
判别式藏语文本词性标注研究
2014-04-14 07:50华却才让赵海兴
中文信息学报 2014年2期
华却才让,刘 群,赵海兴
(1.陕西师范大学计算机学院,陕西西安710062;2.青海师范大学计算机学院,青海西宁810008;3.中国科学院计算技术研究所智能信息处理重点实验室,北京100190)
1 引言
藏语词性标注(Part-of-Speech Tagging,POS Tagging)作为藏语自然语言处理中一个基础研究工作,目标是给藏语文本中每个词语指派一个正确的分类标记。其成果可应用于句法分析、语义分析、形态分析以及机器翻译,对藏文信息处理技术的发展具有重要意义。目前藏语词性标注还处在研究阶段,还没有可实用的词性标注工具。本项目组研发了基于感知机训练模型的判别式藏语自动分词系统,在领域较广泛的500句藏语语料上的测试准确率为96.8%[1],已在2011年藏汉机器翻译评测中得到了应用。本文以青海师范大学制订的“信息处理用藏语词类标记规范”为词性标记集[2],首先回顾藏语词性标注的相关研究工作,重点分析本文提出的基于感知机词语标注训练模型、符合藏语词法特性的特征选择和解码标注方法,经实验证明,在573句人工标注的语料上进行了相关实验,取得了较好的效果。
2 相关工作及词语分类难点
2.1 相关工作
近年来藏语词性标注方面开展的研究工作大致包括三个方面:(1)词性规范。(2)词性词典和标注语料库建设。(3)标注系统的开发。才让加等2005年提出并制订了《信息处理用藏语词类标记规范》(讨论稿),该规范规定了信息处理中藏语词类17个大类,21个一级类和60多个二级词类,给出了相应的词性标注代码[2]。扎西加等结合《语门文法概要》、《词论》和《新编藏语文法》等书籍中藏文词语分类,探讨了藏语自然语言处理中的词类划分,词语划分为26个基本类和9个特殊类[3]。2009年,才智杰、才让加等构建了9万多条藏语词性标注词典,并结合词性词典开发了基于规则的班智达藏语词性标注系统[4],在封闭语料上测试,取得了较好的效果。2010年,扎西加等标注了近4万多条规模的藏语词典[3]。2011年,史晓东等用HMM方法将汉语分词系统移植到藏语分词,实验对分词取得了93%的精确率、83.174%的词性标注精确率[5]。另外青海师范大学、西藏大学和西北民族大学等在词性标注语料库的建设方面做了大量工作,相继构建了较大规模的标注语料库。藏语词性标注的研究相对分词较少,而且相对于98%的汉语词性标注精确率[6]和藏语96%的分词精确率,藏语词性标注的精确率还比较低,目前还存在比较大的提升空间。
2.2 词语分类难点
藏语词语分类同样存在许多棘手的问题,其中主要的困难可归纳为:(1)藏文文法中对实词、格助词、不自由虚词、自由虚词和动词等给出了较详细的定义和语法范畴。格助词和虚词有具体形式标志、接续规则和用法,而动词具有现在时、过去式、将来时和命令式等屈折形态结构变化,但是书面藏语中能发生屈折变化的动词仅占整个单音节动词60%左右[7],因此藏语词语类别无法完全从形态变化上判别。(2)藏语中词语兼类现象比较严重,尤其是常用词具有不同的用法。例如,图1所示的一个句子中出现了5个兼类词。根据我们对现有人工标注的1.1万句语料(包括13.3万个词)的统计,发现兼类词占到2.7%(包括1 043个兼类词),但是兼类词的词次占到了24.2%(包括32 077个词次的兼类词)。兼类类别包括两类、三类和四类等兼类,其中两类兼类包括动词和名词、数词和名词、数词和疑问词、属格和后缀、名词和终结词、代词和接续词、于格和名词、从格和名词、人名和一般名词、地名和一般名词、方位词和名词、语素和名词等兼类;另外还存在未登录词(特殊的兼类词)。在我们的方法中,未对该类词依据上下文特征统计分值判别为唯一的词性之前,认为该词为所有可能的词性的兼类词,因而藏语文本中词类歧义排除的任务量比较大,成为了词性标注的首要任务。(3)词性标注规范,到目前藏语还没有一个统一的被广泛认可的藏语词类划分标准,词类划分的粒度和标记符号不统一。例如,青海师范大学的藏语分类标记集中共有66个代码,西藏大学藏语词类标记集共有26个基本类和9个特殊类。因此对标注语料的共享和信息处理带来了一定的困难。

图1 词性标注实例
3 感知机训练模型
3.1 词性标注模型
基于感知机文本序列标注方法是一种在线的学习方法,在句法分析[7]中取得了比较好的效果,具有易定义特征、训练速度快和分类效果好等特性。此方法同样在Unicode编码藏语分词中得到了验证[1]。设输入句子xi∈X,输出标注序列yi∈Y,X表示训练语料中的所有句子,Y表示对应的词性标注结果。本文采用青海师范大学制订的词性标注规范,其中藏文词语词性代码包括66个。那么最佳词性标注序列为

其中Φ(xi,yi)表示输入句子和产生标注序列的特征向量,→w表示训练后得到的特征权重。
3.2 特征选择
感知机在线训练方法的特点是易定义特征,而特征模板的定义和选择恰恰是判别式分类方法的关键。本文考察了影响藏语句法和词法结构的多种因素,归纳为(1)藏语的主宾谓语序中,动居句尾、物主词居前、位置词居后、形居名后[8];(2)藏语动词形态分“三时一式”、使动与非使动、自主与不自主;(3)主格、属格、于格和从格等主要格词类具有固定的接续特征,且与形态动词相关[9]。接续规则与前一个词的最后一个音节的后置字相关,譬如,(冰箱内外的温度)”中属格的接续要参照词的后置字考虑到藏语词法特征,本系统确定了训练和解码特征模板,见表1。藏语词性标注训练特征模板内容分五类:(1)一元特征:单个词的特征信息;(2)二元特征:由两个词的共同特征信息构成;(3)三元特征:由当前词和其前后两个词的特征信息构成;(4)五元特征:由特征窗口范围内所有词的特征信息构成;(5)词接续特征:由藏语格助词接续规律及动名词结构相关的特征等信息构成,其中后者由表示行为或动作的名词(nv)相关的特征信息构成。

表1 藏语词性标注训练特征模板
3.3 特征权重的训练
选择了感知机训练用特征模板后,关键的核心任务是在人工标注训练语料上进行特征权重的训练,以构建感知机模型,本文为防止过拟合现象采取了平均特征权重。词性标注平均感知机权重训练如算法1所示:GEN(x)产生输入句子xi的候选标注结果,Φ(xi,yi)表示输入句子和产生标注序列的特征向量,选择×Φ(xi,yi)得分最高的标注序列。ti表示正确(训练实例)的标注序列。用正确标注序列的特征向量和产生的最好标注序列的特征向量之差更新权重,累加后取平均为→w。辅助权重向量v用于累加每次迭代后权重。
算法1 词性标注平均感知机权重训练算法
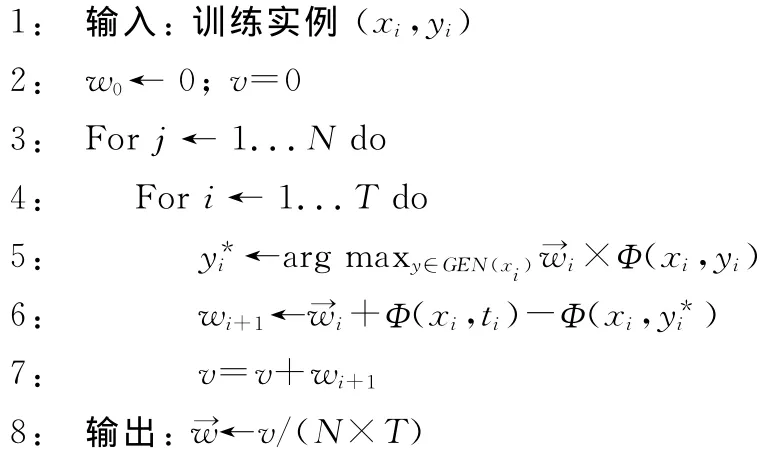
4 词性标注过程
词性标注过程实际为利用已经训练好的感知机模型,句子中按词序列分别对每个词可能的词性获取其上下文特征分数,计算其特征权重,累加句子中每个词性标注序列上所有权重,权重最高的为最佳标注序列。从训练语料和词性词典统计得每个词可能的词性有66个,计算量比较大,因此用词性词典确定每个词可能的词性,然后用Viterbi算法得出每个词可能的权重。藏语词性标注系统TiPosTag的总体框架见图2。

图2 藏语词性标注总体框架

图3 实例“听那人的建议不会错。”的词性标注示意图
用动态规划对句子中词序列标注时,每个词至少存在一个候选词性,最坏情况有66个候选词性,是未登录词的情况。图3所示,在实例“听那人的建议不会错。”中,多个词有两个准词性,也就是说这些词是名副其实的兼类词。其中最粗的有向箭头路径表示算法获得的最佳路径,此路径的累加权重最大,而所有实线都是可能存在的路径。由于特征集的最大窗口为4,当前准词性之前的第2个准词性到第1个词性之间,依据前者的入口可能存在多条路径,此时我们选择权重最大的那条路径。图中第2个词“”和第3个词“”之间具有属格黏着格特征,使第2个词排除了与接续词兼类可能性。这样到第3个词的gz标记可能存在dfrz和nnrz两个前驱路径,都是从rz发出,因此路径dfrz被剪枝,只选择分值最大的路径。
5 实验
我们利用基于规则的班智达词性标注系统生成词性标注语料,经人工修改后确定2.2万多句词性标注句子为感知机模型训练语料。为满足词语标注要求,词性词典是从训练语料、班智达词性词典转为UTF8编码后的9.3万多条词语、1.9千条地名词语、1.6万条人名词典以及计算机等专用词典中抽取,总共抽取到12.36万余条藏语词条。系统在人工建立的573句藏语词性标注测试集上,分别做了完全分好词的句子的标注测试和分词标注一体化测试,见藏文词性标注系统TiPosTag的性能表2。
由表2我们可以发现,系统对已经分好词的语料的分类标注明显好于分词标注一体化。此外,针对系统对测试语料中兼类词、未登录词、人名、地名以及藏语格助词接续等的分类标注结果,进行了人工分析。兼类词标注精确率为98.53%,主要错误集中在一般名词和人名的兼类;未登录词多数为名词,其标注正确率为98.23%;地名、团体和机关等的标注正确率为97.37%;数字和数词的标注正确率为100%;藏语格助词属格、主格、于格、接续格、修饰格、终结词以及兼类格助词等标注正确。

表2 藏文词性标注系统TiPosTag的性能
6 结论
在分析了现有的藏语文本词类标注方法基础上,本文提出了基于判别式模型的藏语文本词类标注方法,结合藏语词语接续和词法特征,选择了模型训练特征模板,系统用感知机拟合训练特征权重,构建了模型库。从训练语料和专用词典中抽取了12.36万条规模的词性词典,最终在573句测试集上进行了系统评测,在已经分好词的测试集上标注精确率达98.26%,分词标注一体化模式标注精确率达94.49%,基本达到了实用水平。
下一步我们计划把基于统计的藏语命名实体如人名、地名和机构名等功能模块集成到本系统中,以提高词性标注准确性。同时尝试将本系统应用于藏语依存句法和藏汉机器翻译等研究工作中。
[1] 孙萌,刘群等.基于判别式分类和重排序技术的藏文分词[C]//第十二届全国少数民族语言文字信息处理学术研讨会论文集,2011.
[2] 才让加.藏语语料库词语分类体系及标记集研究[J].中文信息学报,2009,23(4):146-148.
[3] 扎西加,珠杰.面向信息处理的藏文分词规范研究[J].中文信息学报,2009.24(3):113-123.
[4] 才智杰,才让卓玛.班智达藏文标注词典设计[J].中文信息学报,2010,24(5):46-49.
[5] 史晓东,卢亚军.央金藏文分词系统[J].中文信息学报,2011,25(4):54-56.
[6] 刘遥峰,王志良,王传经.中文分词和词性标注模型[J].计算机工程,2010,36(4):16-19.
[7] Collins,Michael.Discriminative training methods for hidden markov models:Theory and experiments with perceptron algorithms[C]//Proceedings of the Empirical Methods in Natural Language processing Conference,Philadelphia,America,2002:1-8.
[8] 扎塘·降白益西坚参.新编藏文文法[M].拉萨:西藏人民出版社,1997.
[9] 格桑居冕.实用藏文文法[M].成都:四川民族出版社.1987.
[10] 宗成庆.统计自然语言处理[M].北京:清华大学出版社2008.
猜你喜欢
客联(2022年2期)2022-04-29
西藏研究(2021年1期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
西藏艺术研究(2020年2期)2020-09-04
新世纪智能(英语备考)(2019年10期)2019-12-16
现代交际(2019年17期)2019-11-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
新世纪智能(语文备考)(2019年3期)2019-01-12
西藏研究(2017年3期)2017-09-05
