
基于多模芯片的TD-SCDMA系统Turbo码内交织器设计
2014-07-01 01:13刘畅
河南科技 2014年4期
刘畅
(重庆邮电大学移动通信技术重点实验室 重庆 400065)
基于多模芯片的TD-SCDMA系统Turbo码内交织器设计
刘畅
(重庆邮电大学移动通信技术重点实验室 重庆 400065)
本文在多模基带芯片(兼容LTE和TD-SCDMA系统)Turbo译码器的硬件加速器设计背景下,介绍了TD-SC DMA系统中Turbo码的码内交织器结构以及算法设计,针对硬件实现提出了具体的算法优化设计方案,使算法的复杂度得到了进一步降低,并且提高了时间效率,对整个TD-SCDMA系统有很大的实用价值。
TD-SCDMA;Turbo码;交织器;数字信号处理
上世纪90年代Berrou等人在ICC会议上提出了一种采用重复迭代(Turbo)译码方式的并行级联码,该译码器采取了软输入/输出的方式,具有接近香农极限的优良性能,从而受到移动通信领域的广泛重视,特别是在第三代移动通信体制中,被广泛采用。
在多模基带芯片(兼容LTE与TD-SCDMA系统)的设计中,Turbo译码器作为独立的核通过硬件加速器实现,LTE系统与TD-SCDMA系统复用Turbo译码器主体结构,并使用各自独立的码内交织器进行译码。因此,本文针对TD-SCDMA系统的Turbo码内交织器,本着减少硬件开销和复杂度的角度出发,整理出一套可行的算法优化设计方案,易于硬件实现。
1 TD-SCDMA系统Turbo交织器
Turbo编码器的结构是一个并行级联卷积码(PCCC),包括一个2分支8状态编码器和一个Turbo码内交织器。其结构图如图1所示。
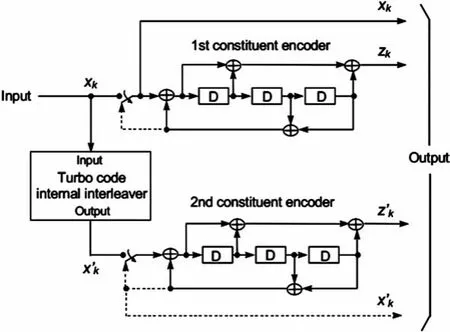
图1 码率1/3的Turbo编码器结构
码内交织器作为Turbo编码器的重要组成单元,在译码过程中实用频率很高。因此,Turbo码内交织器的设计对整个Turbo译码器的性能起着至关重要的作用。
有别于LTE系统中的QPP码内交织器,TD-SCDMA系统中的码内交织器为传统的行列交织器,串行处理数据。其作用是重置输入序列的顺序,减小相关性。TD-SCDMA系统中的Turbo码内交织器的处理流程如图2所示。
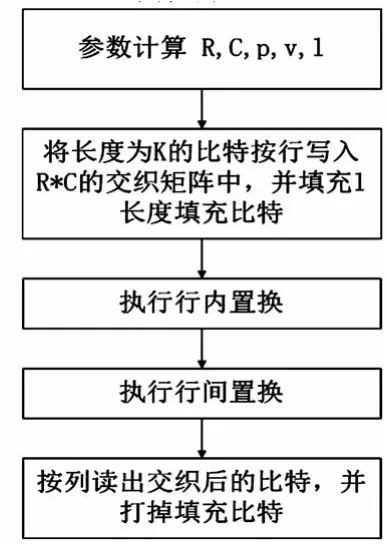
图2 Turbo交织器处理流程图
Turbo码内交织器的输入比特记为x1,x2,x3,…,xK,其中K是比特数目,取值为40≤K≤5114。Turbo码内交织器的输入比特与信道编码的输入比特之间的关系满足xk=Oirk且K=Ki。输入给Turbo码内交织器的比特序列按下列步骤写入交织矩阵中:
(1)确定方形矩阵的行数R,使满足:
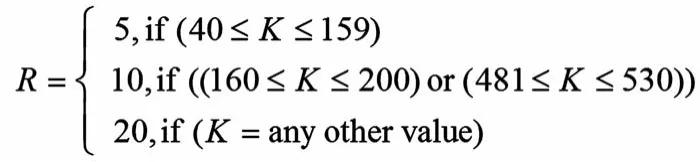
(2)确定行内置换所需的质数p,以及方形矩阵的列数C,使满足:
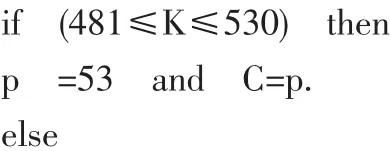
从表1中找到最小质数p,使得k≤R×(p+1),
并计算C使满足:
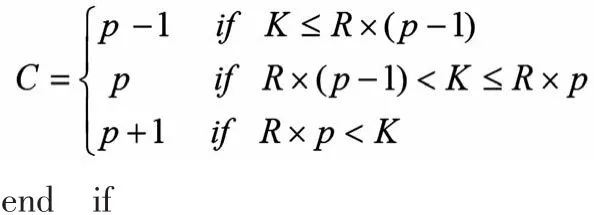
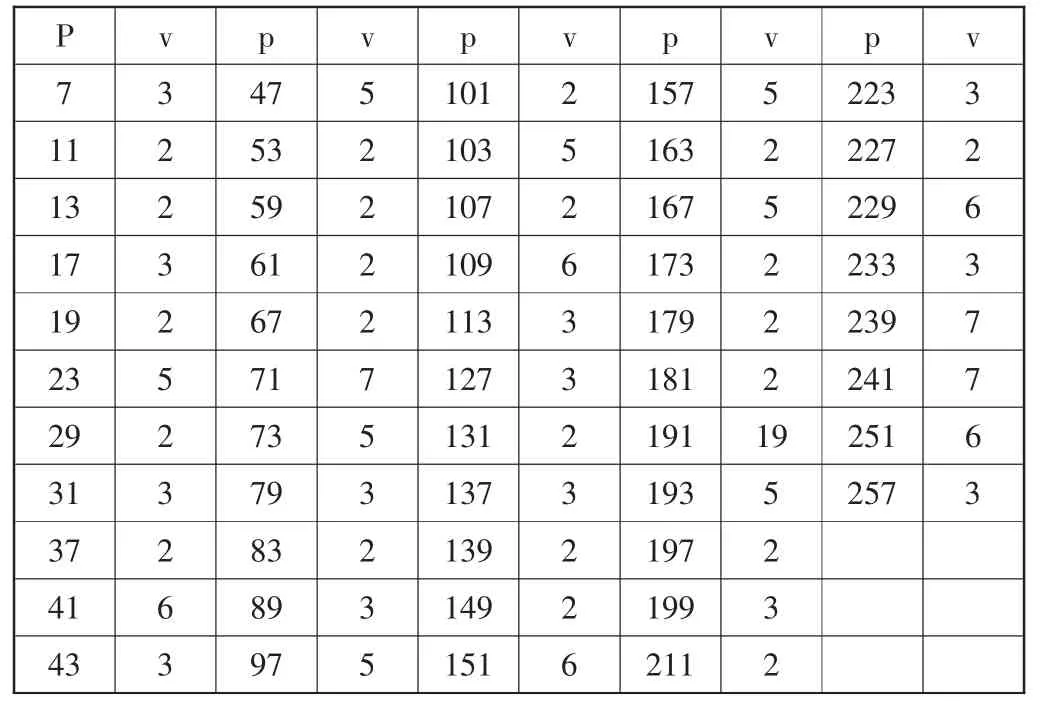
表1 质数p及相应原根v列表
(3)逐行将比特序列x1,x2,x3,…,xK写入R×C的方形矩阵中,首比特y1填入0行0列:
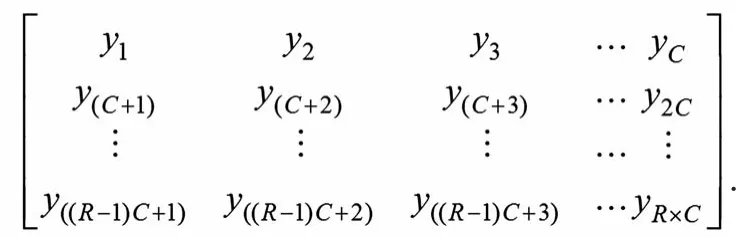
其中,yk=xk for k=1,2,…,K,并且如果R×C×K,则用填充比特yk=0or1,k=K+1,K+2,…,R×C填充。这些填充比特在执行完行内和行间置换之后,从交织矩阵中删除而不输出。
(4)根据不同的输入长度K确定不同的行间置换模式以及行内置换模式。
(5)逐列将比特输出,并删掉填充比特。
2 算法设计
在算法设计时,根据协议以及具体的实现中存在的问题,针对一些计算量较大的序列提出了以下的优化算法。
2.1 针对s序列的优化
协议中规定s序列为:首项s0为1,对于j=1,2,…,p-2,有s(j)=(v×s(j-1))modp。整个Turbo译码器中只有在交织器的s序列和U序列计算中用到模除,所以可以通过减法运算替代代价较大的模除运算。由于每次运算的减法次数一定小于v值,例如v=5时最多做4次减法,所以可以对v=19的情况进行存表,表格含189个数,而对于其他的6种v值,设计以下针对正数的模除运算mod(a,b)=c:
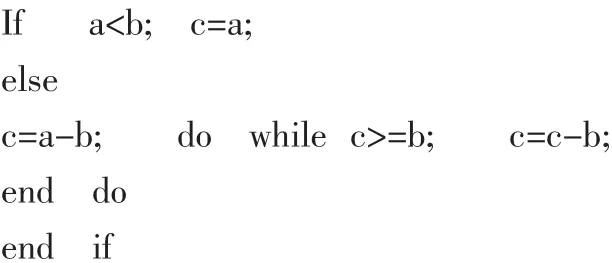
通过减法运算化简了模除运算。除去v=19的情况外,其他所有v值对应的s序列共存在6 105种计算,每次模除需要用到的减法次数统计如表2。
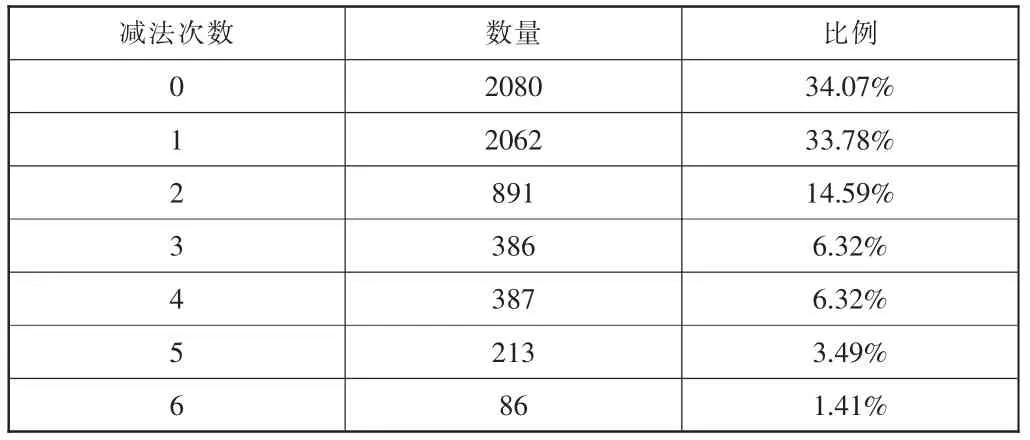
表2 不同减法次数的统计
通过表格可以看到,不做减法直接求得结果的比例占1/3还多,而需要多次减法运算的概率却非常小,例如6次减法运算的比例只占到1.41%。另外,根据遍历测试可以发现,在实际运算中,对于v=V的情况,一定存在减法次数n=V-1的运算。这也方便了对不同v值的时序规划。在之后Uij的计算和填充比特删减操作时用到的模除计算减法量也非常少,同时都为正数模除,都可以利用这个算法代替,不在赘述。
2.2 针对q序列的优化
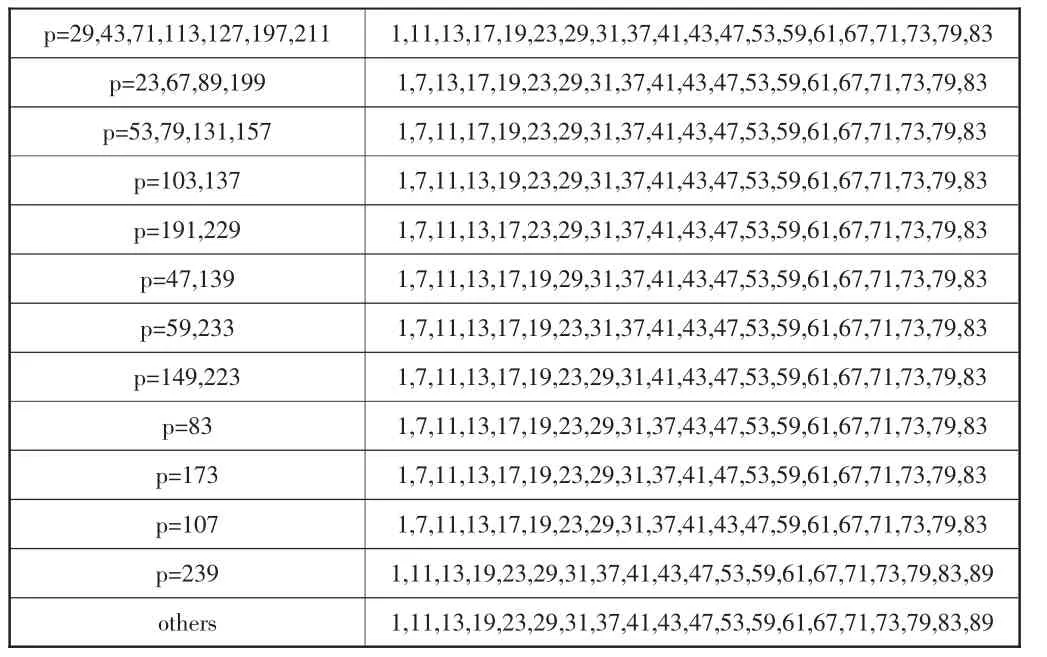
表3 质数p及相应q序列列表
协议中规定q序列为:首项q0为1,第二项大于6的递增素数序列,其中对于i=1,2,…,R-1,有g.c.d(qi,p-1)=1。严格按照协议进行算法设计将需要使用g.c.d函数,由于g.c.d函数使用频率非常低,在整个Turbo译码器核中,仅在TD-SCDMA系统的码内交织器计算q序列时需要。如果将所有的p值对应的q序列进行存表,将得到52*20的表格,开销也很大,所以考虑将不同p值对应的q序列进行分类归纳,部分存表,使用时根据p值查表即可:
2.3 针对填充比特删减的优化
根据协议规定,填充比特的数量l根据交织矩阵的大小RC减去输入的比特长度K而决定,并附在输入比特的尾部按行填入交织矩阵中。执行完交织操作后将删掉填充比特,按列输出信息比特。由于交织后比特将乱序,如何确定填充比特的位置进行正确的删减操作是个问题。最初考虑利用交织矩阵Uij作为标识矩阵,将填充比特设为区别于0和1的其他数,交织矩阵输出时参照Uij进行判定,但是考虑到硬件面积和实现难度,放弃了这种设计。
通过分析交织规律发现,根据填充比特的长度,可以确定交织前行号不小于l_int=ceil(l/C)的行内含有填充比特,其中行号大于l_int的行中全部为填充比特,而行号等于l_int的行中部分为填充比特,且这一行的填充比特数目为l_dec=l%C。所以在输出时,可以根据以下判断条件进行判断:
((T[i]<R-l_int)||((T[i]==R-l_int)&&(U[T[i]][j]<C-l_dec)))
若满足该条件,判定为非填充比特,输出;若不满足该条件,则判定为填充比特,跳过。
3 测试
码内交织器的一致性测试可以通过安捷伦公司的产品Advanced Design System进行测试,选取3GPP的标准Turbo码内交织器进行数据比对,仿真链路的搭建如图3所示。
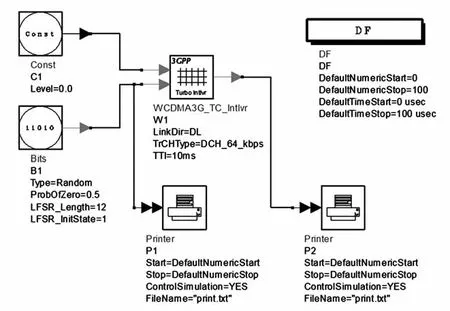
图3 ADS中Turbo码内交织器仿真链路搭建
4 结束语
本文通过算法的优化设计以及RTL代码对算法的仿真,确定了TD-SCDMA系统中Turbo码内交织器的优化算法,在硬件加速器实现时,减少了硬件开销并提高了效率,对整个TDSCDMA系统有很大的实用意义。
[1]BerrouC,GlavieuxA.NearOptimumErrorCorrecting Coding and Decoding:Turbo Codes.IEEE Trans.Commun,vol.44, 1996,(10):1261~1271.
[2]3GPP TS 25.222 V10.2.0 3rd Generation Partnership Project.Technical Specification Group Radio Access Network,Multiplexing and Channel Coding(TDD)(Release 4).2011-12.
[3]李小文.TD-SCDMA第三代移动通信系统、信令及实现[M].北京:人民邮电出版社,2003:110-115.
TN929
A
1003-5168(2014)04-0013-02
猜你喜欢
美食(2022年2期)2022-04-19
女报(2019年3期)2019-09-10
成都信息工程大学学报(2018年4期)2019-01-23
成都信息工程大学学报(2018年6期)2018-03-21
海峡姐妹(2017年10期)2017-12-19
时代英语·高一(2017年5期)2017-11-14
三联生活周刊(2017年33期)2017-08-11
银行家(2017年1期)2017-02-15
华人时刊(2016年17期)2016-04-05
电视技术(2014年17期)2014-09-18
