
基于数据挖掘的高校人才科研能力综合评价方法研究
2014-03-05 08:13:52庄新田
东北大学学报(社会科学版) 2014年6期
谭 雷,庄新田,韩 鹏
(1.东北大学 工商管理学院,辽宁 沈阳 110819;2.东北大学秦皇岛分校 人事处,河北 秦皇岛 066004;3.东北大学 信息科学与工程学院,辽宁 沈阳 110819)
科研人才是支撑国家和区域经济发展的核心因素[1-2],也是高校竞争中重要而稀缺的资源。人才具有的综合科研能力是高校的核心竞争力,直接决定了整个高校的科研水平和发展潜力。因此,科学评价高校人才的科研能力、合理划分高校人才梯队层次、制定符合高校人才梯队发展的人才工作措施,已成为近年来各大高校人才工作的研究热点。
人才科研能力的多样性要求现代高校的人才管理应更具人性化、科学性和适应性[3]。目前国内高校人才工作中存在着人才观念陈旧、人才管理机制滞后、人才引力不够等问题,针对这些问题的研究主要依托工作经验、绩效推断法与传统人力资源理论[4],缺乏科学有效的信息技术作为支撑,无法适应高校人才数量的增长和类型的多样化,难以满足新时期人才工作的要求。而数据挖掘技术能很好地适合海量、动态的高校人才信息,因而受到各界的广泛关注,并在国内高校的人事工作上得到了初步应用。其中,高建伟等[5]研究了数据挖掘在引进人才尤其是引进高层次人才研究中的应用,但是其关联分析置信度较低,影响了所提策略的可用性;白菲等[6]采用数据挖掘的方法对高校人才库进行了分析,但是其仅利用了人事信息而未考虑科研信息中的重要评价指标对人才类型划分的影响;郑春香等[7]应用数据挖掘技术对高校人力资源数据源中的信息进行分析,但其方法不能得到每一类关联的置信度等信息;李峰等[8]研究了人才科研指数与人才水平的关系,但是其采用基于K-means算法的聚类方法,存在无法处理分类型变量、易受极端数据值影响的弱点[9],不利于大规模的人才信息处理。
综合既有的研究成果,本文基于数据挖掘技术,根据高校人才的科研数据特点,设计适用于高校人才工作的数据挖掘分析方法,并将相关参数结合信息库和数据挖掘平台,制作程序模块,从而实现高校人才科研能力批量、实时跟踪评价。
一、适用于高校人才的数据挖掘分析方法
1.高校人才的科研能力在数据方面的特点
高校人才的科研能力在数据方面有许多特点。首先,人才的评价因素多样、数据类型复杂、条目繁多,数值呈现出天然的异构性;其次,高校人才群体呈现天然的多层次性,由于高校人才的科研路径、时间、背景、成果存在不同,其科研水平的表现形式具有方向性的差异;再次,人才的影响因素具有变化性,科研能力的影响因素不仅取决于个体本身,还受到资源与团队等诸多外界因素的影响。因此,对于复杂多样而且嬗变的高校人才信息影响因素,传统人事工作中的人才测评或胜任力模型难以胜任,而数据挖掘技术为解决这类问题提供了新的方法。
2.人才科研能力测评方法的构建
本文基于数据挖掘技术进行人才科研能力的建模。数据挖掘(data mining)是一门涉及数理统计技术、人工智能及知识工程等领域的新兴交叉学科[10]。数据挖掘又称数据库知识发现(KDD),是从大量的、不完全的、有噪声的、模糊随机的数据中提取未知但有价值的信息和知识的复杂过程,是一类深层次的数据分析方法[11]。本文主要采用数据挖掘中的聚类分析、关联分析方法对高校人才数据库进行数据挖掘。其中,聚类分析通过选择一定的评价指标作为细分变量,按照一定的划分标准对人才群体进行分类;关联分析用于发掘大量数据中项集之间有意义的关联,在人才评价指标信息与人才类型之间进行规则挖掘,以期寻找影响人才发展的主要因素。通过聚类分析和关联分析,进而构建科研能力评价模型,使数据库中海量异构的信息得到有效整合,汇聚、抽取、提升为规律性强的、可用性高的科研能力信息,使有关政策有的放矢,为科技人才管理提供有用的决策信息,从而帮助高校人事部门改进人才引进策略和激励方案。
二、高校人才科研能力聚类分析
1.人才科研能力评价指标的划分
科研能力评价指标体系主要来源于创新投入、创新产出、创新资源三个方面[12]:创新投入认为创新能力的来源在于创新投入,主要从资金、人力投入等方面提取评价指标;创新产出认为传统的科研创新产出反映了科研与创新能力,主要从论文、专著、专利、承担项目、科技成果奖励及人才培养等方面总结评价指标;创新资源认为科研创新能力的强弱与参与科研的人力资源和设备资源等相联系,主要从人员、设备、设施等方面提出评价指标。通过对组织科技创新能力评价和某高校现有人才科研能力与科研成果的梳理,本文综合借鉴以上三种观点,通过咨询相关专家,同时结合高校实际情况,选取了具有代表性的科研能力评价指标,见表1。

表1 科研能力评价指标
2.评价指标数据库的样本聚类预处理
首先对样本进行分析和预处理,由于样本总体的人事数据与科研数据的来源的统计方式不同,汇总的样本包含大量异构信息,因此须先通过数据筛选、清洗、离散化等预处理步骤,实现数据的规范化。本文根据特征变量值离散化准则,对表格进行匿名化和编码,对特征值较多的范围型特征变量进行离散化,概化为较少的特征值,以加快聚类处理速度,获得优良的聚类结果。预处理后的样本向量如下:
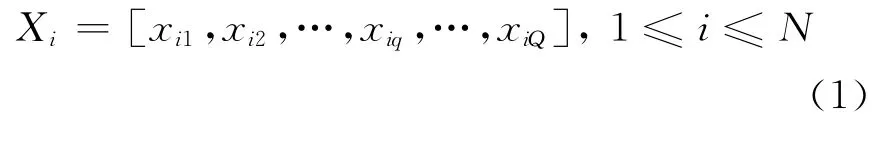
其中,N为样本集合的容量;xiq为样本集合中第i个样本Xi中的第q个属性值。
3.基于两步聚类算法的聚类分析
两步聚类(two-step clustering)算法首先通过预聚类对样本集合进行粗略划分,进而根据亲疏程度差别进行对子类的合并,实现聚类[12]。该算法克服了K-means算法的缺点,能够有效诊断样本中的离群点和噪声数据。采用数据挖掘平台SPSS Clementine搭建聚类分析数据流如图1所示。
其中,人事数据与科研数据经合并、过滤后,填入各评价指标,并经由分箱标准化后采样输入两步聚类算法。为进一步提高聚类的准确性,对数值型聚类变量采用F检验法进行检验,令假设为各聚类变量均值无显著差异;对分类型变量采用卡方检验法进行检验,零假设为各类别分布无显著差异。运行建立的聚类分析数据流,即可获得所用数据库的聚类分析结果。
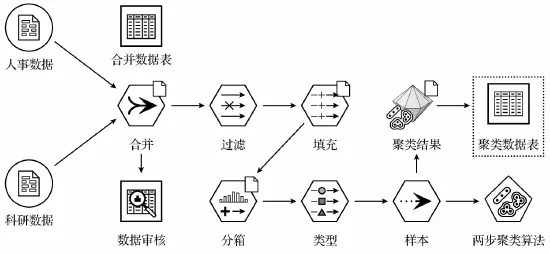
图1 聚类分析数据流图
三、高校人才科研能力关联分析
1.基于Apriori算法的关联分析
在聚类分析的基础上,为充分利用其分析结果,发现人才各个评价因素与人才科研能力类型的关联规律性,为人事部门在人才引进、选拔等工作提供数据支撑,本文采用关联分析对聚类结果进行进一步挖掘,采用基于两阶段频集思想的Apriori广度优先算法,其利用频繁项集非单调性,自底向上地搜索整个数据源,通过迭代检索出事务数据库中所有频繁项集,进而利用频繁项集构造出满足预设条件的关联规则[13]。本文对所用数据进行关联分析的数据流如图2所示。
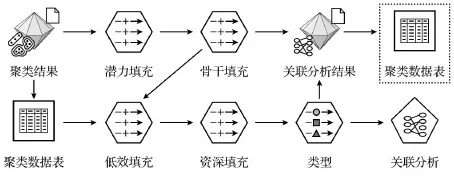
图2 关联分析数据流图
2.关联分析的结果筛选
本文利用支持度、置信度对关联分析结果进行了筛选。其中支持度反映关联是否是普遍存在规律,对于关联规则M⇒N,可表示为:

可信度反映本研究所得关联规则的预测强度,即规则成立概率。M⇒N的可信度求解公式如下:
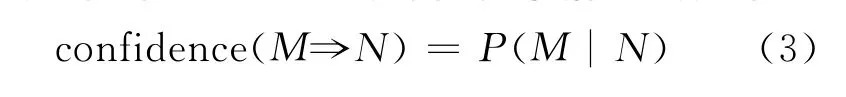
四、算例分析与提升策略
1.算例构建与计算机仿真
本文随机抽取某高校的科研人员,组成样本数为379的总体,选取了该高校最新的研究人员人事数据与近三年的科研累计数据,基于预设的评价指标基于SPSS Clementine平台进行计算机仿真实验,并对仿真结果进行了分析。
选取检验统计量为1.0的聚类变量组成聚类结果,经整理后发现,该校人才样本被明显划分为四类。根据其聚类变量的整体表现,将其分类为骨干、潜力、资深、低效四种类型的人才。其中,骨干型人才的整体年龄、教龄较小,多来自于该校和除该校以外的985高校的优秀博士,职称集中于副高级和中级职称。这类人群呈现很高的论文写作、活动参与和纵向项目开发能力,发表论文质量较高,但在学术组织中参与较少,横向项目开发能力较弱;潜力人才主要由包括本校在内的国内985/211类院校的普通博士、硕士毕业生组成,年龄、教龄均很小,各方面科研能力尚未起步,整体职称较低;资深型人才主要由学校中年龄、教龄较大的高级/副高级专家组成,他们积极参与学术组织并担任管理职务,具有良好的科研水平、项目开发能力与科研活动能力,横向项目开发能力尤其突出,其学历和来源学校受历史原因的影响而呈现出多样性;低效型群体包含教龄、年龄大,职称低,尚无明显科研成果的中年教师群体。
进一步采用所提关联分析方法确定评价因素与科研能力类型的联系,经筛选后各类型人才的典型关联规则如表2所示。

表2 各类人才分类典型关联规则 %
由表2可知,具有较高支持度和置信度的关联规则与聚类分析得到的各类型人才特征基本匹配,且得到了适用于判断各类型人才的基本方法。
2.基于数据挖掘的提升策略
在对该校人才科研能力类型与评价因素进行充分的聚类分析和关联分析基础上,结合关联规则和工作经验,进一步细化和制定各类人才的考核方法,以利于对现有人才考核办法进行科学修订,设计更好的人才评价体系。由本算例结果可得出以下主要结论:
(1)学缘关系对该校科研情况影响较大。过半数留校教师对学校的科研工作没有明显贡献,其中非博士群体更为明显;与之相对,从985高校引进的博士研究生均在入校短时间内呈现出良好的科研能力。因此该校人才引进中应根据学校的实际情况,制定切实可行的高层次人才引进的战略规划,注重引进其他985高校的高学历人才,并在现有科研队伍中促进不同的一流高校毕业教师的学术交流,改善该校的学缘结构。
(2)骨干人才中学术组织参与度与横向项目开发能力较低。学术组织是科研人员拓宽视野、展现能力的有效平台,该校的这一资源主要被资深型人才群体掌握,而骨干型人才对学术组织的参与度较低,且资深型群体通过广泛的学术关系与积累,在承担横向项目方面占据优势。因此应充分发挥资深型人才作为学校宝贵资源的价值,鼓励骨干型人才与之进行充分交流,加强骨干型人才的学术交际,进一步增强其横向科研能力。
(3)各类型人才的科研能力差异化明显。针对目前该校各类型人才的科研能力在各个评价指标上均呈现明显差异的情况,亟需针对不同类型设置富有针对性的人事/科研工作策略。对于骨干型人才宜采用较强的正向激励制度,通过设置种子基金、科研经费、奖金等方式,进一步提高其科研水平,加速人才成长,形成拔尖梯队,同时帮助其进行各类奖项、项目的申报,加速产生在国内外具有重大影响的科研成果;对于资深型人才应进行针对性的细致工作,充分发挥每一位资深专家的资源性价值,带动学校整体科研能力的提高;对于潜力型人才应加强引导,鼓励其加入骨干人才的科研院所,共同组成优秀的学科梯队,构成该校科研的储备力量,并为他们制定切实可行的发展计划,提供各类进修机会,保证科研队伍的可持续发展;对于低效型人才,其较低的科研效率不但会造成资源的浪费,也会制约学校整体科研水平的提升,因此在其考核指标中应制定负激励措施,正确引导其价值取向,促使其加紧科研工作,并引入淘汰制度,对于能力表现不适于从事科研工作的人员进行筛选淘汰。
五、结 语
本文基于数据挖掘技术划分了适用于高校人才科研能力考察的评价指标,在此基础上提出了采用聚类分析和关联分析进行人才科研能力的评价方法,并利用SPSS Clementine数据挖掘平台对其进行了实现。通过该平台,以某校人才数据为算例进行了采样和数据挖掘。算例表明本文所构建的科研能力评价方法能够很好地体现出人才的科研特征,具有较强可操作性。在今后的工作和研究中可进一步利用数据挖掘技术对所提方法进行检验和修正,通过实际工作的运用进一步检验研究成果的可用性,不断提高该方法的准确率,使之成为高校人事工作的重要信息支持工具,更好地为高校科研人才服务。
[1] 王疐曈.辽宁实施人才强省战略面临的问题与对策研究[J].东北大学学报:社会科学版,2005,7(6):422-425.
[2] 张兰霞,金环.高层次人才队伍建设与东北老工业基地振兴[J].东北大学学报:社会科学版,2004,6(2):111-114.
[3] 高艳.人力资源管理理论研究综述[J].西北大学学报:哲学社会科学版,2005,35(2):127-141.
[4] 陈慧.人力资源管理研究综述[J].北京邮电大学学报:社会科学版,2002,4(3):26-30.
[5] 高建伟,罗省贤.数据挖掘在人才引进中的应用[J].四川师范大学学报:自然科学版,2005,28(1):123-126.
[6] 白菲,孟超英.数据挖掘技术在高校人才引进中的应用[J].太原大学学报,2005,6(4):52-55.
[7] 郑春香,董甲东.分类挖掘技术在高校人事管理中的应用[J].信息技术,2006(10):53-55.
[8] 李锋,尹洁,吴洁,等.基于数据挖掘的高校人才引进与培养策 略研究 [J].科技进步与对策,2010,27(12):149-151.
[9] Amorim R C,Mirkin B.Minkowski Metric,Feature Weighting and Anomalous Cluster Initializing in K-means Clustering[J].Pattern Recognition,2012,45(3):1061-1075.
[10] Fayyad U M,Piatetsky-Shapiro G,Smyth P,et al.Advances in Knowledge Discovery and Data Mining[M].Palo Atto:American Association for Artificial Intelligence Press,1996:101-106.
[11] 熊平.数据挖掘算法与Clementine实践[M].北京:清华大学出版社,2011:2-4.
[12] 吴小妹,陈敏玲,缪仁炳.基于科技创新人才信息平台数据挖掘的科研能力评价模型研究[J].科技通报,2011,27(1):154-160.
[13] 薛薇,陈欢歌.Clementine数据挖掘方法及应用[M].北京:电子工业出版社,2010:279-286.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电子测试(2017年15期)2017-12-18 07:19:27
电力与能源(2017年6期)2017-05-14 06:19:37
读者(2017年5期)2017-02-15 18:04:18
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
