
基于多核与众核结构的并行编程模型研究
2014-04-01 07:14:24,
中原工学院学报 2014年3期
,
(中原工学院,郑州 450007)
近半个世纪以来,处理器的计算速度基本上每18到24个月都要提升一倍。然而,由于单核处理器功耗和散热等问题的存在,通过提升芯片时钟频率来无限制地提升性能已不再可能,于是科学家们又开始了对多核、众核处理器技术的探索。
多核芯片是通过在单个芯片上集成多个核心而成的,但这种架构受到物理规律的限制,即受到功耗、互连线延时和设计复杂性等因素的制约。在这种背景下,众核[1]应运而生。所谓众核,是指在单个处理器中集成多个简单的处理器核,即指芯片中拥有大于等于8个核心的处理器。与单核和多核处理器相比,众核处理器计算资源密度更高,片上通信开销更低,更多的晶体管和能量可以胜任更为复杂的并行处理应用[2]。
从存储方式上划分,并行编程模型分为共享存储模型和分布式存储模型。而在多核处理器的实际系统中,通用计算又造就了异构并行编程模型。
本文就基于多核和众核体系结构的并行编程模型——共享存储编程模型、消息传递模型、异构编程模型和混合编程模型进行分析研究。
1 共享存储编程模型
在共享存储编程模型中,各个处理器可以对共享存储器中的数据进行存取,数据对每个处理器而言都是可访问的,不需要在处理器之间进行传送,即数据通信是通过读写共享存储单元来完成的。常见的共享内存编程模型有:POSIX Threads、OpenMP[3]。
1.1 POSIX Threads
POSIX(Portable Operating System Interface of UNIX) Threads,简称为Pthreads,是一个可移植的多线程库,它提供了在多个操作系统平台上一致的程序设计接口。在该模型中,有一些能够被单独控制的并行执行线程。Pthreads现已成为Linux操作系统中多线程接口的标准,并已被UNIX平台使用。Pthreads的主要功能集中在线程的生成、退出、互斥、同步以及一些辅助功能上。例如:
(1)线程的创建与退出 (create & exit)。任何进程在启动时就已有了一个主线程,如果需要再生成线程则使用pthread_create函数,在该函数中可以指定线程属性、线程例程、传给线程例程的参数。线程例程是线程执行的代码,是一个用户自定义的函数。当线程例程返回时,线程则结束运行,也可以通过调用pthread_exit来退出。
(2)线程间互斥(mutex)。互斥操作,就是在对某段代码或某个变量修改时只能有一个线程执行这段代码,而其他线程不能同时进入这段代码或同时修改变量.Pthreads常用pthread_mutex互斥体来实现线程互斥操作。
pthread_mutex_init函数用于初始化一个互斥体变量;pthread_mutex_lock函数用于给互斥体变量上锁,如果上锁时互斥体已经被其他线程锁住,那么调用该函数的线程将被阻塞,直到互斥体被解锁为止;pthread_mutex_trylock函数的作用是试图锁住互斥体,但在互斥体已经被加锁时不会造成阻塞,而是迅速返回;pthread_mutex_unlock函数是对互斥体解锁;pthread_mutex_destroy函数是用来释放互斥体所占资源。
(3)线程同步(cond)。线程同步就是若干个线程等待某个事件的发生,当该事件发生时,这些线程同时执行各自代码。在Linux线程中用条件变量来实现同步。函数pthread_cond_init用来创建一个条件变量。
pthread_cond_wait和pthread_cond_timewait用来等待条件变量被设置,值得注意的是这两个等待调用的函数需要一个已经上锁的互斥体mutex,这是为了防止在真正进入等待状态之前别的线程有可能设置该条件变量而产生竞争;pthread_cond_broadcast用于设置条件变量,即使事件发生,也使所有等待该事件的线程不再阻塞;pthread_cond_signal用于解除某一个等待线程的阻塞状态;pthread_cond_destroy用来释放一个条件变量的资源[4]。
1.2 OpenMP
OpenMP(open multi-processing)编程模型是基于线程的并行编程模型,是一个共享存储应用编程接口(API)。OpenMP多线程接口被特别设计,用来支持高性能并行计算程序,它包含许多编译制导指令,具有移植性好和可扩展等优点。OpenMP是由指导性注释、编译指令以及线程池管理和库例程结合在一起实现的,它与Pthreads不同,不是作为一个库来实现的。这些指令指示编译器创建线程、执行同步操作和管理共享内存等。
OpenMP中的常用函数有:
①void omp_set_num_threads(int num_threads):设置线程数目。通过该函数来指定其后用于并行计算的线程数目,其中参数num_threads就是指定的线程数目。
②int omp_get_num_threads():获取线程数目。通过该函数可以获取当前运行组中的线程数目,如果在并行结构中使用该函数,返回的就是现在并行计算中的所有的线程总数;如果在串行中使用该函数,其返回值就为1。
③int omp_get_max_threads():获取最多线程数目。该函数将返回最多可以用于并行计算的线程数目。
④ int omp_get_num_procs():获取程序可用的处理器数目。该函数将返回可用于程序的处理器数目(其实是线程数目)。
⑤ int omp_in_parallel():判断线程是否处于并行状态。该函数返回值为0时表示线程处于串行程序中,返回值为1时表示线程处于并行程序中。
2 分布式存储线程模型
消息传递模型是一种最常用的分布式存储编程模型,它是通过处理器之间的信息交换来实现通信的,适用于分布式存储系统。在该模型中,驻留在不同节点上的进程可以通过网络传递消息相互通信。它常用于开发大粒度和粗粒度的并行性。
MPI(Message Passing Interface)是一个消息传递接口的标准,用于开发基于消息传递的并行程序,其目的是为用户提供一个实际可用的、可移植的、高效和灵活的消息传递接口库。因此,使用MPI,必须要和特定的语言如FORTRAN和C语言等结合起来[5]。
POSIX Pthreads、OpenMP和MPI等3种并行编程模型属于共享存储模型或分布式存储模型。表1概括了3种编程模型在通常实际应用中的实现特性[6]。

表1 3种并行编程模型实现特性
3 异构并行编程模型
异构并行编程模型主要是针对异构计算机系统的并行编程。异构计算机系统是由功能或性能相异的处理器通过一定的互联结构连接起来的计算系统,一般由通用微处理器和专用加速器构成。通常实际应用较多的异构并行编程模型有:CUDA、Opencl。
3.1 CUDA
CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA公司开发的一种并行编程模型,它是一种将GPU作为数据并行计算设备的软硬件体系。此外,CUDA提供了一个允许开发者使用C语言或者更高级语言的软件环境。对于CUDA来说,一个并行系统包含一个主机(Host)和计算资源或者设备(device)。CUDA编程模型通常将CPU作为主机,GPU作为设备或者协处理器(co-processor)。计算任务是在GPU中依靠一组并行执行的线程来完成的。CUDA将计算任务映射为大量的可以并行执行的线程,通过硬件动态调度来执行这些线程。
CUDA的线程结构包含2个层次结构:Grid(线程网格)和Block(线程块)。由图1所示的CUDA存储结构可以看出,这2个层次内也存在并行,即Grid中的Block间并行和Block中的Thread间并行。
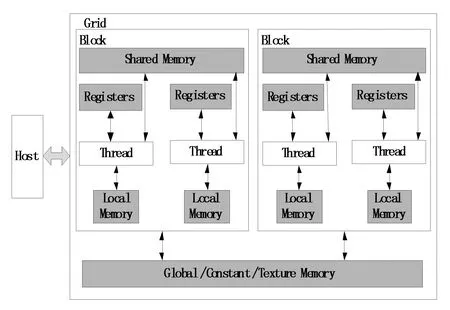
图1 CUDA存储结构
CUDA的体系结构是以Grid的形式组织的,每个Grid由若干个Block组成,而每个Block又由若干个Thread组成,它们都拥有自己的ID,用以和其他线程相区分。在图1的底部,Global Memory(全局存储器)和Constant Memory(常数存储器)能够被主机代码写入和读取。常数存储器允许设备只读访问,在Block里,可以有共享存储器、寄存器或本地存储器,共享存储器能够在Block里被所有的线程访问,而寄存器则对每一个线程都是独立的。同一个Block中的线程通过共享存储器交换数据,并通过栅栏同步保证线程间能够正确地共享数据,从而实现Block内通信。
通常情况下,一个完整的CUDA程序包括在Host上执行的串行代码以及在GPU上并行执行的程序(kernel函数)。在图1中,每进行一次GPU计算,需要在多种存储器之间进行数据传输,这会消耗大量的时间,造成延迟,因此,单独的CUDA并不适合于一些对实时性要求很高的应用,往往还需要与CPU搭配协同运行[7]。
3.2 OpenCL
OpenCL(Open Computing Language,开放计算语言)是一个在由CPU、GPU和其他类型处理器组成的异构平台上进行通用并行编程的免费的标准。它是由用于编写kernels(在OpenCL设备上运行的函数)的基于C99的语言和一组用于定义并控制平台的API组成。
OpenCL操作规范模型可描述成4个相关的模型:平台模型、执行模型、内存模型、编程模型。
平台模型:描述了协同执行的单个处理器及能执行OpenCL代码的处理器,定义了一个抽象的硬件模型,让开发者能够编写在这些设备上执行的kernel。
执行模型:定义了如何在主机上配置OpenCL环境,以及如何在设备上执行kernel。
内存模型:定义了被kernel所用的抽象内存层次。
编程模型:定义了如何将并发模型映射到物理硬件上。
上述4个模型,提供了基于任务和基于数据的2种并行计算机制,极大地扩展了GPU的应用范围,而且由于它是跨平台的基于异构的编程模型,在今后很长一段时期,还将会持续得到发展[8]。
4 混合编程模型
混合编程模型是将共享存储和分布式存储编程相结合的一种方法,它在节点之间使用消息传递来发送和接受数据,在节点内通过共享内存来进行数据运算,充分利用了两种编程模型的优点[6]。这种混合编程模型也非常符合当今混合硬件体系结构的发展趋势。实际应用中出现的主要混合并行编程模型有:MPI+OpenMP,CUDA+OpenMP,CUDA+MPI等。
4.1 MPI+OpenMP
MPI可以解决多处理机间的粗粒度通信,而OpenMP提供的轻量级线程可以更好地解决每个多处理器计算机内部各处理器间的交互,通常在用MPI实现的原始程序中加入OpenMP编译制导语句,就能使程序转化为MPI和OpenMP混合编程模式的程序,原理如图2所示。
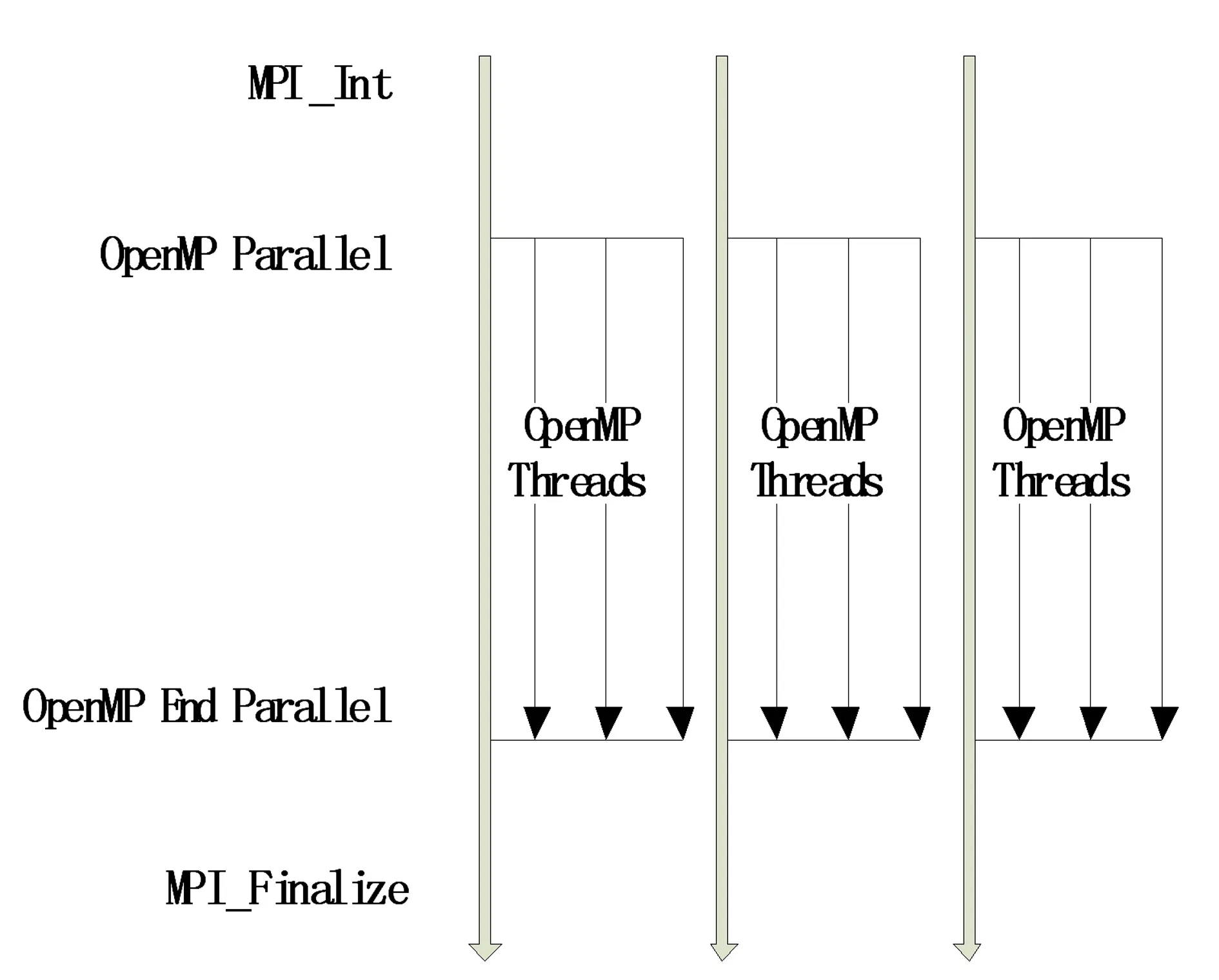
图2 MPI+OpenMP混合编程模型
下面给出简单的细粒度混合编程模型代码:
......
MPI_INIT_THREAD();//初始化进程,使其具有多线程功能
MPI_COMM_RANK();
MPI_COMM_SIZE();
.....MPI communiaciton and some computation
#pragma omp parallel//调用OpenMP
#pragma omp for//多个线程并行地执行for循环的代码
for(...)
{.......computation
}
......computation and MPI communication
MPI_FINALIZE();
3.1.3 进样精密度与重复性 取“2.4.5”项下中间浓度对照品溶液,按“2.1”项下方法进行检测,连续进样6次,硫酸盐峰面积的RSD为0.5%(n=6),表明仪器精密度良好。精密称取注射用硫酸核糖霉素样品,共6份,按“2.4.2”项下方法配制供试品溶液,同法检测,6份样品硫酸盐含量的RSD为0.9%(n=6),表明重复性良好。
4.2 CUDA+OpenMP
该混合模型是在CUDA模型的基础上,通过在执行主程序时加入OpenMP编译制导语句,在CPU端产生大量的线程,这些线程一方面控制GPU,调动kernel函数并行执行分配给GPU的计算任务,另一方面也能够并行化处理在主机上的串行程序,因此在整体上提高了程序的执行效率。其不足之处是CPU和GPU之间的数据传输将会影响到GPU的计算效率。这种模型通常适合多GPU的系统。该模型的简单代码框架如下:
//主机端程序
#include
#include
#include
_global_[......]//CUDA内核程序kernel
......
Main Program
cudaGetDeviceCount(&num_gpus);//获得系统中支持CUDA的GPU数量
//显示GPU与CPU的信息
printf("number of host CPUs: %d ",omp_get_num_procs());
printf("number of CUDA devices: %d ",num_gpus);
......
#pragma omp parallel
...... //并行执行kernel
......
parallel_execute_host_code//执行host上的串行代码
......
...correctsult()//检查对比CPU和GPU的结果
4.3 CUDA+MPI
这种模型也是一种基于CPU和GPU的异构模型,充分利用了MPI在节点间进行消息传递和在节点内进行大量线程计算的特点,非常适合实现集群或者超级计算机中的多节点多GPU并行计算。在这个模型中,MPI用于控制程序、节点间通信和数据调度以及CPU之间的交互,而CUDA负责在GPU中的计算任务。
下面为该混合模型的部分关键代码:
/*声明对MPI以及标准库的引用*/
#include"mpi.h"
#include
......
//启动CUDA函数
#if_DEVICE_EMULATION_
Bool InitCUDA(int myid){return true;}
#else
.......
//获得CPU所在节点中的CUDA设备数量,没有则返回
cudaGetDeviceCount(&count);
if(count==0){
fprintf(stderr,"There is no device. ");
return false;
}
......
_global_[......]//设备端kernel函数的定义和调用
......
//启动MPI环境
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
......
execute_kernel();//执行内核函数
......
MPI_Finalize();
}
从上面几种模型中不难发现,没有一种混合编程模型完全适用于当今所有的计算机体系结构。因此,只能选择那些最适合于硬件宿主特性的编程模型,才能最大程度地提高并行程序的性能。
5 结 语
随着未来计算机微处理器朝着众核处理器方向的发展,以及大规模机群的不断出现,原来单一的编程模型已很难适应这种新的体系结构,因此,基于异构平台的混合并行编程在今后的大规模并行应用中必将成为主流。
参考文献:
[1] Feng Wu-chun , Balaji Pavan.Tools and Environment for Multicore and Many-core Architectures[J].IEEE Computer, 2009, 42(12): 26-27.
[2] 范平.芯革命新未来 英特尔开启MIC时代 [EB/OL]. (2013-06-08).http://server.zol.com.cn/246/2468105_all.html.
[3] 陈明. 反投影算法在双基地合成孔径雷达成像中的应用[D].北京:中国科学院研究生院,2007.
[4] 刘明刚.基于嵌入式Linux的开放式数控系统研究与实现[D].成都:电子科技大学,2005.
[5] 张玉斌. 迭代动态规划算法及并行化研究 [D].青岛:中国石油大学,2008.
[6] Javier Diaz,Camelia Munoz Caro,Alfonso Nino.A Survey of Parallel Programming Models and Tools in the Multi and Many-core Era.[J].IEEE Transactions on Parallel and Distributed Systems, 2012, 23(8): 1368-1386.
[7] 张舒,褚艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009:13-44.
[8] Benedict R Gaster,Lee Howes,David R Kaeli,et al.OpenCL异构计算[M].张云泉,张先轶,等译.北京:清华大学出版社, 2012:15-26.
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
环球市场(2017年36期)2017-03-09 15:48:21
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
汽车零部件(2014年10期)2014-11-11 12:25:04
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
