
基于CUDA的三维数据场可视化加速技术研究
2014-06-15 06:06朱奭
常熟理工学院学报 2014年2期
朱 奭
(常熟理工学院 计算机科学与工程学院,江苏 常熟 215500)
三维数据场的可视化从提出以来经历了20多年的发展,在科学研究,医学,石油勘探等领域得到了广泛的应用.其技术主要分为面绘制和体绘制两种.其中面绘制通过将三维数据构造中间几何面,然后用传统的计算机图形学技术绘制这些几何面实现;而体绘制是直接由三维数据场产生相应的二维图形,故又称为直接体绘制技术.后者的优势在于能够很好的展示物体的全貌以及内部的细节,但是也带来了庞大的计算量.传统的基于软件的方法,由于数据及计算量的庞大,很难达到实时绘制的要求.虽然提出了不少的基于软件的加速技术,比如不透明度提前终止,空体元的跳跃技术,视见变换的优化等,但还是受制于硬件的瓶颈,加速效果有限.随着硬件技术的发展,体绘制开始寻求硬件加速的方法.随着图形硬件处理器GPU的出现,GPU独有的可编程管线技术使得可视化的部分工作可以使用GPU完成,减轻了CPU的负担,提高了可视化的速度;随着GLSL,HLSL,CG等高级着色语言的出现,进一步提高了GPU的可编程性.基于GPU的体绘制方法得到了更好的发展.
CUDA编程模型的出现,实现了在不需要借助图形学应用程序编程接口的条件下,通过类C高级语言直接操作GPU的硬件资源,并行处理数据,大大提高处理速度.目前,国内对CUDA技术的研究处于发展阶段,也提出了基于CUDA的一系列直接体绘制的加速技术.本文通过对实现三维数据场可视化的光线投射算法进行优化和改进.通过将体数据以三维纹理的形式存储在显存中,利用CUDA的并行运算能力处理数据,在图形处理的几何阶段加速数据的处理,实现图形绘制的加速.
1 算法设计
1.1 CUDA架构下的光线投射的设计
CUDA是一种将GPU作为数据并行计算设备的软硬件体系,其编程模型的核心是Grid,Block,Thread三层结构,以线程网格的形式组织,每个Grid由若干个线程块(Block)组成,每个Block又由若干个线程(Thread)组成.
光线投射是从图像的每个像素,沿着固定的方向(通常是视线方向)发射一条光线,光线穿越整个图像序列,并在这个过程中,对图像序列进行采样获取颜色信息,同时依据光线吸收模型将颜色值及不透明度进行累加,直至光线穿越整个图像序列.将所有像素点的颜色拼接起来,就得到一副完整的可视化图像.
光线投射算法中每个像素出发,沿着固定方向发射的光线之间的计算过程是相互独立的,计算方式是相同的,具有高度的并行性.可以根据其特点,利用CUDA下的每个Thread完成,整个屏幕看成一个Grid,每个像素看成一个Thread,根据区域特点屏幕划分为若干区域,每个区域看成一个Block,由此将光线投射法利用CUDA的三层架构进行实现,通过CUDA强大的并行运算能力,提高绘制速度.
1.2 算法设计
算法主要分为两个组成部分,一个是CPU部分(Host部分);另一个是GPU部分(Device部分).
CPU上的工作主要是读取三维数据文件,并存储在内存中,OpenGL环境的初始化,并建立与显存之间的联系.接收GPU返回的最终结果,并进行显示.
GPU上的工作主要就是进行光线的遍历及与数据场求交,进行颜色及不透明度的累积计算,并将最终累积结果返回内存.
具体的算法步骤如下:
CPU上的算法步骤:
(1)读取三维数据场raw文件为一个个unsigned char阵列,存储在device memory中.
(2)OpenGL环境的初始化,建立PBO(OpengGl像素缓存对象),PBO与GPU显存之间的绑定;设置模型变换矩阵,设置视线方向.
(3)根据数据场大小,计算CUDA所需的Block及Thread的大小.
GPU上的算法流程:
(1)CUDA环境的初始化,建立CUDA 的3D Array及3D Texture,device memory中的三维数据场数据读入3D Array,设置纹理参数,并将3D Textrue和3D Array进行绑定.
(2)设定前置参数,根据线程索引计算对应的屏幕像素位置,视点坐标.
(3)采用包围盒法,根据射线方向,分别求出光线进入数据体和离开数据体的交点坐标pin、pout及和相机的距离.
(4)由前往后,沿射线方向依次按照预设的采样间距进行采样,得到采样点的颜色和不透明度,按照由前往后的方式进行累加合成.并利用不透明度提前截止,若不透明度值接近1.0,停止计算;否则继续采样下一个点,直到到达离开点为止.
(5)将最终累加的颜色和不透明度值写入PBO.
至此,GPU上工作完成,CPU再通过OpenGl环境下的API,直接将PBO中的数据在屏幕上显示.
1.3 线程映射及前置参数设计
线程映射是将任一光线与CUDA中的Thread进行绑定,实现光线的并行遍历,是光线投射法并行化处理的关键.利用CUDA的四个内建变量,gridDim,blockDim,blockIdx,threadIdx进行控制.其中前两个内建变量表示了网格和线程块的规模,用来计算线程的起始位置,后两个内建变量表示线程块的编号和线程的下标,通过两者的结合表示并行计算线程单元.通过线程索引来对每一条光线编号,线程索引号index通过公式(1)计算.
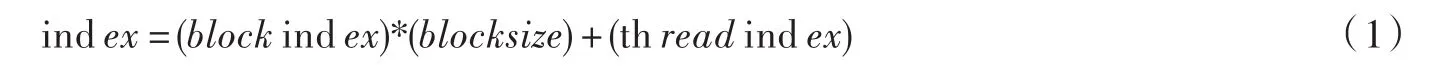
Index有x,y两个分量,为了后面计算的方便,利用公式(2)、(3)将其规范至区间[-1,1].


其中imageW与imageH代表视平面的宽度与高度.
为了将成像范围进行约束,采用单位包围盒,并对视平面大小及视点位置进行初始化规划,如图1所示.其中视点置于z轴(0,0,4)位置,视平面位于(0,0,2)大小2*2单位.Box为单位包围盒.

图1 空间关系图
1.4 光线求交及颜色和不透明度积累
光线投射算法流程的最后是图像合成,通过沿着某一光线计算出该方向上每一点的颜色和不透明度值,并将其累加起来合成图像.首先进行光线的求交运算,对任意一条光线,利用向量表示法对其进行描述,为其设置两个最基本的参数,起点坐标(ori⁃gin)和视线方向(direction),则任意一条光线可以表示为公式(4),其中t表示光线在视线方向上的位移.

光线与包围盒求交采用G.Scott Owen提出的方法,求出一条光线和包围盒的两个交点pin和pout,然后以pin为起始点,以pstep为间距沿着视线方向步进.每前进一步,通过公式(5)计算出光线上的某个采样点在空间中的坐标.
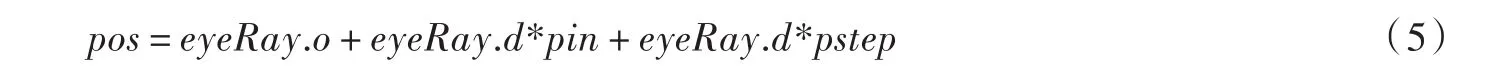
式中eyeRay.o是光线的起始坐标,eyeRay.d*pin是光线入点的坐标,eyeRay.d*pstep是光线的步进距离.由于该坐标位于包围盒中,坐标值介于(-1,-1,-1)和(1,1,1)之间,通过转换,将坐标值转换至纹理坐标[0,1]范围内.这样,根据点的坐标值,提取相应纹理坐标的纹理值,即为该点的灰度值,然后进行不透明度和色彩的累加.色彩和不透明度的合成采用由前往后的合成方法,利用公式(6)、(7)分别进行颜色及不透明度累积.
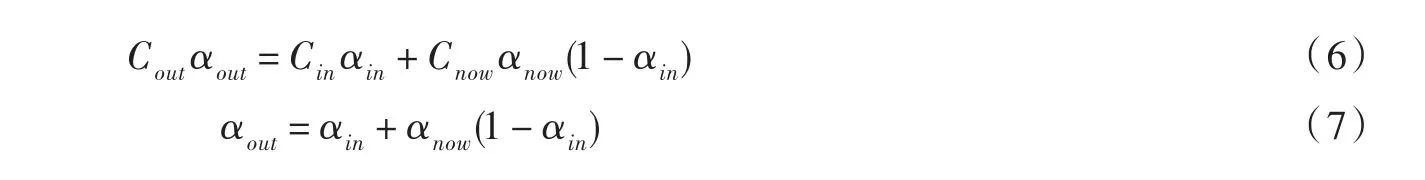
其中C为颜色值,α为不透明度值.在合成过程中采用不透明度提前终止,若不透明度已经达到1,则其后的体元不进行累积,节省计算时间.最后将累加的结果直接写入PBO中,形成图像,在屏幕上显示.
2 实验结果及分析
对上述算法,在硬件系统为Intel Core2双核 T5550 CPU,2GB DDRII内存,NVIDIA GeForce 8400M GS,512MB显存,操作系统Windows XP,开发环境VC++6.0和CUDA SDK3.1,OpenGL3.1库下实现三维数据场并行可视化,并与基于GPU的光线投射算法进行比较.采用两种不同分辨率的数据场分别进行测试,数据场的具体参数如下表1所示.

表1 实验数据场基本信息表
2.1 实验结果
图2为对64*64*64的正方体盒重建的效果,图2a为利用本文算法重建的效果,图2b为利用基于GPU的算法重建的效果.从成像效果上看,前者细节的重建效果更好,并且渲染速度达到了10.1fps,满足交互性要求.
图3为对256*256*256的头部MRI体数据进行重建,图3a为本文算法重建效果,图3b为基于GPU的算法重新的效果,在成像效果上图3a对大脑内部器官的细节表现的更好,渲染速度达到了8.7fps,基本满足交互性要求.通过对两个数据场采用不同算法进行重建的结果分析,本文算法在重建图像的细节效果上更优,并且重建图像基本满足交互性要求(fps)6,即满足交互性.成像效果的优化,主要在于在进行数据滤波上采用了归一化线性滤波;另一方面,在体绘制传递函数上进行了适当的优化处理.
2.2 性能分析
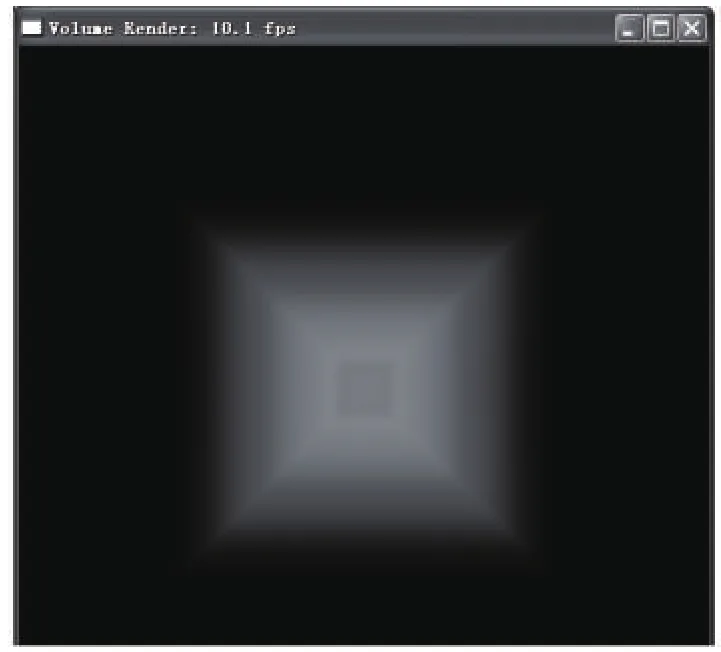
图2 (a)基于CUDA的正方体盒
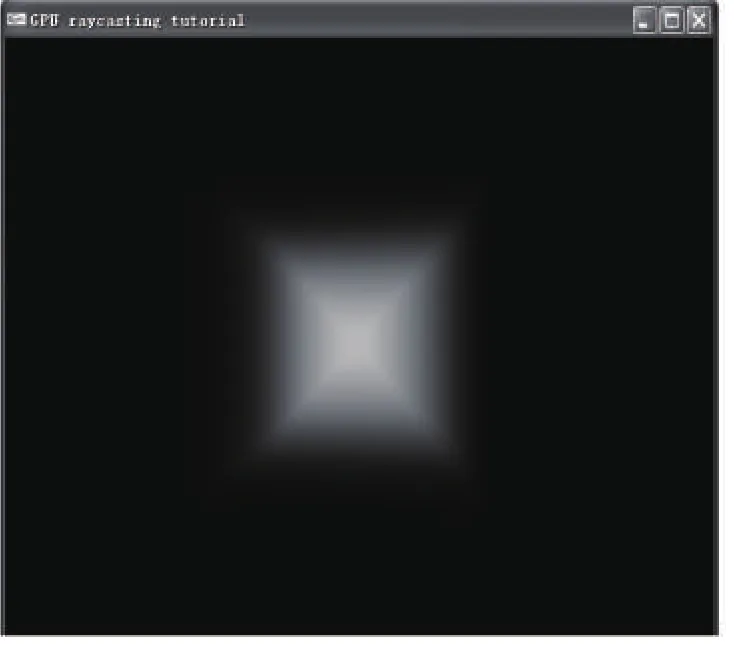
图2 (b)基于GPU的正方体盒重建
表2列出了两组数据场在相同硬件环境下用不同的算法实现所需的时间及加速比的统计情况.从表中看到,基于CUDA的光线投射算法在绘制时间上有明显的提高,以正方体盒数据为例,基于GPU的算法绘制时间为0.68 s,基于 CUDA的算法绘制时间为0.089 s,其加速比达到了7.64.对于MRI人体头部数据场,加速比有所降低,主要是数据场的分辨率提高及数据场数据量增大后,绘制的时间及计算量增加,不过加速比还是在7左右.从实验的结果来看,基于GPU算法的加速效果,体现了图形芯片单指令多数据流处理的特点及CUDA架构并行处理的优点.在以后的实验中,要充分利用该优势.

图3 (a)基于CUDA的MRI人体头部重建
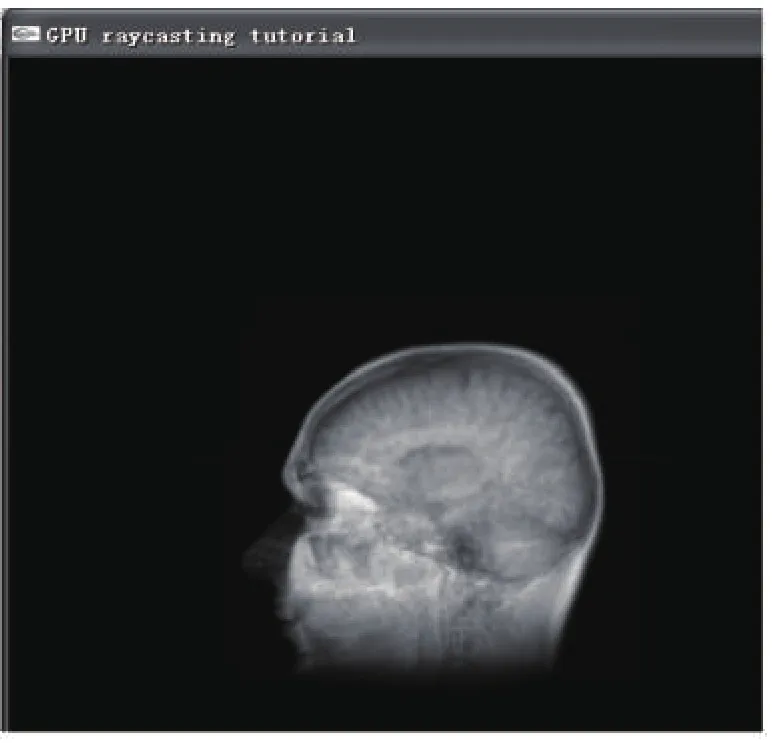
图3 (b)基于GPU的MRI人体头部重建

表2 绘制时间和加速比
3 结论
本文利用CUDA架构的并行技术及可编程硬件技术,采用光线投射算法进行三维数据场可视化的研究.通过与基于GPU的光线投射法在相同环境下对同一组数据场进行测试,从成像的效果,绘制的时间两个方面进行对比,由于CUDA架构具有并行的特点,在绘制上优势明显,具有较高的加速比.在成像效果上,本文算法能更好的展示细节.后期工作是如何改进传递函数,对感兴趣的数据突出显示,以及在交互性上有更好的提高.
[1]张舒,褚艳利.GPU高性能运算之CUDA[M].北京:中国水利出版社,2009.
[2]仇德元.GPGPU编程技术--从GLSL、CUDA到OpenCL[M].北京:机械工业出版社,2011.
[3]石教英,蔡文立.科学计算可视化算法与系统[M].北京:科学出版社,1996.
[4]唐泽圣.三维数据可视化[M].北京:清华大学出版社,1999.
[5]徐赛花,张二华.基于CUDA的三维数据并行可视化[J].CT理论与应用研究,2011,20(1):47-54.
[6]SCHERLH,Keck B,Kowarschik M,et al.Fast GPU-based CT reconstruction using the Common Unified Device Architecture(CU⁃DA)[C]//IEEE Press.Proceeding of Nuclear Science Symposium and Medical Imaging Conference.Washington,DC:IEEE Press,2007:4464-4466.
[7]董现玲,江贵平,张煜.基于CUDA的快速光线投射法[J].北京生物医学工程,2010,29(2):125-129.
[8]毕文元,陈志强,张丽,等.基于CUDA的三维重建过程实时可视化方法[J].CT理论与应用研究,2010,19(2):1-8.
猜你喜欢
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
幼儿画刊(2019年6期)2019-11-04
中外文摘(2019年8期)2019-04-30
消费导刊(2018年10期)2018-08-20
环球市场(2017年36期)2017-03-09
系统工程学报(2015年3期)2015-02-28
现代企业(2015年5期)2015-02-28
现代企业(2015年5期)2015-02-28
计算机教育(2006年4期)2006-04-19
