
基于语义解析的中文GIS自然语言接口实现研究
2014-02-28 01:26周俊生曲维光许菊红龙毅朱耀邦
中文信息学报 2014年6期
周俊生, 曲维光,许菊红,龙毅,朱耀邦
(1. 南京师范大学 计算机科学与技术学院,江苏 南京 210023;2. 南京师范大学 地理科学学院,虚拟地理环境教育部重点实验室,江苏 南京 210023)
1 引言
随着地理信息系统(GIS)应用的普及,中文GIS应用越来越面向公众服务,如位置信息服务、车载地图导航及旅游景点介绍等。人们可以通过GIS系统查询一些与日常生活息息相关的信息,比如“107国道穿越哪几个县”、“查询金陵饭店附近500米范围内的超市”等。但如果在传统的基于窗口、菜单和对话框等形式的GIS条件界面上执行这些GIS操作时,经常需要在不同的图层设置条件和输入信息,比较繁琐与低效。因此,如果在GIS中合理运用自然语言接口实现人机间的通信交互,更符合人们的认知习惯和语言习惯,更有助于GIS的应用普及。近些年来,许多研究者在中文GIS的自然语言接口技术上展开了一系列的研究[1-4],但是目前的研究主要还是基于文法规则或模式匹配的方法。显然,这种基于规则匹配的方法很难解决中文表达的灵活性问题。
另一方面,近些年来语义解析(semantic parsing)已成为自然语言处理领域的一个研究热点。语义解析的目标是将自然语言形式的句子转换成一种完全形式化的意义表示MR(Meaning Representation)[5]。由于意义表示语言MRL(Meaning Representation Language)是一种无歧义的形式化语言,因而,基于一种形式化的MRL给出的自然语言句子的意义表示可以被计算机直接处理和自动推理。在过去的十来年中,研究者们提出了多种基于统计学习模型的语义解析方法。例如,Wong 提出了一种基于统计机器翻译技术的语义解析算法WASP[6],Lu 提出了一种基于生成式模型(generative model)的语义解析方法[7]。Kwiatkowski 则提出了基于组合范畴文法CCG(Combinatory Categorial Grammar)以及高阶合一方法的语义解析方法等[8]。
因此,本文将采用语义解析方法对中文GIS自然语言接口实现技术展开探索性的研究。为了能够采用有监督学习的中文语义解析算法实现中文GIS自然语言接口,我们首先选择一个GIS具体应用领域设计了一种形式化意义表示语言,并开发了一个相应的语义解析标注语料库;然后,我们设计了一种有效的语义解析算法,实现了GIS操作的自然语言输入到形式化意义表示形式的转换。在所开发的语料库上进行的十折交叉验证实验结果显示,本文所采用的语义解析算法的F1值达到了90.67%,性能明显优于baseline系统。
2 形式化意义表示语言的设计及语料库的开发
为了将自然语言的句子转化成一种计算机可理解和执行的形式化表示,首先需要定义一种形式化的意义表示语言。具体地,我们以南京市地图信息查询作为应用领域,设计了一种函数式的形式化意义表示语言GISQL,在此基础上,我们进一步开发了一个相应的中文语义解析标注语料库。
2.1 形式化意义表示语言GISQL的设计
GISQL是一种函数式的意义表示语言,之所以选择函数式的形式语言表示而没有选择更加普遍使用的SQL语言是因为函数式语言能够提供一种更加易于实现映射的组合形式将自然语言句子映射到复杂的意义表示形式。意义表示语言中的基本元素与GIS数据库对象的一些术语之间存在一定的对应关系。这些基本元素包含非终结符和函数(或谓词)。在GIS数据库中,存在很多的实体类型,例如学校、超市、银行、景点、娱乐场所等,所以对于不同的实体类型定义不同的非终结符是不切实际的。因此我们引入了一个非终结符“ENTITYNAME”代表各种不同类型的实体,包括地名、单位名、街道名、行政区名等。但在每一次引用时它指代的实体是确定和唯一的,例如“夫子庙”、“文苑路”、“玄武区”等地理命名实体。此外,在自然语言的表达中有一些实体名具有不确定性,比如 “苏果超市”、“银行”等并不能代表一个特定位置的超市和银行。为此,我们引入了另外一种非终结符“ENTITYTYPENAME”代表不确定的实体类型。在GISQL文法中,我们共设计了10种不同的非终结符,如表1所示。

表1 GISQL中的非终结符
基于以上的非终结符集合的设计,我们进一步为GISQL文法设计和构造了一个函数(或谓词)集合,共包含54个不同函数,表2中给出了GISQL中的部分函数实例及其相应的意义。GISQL中的函数和GIS系统本身提供的函数并不具有直接的对应关系(本文实验中使用的GIS系统是ArcGis)。简单地说,GISQL中的单个函数可能涉及到GIS中多个函数的嵌套调用。例如,GISQL中的函数的contain(Entity, EntityTypeName)函数是首先由GIS中的QueryEntity(List
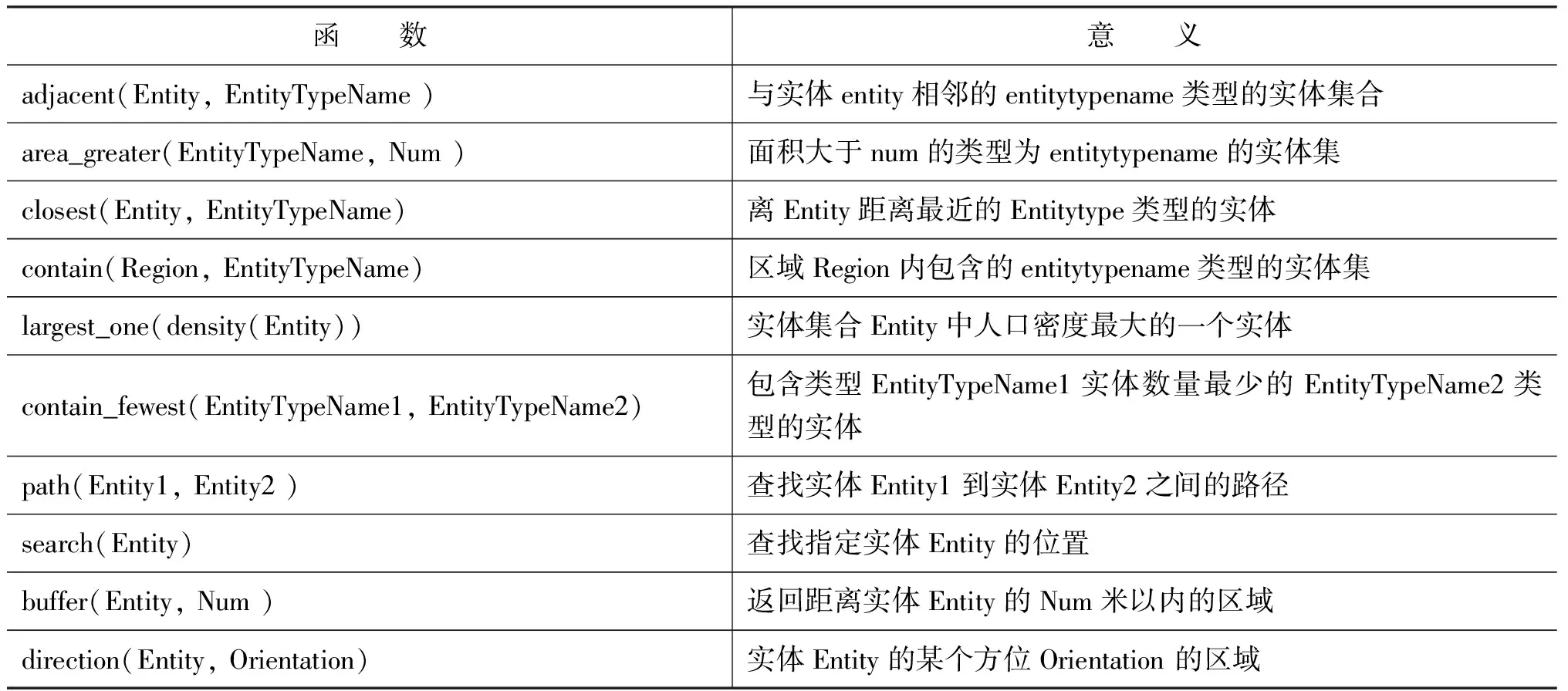
表2 GISQL中的一些函数实例描述
形式文法是由一系列产生式组成的,定义了非终结符和函数集合后,就可定义形式化意义表示语言中的产生式。对于每个非终结符都可以定义一个或多个产生式,而每一个句子意义表示均是由多个产生式组合而成,并且一个特定的产生式组合能确定唯一的MR解析树。图1给出了一个自然语言查询实例和其相应的意义表示以及对应的MR解析树。
(a) 自然语言查询实例: 查询在人口密度最小的行政区内所有苏果超市的面积和是多大?
(b) 形式化意义表示: answer(sum(area(contain(smallest_one(density(queryentity('行政区'))),'苏果超市'))))
(c) 意义表示(MR)解析树:
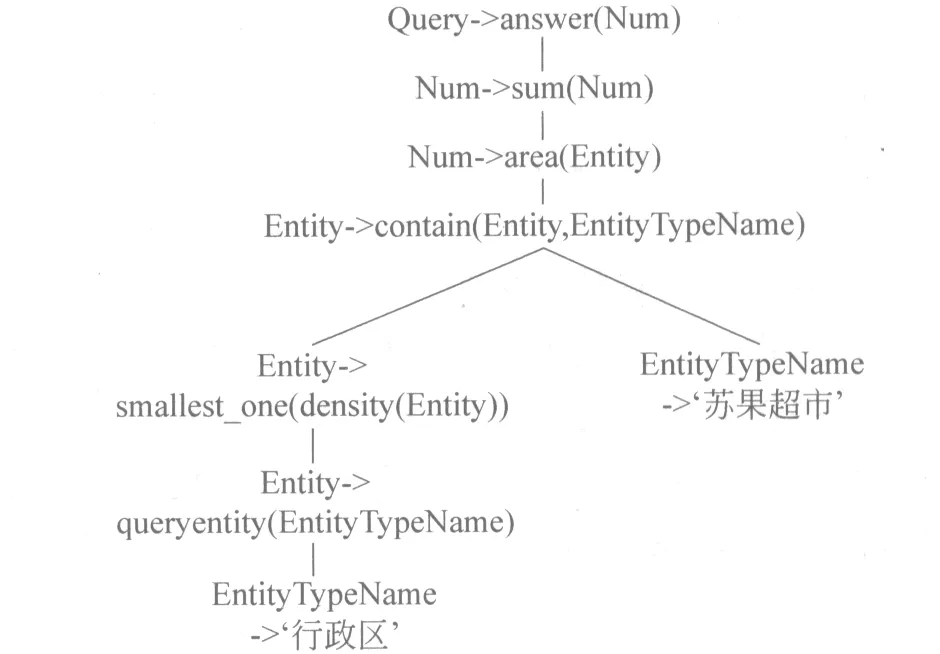
图1 一个自然语言的查询实例及其相应的的MR解析树
2.2 中文语义解析标注语料库的开发
为了建立基于有监督学习的中文语义解析器和实验测试的需要,我们在GISQL文法设计的基础上开发了一个中文语义解析标注语料库。为此,我们需要收集大量关于南京市地图查询的中文自然语言查询实例。为了使收集的查询问题实例更接近于人们在实际生活中可能提出的真实查询问题,我们在组织学生收集具体的中文自然语言查询实例之前,首先全面分析和考虑了涉及南京市地图查询的所有可能的问题类型,并设计了一个实际查询问题的类型方案。具体的,我们依据可能的查询目标将所有可能的真实查询问题共分为七种类型,如表3所示。其中每种类型下可包含大量不同的查询实例表达,而且一些类似的问题也可以根据不同的句式添加不同的实例表达,例如可以根据人们的表达习惯,将查询动词、语气词、查询目标三者之间的位置互换等。针对这七种查询问题的类型,我们共收集了1 110条自然语言实例。这些自然语言查询实例表达都是非常常见和灵活的自然语言查询问句,有些比较口语化,如包含词语的缺失、词序的灵活变动等。
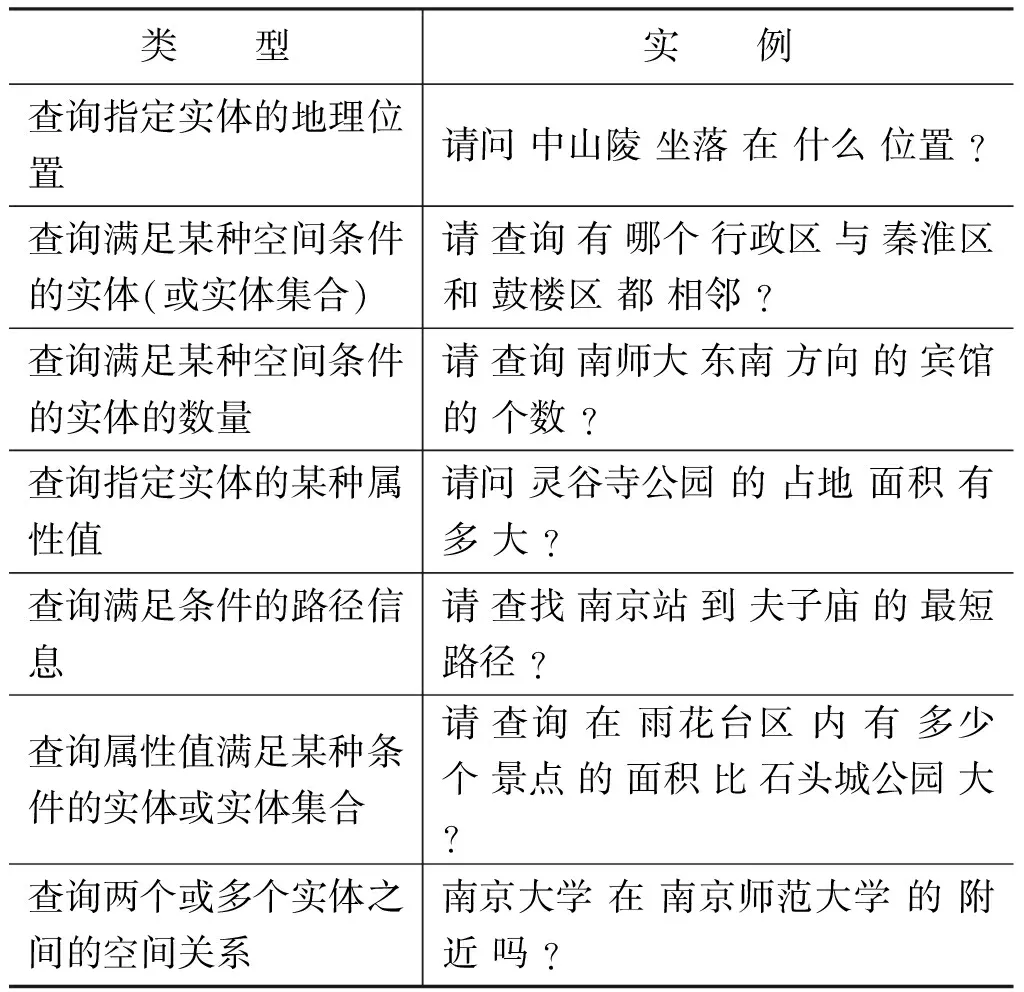
表3 自然语言查询的问题类型与相应实例
对于收集的这1 110个自然语言实例,我们根据GISQL文法对每个实例的意义表示形式都进行人工标注和校对,从而构成了1 110个自然语言句子/意义表示(NL/MR)对的语料库。其中,自然语言句子的平均长度为16.38个字,意义表示的平均长度为7.72。
在英文语义解析研究中,目前广泛使用的一个实验语料库是GEOQUERY[9],它是随Turbo Prolog 2.0一起发布的一个小的数据集,共包含880条关于美国简单地理信息的自然语言查询实例(例如,“美国最高的山是哪个?”、“有哪些河流经德克萨斯州?”等),并对这些实例采用了一种逻辑查询语言进行了标注。相对于GEOQUERY,本文研究的实际GIS应用领域更复杂,因而设计的GISQL文法也更复杂,包含了更多数量的函数和产生式;而且,我们开发的语料库规模也更大。
3 基于隐变量感知器的语义解析实现算法
语义解析任务是将自然语言句子x转换成形式化的意义表示y,其中,输入x是词的序列,输出y是由形式化意义表示文法中的产生式构成的MR树。显然,判别式的结构化学习模型非常适合于求解语义解析任务。但是,句子x中的词和MR树y中的结点之间并不存在直接的对应关系。为了解决这个问题,一种有效的方法是通过引入隐变量h构造输入句子和输出的意义表示之间的对应性[11]。假设给定输入句子x,输出的MR树y和隐变量h的联合特征向量,用F(x,h,y)表示,w表示一组相对应的参数。判别式结构化预测模型f用于返回输出的得分最高的意义表示y,同时最大化隐变量h[10],如公式(1)所示:
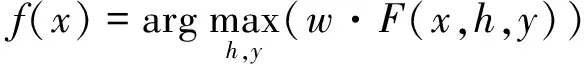
(1)
应用隐变量结构化预测模型解决语义解析问题将面临三个方面的挑战[11]: 1)如何引入一个合适的隐变量对输入和输出之间的对应关系进行建模;2)如何设计一个有效的学习算法用于直接优化最大化问题的模型参数w;3)在庞大的树结构搜索空间中,如何设计一个有效的解码算法以获得最优输出。
3.1 隐变量的结构
我们引入混合树(hybrid tree)作为隐变量构造输入句子和输出的意义表示树(MR-tree)的对应关系,因为它提供了一个自然的结构表示自然语言句子中的词语和意义表示文法中的产生式的相关性[7]。混合树是由自然语言词语作为叶子节点和文法中的产生式作为内部节点的树。图2中给出了在图1中所示的实例对应的一棵混合树。
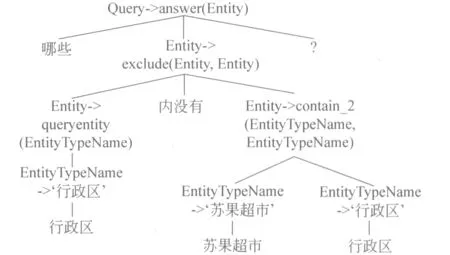
图2 混合树实例
对于每一对输入句子x和对应的输出MR树y,可能存在多个不同的推导能够建立输入输出对(x,y)之间的对应关系,而其中的每一个推导构成了一棵混合树。对每一棵混合树通过保留其中的产生式中间结点和地理实体终结符可派生出唯一的一棵MR树或一种形式化意义表示。因此,混合树结构非常适合在判别式结构化模型中充当隐变量结构。
3.2 参数学习算法
基于效率和收敛性的考虑[12],我们采用隐变量感知器算法学习判别式模型的语义解析器。类似于结构化感知器[13],隐变量感知器算法也是一种通过迭代训练集的在线学习算法,图3中描述了语义解析任务中的隐变量感知器算法。此算法主要通过学习预测混合树来帮助解决解析任务,在算法中存在以下两种解码任务:
其中,h*表示与实例对(xi,yi)对应的混合树。对训练实例对(xi,yi)我们可以通过应用一种约束的隐结构解码器来预测混合树h*。约束解码器是指解码搜索过程中仅使用正确解析树yi中的MR产生式作为候选MR产生式集合去搜索得分最高的混合树,且此混合树涵盖了句子xi中的所有词语。而混合树h′则可以通过一种非约束的普通解码器进行预测,并且从混合树h′中可直接提取预测输出y′,该操作用运算式Proj(h)表示。受MIRA在线学习算法的启发[14],本文采用最大间隔原则更新参数向量w。

图3 基于隐变量感知器的语义解析训练算法
3.3 特征模板的设计
在基于含隐变量的结构化感知器的判别式学习模型中,特征模板的设计非常重要。在混合树中,结点或者对应于自然语言(NL)词,或者对应于一个MR产生式,每个NL词和子MR产生式都是由它的直接父MR产生式产生的。换句话说,混合树中的所有NL词和子MR产生式都连接到他们的父MR产生式。为了能全面地描述混合树的结构特性,我们共设计了四种类型特征:
1) 词特征(Word features);
2) 产生式特征(Production features);
3) 词和产生式的混合特征(Mixture features);
4) 混合模式特征(hybrid pattern features)。
表4中给出了所有类型的特征模板定义。其中,前三种类型特征用于获取父MR产生式和它所有孩子结点之间的相关性。最后一种特征描述由父产生式结点向下延伸的混合模式,具体地说,对于混合树中一个给定的MR产生式结点,混合模式是指该结点下的自然语言的词序列和其各个子MR产生式结点之间组合的形式。为简化解码过程,在文法GISQL中我们已约定每个MR产生式的右边最多有两个子语义范畴,即含有两个子MR产生式。

表4 特征模板
其中,w表示自然语言中的词,w-1表示词w左边的第一个词,p表示子MR产生式,par表示与一个NL词或者一个子MR产生式直接相关的父MR产生式,rule表示一个混合模式;isConstant(w)用于检查w是否是已知常量,例如地理命名实体等;predicate(p)表示从MR产生式p中提取出函数(或谓词)。
3.4 解码算法的设计
解码算法的目标是根据模型参数找到分值最高的混合树。由于前述的所有特征模板均具有局部性,因此我们设计了一种动态规划解码算法有效地产生最优混合树。
在动态规划的解码算法中,首先让每一个子问题对应于混合树中以某个MR产生式为根的子树,该子树派生自然语言句子中的部分词;然后,根据每个根MR产生式涵盖的词的个数以及根MR产生式相关的所有可能混合模式来分解子问题;最后,依照自底向上的次序求解所有子问题。但是,由于算法中可能的混合模式数量多达21个,从而导致动态规划中的递归表达非常复杂,图4中仅给出了算法的简要轮廓描述。该动态规划算法的时间复杂度为O(n2T2),其中n为句子的长度,T为候选MR产生式的个数。

图4 语义解析中的动态规划解码算法
3.5 候选MR产生式集合的提取
由于解码算法的时间复杂度不仅依赖于句子的长度,而且还与候选MR产生式集合的大小有关。因此,为了在测试阶段能进一步提高解码的效率和准确率,我们提出了一个基于向量空间模型的MR产生式排序方法来提取相关的MR产生式用于解码,而不是简单地使用所有可能的MR产生式作为候选集合。
类似于文档排序方法[15],我们利用向量空间模型将相关MR产生式的提取问题转换为MR产生式排序问题。但是与文档排序问题不同的是,将每个可能的MR产生式表示成一个向量是非常困难的。对于训练数据集中的每个实例,它的正确MR树均是给定的,而每个训练实例的正确MR树中一般都包含多个不同的MR产生式,如何建立各个MR产生式与自然语言句子中一个词或多个词之间可能存在的关联性呢?为了解决这个问题,我们首先设计了一个简单有效的方式来构建每个MR产生式的向量。
第一步,对于每一个训练实例通过从其自然语言句子中抽取所有一元、二元、三元词汇串的方式建立一个相应的向量表示;接下来,为了给出每个MR产生式的向量表示,我们对包含该MR产生式的所有训练实例的向量进行求和,用此和向量作为该MR产生式的对应的向量表示。对每个MR产生式的向量表示均按此方法计算获取。采用这种计算方法的基本理由是: 因为与某个MR产生式密切相关的一些词或短语可能会多次出现在其MR树中包含该MR产生式的训练实例句子中,因此,对包含相同MR产生式的实例向量进行相加求和可以导致在该MR产生式对应的和向量中与这些词或短语对应的项会具有较高的频度值。
其次,为每个MR产生式构建向量表示的另一个重要问题是MR产生式向量中每一项的权重如何设置?如果简单按照上述求和方式直接构建每个MR产生式向量将会导致在和向量中必然存在很多噪音,为此我们采用一种修改的tf-idf权重方案,即通过计算相对词频值来替换传统的词频,因为相对词频值可以更好地反应向量中的各个特征项对于一个MR产生式的重要性。
在测试时,对于一个给定的测试自然语言实例,首先按上述方法构造一个向量表示,然后根据余弦相似度计算提取前n个相似度最高的MR产生式作为该测试实例的相关MR产生式集合。其中,n的值可由句子中包含词的个数确定。
4 相关工作比较
在过去的十来年中,研究者们提出了多种基于有监督学习的语义解析模型与算法。Wong提出了一种基于统计机器翻译技术的语义解析算法WASP[6]。该算法从成对的标注训练语料中学习同步上下文无关文法SCFG形式的转换规则来捕捉自然语言句子与意义表示之间的关系。Wong进一步将WASP扩展到处理λ演算意义表示形式,提出了一种语义解析算法λ-WASP[16]。Li通过对统计机器翻译领域中经典的同步文法学习算法GHKM进行了扩展[17],用于从成对的自然语言句子与逻辑形式的标注数据集中学习归纳λ-SCFG的规则集,更好地建立了自然语言句子与逻辑形式的对应关系。然而,这些基于SCFG规则的语义解析算法主要是在采用基于λ演算的逻辑形式的意义表示类型的语义解析问题中表现了较好的性能,而本文主要聚焦于函数式(variable-free)的意义表示类型。
Lu提出了一种基于生成式模型的语义解析方法[7],该方法首先定义了一种混合树结构,然后提出一种生成式模型对自然语言句子和其意义表示关系进行联合建模,在利用生成式模型输出n-best结果的基础上,进一步采用一个判别式模型并引入各种非局部特征对n-best结果进行重排序。本文中的语义解析算法也借鉴了混合树的结构,但我们将混合树视为一种隐变量,设计了一种有效的判别式学习模型直接实现了语义解析过程,避免了生成式模型中需要引入各种独立性假设的不足。该方法既具有判别式模型能够方便地嵌入各种灵活的特征组合表示的优点,又自然地将解码算法集成在训练与推导阶段。
近年来,基于组合范畴文法CCG(Combinatory Categorial Grammar)的英文语义解析研究受到了较多的关注[18]。CCG作为一种能够耦合语法和语义关系的有效语言文法形式,能够对各种语言现象进行描述与建模[19]。但采用基于CCG的语义解析方法时,如何获取一个好的、有效的词典是一个非常困难的问题。Kwiatkowski则通过使用高阶合一(higher-order unification)的方法定义了一个与训练数据一致的包含所有文法的假设空间,实现了词项的自动生成,从而避免了人工设计规则模板的复杂性[8]。
5 实验结果与分析
基于我们开发的包含1 110条实例的中文语义解析标注语料库,采用我们提出的含隐变量的感知器模型的语义解析算法进行了十折交叉验证实验,并计算其微平均(micro-averaged)结果。实验的评价指标采用了传统的准确率(precision)、召回率(recall)和F1值。其中,对于每个测试实例预测正确性的判定方法是: 当预测产生的MR树与对该实例标注的正确MR树完全一致时,才认为该实例的测试输出是正确的。
5.1 候选MR产生式集合提取方法的有效性验证
为提高测试阶段的效率与准确率,我们提出了一种基于排序方法的候选MR产生式集合抽取方法,为了验证该方法的有效性,我们进行了两组十折交叉验证对比实验,实验结果如表5所示。表中第一行(LP)表示采用隐变量感知器模型进行训练,在测试时使用所有的MR产生式作为候选产生式集合;而第二行(LP+EXT)表示采用同样的隐变量感知器模型LP进行训练,但在测试时对每个测试实例分别使用排序访法抽取一个更小的候选MR产生式集合后进行解码。从表中的实验结果可以看出,通过基于排序法实现更小MR产生式候选集合的抽取明显改进了时间效率,将总的测试时间缩短了将近2/3。同时,语义解析的准确率也得到了显著的提高,F1值提高了3.2%,获得了25.5%的错误减少率。
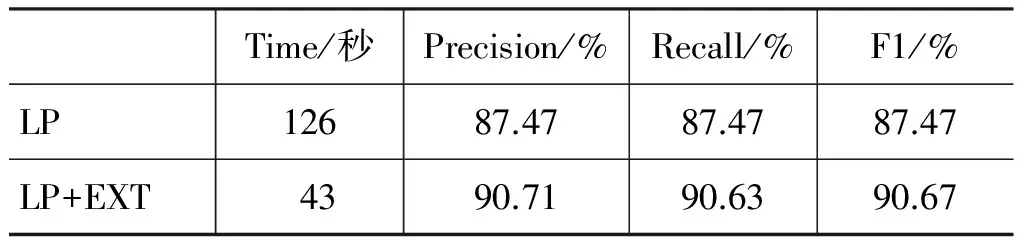
表5 增加候选MR产生式集合提取方法的实验结果对比
5.2 不同语义解析算法的实验比较
为了能够验证我们的方法在中文GIS自然语言接口实现中的有效性,我们也实现了两个baseline系统。我们选择Lu 提出的产生式模型并结合重排序的后处理过程[7],以及Kwiatkowski 提出的基于CCG文法和采用高阶合一方法自动构造词典的的语义解析模型[8]构造了两个baseline系统,分别记为baseline-1和baseline-2。因为这两种方法是目前英文语义解析研究中性能领先的基于有监督学习模型,而且它们也不需要任何额外的语法先验知识,因而这两种方法和我们的方法具有直接的可比较性。
表6中的实验结果显示,在F1值上,我们的系统比baseline-1系统获得了4.11%的提高,相对于目前在英文语义解析任务中具有最佳解析性能的baseline-2系统也高出了1.77%。同时注意到,我们系统的召回率和准确率几乎相等。这意味着对于几乎所有的测试实例,我们的系统都能解析出一个意义表示树结果。一个可能的原因是因为我们的方法是基于判别式结构化预测模型,它能够很好地集成各种有效的特征组合,因而对一些训练数据中未见的MR产生式具有一定的平滑作用。

表6 不同方法的实验结果对比
6 结束语
本文针对基于语义解析的中文GIS自然语言接口实现技术与方法进行了探索性的研究。我们选择南京市地图查询作为具体的实际应用领域,首先设计了一个形式化意义表示语言GISQL,并在此基础上开发了一个相应的中文语义解析标注语料库。
据我们所知,这也是第一个中文语义解析语料库。然后,我们提出了一种基于含隐变量的感知器模型的语义解析算法。在开发的中文语义解析标注语料库上的实验结果显示,该算法的F1值达到了90.67%,明显优于两个baseline系统。更重要的是,本文的研究结果证明了基于语义解析方法实现中文GIS的自然语言接口是一种有效可行的途径。
在下一步的工作中,我们将扩展形式化意义表示语言GISQL和语料库,以覆盖更广泛的GIS应用领域与问题,包括地图浏览、数据采集和空间分析等领域;另外,我们将研究基于启发式搜索的结构化学习算法,这样能够引入更多非局部化的特征描述混合树结构,从而会产生更好的语义解析性能。
[1] 张连蓬,储美华,刘国林,江涛. 车载智能地理信息查询系统及其自然语言接口[J]. 现代测绘, 2005, 28(1): 20-23.
[2] 马林兵, 龚健雅. 空间信息自然语言查询接口的研究与应用[J]. 武汉大学学报(信息科学版), 2003, 28 (3): 301-305.
[3] S Mador-Haim, Y Winter, A Braun. Controlled language for geographical information system queries[C]//Proceedings of Inference in Computational Semantics, 2006.
[4] 余明朗, 明小娜, 龙毅, 张雪英. GIS环境下中文命令的规则匹配与语义解析[J]. 地理与地理信息科学, 2012, 28(6): 7-12.
[5] R J Kate, Y W Wong, R J Mooney. Learning to transform natural to formal languages[C]//Proceedings of AAAI, 2005: 1062-1068.
[6] Y W Wong, R J Mooney. Learning for semantic parsing with statistical machine translation[C]//Proceedings of the HLT-NAACL, 2006: 439-446.
[7] Wei Lu, Hwee Tou Ng, Wee Sun Lee, Luke S. Zettlemoyer. A Generative Model for Parsing Natural Language to Meaning Representations[C]//Procee-dings of EMNLP, 2008: 913-920.
[8] Tom Kwiatkowski, Luke Zettlemoyer, Sharon Goldwater, Mark Steedman. Inducing probabilistic CCG grammars from logical form with higher-order unification[C]//Proceeding of EMNLP, 2010: 1223-1233.
[9] John M. Zelle, Raymond J. Mooney. Learning to parse database queries using inductive logic programming[C]//Proceedings of AAAI, 1996: 1050-1055.
[10] C N J Yu, T Joachims. Learning structural svms with latent variables[C]//Proceedings of ICML, 2009.
[11] Junsheng Zhou, Juhong Xu, Weiguang Qu. Efficient Latent Structural Perceptron with Hybrid Trees for Semantic Parsin[C]//Proceedings of the IJCAI, 2013: 2246-2252.
[12] Michael Collins. Discriminative training methods for hidden Markov models: Theory and experiments with perceptron algorithms[C]//Proceeding of EMNLP, 2002.
[13] Xu Sun, Takuya Matsuzaki, Daisuke Okanohara Jun’ichi Tsujii. Latent Variable Perceptron Algorithm for Structured Classification[C]//Proceedings of IJCAI, 2009: 1236-1242.
[14] Ryan McDonald. Discriminative Training and Spanning Tree Algorithms for Dependency Parsing[D]. University of Pennsylvania, PhD Thesis, 2006.
[15] D L Lee, H Chuang, K Seamons. Document Ranking and the Vector-Space Model[J]. IEEE Software, 1997, 14(2): 67-75.
[16] Yuk Wah Wong, Raymond J. Mooney. Learning Synchronous Grammars for Semantic Parsing with Lambda Calculus[C]//Proceedings of ACL, 2007: 203-210.
[17] Peng Li, Yang Liu, Maosong Sun. An Extended GHKM Algorithm for Inducing -SCFG[C]//Proceedings of AAAI, 2013: 605-611.
[18] L S Zettlemoyer, M Collins. Online learning of relaxed CCG grammars for parsing to logical form[C]//Proceedings of EMNLP-CoNLL, 2007: 678-687.
[19] Mark Steedman. The Syntactic Process[M]. The MIT Press, Cambridge, Mass,2000.
猜你喜欢
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
中国石油大学胜利学院学报(2018年4期)2019-01-17
西夏学(2018年2期)2018-05-15
兵团工运(2016年9期)2016-11-09
外语教学理论与实践(2014年4期)2014-06-13
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中国高新技术企业(2009年3期)2009-04-16
