
数据挖掘技术及其在生产过程质量控制中的应用
2014-04-14 15:39陈梅CHENMei
价值工程 2014年16期
陈梅 CHEN Mei
(乌鲁木齐职业大学信息工程学院,乌鲁木齐 830002)
(Information and Technology College of Urumqi Vocational University,Urumqi 830002,China)
0 引言
随着信息技术、网络技术及计算机技术的发展,在生产过程自动化系统各种数据库中收集和存储了大量数据,而今年来得到国内外极大重视和研究的数据挖掘技术主要运用数据库、统计学的基础,结合人工智能、计算智能、模式识别等先进技术从大量数据中挖掘和发现有价值和隐含的知识[3]。对于复杂的工业生产过程,在实现了基础自动化以后,为了增产降耗,提高产品质量,需要研究生产过程的先进控制。本文主要介绍数据挖掘技术的原理和方法以及在生产过程中如何运用数据挖掘技术进行质量控制的应用。
1 数据挖掘基本概念
数据挖掘是从大量的数据中挖掘知识。Fayyad给出的定义是:数据库中的知识发现是从数据中识别出有效的、新颖的、潜在有用的、以及最终可理解的模式的高级过程[6]。数据挖掘的任务是利用各种技术在“数据矿山”中找到蕴藏的“知识金矿”,揭示数据中隐含的知识模式,帮助人们进行决策。
根据挖掘的任务不同,数据挖掘可以分为分类或预测模型发现、回归、数据聚类、关联规则发现、序列模式发现、依赖关系(模型)发现、异常和趋势发现等。根据挖掘对象不同,数据挖掘可分为关系数据库挖掘、面向对象数据库挖掘、空间数据库挖掘、时态数据库挖掘、文本数据库挖掘等。根据数据挖掘的方法不同,数据挖掘又可分为机器学习、统计方法、神经网络方法和数据库方法等。
2 数据挖掘
数据挖掘的过程是一个从已知数据集合中发现各种模型、规则、关联的过程,并且这个过程是一个反复迭代的复杂过程[5]。在数据挖掘的过程中,必须对每个步骤及其任务进行精心的策划和深思熟虑的安排,才能保证挖掘出的知识符合需求。典型的数据挖掘过程包括以下几个步骤:
①数据的选择:最初为数据挖掘准备的所有原始数据集通常较大,而且一般都是杂乱无章的,因此必须从原始数据中选择适当的样本。数据选择的目的就是从数据集中根据用户的需要提取有意义的数据,确定数据挖掘的操作对象。
②数据的预处理:其目的是剔除数据中的失真值或者误记录,这是数据挖掘中最为关键的步骤之一,其处理结果将对数据挖掘的结果产生重大影响[4]。数据预处理的主要任务是把数据组织成一种标准的形式,使其能被数据挖掘工具和其他计算机工具进行处理、准备数据集,使之能得到最佳的数据挖掘效果。
③数据的转换:主要是为了消减数据的维数或降维,降低数据处理的难度和复杂度,及找出数据当中有意义的特征,以减少数据挖掘时要考虑的特征或变量的个数。
④数据挖掘:首先根据对问题的定义明确挖掘的任务或目的,如分类、聚类、关联规则发现、预测模型建立等,然后根据任务决定采用何种算法。选择算法时应考虑两个因素:一是不同的数据有不同的特点,因此需要采用与之相关的算法来实现;二是用户或实际运行系统的要求。
⑤模型评估:数据挖掘阶段发现出的模式,经过评估,可能存在冗余或无关的模式,此时需要将其剔除;也可能模式不能满足实际的要求,这时需要退回到前一阶段,如重新选择数据、采用新的数据转换方法或设定新的参数等,甚至有时需要重新选择算法。
由此可见,整个数据挖掘的过程是一个不断反馈的过程。例如,用户在挖掘的过程中发现所选择的数据不合适,或者采用的挖掘技术得不到期望的结果,此时用户需要重复之前的过程,甚至从第一步重新开始。
3 在生产过程质量控制中的应用
目前对于数据挖掘技术的应用和研究主要在以下两方面:
①在数据挖掘技术自身领域中,对现有的典型的数据挖掘算法进行优化和改进,以及对挖掘方法的改进、挖掘语言标注化等方面的研究。
②利用现有的工具软件如SAS,SPSS climentine,wake,R,statistica等结合其他开发软件,对实际应用环境如医疗、金融、教育及电信等领域中的积累数据进行知识挖掘,找寻潜在规律,为后续工作提供数据支持和依据。数据挖掘技术在不断的向各个应用领域进行延伸,尤其是生产质量控制领域。生产过程质量控制是一个非常复杂的动态过程,是利用生产过程的动态信息进行质量预测和质量控制,要解决的问题主要包括被控变量的选择、控制器参数的调整、系统建模、系统的关联问题及过程优化等问题[1]。因其实时性和较高的准确性,可预估质量问题,进而降低企业生产成本和经济损失。生产过程质量的基础是对生产过程的质量预测。只有对产品质量参数进行预先估计,才能在产品质量出现问题前调整生产过程,继而达到提高产品质量的目的。通过以各种决定产品质量的变量为输入,以产品各质量指标为输出,引入数据挖掘技术建立生产过程的质量模型。
这里以某挤塑产品生产为例,因生产过程中生产线不同点加热温度的高低,直接影响挤出成型产品质量,为实现良好的质量控制,介绍在生产过程中如何使用数据挖掘中的预测技术实现对产品挤出时刻温度的预测,为生产线温度调控提供数据支持和依据,进一步实现质量控制。当将数据挖掘方法用于建立挤塑产品生产过程的温度预测模型时,因传感器对生产过程不断采样,获得的生产历史数据通常都是时间序列,即历史数据是和时间相关的一系列值。这里我们采用动态数据挖掘的方法,主要目标有两个:1)通过对挤塑产品生产过程历史记录的数据挖掘,建立产品挤出温度预测模型,并运用于生产过程,进行实时温度预测;2)利用对历史数据的挖掘,分析加热参数对产品挤出温度的影响,找出隐藏的加热规律,为更好的实现产品生产过程的质量控制提供决策支持。
3.1 数据的选择、预处理与转换 在实际生产中,产品在t1时刻的挤出温度y与t1-Δt时刻的生产线的中间点温度x1、推进速度x2及加热设备的加热功率x3有着非常密切的关系。这里将产品挤出温度y定为输出变量,其余参数定为输入变量。
实例中选取了最长时间序列采样数据7500个,对原始数据进行去除无效值、数据平滑等预处理,将5000个数据作为训练集,1000个数据作为测试集。为了更直接的得到输入变量对输出变量的影响度,将推进速度和加热功率进行无量纲化处理,数据均在0-1之间,处理后的数据如表1所示:

表1 预处理及转换后数据表
3.2 数据挖掘 多元线性回归是数据挖掘技术中进行预测挖掘的主要方法之一,其涉及多个预测变量,它允许响应变量Y用描述元组X的n个预测变量或属性A1,A2,…,An的线性函数建模。
如今受新媒体和人们生活方式改变的影响,订阅报纸的客户数量逐年下降,一些文艺性、娱乐性的报刊群体也在逐渐减小,发行量连年急剧下滑,人民日报印刷厂也不例外地受到这一趋势的冲击。杨兴华认为,报业印量下滑是大势所趋,但人民日报印刷厂在这样的大趋势中依然能够保持相对稳定的态势,实属不易。
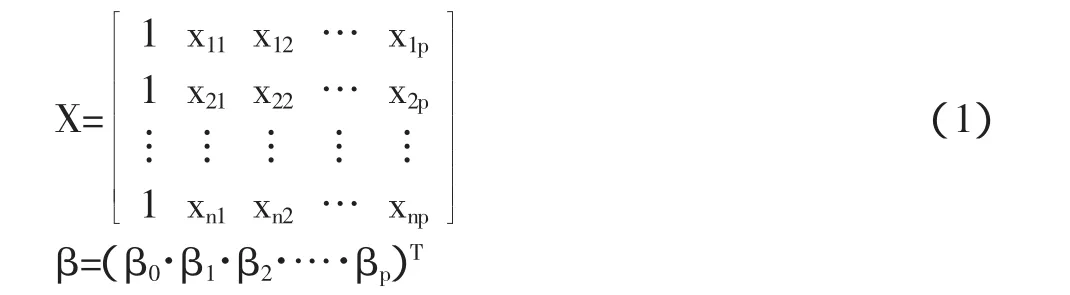
预测模型为:Y=Xβ
其中Y=(y1,y2,…,yn)T
式中Y——预测对象的历史观测向量;
X——影响因素的历史观测矩阵,是收集到的p个y的影响因素的n次观测值;
B——系数向量。
应用中,数据采集和挖掘过程如图2所示,在上位机中以Labview为运行平台,数据库采用Access数据库,结合Matlab软件实施挖掘,调用函数regress(y,x),得到系数β=[-7.85951.5742-0.344640.00042534],则温度预测方程如下:Y=-7.8595+1.5742x1-0.34464x2+0.0004x3(2)
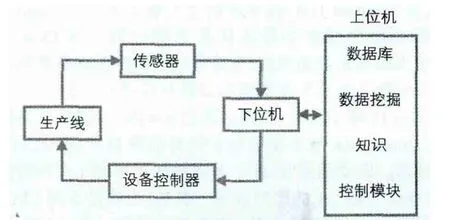
图1 数据采集、挖掘过程
3.3 模型评估 相关系数为R2=0.8985,表明回归方程效果良好。经计算得到F=4307.6,F取4307.6的概率p=0.0000,这表明该回归方程合理。
将公式(2)引入到测试集中进行预测检验,其结果如表2所示。
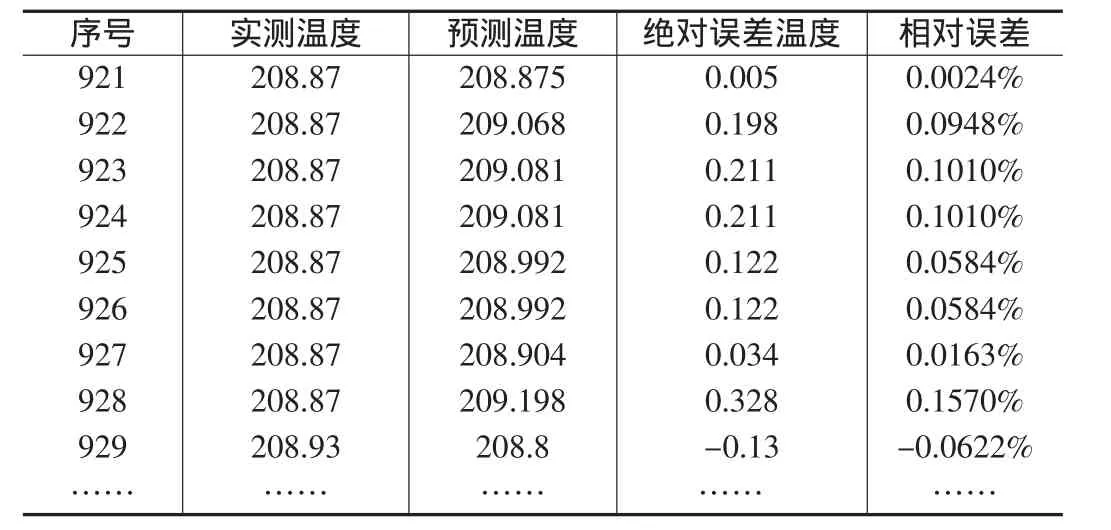
表2 温度预测检验表
由表2可看出,预测温度与实测温度的偏差都在0.5以内,达到较好的预测效果。此外,在预测方程(2)中将速度变量和加热功率变量的系数相比较,可知速度的变化对挤出温度影响幅度相对较大,加热功率的变化对挤出温度影响幅度相对较小,为挤塑产品生产中挤出温度的控制提供了理论依据,进而为更好提高生产质量提供保证。
4 结语
数据挖掘技术能从大量生产数据中挖掘和学习有价值和隐含的知识,因而在生产过程质量控制系统中具有很大的应用前景。本文简要介绍了数据挖掘的概念及挖掘过程,以挤塑产品生产过程中温度的多元回归预测挖掘为例介绍了数据挖掘技术在生产过程质量控制的应用,其他的挖掘方法如何应用于实际生产中还有待于进一步研究。
[1]万维汉.工业生产的产品质量控制以及应用[J].系统仿真学报,2001,13(8):153-155.
[2]舒正渝.浅谈数据挖掘技术及其应用[J].中国西部科技,2010,202(09):38-39.
[3]郭立伟,高雷,陈丹.数据挖掘技术在冷连轧机板形控制系统中的应用研究[J].冶金自动化,2012,02:96-100.
[4]胡燕,何腊梅.数据挖掘数据挖掘技术在转炉终点控制中的应用[J].钢铁技术,2010,5:7-9.
[5]高立鹃,刘云,赵玲.双向数据挖掘的反馈预测分析[J].郑州轻工业学院学报,2011,12(5):81-85.
[6]武书彦,李咚.数据挖掘技术的探索性研究[J].制造业自动化,2011,33(1):102-105.
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
数学年刊A辑(中文版)(2015年2期)2015-10-30
新高考·高二数学(2014年7期)2014-09-18
电子设计工程(2014年18期)2014-02-27
