
社交网络账号的马甲关系辨识方法
2014-02-28 01:26许洪波
中文信息学报 2014年6期
樊 茜,许洪波,梁 英
(1. 中国科学院计算技术研究所 网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学,北京 100049)
1. 引言
当前,全球超过15亿人使用社交网络,全球社交网络的月活跃用户数量超过20亿。在社交网络中,同一人拥有多个账号的情况十分常见。某人在同一网站注册多个账号时,常用的账号为主账号,而其余账号称为马甲账号,简称马甲。马甲功能中一部分是负面的,例如,利用不同账号为自己所开的讨论冲人气或推文;在主账号已有固定的朋友圈或形成固定形象时,使用马甲反对甚至诋毁他人或发表另类见解;注册成千上万个账号来发布不良信息、散布谣言、炒作或者通过卖等级高的马甲账号获益等等。这样的行为既浪费网络资源,又影响网络的安全性和公平性。
社交网站的后台实名注册实施困难,目前在国内还没有完全普及;即使网站后台是基于实名制的,但是网络言论在网站前台大都是匿名的,不易知道网络上的言论所属网络用户的真实身份。当用户在社交网络中发表不和谐言论,例如,造谣、诽谤他人、宣传不良思想等危害民众甚至国家安全的状况发生时,将社交网络中属于同一人的账号(马甲)进行同一性认定,有利于协助政府相关部门打击犯罪行为。
目前,基于语言风格进行文本挖掘识别作者身份的研究工作受到广泛关注[1],但缺少针对网络账号的马甲关系识别方面的研究。由于网络中的账号相关信息少、噪音大,真实用户信息难以获取,使得对社交网络中账号马甲关系的标注十分困难,现有研究中缺少能够有效验证其所提出辨识方法准确性的权威数据与方法。如何更好的实现网络文本的挖掘,并充分利用网络账号的其他相关数据,以及如何有效验证方法准确性等问题,都有待解决。
本文利用某论坛泄露的账号信息数据,确定了一个已知相互马甲关系的账号集合,并提出了一种基于支持向量机,将社交网络中属于同一用户的账号的关系进行辨识的方法。通过研究人物的语言风格,挖掘论坛帖子文本特征,结合账号的回复关系特征,组合账号构造特征权值向量空间表示,利用支持向量机判别账号的马甲关系。实验结果证明这种方法能够有效辨识账号的马甲关系。
本文后续组织结构如下: 第2部分主要介绍文本挖掘领域中作者识别方面的相关工作,第3部分详细描述本文提出的方法,第4部分是实验结果与分析,最后是总结。
2. 相关工作
社交网络上与账号相关的数据中文本数据最为丰富[2],通过挖掘文本的语言风格进行作者识别的研究工作在国外很早以前就有了,但中文文本在这方面的相关研究较少,尤其在网络文本上的研究更少。
识别作者的关键问题是从其已知作品中统计出能代表其独特风格的识别特征,例如,词汇总量及其特色词汇构成的数量比例、标点符号的使用频率、词语频率、句子长度、句式的使用分布、辞格的运用、声调和韵律分布等。 根据文本是否规范,基于语言风格的研究方法有很大的差异。
对于文学作品等规范文本,单词是常用的文本挖掘的特征,但在语言风格分析中往往会结合其他的特征。王少康等[3]基于对句长的统计,构建段长的序列组合分析写作风格,利用不同作者写作时在文章语句节奏控制方面的特点,对10位作家进行识别分类,平均准确率约为60%;孙晓明等[4]基于停用词使用的规律,使用文章中虚词频率分布作为特征,通过模式匹配,使用SVM和K-means对13位作家进行识别,正确率达93.58%;日本学者金明哲[5]基于词性组合的统计分析,使用字符为单位的unigram和词性为单位的n-gram作为特征,其正判别率可达95%。
相比文学作品,网络文本的特点是大多为短文本,语法不严谨,并且有许多的网络用语。短文本的特点是样本的特征稀疏,如何更好的利用短文本为数不多的特征是一个难点。网络用语的不规范使得流行语及奇异短语日异增多,识别流行词语或避免非正式语言的干扰也是一个难点。针对短文本的特征稀疏问题,武晓春[6]等基于语义扩展文本,取得了一定效果,但语言风格更多是形式上的分类,语义扩展的假设并不是很合理。DeVel等人[7]从电子邮件中抽取了语言特征和结构特征作为作者的写作特征,采用支持向量机等机器学习方法,对电子邮件作者身份进行分类识别,但该方法基于电子邮件的相关格式特征,不能普遍应用到社交网络中的文本。Abbas等[8]为有效监控互联网上的非法信息,提出运用文体学的方法对网络论坛发布信息的作者身份进行识别,抽取词汇、句法、结构、内容等特征,采用SVM和决策树分类算法,该方法只能区分论坛中发布恐怖信息的不法分子和普通用户两种类别,不能区分到具体真实用户。
除了文本数据,社交网络中账号之间的回复关系也具有很好的可利用价值。在现有的研究中,利用账号之间回复关系的研究工作主要用于社区发现、传播分析等领域。基于社交网络中账号之间的特性相似度与交互信息[11],例如,兴趣、观点的相似度、互相关注关系、发言回复关系等构建的网络进行社区发现,可以用于发现共同兴趣的社会团体,识别水军团伙,对恶意水军进行防范等。但是,社区发现相较本文的账号马甲关系辨识是宏观层面的账号关系聚类的工作,不能够准确地发掘单个账号的马甲关系。
3. 基于账号组合的马甲辨识方法
目前,在社交网络中辨识账号的相关研究主要是基于文本挖掘账号的语言风格。在社交网络的文本挖掘分类任务中,经常面临网络语言不规范、文本长度短、无固定格式特征、待分类类别多等问题。而现有的对文本语言风格的研究工作多数基于文学作品文本和有格式的网络文本,例如,电子邮件,对于论坛帖子这种无格式的短文本的处理方法较少,文献[6]基于电子邮件的特殊格式进行作者识别研究的方法不适用论坛帖子。而在分类学习方面,前人工作的分类类别大多只有几十个,若将本文涉及的社交网络中的账号所属的真实用户作为类别进行分类,类别数量则会达到几百甚至数千,很容易导致分类算法运行效率降低,分类效果变差。为此,本文提出了基于账号组合的马甲辨识方法。
3.1 方法概述
针对网络文本挖掘中面临的短文本质量低的缺点,我们提取账号发言文本的n-gram与账号之间的回复关系频次,两组特征相结合进行账号马甲辨识,一方面最大程度提高文本特征的质量,另一方面加入账号之间的关系特征,扩展账号在文本内容之外的信息。
由于网络文本的长度短,为保证文本特征的数量,适合选择字、词、词组作为特征,不适合选择段落、句子作为特征。如果选择字表示文本特征,会丢失原始文本的大量信息;选择词组虽然会保留一些字、词丢失的有用信息,但使得特征向量更加稀疏,增加了分类的难度。因此我们采用分词后的词语和字n-gram作为特征,在保证文本特征数量的同时,保留了文本作者大量语言风格相关的信息。由于网络文本中的语法大多不严谨,并且夹杂许多网络用语,如果单纯利用中文分词的方式提取词语特征,由于分词性能十分依赖所用的词典的规模和质量,需要不断更新补充词典来保证分词效果,而采用n-gram特征提取方式可以不用考虑随语言领域和时间的变化而不断对分词词典进行修正扩充的工作。因而n-gram更适合作为网络文本的特征。另外,账号之间的回复关系是在作者身份识别领域,社交网络中账号特有的数据,能够体现有马甲关系的账号共同回复他人的规律。将文本特征与关系特征综合能够更好的体现账号的特性。
针对马甲关系辨别存在待分类类别多的问题,本文将账号两两组合构成新样本,而不是直接将单个账号作为分类实例,这样做的好处是可以将多类别分类问题转化成二类分类问题(详见3.3节分析),大幅简化分类算法的训练与测试的复杂度,也可以避免因为类别太多造成无法得到有较大区分度的分类结果。
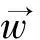
本文提出的马甲关系辨识方法主要步骤如下:
步骤一 提取账号的发言文本特征与回复关系特征,统计相应的频次,得到账号的特征权重向量;
步骤二 基于账号两两组合,得到账号组合的特征权重向量;
步骤三 由已知马甲关系的账号构成的账号组合构建训练样本,利用SVM算法训练得到相应的分类模型;
步骤四 测试含有待辨识马甲关系的账号组合,由账号组合的类别确定账号之间的马甲关系。
下面重点介绍上述步骤中的特征提取方法以及基于账号组合的向量空间构造方法。
3.2 特征提取和向量空间构造
3.2.1 网络文本特征提取
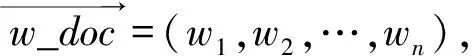
(1)
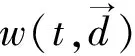
3.2.2 账号回复关系特征提取
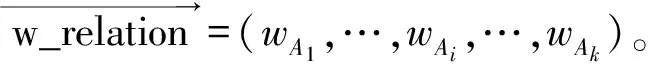
3.2.3 文本特征与关系特征融合

3.3 基于账号组合的向量空间构造
利用机器学习算法解决社交网络中账号马甲关系的辨识问题即是解决对所有账号的分类问题,目标是将拥有马甲关系的一组账号分为同一个类别,没有马甲关系的账号不分在同一类别。由此可知,如果将单个账号作为分类实例,分类问题即为将账号所属的真实用户作为类别进行分类的问题,待分类类别极多,远远超出常用分类算法待分类类别的适用数量。因此,本文提出将账号两两组合构成新样本,通过对账号组合类别的判断,确定两个账号之间的关系是马甲或非马甲。这样做的好处是可以将多类别分类问题转化成二类分类问题,大幅简化分类算法训练与测试的复杂度,也可以避免因为类别太多造成无法得到有较大区分度的分类结果。
社交网络中账号分为有马甲的账号和没有马甲的账号,而有马甲的账号分别属于各自马甲组。定义账号组合pair
1) 账号i与j均有马甲,且属于同一马甲组;
2) 账号i与j均有马甲,但属于不同马甲组;
3) 账号i有马甲,账号j无马甲;
4) 账号i无马甲,账号j有马甲;
5) 账号i与j均无马甲。
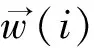
在新样本的向量构成的向量空间模型中进行分类,账号组合类型1)设为正例,账号组合类型2)和3)设为负例,账号组合类型4)和5)不参与计算,其中负例的可用样本数量比正例数量多很多,为了保证样本数量的平衡,实验时对负例的可用样本进行随机筛选,使正负两例的样本数基本一致。
3.4 基于账号组合的马甲关系辨识方法
从社交网络中账号发言的数据中提取特征,利用账号组合构造向量,然后利用SVM算法训练分类模型。预测时,判断一个未知账号idx是否与某个账号集合S={s1,s2,…,sn}中的账号有马甲关系的步骤如下。
1) 提取该账号idx在社交网络中的文本数据和关系数据,使用前述特征提取方法得到相关特征以及特征权重;
2) 使用账号组合向量空间构造方法,将账号集合S中的所有账号{s1,s2,…,sn}分别与该未知账号idx组合,构成pair
3) 基于训练得到的支持向量机分类模型,测试步骤2得到的每一组向量,判断其中的各个账号组合pair
4. 实验与分析
4.1 实验数据
本文的实验数据是从某中文论坛上采集的帖子,由于该论坛数据庞大,仅采集了2005年12月到2006年2月之间“杂谈”板块内的所有帖子以及相关信息,包括发帖文本、回复关系、发帖时间等。
同时从网络上收集了该论坛账号信息三千多万条(根据该论坛账号信息数据库泄露出的文件整理),从中找到有发言文本数据的账号19 883个。在有文本的账号中,人工比对注册邮箱地址和密码,将注册邮箱地址一致或地址相似密码相同的账号标注为一个马甲组。一共整理出1 693个账号,分为551个马甲组,每个马甲组中包含2到33个账号不等。
4.2 评价指标
本文采用的实验结果评价指标为准确率(precision,P)、召回率(recall,R)和F1值。首先计算每一类别的评价指标,为了表示分类器在全部类别上的综合分类性能,有宏平均和微平均两种方法。本文使用宏平均进行实验结果评价,即对所有类别的单项评价指标求取平均值。对账号组合所属类别的分类结果计算如式(4)~(6)所示。
其中,式(4)、(5)中a代表正例账号组合被判别正确的组合个数,式(4)中b代表负例账号组合被判成正例的组合个数,式(5)中c代表正例账号组合被判成负例的组合个数。
4.3 实验结果
4.3.1 基于账号组合的马甲辨识方法的分类结果
提取账号发言内容和关系特征,按照3.3节的方法,将属于同一马甲组的两个账号的组合向量作为正例,不属于同一马甲组的两个账号和一个账号有马甲而另一账号无马甲的组合向量作为负例,随机筛选负例样本使其数量与正例保持一致(即正负例样本数量相当),利用liblinear(SVM分类器)进行训练和分类测试。实验数据中共有8 080个样本,每个样本是由一对账号组成的,其中4 040个正例如,4 040个负例。由于负例的4 040个样本是从所有负例账号组合中随机采样出来的,为了避免数据采样的偶然性导致实验结果出现偏差,我们采用5次实验取平均值的方法,每次实验随机选择4 040个负例样本跟4 040个正例样本组成测试集,进行十折交叉验证,5次实验的结果如表1所示。
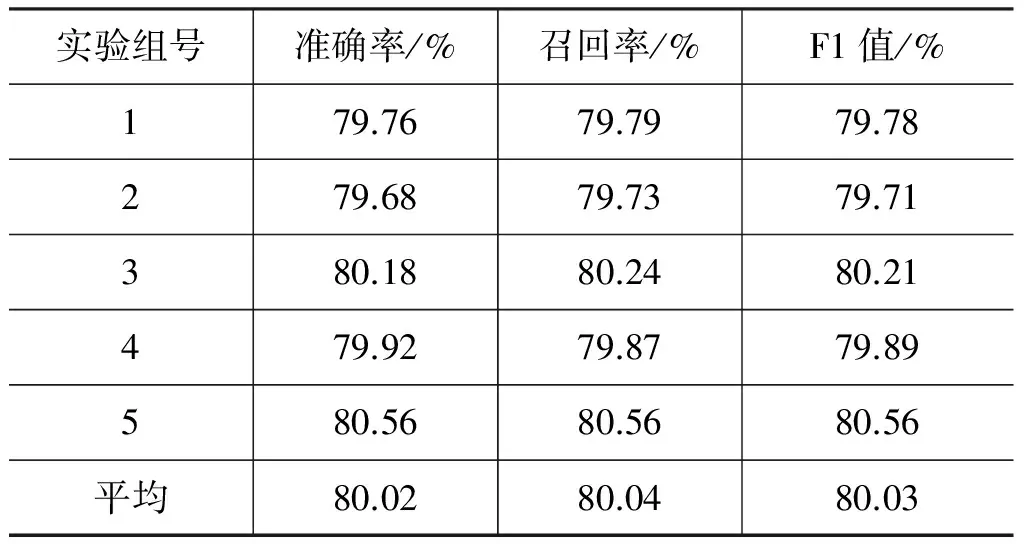
表1 基于账号组合的马甲辨识方法的分类结果
从表1可以看出,5次实验的平均准确率、召回率、F1值等各项评价指标均超过80%。实验同时表明,本文方法在不同的随机数据上都有较优的表现,实验结果能充分验证本文提出的方法的有效性。究其原因,虽然账号组合并没有增加两个账号各自的特征,但以账号组合为单位计算分类相似度,会显著放大两个账号中相同特征的影响,因此,两个账号相同的特征越多,其组合被判为正例的可能性越大,这样的账号组合是马甲的可能性也就越大。
需要指出的是,如果不采用账号组合构造向量的方法,而直接使用原始的单个账号构造向量,则需要分类551个马甲类别,如此多的类别对现有的多类分类算法是很大的挑战,基本都很难得到与我们的算法准确率相当的实验结果。
4.3.2 特征有效性分析
为了测试不同特征的有效性,我们对文本分词后的词语、字bigram、回复关系特征及其组合进行了实验对比,跟前面相同,每组实验均对负例样本进行5次随机采样取结果平均值,对比结果如表2所示。

表2 使用不同特征的实验结果对比
把表2的结果转换成图1所示的直方图,可以直观地看出本文选用的字bigram和回复关系两种特征较已知的其他方法只选用一种特征或选用分词后的词语的分类效果更优,准确率、召回率、F1值各项评价指标均超过80%。实验结果表明,文本特征中选用字bigram比文本分词后的词语效果更好;融合了社交网络关系特征与文本特征的方法比单用文本特征的效果更好,原因是有马甲的账号大部分都很活跃,而活跃的账号与其他账号有较多的回复关系,即有丰富的关系特征,因此融合关系特征后使有马甲的账号组合更容易被识别,提升了整体的实验效果。由此表明本文选用的字bigram更适合有不规范用语、网络流行新词的网络文本,提出的融合关系与文本特征的方法更适合进行马甲关系识别。

图1 使用不同特征的实验结果对比
4.3.3 不同分类方法的对比分析
为了进一步验证本文的方法在辨识马甲应用上的有效性,我们将基于账号组合的马甲辨识方法与经典的分类方法如逻辑回归法、朴素贝叶斯(NB算法)方法进行了实验对比,每组实验同样对负例样本进行5次随机采样取结果平均值,实验结果如表3所示。

表3 使用不同分类算法的实验结果对比
从表3可以看出,SVM算法比逻辑回归和朴素贝叶斯分类算法在辨识马甲时效果更好。由于论坛短文本的稀疏性导致NB算法的概率估计偏差严重,因而效果相对最差,实验结果的准确率等评价指标远远低于SVM算法。逻辑回归法表现比较稳定,效果不错,但仍低于SVM算法。
5. 总结与展望
本文主要研究了社交网络中账号之间马甲关系的辨识方法。在特征选择方面,利用账号的发帖文本,选择适合网络文本的特征,并结合回复关系的信息,从中挖掘出马甲账号之间的相似性。在向量构造方面,通过将账号两两组合构建新的向量空间,克服了多数分类算法不能有效对多类别数据进行分类的缺陷。此外,在社交网络中还有一些信息是很有价值的,例如,发言时间、马甲账号的上网作息规律等,将在后续的工作中加以考虑。
[1] Nirkhi S, Dharaskar R V. Comparative study of Authorship Identification Techniques for Cyber Forensics Analysis[J]. International Journal of Advanced Computer Science and Applications, 2013,4(5): 32-35.
[2] Zheng R, Li J, Chen H, et al. A framework for authorship identification of online messages: Writing‐style features and classification techniques[J]. Journal of the American Society for Information Science and Technology, 2006, 57(3): 378-393.
[3] 王少康, 董科军, 阎保平. 基于语句节奏特征的作者身份识别研究[J]. Computer Engineering, 2011, 37(9):4-5.
[4] 孙晓明, 马少平. 基于写作风格的作者识别[C].中国中文信息学会第五届全国会员代表大会暨成立二十周年学术会议论文集. 北京: 清华大学出版社.2001.
[5] 金明哲. 中文文章的作者识别[R]. 第二届中国社会语言学国际学术研讨会暨中国社会语言学会成立大会, 2003.
[6] 武晓春, 黄萱菁, 吴立德. 基于语义分析的作者身份识别方法研究[J]. 中文信息学报, 2006, 20(6): 61-68.
[7] De Vel O, Anderson A, Corney M, et al. Mining e-mail content for author identification forensics [J]. ACM Sigmod Record, 2001, 30(4): 55-64.
[8] Abbasi A, Chen H. Applying authorship analysis to extremist-group web forum messages [J]. Intelligent Systems, IEEE, 2005, 20(5): 67-75.
[9] Yu B. An evaluation of text classification methods for literary study [J]. Literary and Linguistic Computing, 2008, 23(3): 327-343.
[10] Diederich J, Kindermann J, Leopold E, et al. Authorship attribution with support vector machines[J]. Applied intelligence, 2003, 19(1-2): 109-123.
[11] Ge R, Ester M, Gao B J, et al. Joint cluster analysis of attribute data and relationship data: The connected k-center problem, algorithms and applications [J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2008, 2(2): 7.
猜你喜欢
儿童时代·快乐苗苗(2022年7期)2022-10-18
数学小灵通(1-2年级)(2021年11期)2021-12-02
派出所工作(2021年4期)2021-05-17
少儿画王(3-6岁)(2020年4期)2020-09-13
小学生作文·小学低年级适用(2018年12期)2018-04-11
小学生作文(低年级适用)(2018年12期)2018-03-23
小资CHIC!ELEGANCE(2017年6期)2017-03-20
CHIP新电脑(2016年3期)2016-03-10
浙江大学学报(工学版)(2015年1期)2015-03-01
小小说月刊(2010年6期)2010-11-22
