
基于图形分析方法的函数型数据异常值检验实证研究
2014-05-12 10:22米子川
统计与信息论坛 2014年6期
米子川
(山西财经大学 统计学院,山西 太原 030006)
基于图形分析方法的函数型数据异常值检验实证研究
米子川
(山西财经大学 统计学院,山西 太原 030006)
函数型数据本质上是一种复杂数据,其抽样、生成、结构和关联程度都会影响到数据的复杂性和描述性,有些情形甚至连基本的可视化描述都成为难点。在利用函数型数据的主成分得分、图基的数据深度和密度概念的基础上,引入函数型数据的打包图和箱线图,并针对函数型数据的图形分析提出了函数型数据异常值检测的三种方法。与已有的检测方法相比较,所提三种方法更易于识别函数型数据的异常值。
函数型数据;图形工具;异常值检测
一、引 言
从数据生成的过程看,统计数据大致可以划分为两类,即简单数据和复杂数据。简单数据内涵小而外延大,如电子监控视频、手机通话记录、网络日志、图片、地理位置信息等,这些数据的各种集合现通常被称之为大数据,大数据的基本单元从本质上看就是一类简单数据,是非结构化和半结构化的数据;复杂数据一般来源于人们对统计数据产生过程的干预和设计,如抽样技术、工业控制过程、人口普查等有目的的数据搜集过程而产生的数据,这都可看做是复杂数据,复杂数据内涵丰富而外延则相对简单。
函数型数据本质上就是复杂数据,因为通过现有的统计手段所获取的信息往往是一个不连续的、片段的、离散的有界有序有经济意义的数列,这类数据的结构复杂,内涵丰富,而且数据的生成过程不是简单的自然产生过程,大部分情况下是由人为主动干预所形成的。随机抽样、专项调查、官方统计制度等手段都会增加数据的复杂度,因而函数型数据从抽样、生成、结构和建模都体现出了复杂性,是一类具有重要意义和价值的统计数据。
近年来,函数型数据分析的应用领域正在不断扩大,从自然科学到社会科学、从静态数据到动态数据、从普查数据到抽样数据,人们都在寻找利用函数型数据方法进行分析和检验的基本路径。对于复杂的函数型数据而言,发现一种简单的描述工具就显得尤为重要。
可视化方法有助于发现一些用数学模型和描述性统计方法无法得到的特征,然而到目前为止,该方法在函数型数据的相关文献中并未得到广泛的关注和认同。大多数文献仅关注于函数型数据的建模、聚类和预测,而对可视化方法及异常值的检验不够重视。在查阅到的大量文献中,讨论函数型复杂数据可视化方法的文献为数不多,但其中不乏精品。一种情况是加拿大麦吉尔大学教授Ramsay等人的相平面图和澳大利亚莫纳什大学教授Hyndman等人的地毯图(意为类似地毯构图中依据某种图案进行的有边界的渲染效果),这两类图从函数型数据的一阶和二阶导数中得出了显著的重要分布特征[1]254-255[2];另 一 种 情 况 是 美 国 普 渡 大 学 教 授Zhang等人的异常值分解图,旨在展示当样本量及维数增加情况下潜在组成部分的变化[3]。这一类统计图形方法的好处就是能检测函数型数据中的异常值,通常这些异常值在最初的简单数据描述图中并不明显,偏离的曲线要么可能位于大量数据范围之外(称为“位置异常”),要么可能在数据范围之内,但相对于其他曲线有不同的形态(称这些点为“分布异常”),而这些偏离的曲线更多情形是上述两个特征的混合。
异常值的存在对函数型数据的建模和预测有严重的影响,如果对异常值不进行处理,统计分析经常会导致不精确的结论。尽管此问题如此重要,但对于函数型数据异常值的检测也仅有两种方法。一种是Hyndman等人的基于稳健型主成分分析的方法[4];另一种是Febrero等人的基于连续似然比检验和平滑自助法所进行的函数型异常值检测[5-6]。
二、函数型数据图形描述方法综述
数据平滑方法是函数型数据图形化描述的基本工具。对于一组面板数据,当使用数据平滑方法在同一个坐标系内绘出同一个指标不同时间点的拟合曲线,而且这些曲线依照时间顺序以不同的颜色排列,就形成了类似雨后彩虹一样的图形,称这个图形为彩虹图。
Hyndman使用惩罚样条插值法,对1899年到2005年间法国特定年龄段男性的死亡率曲线形成的彩虹图数据进行了平滑处理,得到一个形似彩虹的图形[7]。
本文采用1991—2013年的中国上证指数统计数据,使用惩罚样条插值法对每个交易日的收盘价和总的交易金额作彩虹图,从1991年开始到2013年9月25日的数据依照不同颜色顺序排列形成了一组彩虹图。由于2007年和2010年中国股市的两次暴涨暴跌,使图形看起来没有形成一个完整的彩虹形状,但色谱同样逐次排列的光滑曲线在时间不断重复的条件下,仍形成了函数型数据的彩虹图(见图1)。
同时,还可基于数据深度、数据密度或其他特性顺序作彩虹图。由于曲线在很多取值上重合,很难识别平均曲线的位置或者大多数曲线的下降位置,当异常值被曲线其他特性混淆时(例如某一段上的曲线形状与其他部分很不相同)则很难识别。对于单变量数据,通常用箱线图来解决上述问题,而本文的目的是以箱线图的形式定义函数型数据的变动,这种箱线图可以给出偏离曲线、一条中心线和一个包含曲线中间50%部分的区域。
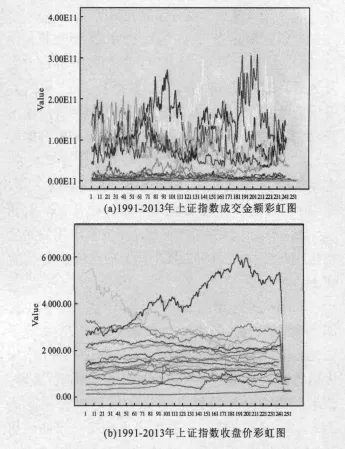
图1 上证指数收盘价和成交金额彩虹图
图1是以上证指数收盘价和成交金额等自然指标进行的排序,这样的排序在函数型数据的分析上缺乏新意,很难从中发现统计规律。在函数型数据研究的文献中,很多研究者采用不同的思路进行数据排序的尝试,如可利用稳健主成分方法计算出每个时间点的主成分得分,并以此排序形成彩虹图。
几乎所有针对函数型数据的作图方法都涉及到对函数型数据的排序。图1中的数据是基于时间排序,然而对于很多数据集以数据本身潜在的价值来排序,似乎是更好的选择。
关于函数型数据的很多排序方法都使用了数据深度或者数据密度的概念,这些方法揭示了给定的函数型数据的观测值及其潜在分布的“深度”或“密度”的情形[8-9]。一般情况下,一个深度函数或密度函数的轮廓图可以用来展现多变量数据的可以看得见的形状和结构特征。
(一)函数型数据深度的测度方法
Febrero等人提出了一种基于函数型深度概念的异常值检测方法,其基本定义为:

其中对于给定的x值,D(yi(x))是对其深度的度量函数。在这个定义下,通过一个不断增加的o{}i序列来定义曲线的顺序,因此接近x轴的第1条曲线的函数型数据深度最小,而最后一条的最大。
(二)二元主成分得分深度的测度
对多变量函数型数据进行主成分分析,设{φk(x)}为主成分,{zi,k}是对函数型数据进行主成分分解后的主成分得分。原始数据 {yi(x)}中的大量信息可以由少数的前几个主成分及其得分反映出来。大多数情形下,对于一些经济或自然观察数据而言,少数几个主成分得分往往可以积累超过80%的方差贡献率,这也正是主成分分析的优点之一。因此,将 考 虑 前 两 个 得 分 向 量 (z1,1,z2,1,…,zn,1)和(z1,2,z2,1…,zn,2),并考虑将这两个向量应用到深度函数的方法中,还可将二维平面上的点(zi,1,zi,2)看作zi。
Tukey还提出了二元得分可以利用半空间位置深度排序的方法,即用d(θ,z)表示,θ∈R2对应于二元数据区域z= {zi;i=1,2,…,n}[8]。Tukey深度函数被定义为:当θ存在于封闭半平面边界上时,该半平面内全部数据点的最小值可以按照距离d(zi,Z)以升序排列,这种顺序下的第一条曲线可认为是平均线,而最后一条曲线是在样本曲线中离中心最远的曲线。
(三)数据密度方法
Scott提出的数据密度方法是通过每个观测值上的二元核密度估计值排序[10]209-210。设oi=^f(zi),^f(zi)是由所有二元主成分得分计算得到的核密度估计值,这样函数型数据就可以按照o{}i的值以升序排序。因此,有最高密度的曲线是第一个观测值,而最后一条曲线是最低密度值;第一条曲线被认为是模板曲线(这里可以理解为基本的参照曲线),而最后一条曲线被认为是最不同寻常的曲线,实际上也最可能是异常值。应注意到,这种排序下的最后一条曲线取值与其他曲线差异可能不大,其二元得分也可能并不在散点图(zi,1,zi,2)的边缘,可能的情形是有一点在散点图内,但该点附近再无其他点,这样该曲线就表现为低密度值。
三、函数型数据图形分析的主要方法
(一)彩虹图
对于一些不依时间而按其他统计指标排序的数据,基于特定的排序指标或辅助标志也可以用彩虹图来表示,例如上面定义的数据深度或数据密度排序指标,绘图时根据o{}i的排序即可选择对应的线条颜色。
为验证上述方法,Hyndman根据国际气象组织公布的厄尔尼诺现象的测量数据进行模拟计算,选择了1951年1月至2007年12月南太平洋赤道附近的厄尔尼诺浮标点(南纬0~10度,西经90~80度)海平面的月平均温度时间序列数据进行了分析[11]。本文更新了上述数据,采用1982年1月至2013年12月的数据进行了再次模拟,并绘制了一组彩虹图,这些数据没有显著的时间趋势,因此基于时序的彩虹图意义不大。图2显示的是基于深度函数和密度函数指标顺序所表示的彩虹图,颜色按照彩虹颜色顺序,最接近中心数据的曲线设为红色,远离中心的设为紫色。按照深度和密度描绘曲线,因此红色曲线是最模糊的,而紫色最清楚,即使曲线部分大多数数据重合。图2中横坐标表示数据测量的月度顺序,纵坐标表示海平面的温度;图2(a)中黑色实线表示中线,图2(b)中黑色实线表示参照曲线。
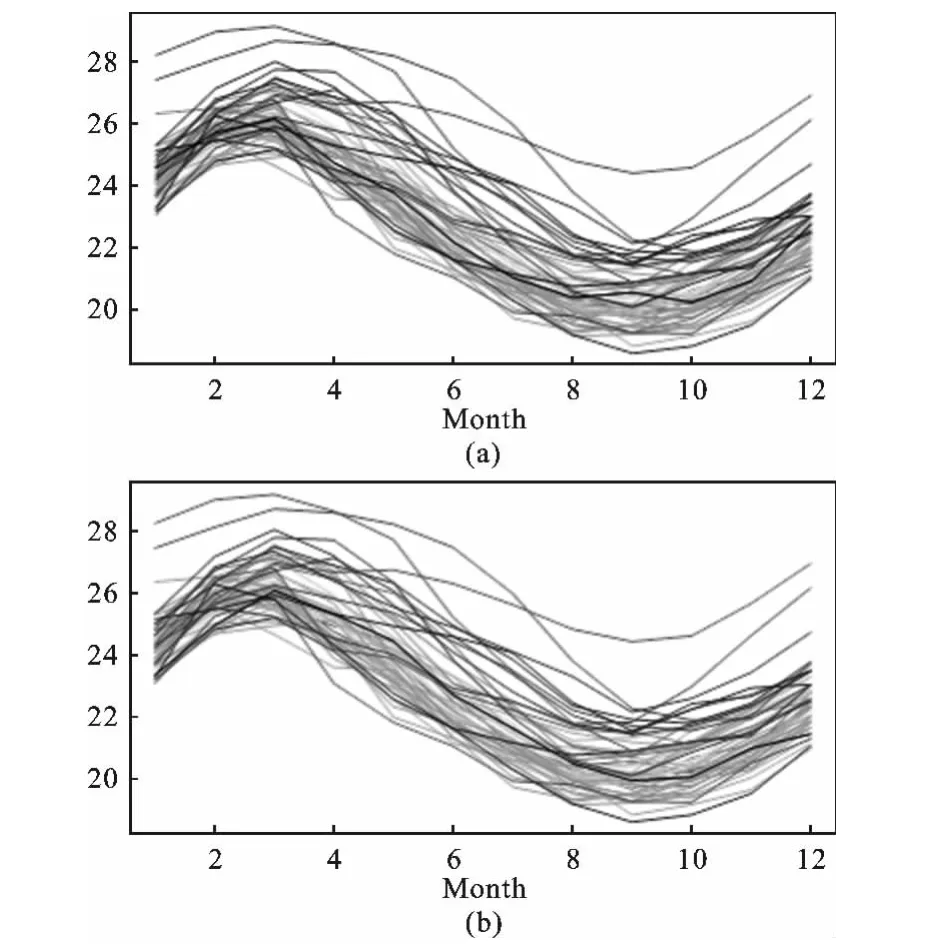
图2 基于不同排序指标的彩虹图
(二)打包图
函数型数据的打包图是建立在二元主成分打包图基础上,并应用前两个主成分得分而得到。图3使用了Tukey所定义的位置深度函数的概念,这个深度区域Dk是所有θ的集合,d(θ,k)≥k,因此深度区域形成一个凸面体,对于任意k2>k1有。Tukey的二元深度中位线被定义为:给定一个独立的θ,使d(θ,k)达到最小的θ值,并被定义为最深区域的重心。
类似于二维箱线图,二维打包图有一个中心点(即Tukey中位数)、一个内部区域(包)和一个外部区域,除此之外异常值以个别点显示。包被定义为至少包括总数50%的观测值的最小深度区域,打包图的外部区域(或称“围栏”),是包括由显著性水平决定的概率度因子ρ得到的包(与Tukey中位数有关)所组成域内的点组成的凸面体,当ρ=2.58时,假设投影的二维得分服从标准正态分布,则该区域允许外部区域的围栏部分包含99%的观测值;同理,当ρ=1.96时,围栏部分包含的数据观测值可以达到95%;当ρ=1.64时,围栏部分包含的数据观测值可以达到90%。

图3 厄尔尼诺现象观测数据的二元函数型打包图
图3显示的是关于厄尔尼诺现象数据的描述图形。在图3(a)中,深灰色区域表示的是50%的包,浅灰色区域显示的是99%的边界,这些凸面体对应于图3(b)中函数型打包图的相同阴影部分。位于围栏区域之外的点一般可视之为异常值,不同颜色的异常值表明右边的个体函数曲线同左边的二元主成分得分相匹配。图3(a)中,红色星号表明了二元主成分得分的Tukey中位数,图3(b)每个平面的黑色实线表明的是中位数曲线,蓝色点线是中位线上对应点的95%的置信区间,深灰和浅灰域标明了包和边界。红色星号是Tukey深度平均数,右面的黑色实线是平均线,上下虚线是对应点的95%置信区间,而外域之外的曲线用不同颜色标明的是异常值。
在厄尔尼诺数据中检测出的异常值出现在1982—1983年和1997—1998年。1982—1983年间厄尔尼诺指数在1982年6月升高较慢,在1982年9月至1983年6间海洋表面温度有一个极不正常的升高;1997—1998年间厄尔尼诺指数也不正常,尤其是在3月和5月。国际气象组织和有关国家公布的资料表明,1982年4月至1983年7月的ENSO现象是几个世纪来最严重的一次,太平洋东部至中部水面温度比正常高出约4~5℃,造成了全世界1 300~1 500人丧生,经济损失近百亿美元。2009年12月在丹麦举行的哥本哈根联合国气候变化大会上,2009年便被定为厄尔尼诺年。
当异常值远离平均数时函数型打包图可能是一种较好的异常值检测方法,然而当异常值接近于平均数时,这种深度测量异常值的方法可能误判异常值,在这种情况下函数型HDR箱线图则更适用。
(三)HDR箱线图
HDR箱线图即高密度区域箱线图,是Hyndman最先提出并进行实证分析的。函数型HDR箱线图是建立在二维HDR箱线图基础上的,由前两个主成分得分并进行分析后绘制。二维箱线图HDR是由一个二维核密度估计^f(z)构造,定义如下:

二维HDR箱线图表示的是众数,被定义为sup^f(z),即核心部分包含50%和外层包含99%的点的最高密度区域,分布在99%区域之外的点即可视为异常值。
函数型HDR箱线图是一个由前两个稳健主成分得分的二元HDR箱线图到函数的映射,包括参照曲线(有最高密度的曲线)、内部和外部区域。内部区域是由50%二元HDR内的点所形成的曲线而组成的域,因此有50%的曲线在内部区域。类似地,外部区域被定义为外围二元HDR图上的点所形成的曲线而组成的区域(见图4)。
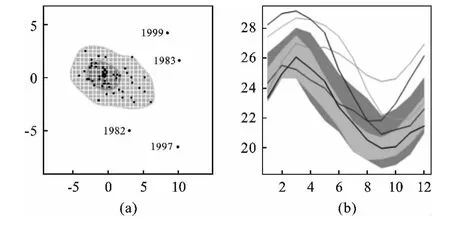
图4 厄尔尼诺统计数据的HDR箱线图和函数型HDR箱线图
图4显示了用厄尔尼诺统计数据进行实证分析的例子。在图4(a)中,深灰色和浅灰色区域分别表示50%的内部区域和99%的外部区域,直接对应于图4(b)中函数型HDR箱线图中的同色阴影区域,而外部区域之外的点被认为是异常值,不同颜色的异常值与图4(b)中个体曲线颜色及图4(a)中二维得分HDR相对应。图4(a)中的红色圆点表示二元主成分得分的众数,对应于图4(b)平面图中的黑色实线。从图4不难看出,1982-1983年和1997-1998年作为异常值被排除在外部区域之外,可以显著地定义为异常值,这个结论和前文的讨论是一致的,符合实际情况。
包括打包图和HDR箱线图在内的任何一种异常值检测方法,都需要提前确定外部区域的覆盖率。在99%的概率保证程度下,厄尔尼诺数据集中检测出的异常值出现在1997—1998年。如果假定厄尔尼诺数据中的覆盖率分别为92%和93%,那么在每个例子中检测出的异常值将同打包图得到的结果相对应,这表明相对于其他数据,这些异常值有不同的数量大小和分布形状。
四、借助图形分析方法进行异常值检测
在函数型数据分析中,一般利用函数型数据打包图和函数型深度方法即可完成异常值的检测。
(一)函数型深度方法
Febrero提出了一个对每一条曲线 {yi(x)}计算其似然比检验统计量的异常值检测方法[6]。如果检验统计量的最大值比给定的置信值C大很多,那么可以断定该数据点为异常值。去掉该点,对余下的数据用该方法继续检测其他异常值,一直重复这个过程,直到不再有其他异常值出现。这种检测方法是建立在式(1)给定的函数型数据的深度测量基础上,故对形状异常值并不敏感。
(二)误差平方积分方法
Hyndman等人提出了一种基于稳健型函数主成分分析的异常值检测方法[4]。设对每一个随机观测样本点i的误差平方项积分如下:
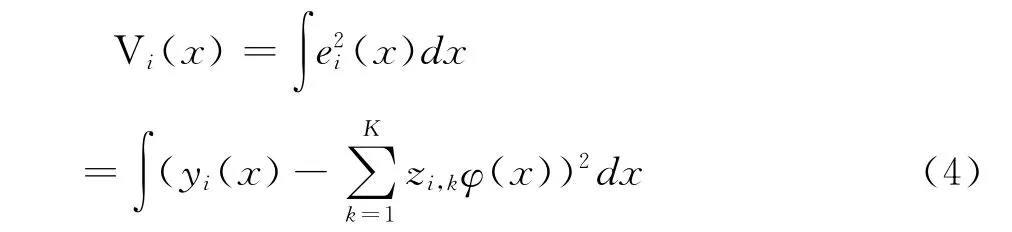


(三)稳健的马氏距离方法

五、异常值检测方法的实证分析
根据上述讨论,针对函数型数据的异常值数据,再次采用公开的厄尔尼诺现象在1982年1月到2014年1月的同步统计数据进行实证分析(图5)。

图5 厄尔尼诺统计数据的传统箱线图及异常值图
(一)正态分布假定下的异常值检测
由图5可以直观地看出,在1982—2014年的33个年度数据中,除了4月份以外,其他月份的箱线图都有异常值出现,而且这些异常值主要集中在1982—1983年和1997—1998年两个厄尔尼诺现象严重的年份,这与前文所述的情形基本类似。为了进一步比较本文所述的异常值检测方法,对于同一组数据,首先使用传统的异常值检测方法进行初步分析,即考虑大样本情形下以均值为核心构建一个半径为3s的置信区间,如果数据溢出这个区间,则判定为异常值,结果见表1。
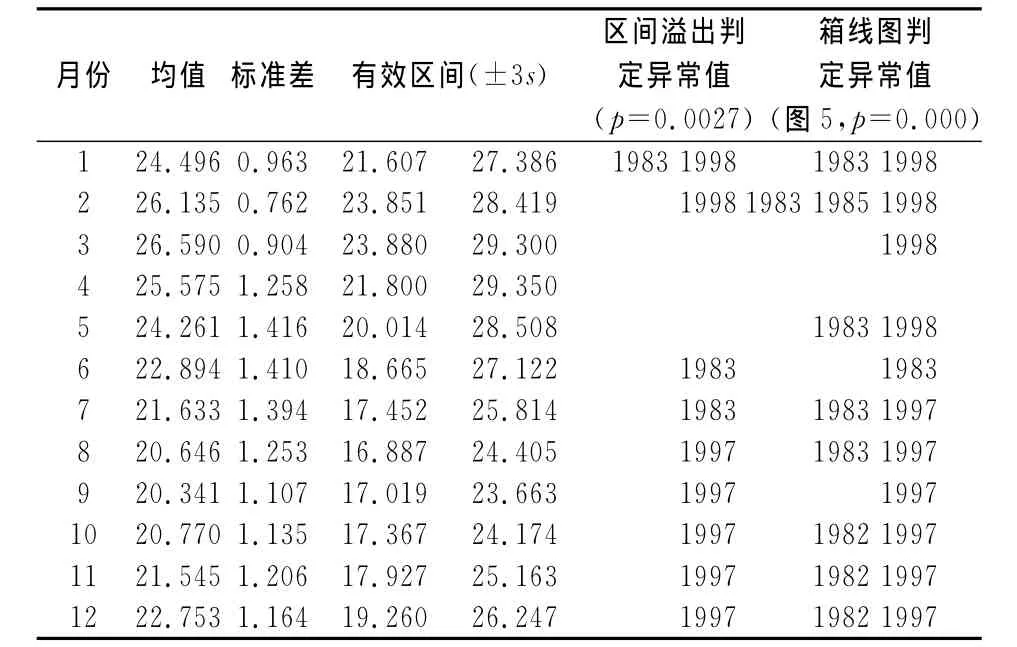
表1 正态分布假定下的厄尔尼诺数据异常值检测表
(二)函数型数据异常值检测
对于厄尔尼诺数据,同样利用前文涉及到的三种方法和HDR箱线图与打包图进行异常值检测。R语言程序准确地记录到了每种方法的计算时间,考虑到全部计算程序在同一台计算机上完成,硬件的影响可以忽略不计。
比较一种异常值检测方法的优劣,主要考察该方法的精确度和计算速度。以传统的箱线图方法为基准计算出的异常值检出率,即检测出的异常点占全部异常点的比例,除了函数型深度方法以外其他方法的检出率均为100%。检测方法的响应速度则直接采用统计软件显示的有效计算时间,计量单位是秒。
计算表明,图形方法是异常值检测的较好方法,不但保持了较高的检出率,而且计算时间也较短,比较适合大数据场合下持续进行的计算和分析,其中打包图比HDR箱线图的计算效率更优。如果考虑到未来在线大数据的计算,动态的函数型HDR箱线图和打包图都是一种较好的选择方法,甚至可考虑生成类似股价图一类的动态图示方法,从而及时地检出异常值,排除异常原因,最终保证数据过程的正常运行(见表2)。

表2 函数型异常值检测方法比较表
六、结论与进展
本文针对函数型数据的可视化分析,提出了三种描述工具和三种识别函数型数据异常值的方法。在所熟悉的二维空间中,对主成分得分按照数据深度和数据密度排列后,异常值和正常点自然就分开了。
本文所提及的方法,其优点是可以对复杂的函数型数据进行快速分析,并通过图形直观地表示出来,有利于批量地处理大数据,也有利于在更广义的领域推广使用,有较高的应用价值。根据笔者对更新的厄尔尼诺统计数据的实证研究,所介绍的三种异常值检验方法,无论是检测速度、效率和直观性还是检测的精度,都比以往的传统方法更优。
国外近期文献显示,在复杂数据背景下无论是自然科学还是社会科学,都对函数型数据的方法开展了研究,其研究主要包括三方面的进展:一是对传统主成分分析方法的扩展和进一步探索,主要目的是针对函数型数据的降维分析,在尽可能保持数据信息的前提下,降低数据的复杂性,以保留最多的因子贡献及方差贡献;二是探索更多的检测异常值的方法,以Tukey的深度函数和密度函数为基础,逐步发展了一些快速捕捉数据特性和检测函数型数据中异常点的方法,能辅助计算方法的改进,以替代传统的异常点检测方法;三是发展以稳健方法为主要趋势的基本统计方法,以函数型数据的众数和中位数为参照,对各类数据集进行排序和分割,以得到更直观有效的结果。
[1] Ramsay J O,Silverman B W.函数型数据分析[M].北京:科学出版社,2009.
[2] Hyndman Rob J,Shang Han Lin.Rainbow Plots Bagplots and Boxplots for Functional Data[J].Journal of Computational and Graphical Statistics,2010(1).
[3] Zhang L,Marron J S,Shen H,Zhu Z.Singular Value Decomposition and its Visualization[J].Journal of Computational and Graphical Statistics,2007(4).
[4] Hyndman R J,Ullah M S.Robust Forecasting of Mortality and Fertility Rates:A Functional Data Approach[J].Computational Statistics and Data Analysis,2007(10).
[5] Febrero M,Galeano P,Gonzalez-Manteiga W.A Functional Analysis of NOx Levels:Location and Scale Estimation and Outlier Detection[J].Computational Statistics,2007(3).
[6] Febrero M,Galeano P,Gonzalez- Manteiga W.Outlier Detection in Functional Data by Depth Measures,With Application to Identify Abnormal NOx Levels'[J].Environmetrics,2008(4).
[7] Hyndman Rob J,Shang Han Lin.Rainbow Plots,Bagplots,and Boxplots for Functional Data[J].Journal of Computational and Graphical Statistics,2010(1).
[8] Tukey J W.Mathematics and the Picturing of data[C].Vancouver:Proceedings of the International Congress of Mathematicians,1974.
[9] Hyndman R J.Computing and Graphing Highest Density Regions[J].The American Statistician,1996(2).
[10]Scott D W.Multivariate Density Estimation:Theory,Practice,and Visualization[M].New York Wiley,1992.
An Empirical Study on Outliers Test of Functional Data Based on Graph Description Tools
MI Zi-chuan
(School of Statistics,Shanxi University of Finance and Economics,Taiyuan 030006,China)
As one kind of complex data essentially,functional data can be affected in its complexity and descriptive nature by sampling,producing,structure and degree of association easily,even basic visual descriptions of it has become difficult.In general,the usual graphical-analytical method of functional data is the traditional method called data smoothing.Through this method,status,structures and trends of functional data can be described by the smooth curve.This paper introduces package diagram and box plot of functional data into the scores of principal component and the concept of data depth and density of Turkey.Simultaneously,while graphical analysis of functional data develops,tests of outliers in functional data have been resulted.Compared with the existing detection methods,the proposed method by this paper is easier to identify the outliers of functional data.
functional data,graphical tools,tests of outliers
F224.0∶O243
A
1007-3116(2014)06-0018-07
2014-02-09;修复日期:2014-04-18
国家社会科学基金重点资助项目《中国社会核算矩阵研究》(10ATJ001);国家统计局全国统计科学重点研究项目《统计数据的函数化及函数型数据分析的工具创新》(2009LZ026)
米子川,男,山西祁县人,统计学博士,副教授,硕士生导师和MPA导师,研究方向:应用统计学。
(责任编辑:郭诗梦)
猜你喜欢
现代临床医学(2021年1期)2021-01-26
新世纪智能(英语备考)(2019年4期)2019-06-26
东北史地(学问)(2016年6期)2016-12-14
海洋世界(2015年6期)2015-12-06
创新作文(1-2年级)(2015年7期)2015-08-06
科普童话·百科探秘(2015年4期)2015-05-14
湖南师范大学学报·自然科学版(2014年1期)2014-03-13
枣庄学院学报(2013年5期)2013-11-09
智慧与创想(2013年2期)2013-03-25
