
哈萨克语阿拉伯文与斯拉夫文间的智能转换
2014-04-03 07:34萨合多拉木巴拉克古丽拉阿东别克
计算机工程与应用 2014年18期
萨合多拉·木巴拉克,古丽拉·阿东别克
Sahdolla MUBARAK,Gulila ALTENBEK
新疆大学 信息科学与工程学院,乌鲁木齐 830046
College of Information Science&Engineering,Xinjiang University,Urumqi 830046,China
随着全球经济一体化发展,中国和中亚国家的经济贸易往来日益频繁,哈萨克斯坦是一个很重要的合作伙伴,哈萨克语成为两国之间经济文化交流的重要载体。由于居住在不同地区的哈萨克族长期受到不同文化、不同历史等一些因素的影响,形成了基于同一语言的两种文字的特殊情况,阻碍了两国经济文化交流的深入发展。所以开发解决这个问题的计算机转换系统的意义很大,本文研究在Windows环境下,哈萨克语两种文字间智能转换的实现。
1 两种文字的特点
阿拉伯字母哈萨克语是以阿拉伯字母为基础的拼音文字,共有33个音(音位),其中9个是元音,24个是辅音,有些字母有两种书写形式,有些有四种书写形式,根据词里的位置,书写形式发生变化。拼写时由右向左写,词和词之间必须留有一定的空隙[1]。语音方面的特点是元音和谐和辅音同化规律,元音和谐指的是前后元音和谐,即在本族固有词汇中,前后两组元音不能出现在同一个单词中;辅音同化的特点是词中相邻的两个辅音,前一辅音影响后一辅音,随即后一辅音又导致前一辅音发生变化,称为辅音的相互通话,即同时出现辅音的前进与后退通话。
斯拉夫字母哈萨克文(西里尔文)是哈萨克族于1940年开始使用的,以斯拉夫字母为基础的文字。这种文字形式共有37个音素,42个字母。除原有的斯拉夫字母之外,还增加了9个字母,这9个字母不出现在俄语词里,是哈萨克语特有的字母。另外还有13个字母用来拼写外来语(俄语)借词时使用。因此,斯拉夫字母哈萨克标准文一般只有31个音素,从语言历史来看,哈萨克语固有词中,实际上只有24或25个音位[2]。
2 系统的主要工作
2.1 基本字母的转换(一对一)
斯拉夫字母哈文有37个音,42个字母,阿拉伯字母哈文有35个音,33个字母。这两种文字之间大部分(32个字母)是一一对应的关系,根据哈萨克语词的构成规则来对特殊情况进行一些处理之后,采用对应字母相互转换的方法来设计系统。
2.2 复合音的转换(一对多或多对一)
西里尔文中有些字母是由两个音构成的复合音,这些词在哈萨克固有词里没有音位。例如:程序把文章从斯拉夫字母哈文转换为阿拉伯字母哈文的过程中,读到这四个字母中的任何一个时,先把这个字母拆分成对应的两个斯拉夫字母,再进行转换。阿拉伯文转换为斯拉夫文时,因为这些词一般只出现在俄语借词中,所以用对应库来解决这个问题。
2.3 软音符号ь和硬音符号ъ
这两个非音素字母是不发音的。它们多是从俄语或是经俄语传入哈萨克语的单词中出现,阿拉伯字母哈文没有这两个音符[3]。从斯拉夫字母哈文转换为阿拉伯字母哈文的过程中,由于阿拉伯字母和斯拉夫字母的发音相同,所以转换时就采用了忽略这两个符号的方法。而对于从阿拉伯字母哈文转换为斯拉夫字母哈文的过程中,由于没有如何加入这两个音符的具体规则,所以采用建立对应词汇库来解决这一问题。
2.4 “И”和“Й”
哈萨克斯拉夫文中有“Й”和“И”两个字母,而在阿拉伯字母哈文中这两个字母都用同一个来代替,这就产生了到底在什么时候用Й,什么时候用И的问题。一般情况下辅音后面跟“И”,元音后跟“Й”。所以在单词中出现有时,检查它的前一个字母是元音还是辅音。
2.5 标点符号
阿拉伯字母哈文采用阿拉伯文标点符号的记法,而斯拉夫字母哈文中采用的是与英文字母相同的标点符号记法。两种标点符号中除了如表1所列的三个标点符号之外的其他标点符号是一样的。
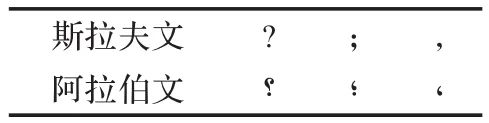
表1 两种字母的标点符号
2.6 阿拉伯字母哈萨克文中的编码错误问题
这个问题是本系统要解决的主要问题。在斯拉夫字母哈萨克文到阿拉伯字母哈萨克文的转换过程中由于斯拉夫文是怎么读就怎么写,所以不出现字母的形变现象。但在阿拉伯字母哈萨克文中的一个词中,如果有三个字母中的任何一个出现,则使得这个单词中的前元音符号不能写,所以单词里应写为的四个字写成,但发音不变。例如:“人生)这个单词中第一个字母是,在这个单词后加后缀时,因为后缀中出现了”这个字母,所以第一个字母的写法发生变化,写成字母了,所以输入员输入时直接输入了。最后阿拉伯字母哈萨克文转换为斯拉夫文时转换成了
3 哈萨克语中词的组成结构
通过分析哈萨克语词的组成结构,结合《现代哈萨克语问答》,《哈萨克语语法知识》[4]发现哈萨克语中词的构成是有一定规则的。因此,本文以词的形式结构规则为核心,再加一些限定条件,分析了哈萨克语中词的内部构成规则。
在哈萨克语的固有词(包括一些早期外来语借词)中,前一音节的元音同后一音节的元音在舌位的前后,同时在唇形方面互相制约,存在着明显的调谐,匹配的现象。词干和附加成分之间也如此,通常把多音节词里元音的这种调谐,匹配叫做元音和谐,而把这种模式叫做元音和谐律[5]。
哈萨克语的元音和谐律在音节之间以元音的前后和谐为基础,辅以圆唇元音和谐。哈萨克语元音按舌位的前后分类如表2所示。
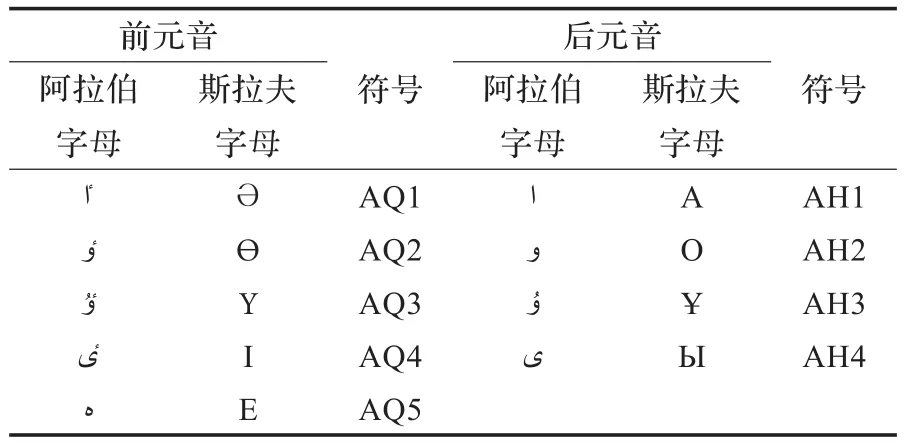
表2 哈萨克语元音按舌位的前后分类
3.1 后元音的和谐
如果词的前一音节里的元音是后音,那么后续音节(包括附加成分)里的元音也只能是后元音。
哈萨克语固有词里后元音和谐的模式,在文字上表现为:后元音后只能出现。
3.2 前元音的和谐
如果词的前一音节里的元音是前元音,那么后续音节(包括附加成分)里的元音也只能是前元音。
哈萨克语固有词里前元音和谐的模式,在文字上表现为:前元音后只能出现
3.3 外来词的词根和后缀的和谐
哈萨克语在形成和发展过程中吸收了大量的外来词,它们不受上述的哈萨克语元音和谐律的限制[7],所以本文中用数据库来解决这个问题。但对这些外来词后后续的附加成分遵守元音和谐律。
外来词借词缀加附加成分时,根据词的最后一个音节元音的性质来调配后续音节里的音节。如果外来词的最后一个音节里的元音是后元音,那么附加成分里的元音都是后元音字母,如果前元音,那么附加成分里元音都是前元音字母。
3.4 特殊字母组
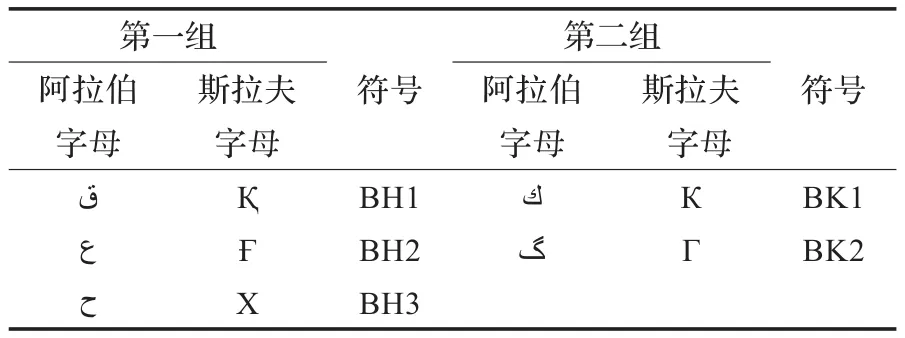
表3 特殊字母组对应表
4 哈萨克语词的构成规则集的建立
结合以上哈萨克语词的结构规则和构形附加成分集,建立了哈萨克语词的结构规则集,形式化表示如下几种。
4.1 词中第一个音节后后续的音节的规则集
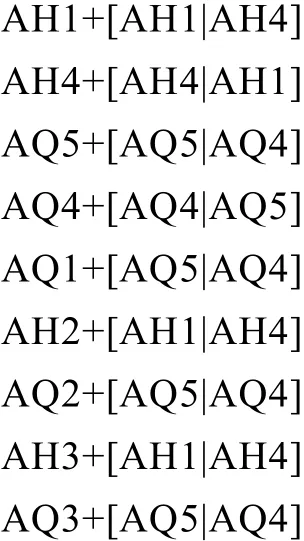
4.2 外来词的最后一个音节后后续的附加成分的音节规则集

4.3 特殊字母组的音节规则集
5 哈语两种文字转换系统
5.1 阿拉伯字母哈萨克文转换为斯拉夫字母哈萨克文
由于标准Unicode建立前,新疆哈萨克文输入法采用不同的Unicode代码来表示哈萨克文,所以在程序执行阿拉伯字母哈萨克文转换成斯拉夫字母哈萨克文前,需要先将各种不同的输入法转换为统一标准Unicode格式。然后把已载入的文本切成单词,并进行词干提取。接下来从第一个词干开始从数据库里找对应的斯拉夫文词,如果找到了,替换对应的斯拉夫文,根据词干最后音节的情况对后缀进行操作。如果从数据库中找不到对应斯拉夫文词,那么根据上述的规则对整个单词(包括词干和后缀)进行修正编码错误问题等操作。程序流程如图1所示。
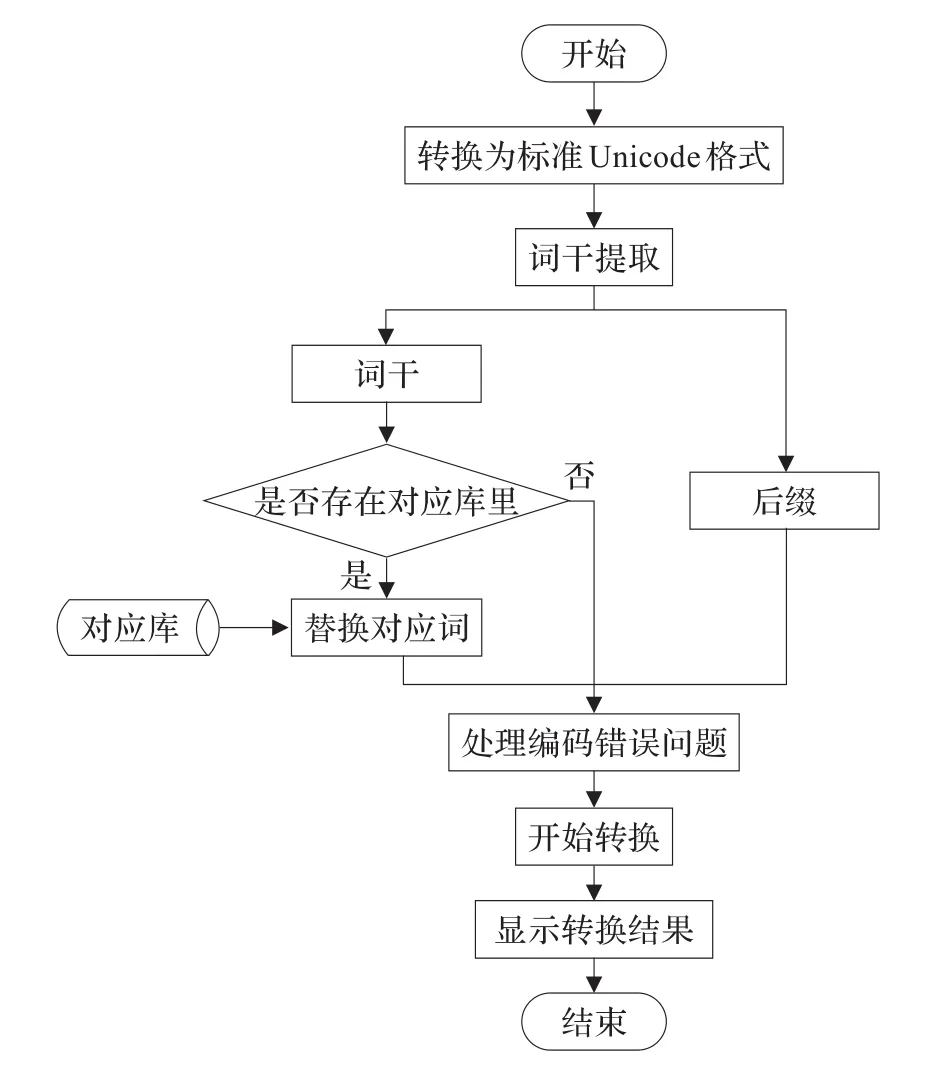
图1 阿拉伯字母哈萨克文转换为斯拉夫字母哈萨克文程序流程图
5.2 斯拉夫字母哈文转换为阿拉伯字母哈文
42个斯拉夫字母哈文中32个字母是和哈萨克阿拉伯字母一一对应的,7个字母是多对一对应的,也就是这7个字母的每一个对应哈萨克阿拉伯字母的2字母。还有两个不发音的音符,软音符号和硬音符号,它们在阿拉伯字母哈文中没有对应的字母,所以把文本从斯拉夫字母转换成阿拉伯字母时忽略了这两个音符。
6 实验结果及分析
6.1 实验结果
系统利用基于规则的方法,采用C#编写阿拉伯字母哈萨克文与斯拉夫字母哈萨克文间相互智能转换系统,系统界面如图2所示,使用哈萨克语小学语文(共有5个年级的课文)进行了测试,共有65 461个单词的文章进行转换后2 930个单词出现了错误,准确率为95.5%。
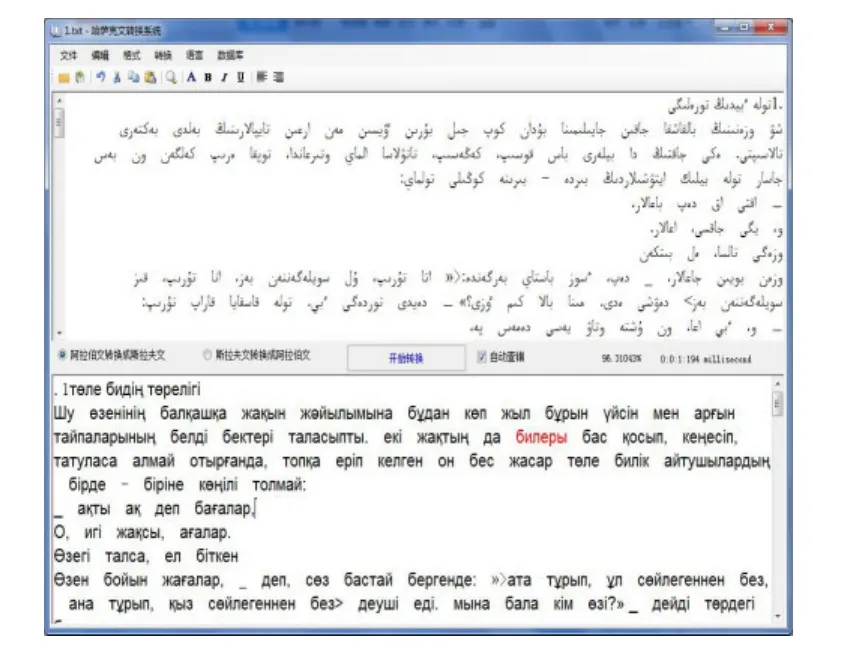
图2 程序基本的操作界面
6.2 分析
从实验结果来看,采用的方法基本令人满意,但准确率尚需近一步提高。该方法还没有达到很高的转换效率,主要原因有以下几个方面:
(1)软音符号导致的问题,阿拉伯字母哈萨克文的软音符号导致上述的编码错误问题,还加上阿拉伯字母哈语本身存在的语法问题,给哈萨克语自然语言处理工作带来很大的麻烦,本系统中也是因为这个问题下降了正确率。
(2)数据库完整性问题,数据库包括外来词,人名,地名,机构名等信息。因为中国哈萨克人和哈萨克斯坦哈萨克人对一些同一个事物有不同的名称,例如:手机,馕等词都有不同的名称,这些词不可能靠规则来转换。解决这个问题需要很长的时间和人力才能实现。
(3)哈萨克语词的构成规则有待完善。本文主要讲的是基于规则方法的转换系统,完善的哈语构词规则会更好地提高两种文字形式间转换。
7 结束语
本文分析并实现了哈萨克语两种文字智能转换的方法,建立了哈萨克语基本外来词库,为哈萨克文资料的传播和交流提供了便利。该实验方法从哈语最本质的特征出发,从宏观上总结出一些规则,比较直观地表达了哈语基本词的构成规律,但该方法还没有能够解决哈语中外来词的转换。因此,下一步将完善对应库,进一步改善哈语词的构成规则,并尝试规则和统计相结合的方法,提高哈语两种文字间智能转换系统的效率。
[1]阿里木赛依提·阿布力哈孜.哈萨克语入门[M].奎屯:伊犁人民出版社,2009.
[2]古丽扎达·海沙,古丽拉·阿东别克.我国哈萨克族词汇与哈萨克斯坦词汇间自动转换的研究[J].计算机应用与软件,2012,29(7):3-5.
[3]吴宏伟.从现代哈萨克语词的构成看原始突厥语词汇的特点[J].语言研究,1994,15(1):3-4.
[4]迪丽达.哈萨克语语法知识[M].奎屯:伊犁人民出版社,2010.
[5]努尔兰.现代哈萨克语问答[M].奎屯:伊犁人民出版社,1998.
[6]张定京.现代哈萨克语实用语法[M].北京:中央民族大学出版社,2004.
[7]蒋宏军.如何区分哈萨克语中的外来词[J].伊犁师范学院学报:社会科学版,2011,18(2):1-2.
[8]黄中祥.哈萨克词汇与文化[M].北京:中国社会科学出版社,2005.
猜你喜欢
外语学刊(2021年1期)2021-11-04
哲学评论(2021年2期)2021-08-22
延边大学学报(社会科学版)(2020年2期)2020-03-25
韩国语教学与研究(2017年3期)2017-11-30
海外华文教育(2016年2期)2017-01-20
外语学刊(2016年4期)2016-01-23
外语学刊(2016年4期)2016-01-23
外语学刊(2016年4期)2016-01-23
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2014年2期)2014-07-12
