果有过期数据,至步骤(5),否则,转至步骤(8)。
(5)获取过期标签数据。
(6)过期数据经过比较器处理,结果是真实标签数据的,转至步骤(7),否则 转至步骤(8)。
(7)输出过期标签数据到上层应用系统,然后转至步骤(8)。
(8)删除读取缓存对中获得的过期标签数据,转至步骤(9)。
(9)结束。
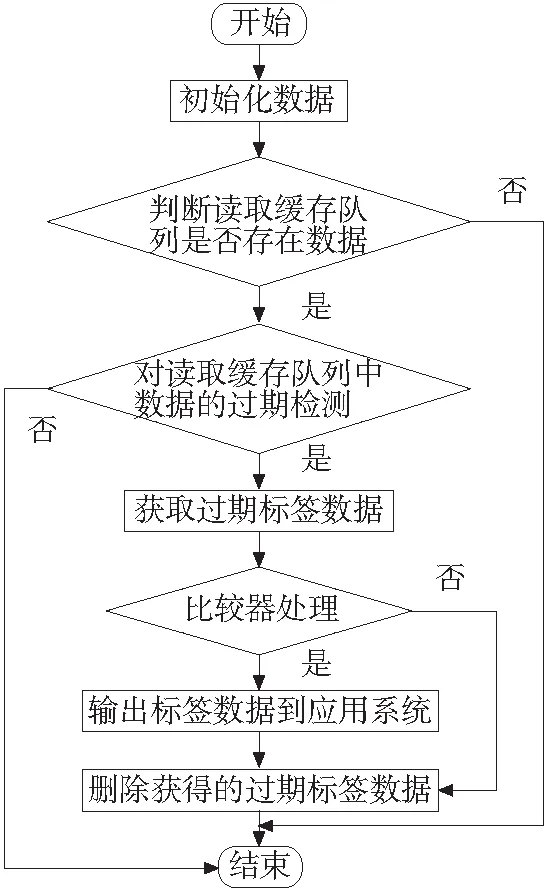
图5 输出流程
4 实验及算法结果分析
4.1 实验准备
实验目的是测试本文所提出的算法的性能,证明其适用性。试验方法是通过标签穿过某仓库阅读器型号为CCS2026A的环境所生成的测试数据,然后在处理器为AMD Phenom(tm)Ⅱ×4810 Processor 2.6GHz 、内存为2GB的PC机上完成对获得的测试数据进行MATLAB的仿真处理。通过和现有经典算法SMURF算法[3]比较来判别该算法的整体性能,从而证明该算法的适用性。
试验要求的具体装置:阅读器型号为CCS2026A,处理器为AMD Phenom(tm)Ⅱ×4810 Processor 2.6GHz 、内存为2GB的PC机,大量的测试RFID标签。表一是部分试验条件的主要参数。
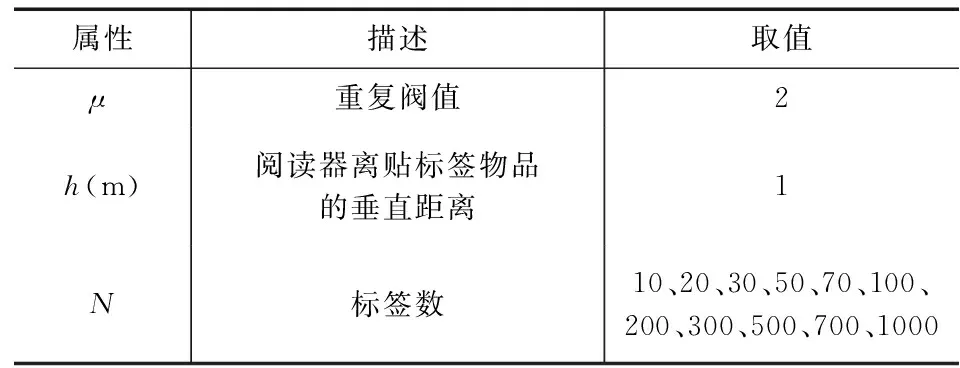
表1 实验条件主要参数及说明
4.2 算法结果分析
本算法结果主要从算法缓存大小、输出标签数据个数、执行算法所用时间的角度来分析,通过和经典smurf算法的比较来检验本文算法的可行性。
从图6可以看出,传统的smurf算法缓存大小会随着标签个数的增加成倍数的增大,而本文算法的增长速度却相比较慢,与传统的smurf算法相比呈现差距比较大,节约缓存了空间,产生这结果是由于本文算法通过将相同数据用次数N值来表示和定期的删除过期的标签数据的方法来节约缓存空间,从而达到了提高缓存空间的利用率,验证了方法的可行性。

图6 缓存大小
从图7可以看出,经典smurf算法和本文算法在标签数据输出个数时差异不是很大,但是经典smurf算法随着标签的增多,出现了一定的冗余标签数据,而本文算法基本上和真实数据保持了一致,反应了本文算法通过考虑标签在阅读器辐射范围内的过程时间来消除冗余数据的办法的可行性,从而提高了标签数据的准确性。
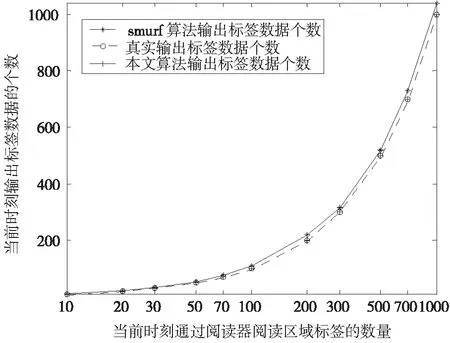
图7 数据输出
图8是从算法运行的时间来比较的一个仿真结果,从图中可以看出,本文算法相比于经典的sumrf算法,运行的时间得到了减少,说明了本文算法将数据处理和数据输出并行处理来节约算法时间的方法是可行的,从而提高了算法的运行效率,提高了效率。
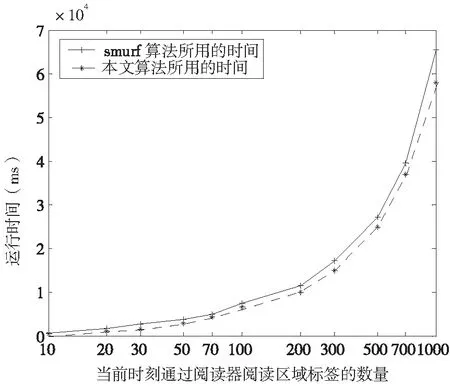
图8 算法所用时间
5 结论
本文针对目前传统的RFID数据清洗算法的一些不足之处,将距离-信号模型运用到数据清洗算法中,计算出标签的过程时间,同时将数据处理和数据输出分开并行执行,运用定时器定时循环的支持数据输出,缩短了算法的执行时间,提高了效率。实验证明了该算法相比于传统的SUMRF算法在缓存空间、冗余数据清除、算法运行方面,都具有一定的优势,具有很好的可行性。
[1] Futher P,Guinard D,Liechti O.RFID: from concepts to concrete implementation[C]. In:Proceedings of Systems and Interdisciplinary Research,IPSI,Marbella,Spain,2006: 10-13.
[2] Jeffery R,Alonso G,Franklin M,et al. A pipelined framework for online cleaning of sensor data streams[C]. In: Proceedings of Internatianal Conference on Data Engineering,ICDE,Atlanta,Geor-gia,USA,2006: 773- 778.
[3] Jeffcry S R,Garofalakis M,Franklin M J.Adaptive cleaning for RFID data streams//Proc of the 32nd Int Conf on Very Large Data Bases.New York:ACM,2006:163—174.
[4] 王妍,宋宝燕,付菡,等. 引入卡尔曼滤波的RFID数据清洗方法[J]. 小型微型计算机系统,2011,(09):1794-1799.
[5] 王妍,石鑫,宋宝燕. 基于伪事件的RFID数据清洗方法[A]. 中国计算机学会数据库专业委员会.第26届中国数据库学术会议论文集(B辑)[C].中国计算机学会数据库专业委员会:,2009:5.
[6] 邓海生,李军. RFID数据流过滤算法研究[J].计算机技术与发展,2012(6):26-29,34.
[7] 潘伟杰,李少波,许吉斌.自适应时间阈值的RFID数据清洗算法[J].制造业自动化,2012,13:24-27+36.
[8] 王琦.基于RSSI测距的室内定位技术[J]. 电子科技,2012(6):64-66,78.
(编辑 李秀敏)
A Cleaning Algorithm of RFID Data Based On Distance - Signal Model
WU Xin-miaoa,b,LI Shao-boa,b,TANG Xiang-honga,b,HUANG Hai-songa,b
(a. Key Laboratory of Advanced Manufacturing Technology, Ministry of Education;b.College Of Mechanical Engineering, Guizhou University, Guiyang 550003 ,China)
In order to handle redundant data and “dirty” data caused by uncertainty of RFID data reading ,this paper proposed a new method ,which estimated the speed of RFID tags movement and process time according to the signal strength of RFID tags at different times and then cleaned redundant data and dirty data based on the results of the estimation. The method ran processing and output of data in parallel. This method greatly enhances the cleaning effect of redundant data and dirty data and shortens the execution time. It also improves accuracy and validity of data. The results of simulation experiments showed that the proposed method, compared with traditional RFID data cleaning algorithm, has the advantages at the effect of data cleaning and greatly reduced time and space of processing. The method is proved to be feasible.
RFID;date cleaning;date processing;date output;concurrent execution
1001-2265(2014)05-0087-05
10.13462/j.cnki.mmtamt.2014.05.022
2013-08-19;
2013-09-23
国家科技支撑计划课题(2012BAF12B14);贵州省重大科技专项(黔科合重大专项字(2012)6018);贵州省科学技术基金项目(黔科合 J字[2011]2196号)
吴新淼(1986—),男,湖北咸宁人,贵州大学硕士研究生,主要研究方向为先进制造模式与信息系统,(E-mail)wuxinmiao86@126.com;李少波(1973—),男,湖南岳阳人,贵州大学博士生导师,主要研究方向为先进制造模式与信息系统、智能控制、物联网技术及系统等,(E-mail)lishaobo@gzu.edu.cn。
TH166;TG65
A
猜你喜欢
电子设计工程(2022年15期)2022-08-17 10:07:04
中华眼视光学与视觉科学杂志(2022年8期)2022-08-17 06:05:42
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
军营文化天地(2018年2期)2018-12-15 17:39:08
东北师大学报(自然科学版)(2018年3期)2018-09-21 09:06:36
现代测绘(2018年1期)2018-03-06 05:16:16
产品可靠性报告(2017年7期)2017-09-05 09:49:12
测绘通报(2016年9期)2016-12-15 01:56:16
现代计算机(2015年17期)2015-09-26 02:01:54
