
依存树到串模型中引入双语短语的三种方法
2014-04-14 07:50谢军刘群
中文信息学报 2014年2期
谢军,刘群
(中国科学院计算技术研究所,北京100190)
1 引言
依存树旨在描述句子中各个成分之间的语法关系,兼有句法和语义知识,也被视为语言学从句法表示向语义表示迈进的一种过渡形式。与成分树相比,依存树具有以下特点:1)完全由词汇化元素构成,更加简洁;2)同时包含了句法和语义知识;3)具有更好的跨语言短语聚合(phrasal cohesion)性质[1]。因此,依存树是一种非常适合构建统计机器翻译模型的知识源。
不过,依存树缺乏类似于短语结构文法的生成式文法体系,构建基于依存树的翻译模型时,需要首先定义合适的树分解方式或形式化文法来描述依存树的生成过程,这也使得这方面的研究工作相对更加困难。
在基于源语言依存树的模型研究方面,研究人员从不同的角度进行尝试,提出了多种不同的树分解方式。Lin[2]以路径为基本结构单元、合并为基本操作,提出了基于路径转换的模型。Quirk[3]等人扩展了Lin的工作,将基本结构单元由路径扩展为树杈(Treelet),提出了依存树杈模型;其中,树杈指依存树中的任意连通子树,可以捕捉更大范围的语言学知识。熊德意等人[4]提出的依存树杈-串(DTSC)对应模型,也以树杈作为基本单元,不过使用了与依存树杈模型不同的泛化处理方式,并定义了替换和粘接两种操作。Xie等人[5]以中心词及其所有依存节点组成的树片段(简称HDR片段)为基本结构单元,以替换为基本操作,提出了一种依存树到串模型。相对于上述模型,该模型更加简洁,不再需要启发式或调序模型辅助翻译过程。该模型在大规模实验上表现出比当前主流的成分树到串模型[6]和层次短语模型[7]更好的性能和长距离调序能力,是第一个性能超过主流模型水平的基于源语言依存树的翻译模型。
依存树到串模型使用的基于HDR片段的翻译规则擅长捕捉源语言中的句子模式和短语模式(即句子或短语的组成方式),不过由于依存树完全由词汇化元素构成、且结构相对扁平的特点,这种翻译规则表示在捕捉语言中的非组合现象(如习惯用语或固定搭配)方面存在明显不足(详见第3节的说明)。而这类非组合现象可以很容易被短语捕捉。为了缓解这一问题,本文提出了三种引入短语的方法,除了传统的引入句法短语的方法外,还探索了以下两种新的方法:对句法短语进行适度泛化以扩大具有特定上下文的句法短语的适用性;通过构造新的翻译规则以使翻译规则更好地兼容非句法短语。实验结果表明,同时引入句法短语、泛化的句法短语和非句法短语时,可以使依存树到串模型的性能提升约1.0BLEU。
本文以下内容中,首先简要介绍依存语言模型,然后说明基于HDR片段的翻译规则的缺点,随后详细说明引入句法短语、泛化的句法短语和非句法短语的方法,并给出相应的实验结果。
2 依存树到串模型
Xie等人[5]提出依存树到串模型,以HDR片段作为依存树的基本结构单元、替换为基本操作来描述依存树的生成过程,将翻译规则表示为:源语言端为适度泛化的HDR片段、目标端为目标语言词和变量组成的串。
HDR片段是由中心词及其所有依存节点组成的树片段,高度为1。每个HDR片段与源语言中的一个句子模式或短语模式相对应。因此,该模型使用的基于HDR片段的翻译规则可以较好地描述源语言中的句子模式或短语模式的翻译方式。这种类型的翻译规则被称为HDR翻译规则。
为了保证翻译的顺利进行,该模型还使用了另一类中心词翻译规则,用于完成单个节点的翻译。
图1示例了三个HDR翻译规则(a)、(b)、(c)和一个中心词翻译规则(d)。图中,“*”指示的节点为替换节点。需要说明的是,三个HDR翻译规则描述的是同一个句子模式(名词短语+介词短语+副词+动词”组成的句子模式)的翻译方式。不同之处是,三条规则所描述的上下文环境。规则(a)清楚地指定了适用的上下文,规则(b)部分指定了适用的上下文,规则(c)则未对上下文做任何约束。
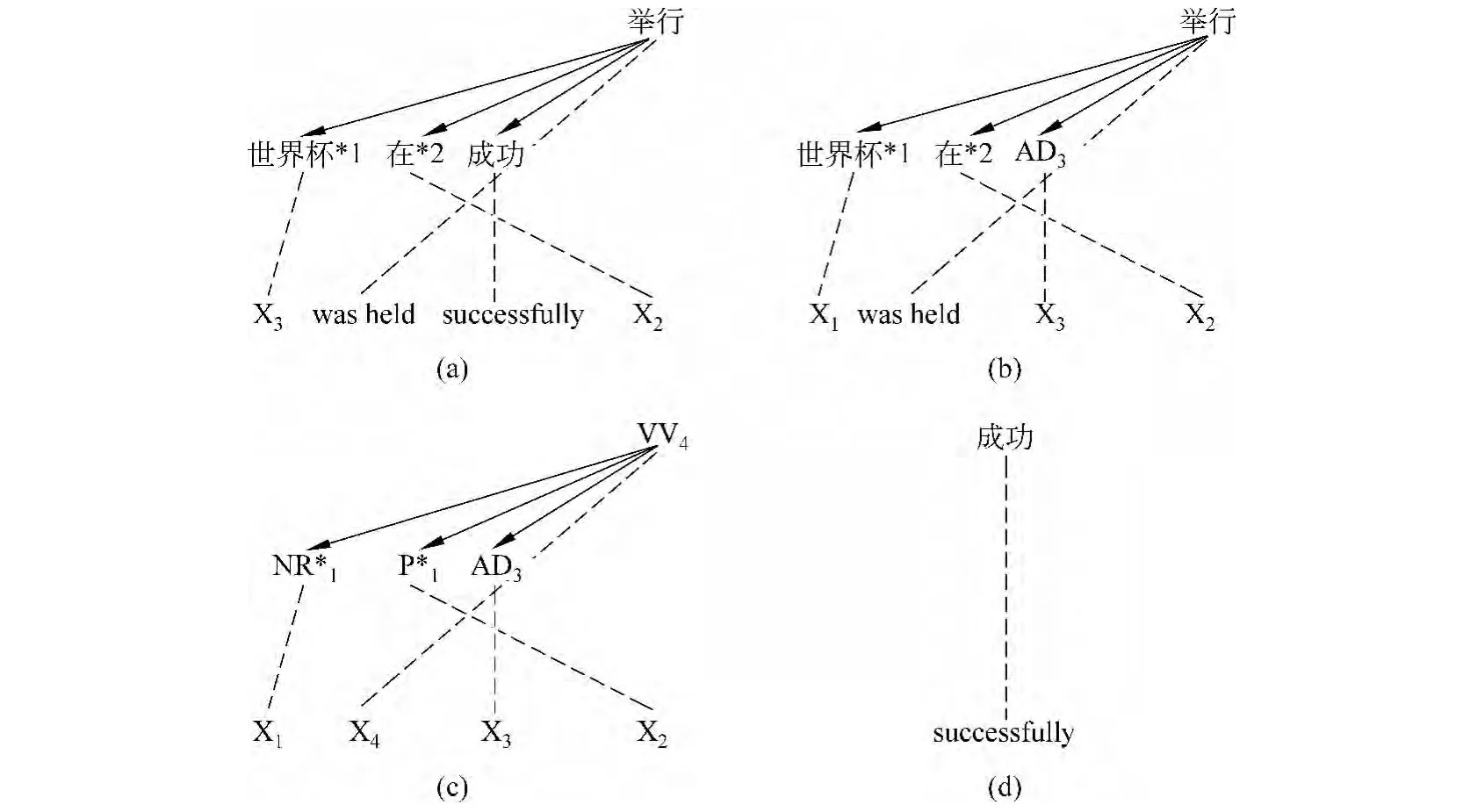
图1 HDR翻译规则和中心词翻译规则示例
该模型的解码算法基于自底向上的chart-parsing算法。解码器后序遍历输入的依存树,对于访问到的每个节点,使用HDR翻译规则和中心词翻译规则,利用Cube Pruning算法[6]为该节点生成n-best翻译假设。重复此过程直至处理完依存树的根节点,算法结束。
3 HDR翻译规则的缺点
HDR翻译规则可以较好地捕捉源语言的句子和短语模式这类组合现象,但在处理习惯用语或固定搭配这类非组合现象时存在明显不足。例如,在图2给出的两个示例中,HDR翻译规则为阴影指示的习惯用语或固定搭配难以给出准确的翻译。图2(a)中“发射 升空”为一个常见的固定搭配,通常翻译为“lauch/lauched/lift up”;图2(b)中“中华人民共和国”为一个命名实体,有固定的翻译方式“the People's Republic of China”。
由于依存结构的特点,习惯用语和固定搭配通常作为HDR片段的一部分出现,如图2(a)中的“发射升空”和图2(b)中“中华人民共和国”。对于这类非组合现象,使用HDR翻译规则进行翻译时,将会非常低效(如图2(b)),甚至完全无法得到理想的译文(如图2(a))。

图2 HDR翻译规则难以捕捉的短语示例
4 引入短语的三种方法
对于习惯用语或固定搭配这类非组合现象,可以很容易地使用短语来捕捉。因此,可以通过引入短语来弥补HDR翻译规则在处理非组合现象方面的不足,从而进一步提高依存树到串模型的性能。本文尝试了三种引入短语的方法,除了借鉴成分树到串模型,为依存树到串模型引入句法短语外,还探索了引入泛化的句法短语和引入非句法短语的方法。
4.1 引入句法短语
句法短语是指依存树中由一棵完整的子树所覆盖的短语。例如,图2(b)所示的依存树片段中,包含两个句法短语,分别为:“伟大 的”和“伟大 的 中华人民共和国”。
4.1.1 双语句法短语的获取
双语句法短语的获取相对比较简单。类似于成分树到串模型,本文直接利用基于短语的模型[6]的规则抽取模块来获取双语短语。

4.1.2 双语句法短语的使用
在引入双语句法短语方面,依存树到串模型借鉴了成分树到串模型[6]的方法。
具体来说,解码过程中,对于访问到的每个内部节点n,翻译假设的生成将包含两个步骤:
1)查找短语表,获取与以n为根的子树覆盖的句法短语匹配的双语短语,使用匹配到的双语短语,为节点n生成翻译假设;
2)根据以n为中心词的HDR片段,生成HDR片段所包含句子模式或短语模式的实例,查找规则表,获取匹配的HDR翻译规则及必须的中心词翻译规则,利用Cube Pruing算法为节点n生成新的翻译假设。
4.2 引入泛化句法短语
泛化句法短语是通过对句法短语的某些部分进行泛化得到的,用以扩大具有特定上下文的句法短语的适用性。本质上,泛化的句法短语与HDR翻译规则类似,不过泛化的句法短语的对应的树片段高度≥1。
4.2.1 泛化句法短语的获取
由于句法短语涉及树高≥1,泛化不像HDR翻译规则那样直接。作为初步尝试,本文使用了简单的启发式,仅对包含时间词和数词的句法短语做了泛化处理。之所以选择包含时间词或数词的句法短语作为处理对象,是因为时间词和数词是未登录词的主要组成部分。
句法短语的泛化处理中,将满足下述条件的节点替换为变量:
·节点的中心词跨度(head span)[4]是对齐一致的;
·节点的词性标记属于集合{CD,OD,NT},即该节点为基数词、序数词或时间词。
为了获取泛化的句法短语,对于依存树中的每个节点,除了标记中心词跨度和依存跨度(dependency span)[4]外,我们还标记一个新的属性——短语跨度(phrase span)[2],以说明以该节点为根的子树覆盖的句法短语的对齐情况。
图3给出了一个标记有中心词跨度、依存跨度和短语跨度的依存树片段示例。为了清晰起见,图中只显示了与泛化句法短语相关的树片段,只在相关节点标记了三个跨度;不再给出阴影覆盖的部分详细对齐信息。其中,节点“占”和“25.5%”上标记的三个集合依次为中心词跨度、依存跨度和短语跨度。
图3(b)给出了一个泛化句法短语的翻译规则示例。

图3 树标记及泛化句法短语示例
完成依存树标记后,获取泛化的句法短语只需要对依存树到串模型的翻译规则抽取算法做简单修改。具体来说,对于访问到每个内部节点,除了按照原有的规则抽取过程生成HDR翻译规则和中心词翻译规则外,短语跨度对齐一致时,且存在满足上述约束的节点,则可以生成泛化的句法短语。需要说明的是,短语跨度的对齐一致性与基于短语模型的双语短语对齐一致性是等价的,可以直接利用双语短语的对齐一致性来判断短语跨度的对齐一致性。
4.2.2 泛化句法短语的使用
解码过程中,泛化句法短语的使用与HDR翻译规则的使用类似。
具体来说,在后序遍历源语言依存树的过程中,对于访问到的每个内部节点n,使用两个步骤为n生成n-best翻译假设:
1.根据以n为根的子树,生成泛化句法短语的源语言端,查找翻译规则表获取匹配的泛化句法短语,利用Cube Pruning算法,为n生成翻译假设;
2.根据以n为中心词的HDR片段,生成HDR片段所包含的句子模式或短语模式实例,查找规则表,获取匹配的HDR翻译规则及必须的中心词翻译规则,利用Cube Pruning算法为节点n生成新的翻译假设。
4.3 非句法短语
非句法短语是指不能够被依存树中的一棵完整的子树所覆盖的短语。也就是说,非句法短语涉及的节点或者是子树的一部分,或者跨越多棵子树。引入非句法短语的目的是为了进一步改善依存树到串模型的短语覆盖度。
4.3.1 非句法短语的获取
由于基于短语的模型的短语规则获取中,不涉及句法树的约束,因此可以利用基于短语的模型的短语规则抽取算法来获取非句法短语。
4.3.2 非句法短语的使用
非句法短语的使用是通过构建新的HDR翻译规则来实现的。
具体来说,在后序遍历源语言依存树的过程中,对于访问到的每个内部节点n,将按照以下两个步骤来为n生成n-best翻译假设:
1.根据以n为中心词的HDR片段,生成HDR片段所包含的句子模式或短语模式实例,查找规则表,获取匹配的HDR翻译规则及必须的中心词翻译规则,利用Cube Pruning算法为节点n生成翻译假设;
2.对于每个匹配的HDR翻译规则,按照如下过程生成新的HDR翻译规则:
1)查找翻译规则中不发生调序的、且长度>1的片段(可能有多个);
2)对于步骤1)得到的片段,生成片段覆盖的源语言短语,查找规则表获取匹配的双语短语;
3)若存在匹配的双语短语,则将该片段设置为对应的源语言端和目标语言端替换为一个新的变量;
4)按照步骤2)和3)依次处理所有片段,即生成一条新的HDR翻译规则,该规则将使用原HDR翻译规则的概率;
根据新生成的HDR翻译规则和双语短语,利用Cube Pruning算法为节点n生成新的翻译假设。
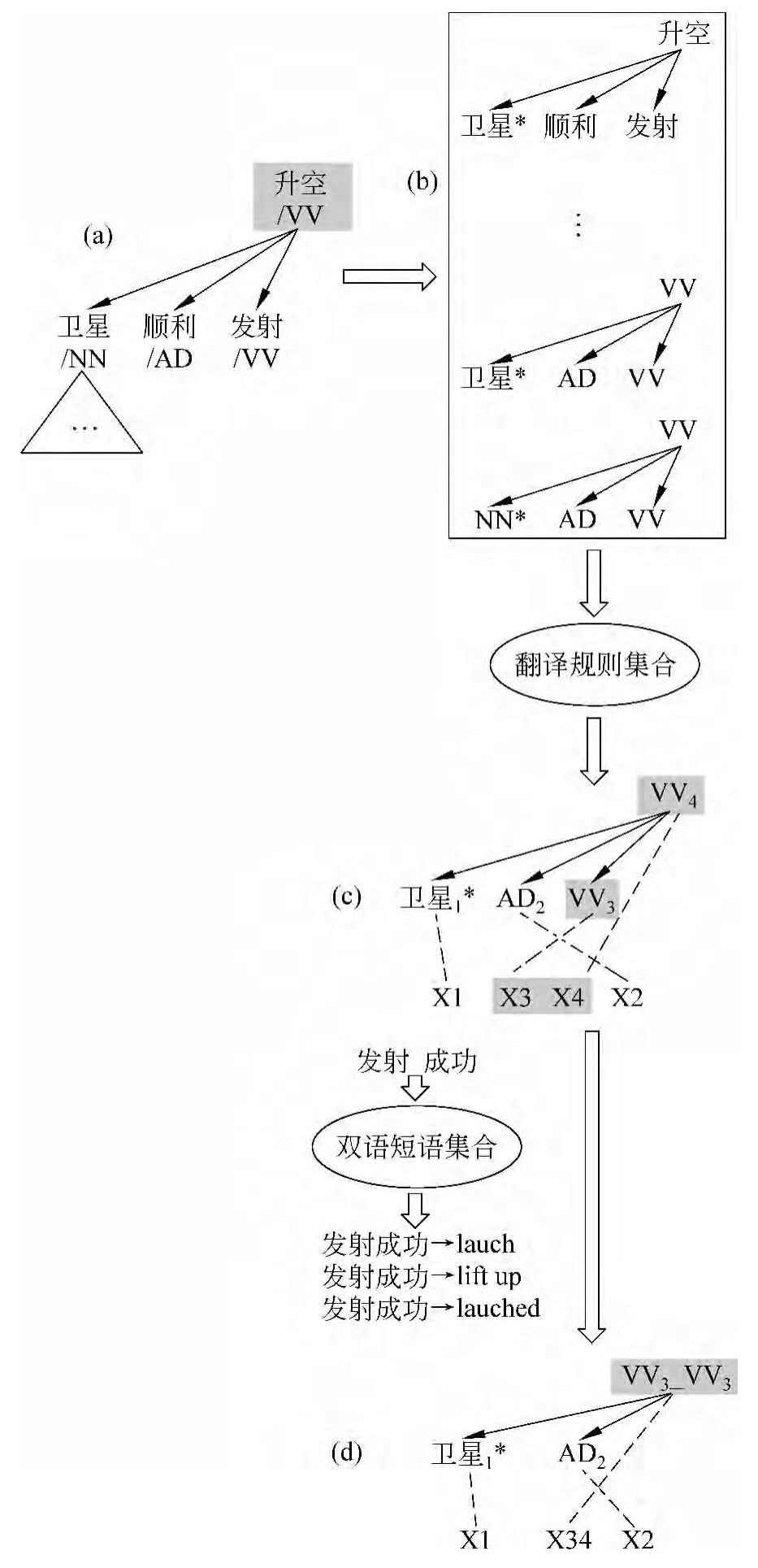
图4 生成新的HDR翻译规则示例
图4示例说明了根据双语短语和HDR翻译规则生成新的HDR翻译规则的过程。假设目前访问的节点为阴影指示的节点“升空”。
根据以“升空”为中心词的HDR片段,生成对应句子模式的所有实例,如(b)所示;查找翻译规则表获得匹配的HDR翻译规则,假设只有一条匹配的HDR翻译规则(c);确定HDR翻译规则(c)不发生调序的片段“VV3VV4”;根据“VV3VV4”所覆盖的源语言短语“发射 升空”查找短语表,得到匹配的翻译规则;将“VV3VV4”及其在目标语言端的对应部分分别替换为新的变量“VV3_VV4”和“X34”,从而得到新的HDR翻译规则。
5 实验部分
为了验证这三种引入短语的方法在改善依存树到串模型性能方面的作用,我们以不引入任何短语的依存树到串模型作为基准系统进行了汉—英翻译实验。
5.1 实验数据及工具说明
实验使用的开发集为NIST 2002,测试集为NIST 2005;训练语料来自LDC语料,双语平行语料包括27万句对①包括LDC2002E18,LDC2003E07,LDC2003E14,LDC2004T07,LDC2005T06.,英语单语语料为LDC单语语料Gigaword Xinhua部分。
上述语料的汉语部分使用Stanford Word Segmenter[8]②http://nlp.stanford.edu/software/segmenter.shtml进行分词处理。
使用GIZA++[9]对双语平行句对进行双向对齐,并借助“grow-diag-and”启发式来优化对齐结果。
使用Stanford Parser[10]对双语平行句对的中文句子进行句法分析得到投射性(projective)的依存句法树。其中,依存树的每个节点都标记有词性标记。
使用SRI语言模型工具包[11]在英语单语语料上训练得到三元的语言模型。
使用MERT[12]进行调参以最大化依存树到串模型在开发集上的BLEU值。
使用大小写不敏感的BLEU-4指标[13]对于翻译结果进行评价,实验使用脚本为mteval-v11b.pl①ftp://jaguar.ncsl.nist.gov/mt/resources/mteval-v11b.pl。
5.2 实验结果
表1给出了实验结果。其中,“dep2str”为不引入任何短语的基准系统,“dep2str+bp”为引入双语句法短语的系统,“dep2str+bp+gbp”为引入双语句法短语及泛化句法短语的系统,“dep2str+bp+gbp+nsbp”为引入双语句法短语、泛化句法短语和非句法短语的系统。
从表中可以看到,依次引入句法短语、泛化句法短语和非句法短语,依存树到串模型的性能也逐渐升高。其中,双语句法短语的引入使系统的性能提升了0.52BLEU,泛化的句法短语的引入使系统性能进一步提高0.14BLEU,非句法短语的引入使系统的性能再度提升0.31BLEU。最终,同时引入句法短语、泛化的句法短语和非句法短语使得依存树到串模型的性能比基准系统提升了0.97BLEU值。
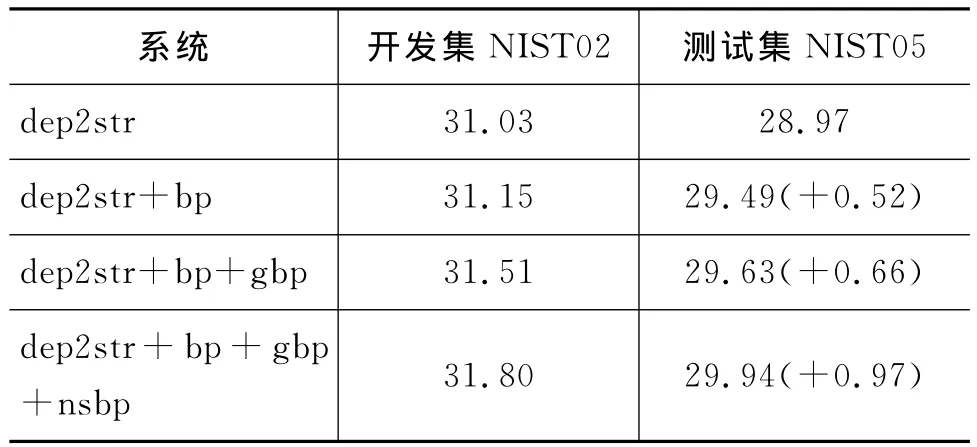
表1 依次引入句法短语、泛化句法短语和非句法短语后的性能比较
6 结语
Xie等人[4]提出的依存树到串模型使用基于HDR片段的翻译规则,这种翻译规则可以较好地捕捉源语言的句子模式和短语模式等组合现象,但在处理如习惯用语或固定搭配等非组合现象方面存在不足。为了缓解这一问题,改善依存树到串模型的性能,本文针对HDR翻译规则的特点,提出了三种不同的引入短语的方法,分别为:引入句法短语的方法、引入泛化的句法短语方法和引入非句法短语的方法。实验结果表明,同时引入句法短语、泛化句法短语和非句法短语可以将依存树到串模型的性能显著提高约1.0BLEU。
本文工作是对依存树到串模型引入短语方法的初步探索,还有很多工作需要进一步改进和优化。比如,泛化的句法短语的处理仍比较简单,目前仅能处理时间词和数词等,覆盖度比较有限。今后的工作中我们将探索更加有效的方法,以提高泛化句法短语的适用性。引入非句法短语方面,本文的方法可以较好地处理HDR翻译规则中的不发生调序的片段,可以有效处理图2(a)中“发射升空”这类非句法短语。不过对于图2(b)中“中华人民共护国”这类非句法短语的翻译需要调序的情形仍无法有效处理,这将是我们今后研究工作的重要内容。
[1] Heidi J.Phrasal cohesion and statistical machine translation[C]//Proceedings of EMNLP 2002:304-311.
[2] Dekang Lin.A path-based transfer model for machine translation[C]//Proceedings of COLING 2004:625-630.
[3] Chris Quirk,Arul Menezes,Colin Cherry.Dependency treelet translation:Syntactically informed phrasal smt[C]//Proceedings of ACL 2005:271-279.
[4] Deyi Xiong,Qun Liu,Shouxun Lin.A dependency treelet string correspondence model for statistical machine translation[C]//Proceedings of the second workshop on Statistical Machine Translation.Assocication for Computational Linguistics,2007:40-47.
[5] Jun Xie,Haitao Mi,Qun Liu.A novel dependency-tostring model for statistical machine translation[C]//Proceedings of EMNLP 2011:216-226.
[6] Yang Liu,Qun Liu,Shouxun Lin.Tree-to-string alignment template for statistical machine translation[C]//Proceedings of ACL 2006:609-616.
[7] David Chiang.Hierarchical phrase-based translation[J].Computational Linguistics,2007,33(2):201-228.
[8] Huihsin Tseng,Pichuan Chang,Galen Andrew,et al.A Conditional Random Field Word Segmenter[C]//Proceedings of Fourth SIGHAN Workshop on Chinese Language Processing.
[9] Franz Josef Och,Hermann Ney.A systematic comparison of various statistical alignment models[J].Computational Linguistics,2003,29(1):19-51.
[10] Dan Klein,Christopher D.Manning.Fast exact inference with a factored model for natural language parsing[C]//Proceedings of Advances in Neural Information Processing Systems 15NIPS,2003:3-10.
[11] Andreas Stolcke.Srilm—an extensible language modeling toolkit[C]//Proceedings of ICSLP,2002,30:901-904.
[12] Franz Josef Och.Minimum error rate training instatistical machine translation[C]//Proceedings of ACL 2003:160-167.
[13] Kishore Papineni,SalimRoukos,Todd Ward,Wei Jing Zhu.Bleu:a method for automatic evaluation of machine translation[C]//Proceedings of ACL 2002:311-318.
猜你喜欢
大连民族大学学报(2021年2期)2021-07-16
疯狂英语·新悦读(2020年2期)2020-04-29
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
北方文学·中旬(2016年6期)2016-08-01
考试周刊(2015年36期)2015-09-10
文理导航(2015年16期)2015-06-18
科学中国人(2014年22期)2014-07-23
