
基于CK810处理器的汇编链接时优化
2014-06-07 05:53卢永江
计算机工程 2014年11期
胡 敏,卢永江,刘 兵
(浙江大学超大规模集成电路设计研究所,杭州310027)
基于CK810处理器的汇编链接时优化
胡 敏,卢永江,刘 兵
(浙江大学超大规模集成电路设计研究所,杭州310027)
提出基于CK810处理器的16/32位混编指令集汇编链接时优化技术。利用汇编输出二进制文件,根据CK810处理器的16/32位混编指令集中指令及操作数的特征,动态选择指令的编码方式,实现对指令relax,最大程度地提高了程序的代码密度。对于在汇编时不能确定编码方式的指令,通过留出重定位的方式,由链接时完成优化。在链接时,利用信息的确定性,实现对整个程序的压缩和指令的替换,使得程序执行效率更高,代码占用空间更小。汇编链接时优化技术克服了传统编译器只限于一个模块优化的缺点,把优化范围扩展到整个程序,实现了跨模块的优化,使得基于CK810处理器的程序代码密度平均提高7.52%,性能平均提升7.91%。
汇编优化;链接优化;动态编码;重定位;压缩;替换
1 概述
在计算机系统中,现今16/32位混编指令集架构已经成为主流。通常在 16/32位混合编码集中[1-2],32位指令用于提升指令集的运算性能,采用3操作数寻址模式,可以访问所有寄存器资源,具有寻址范围大的特点;16位指令是32位指令中出现频率最高的指令子集,用于提升指令代码密度,16位指令多采用两操作数寻址模式,只能访问部分寄存器资源,立即数寻址范围较小。为获得代码密度和性能提升的有机结合,对16/32位混编指令集的优化必不可少。目前,大部分对代码的优化主要集中在编译阶段[3-4],虽然文献[5-6]有对程序在链接时做过优化,但也是在对可执行程序重新反汇编和链接来达到优化,属于链接后的优化,不是本文所论述的汇编链接时优化,所以当前在汇编与链接时对代码优化几乎为空白。传统编译器是指通过词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成的编译翻译过程。这个过程通常的优化是对单个函数而言,并且是生成一个个独立不相关的汇编文件[7],即不能对整个程序进行优化,故传统编译器对16/32位混编指令集的编译优化存在3个不足:
(1)从文献[8]可知,传统编译器对程序的分析和优化一般都是限于单个函数和过程,损失了过程间的优化机会;
(2)从文献[9]可概括出,传统编译器无法获得整个程序的所有信息,在编译时无法获得指令和数据的地址信息;
(3)传统编译器不能决定指令是以16位编码还是以32位编码,而指令以何种形式编码是程序代码密度和性能优劣的关键因素,若指令本可以以16位形式编码却被编码成了32位的指令,无疑是浪费了代码空间;反之,若本该编码成32位的指令,却被编码成多条16位指令,性能则会受到影响。
针对传统编译器在16/32位混编指令集编译时存在的局限性,本文提出汇编链接时的指令编码优化方法。汇编时,运用relax优化机制,实现对指令动态选择的编码方式,以达到代码密度和性能的最优化;链接时,根据地址信息的确定性,提出链接时指令替换、空间压缩、地址索引优化和静态地址优化等优化策略。
2 16/32位指令混合编码的优化
2.1 汇编时relax优化
在针对16/32位混编指令集的汇编阶段,当指令在操作数确定的情况下,根据操作数个数和操作数是否超出16位指令编码范围来选择采用16位或32位指令。
如编码无符号加法指令addurz,rx(CK810指令,下同),当z和x的值落入16位指令的操作数范围时,采用16位指令编码,否则以32位指令编码。当指令的操作数不确定时,指令只能无条件编码成为32位的指令,这就可能导致代码密度的损失。为最大可能性对指令选择合适的编码方式,本文提出一种relax优化机制。relax机制是指,在编码阶段,把指令存放在一个个称为frag的缓冲区,在汇编某条指令时,当指令操作数不能确定时,把指令暂且编码成16位的指令,把这条指令作为当前frag的最后一条指令并预留出32指令的空间,之后开辟新的frag来存放接下来的指令,当再次遇到操作数不能确定的情况,重复上述过程。图1是CK810的汇编代码片段的汇编示意图。
在图1中,根据relax机制,在汇编bsr指令时,操作数label不能确定,把bsr指令编码成16位指令,结束当前frag1。在最后汇编输出的阶段,bsr指令与lable的距离为0x1f,满足16位指令的操作数范围,bsr编码成16位指令。
在引入relax机制时,在汇编输出阶段,若操作数的范围仍不能确定,则把指令编码为32位的指令,并留出重定位信息给连接器,在链接器中对指令再做优化。
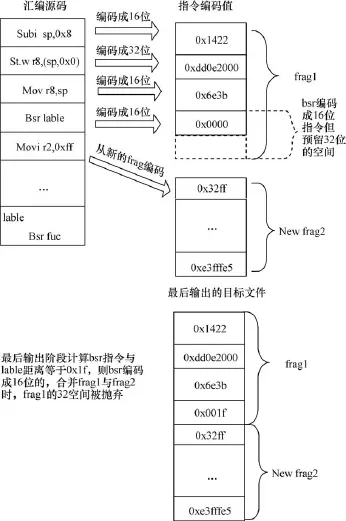
图1 汇编代码的过程示意图
图2是在IA64linux主机平台上,汇编目标处理器为CK810的测试结果(以下各个优化的环境相同)。测试实验采用标准的benchmark CSiBE,对其在没有引入relax和引入relax优化的一个代码密度进行对比。从图2可以看出,所有程序的代码密度都有提到,代码密度最低提高了 3%,最高提升6.38%,平均提升4.5%。
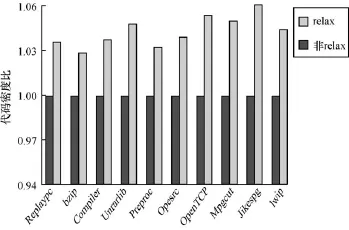
图2 relax优化代码密度对比
2.2 链接时压缩替换优化
利用链接时代码信息都确定的优势[10-11],可以对指令进一步压缩与替换。本文针对嵌入式CPU指令集的特征,引入下面3种压缩优化策略:
(1)把32位指令压缩成16位指令;
(2)把带常量池的指令替换成不需要常量池的指令;
(3)由上面2个压缩,引起新的压缩,即曾经PC偏移量超出指令编码的,由于递归压缩PC偏移量变小而可以在指令编码中编码。如绝对地址函数调用jsri指令,随着程序的不断递归压缩,使得可以用相对地址偏移函数调用bsr指令来替代,从而删除常量池,进一步提高代码密度和性能。
图3是链接时压缩替换的示意图。
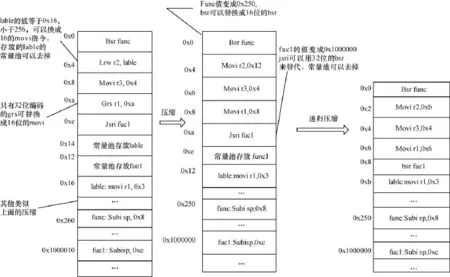
图3 链接时压缩替换的示意图
根据上述链接压缩示意图,通过对上述3种类型不断的递归压缩,使得程序代码密度都处于最优状态。图4是CSiBEbenchmark使用链接时压缩优化策略的代码密度对比图。从图中可以看出,利用链接时压缩优化,代码密度最高提升6.1%,平均提升4.6%。
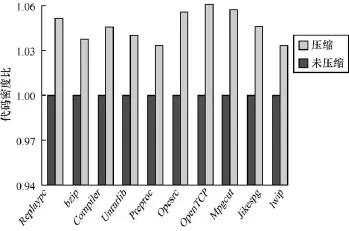
图4 压缩前后代码密度对比
2.3 地址索引优化
在load/store架构嵌入式CPU中,获取全局变量地址、函数地址或大立即数时,无法将立即数直接在指令中编码,需将立即数存放在相对当前PC偏移一段距离处(即常量池),再通过相对PC偏移内存寻址指令读取立即数(本文称其为“地址立即数装载指令”,如CK810的lrw指令)。在C语言的程序中,获得某个全局变量的值,或绝对地址函数调用随处可见,也就是说汇编代码会包含大量的“地址立即数装载指令”,通常在所有指令中占比为8%左右。大量的“地址立即数装载指令”势必会引起常量池的访问而导致性能和代码密度下降,一方面,“地址立即数装载指令”从常量池内存读取数据,频繁的内存读取增加了CPU和数据总线的开销,导致性能的下降;另一方面,“地址立即数装载指令”借助常量池来获得数据,大量常量池的存在,必定使得代码密度下降。
为此,本文提出一种名为“锚地址优化”的指令替换策略,把“地址立即数装载指令”替换成立即数加法指令,从而提高代码密度的同时提高性能。汇编时代码段或数据段基地址放在某个预留的寄存器rb中,通过加法指令计算“地址立即数装载指令”中的地址立即数,如CK810中采用汇编指令“addirx, rb,#offset”实现。在链接时,“地址立即数装载指令”中的地址立即数已经确定,#offset等于把目标地址减去代码段或数据段基地址rb。当程序执行时rx等于代码段或数据段基地址rb加上#offset,就是需要装载的地址立即数。通过“锚地址优化”的指令替换策略,不仅可以提高运行效率,也提高了代码密度。图5是通过CSiBEbenchmark使用“锚地址优化”的指令替换策略前后的性能比较图,从图中可以看出,通过静态地址优化策略,性能平均提升2.33%,最高提升3%。
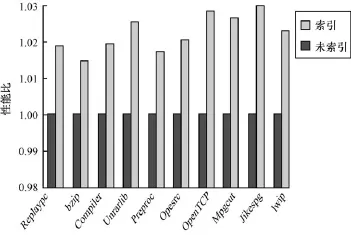
图5 指令替换策略前后性能对比
2.4 静态链接地址优化
在RISC架构嵌入式CPU中,绝对地址函数调用的目标地址立即数无法在指令中直接编码,需要借助常量池,使得函数的跳转范围在4 GB内。但是在嵌入式领域里,函数通常只需要在一个很小的范围内跳转,如果能把绝对地址函数调用指令替换成PC相对跳转指令,不仅能提高程序运行性能,而且还可以删除常量池,从而提高代码密度。基于这个思路,本文提出一种在静态链接时的函数调用优化策略,即在静态链接程序时[12],根据链接地址信息确定的优势,在重定位绝对地址函数调用指令的目标地址时,根据地址的范围,计算要跳转的地址与当前PC距离,若小于PC相对跳转指令的偏移范围(如CK810为前后64 MB偏移),则把绝对地址函数调用指令替换为PC相对跳转指令。
图6是CSiBEbenchmark使用静态链接地址优化策略的性能对比图。从图中可以看出,通过静态地址优化策略,性能平均提升 5.7%,最高提升6.5%。
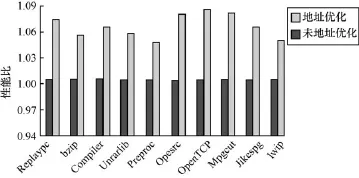
图6 静态链接地址优化策略性能对比
3 实验与结果分析
实验平台以GCC4.5.1为编译器,实验的Case采用标准的benchmark CSiBE,通过编译器编译出汇编目标文件,再通过汇编链接优化生成目标程序,使目标程序运行于小端的CK810处理器上,对CSiBE使用所有的优化手段和不使用任何优化策略,来比较整体的优化效果。
从图7和图8可以看出,对程序使用所有的优化策略,代码密度最低提高也有6.12%,最高可达到11.06%,平均提升 7.52%;而性能最低提升有5.8%,最高有11%,平均提高7.91%。对程序使用所有的优化策略,并不是简单的每个优化策略之和相加,这是因为一些优化策略,比如压缩优化和地址索引优化,在地址索引优化中,有压缩优化的功能。另外,在压缩优化时,随着指令的替换与压缩,性能会所有提高。所以所有的优化放在一起,会比单个优化的效果更好,但不是每个优化的相加。
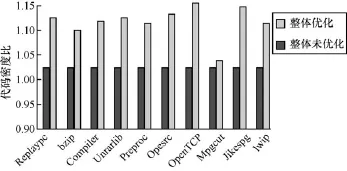
图7 优化前后代码密度对比
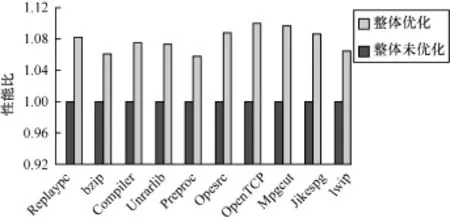
图8 优化前后性能对比
4 结束语
根据嵌入式16/32位混编指令集特征,在兼顾性能和代码密度的情况下,本文充分利用编码特性和链接后信息的确定性,对基于16/32位混编指令集在汇编链接时做出优化,取得较好的效果。另外,在实验过程中,还发现在汇编链接时,仍有其他优化空间。如寄存器编码优化,对整个函数过程进行寄存器生命周期分析,对寄存器进行重分配,尽量采用低编码寄存器,使得指令尽可能用16位进行编码;再如,对常量池重新排序,使得存放同一个变量的常量池合并,把分散在程序中的常量池尽量集中在一起,达到共享常量池的作用,提高代码密度。
[1] Bunda J,Fussell D,Jenevein R,et al.16-bit vs.32-bit Instructions for Pipelined Micro-processors[C]//Proceedings of the 20th Annual International Symposium on Computer Architecture.[S.l.]:IEEE Press,1993:237-246.
[2] Gupta A R.Enhancing the Performance of 16-bit Code Using Augmenting Instructions[C]//Proceedings of ACM SIGPLAN Conference on Languages Compilers.[S.l.]:ACM Press,2003.
[3] 刘 博,李蜀瑜,阮 园.一种面向CoSy编译框架的编译优化开发方法[J].计算机技术与发展,2013,23(3): 61-64.
[4] 张茉莉,杨海钢,刘 峰,等.针对递归函数的高级综合编译优化算法[J].计算机辅助设计与图形学学报, 2013,25(10):1557-1565.
[5] 陈 瑜,朱晓静,邹 琼.龙芯链接后优化器设计与分析[J].计算机研究与发展,2006,43(8):1450-1456.
[6] 陈 瑜.龙芯2号链接后优化器的实现与分析[D].北京:中国科学院计算技术研究所,2004.
[7] Li D X,Ashok R,Hundt R.Lightweight Feedbackdirected Cross-module Optimization[C]//Proceedings of the 8th Annual IEEE/ACM International Symposium on Code Generation and Optimization.[S.l.]:ACM Press,2010:53-61.
[8] Liu Xianhua,Zhang Jiyu,Cheng Xu.Efficient Code Size Reduction Without Performance Loss[C]//Proceedings of ACM Symposium on Applied Computing.[S.l.]: ACM Press,2007:666-672.
[9] Bus B,Kaster D,Chanet D,et al.Post-pass Compaction Techniques 2003[J].Communications of the ACM, 2003,46(8):41-46.
[10] Phela R.Improving ARM Code Density and Performance[EB/OL].(2003-05-07).http://www.cs.uiuc.edu/ class/fa05/cs433ug/PROCESSORS/Thumb2.pdf.
[11] Sutter B.Link-time Binary Rewriting Techniques for Program Compaction[J].ACM Transactions on Programming Languages and Systems,2005,27(5): 882-945.
[12] Jones T M,BartoliniS,Maebe J,etal.Link-time Optimization for Power Efficiency in a Tagless Instruction Cache[C]//Proceedings of the 9th Annual IEEE/ACM InternationalSymposium on Code Generation and Optimization.[S.l.]:IEEE Press,2011:32-41.
编辑 顾逸斐
Assembly and Link Time Optimization Based on CK810 Processor
HU Min,LU Yongjiang,LIU Bing
(Institute of Very Large Scale Integrated Circuits Design,Zhejiang University,Hangzhou 310027,China)
According to feature of 16/32 bit mixed instruction set of CK810,assembly and link time optimization techniques based on the 16/32 mixed instruction set of CK810 make use of assembler output binary files to achieve instructions relax and coding instructions dynamically.The assembler gives relocations to linker for instructions that can' t decide how to code at assembly time,the techniques fully utilizes the information only available at link time to realize of the entire program for compression and replacement of instructions to make program more efficient and small.Assembly and link optimization techniques overcome the limitations of traditional compilers by enlarging the optimizing scope from a single function or a module to the whole program,making the code density on CK810 increase an average of 7.52%, the average performance improvement of 7.91%.
assembly optimization;link optimization;dynamic coding;relocation;compaction;replace
1000-3428(2014)11-0250-05
A
TP313
10.3969/j.issn.1000-3428.2014.11.050
国家“863”计划基金资助项目(2009AA011706)。
胡 敏(1987-),男,硕士,主研方向:嵌入式系统;卢永江,副教授、博士;刘 兵,硕士研究生。
2013-10-25
2014-01-06E-mail:zju21110143@163.com
中文引用格式:胡 敏,卢永江,刘 兵.基于CK810处理器的汇编链接时优化[J].计算机工程,2014,40(11):250-254.
英文引用格式:Hu Min,Lu Yongjiang,Liu Bing.Assembly and Link Time Optimization Based on CK810 Processor[J].Computer Engineering,2014,40(11):250-254.
猜你喜欢
——卡文迪什测定万有引力常量
农村青少年科学探究(2022年5期)2022-08-16
铁道通信信号(2020年7期)2020-02-06
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
西藏科技(2015年1期)2015-09-26
组合机床与自动化加工技术(2014年10期)2014-03-01
衡水学院学报(2011年4期)2011-12-22
单片机与嵌入式系统应用(2010年2期)2010-07-02
