
一种迭代式的概念属性名称自动获取方法
2014-02-28 05:12汪平仄曹存根
中文信息学报 2014年4期
汪平仄,曹存根,王 石
(1. 中国科学院 计算技术研究所,北京 100190)(2. 中国科学院大学,北京 100049)
1 引言
任何概念词都有一定的语义,其直接表达语义的能力非常弱,因此我们必须借助其他类型的知识来进一步表达或者刻画它所蕴涵的语义。概念的属性就是一种此类的知识。
一般认为,属性是一种概念内涵的载体。一个属性描述了概念的一个特征或性质。属性具备描述概念和鉴别概念的功能,通过属性,我们可以区分不同的概念,发现它们之间的差异。属性在文本中表现为不同的属性名称。属性名称是表示属性的专有名词,大多数属性名称都能起到见名知义的作用。
在本文中,属性名称也称属性词;在不致混淆的情况下,我们可能会直接使用属性或属性词来简称属性名称。
中文属性名称主要包括数量型、定性型、角色型三种类型[1]。目前的属性名称获取依据语料数据的来源,主要包括基于结构化数据源的提取,如Web查询日志[2];基于半结构化的Web网页的提取,如从网页表格或表单中提取[3],从Wikipedia Articles中提取[4];以及基于多数据源的提取[5-6]。基于结构化和半结构化数据源的方法因其语料结构规整简短,具有一定的规律性,针对性强,主要采用弱文法和统计的方式进行提取,具有较高的准确率,但由于数据源的规模有限,因此召回率普遍不高。基于多数据源的方法主要是将结构化与非结构数据交叉迭代起来获取,首先从结构化数据中获取准确率较高的结果作为种子属性,然后使用种子属性从非结构化文本中迭代获取更多的属性。这种方法相比单一语料来源,综合考虑了准确率和召回率,但获取方法相对更加复杂,且结果属性的好坏和属性类型过多依赖于种子。
我们提出了一种基于前后缀迭代的属性名称获取方法,语料来源于非结构化数据源。本方法的每一步迭代分为两个步骤。
第一个步骤是: 从现有属性集合中选择合适的前后缀,构造词汇—句法模式,从Web网页中提取候选属性;
第二个步骤是: 采用基于相似性的验证模型对候选属性进行验证以扩充现有属性集合。
与现有的属性名称获取方法相比,本方法的特点在于:
(1) 基于非结构化的数据源,但引入了种子属性,兼顾了准确率和召回率,具有多数据源的优点,但获取方法更简单;
(2) 强化了结果的验证,提出了一组基于相似性的属性验证模型,提高了候选结果的准确率;
(3) 提出了一种滚雪球似的属性迭代获取方法,极大地提高了召回率、准确率和属性类型覆盖率。
本文的组织如下: 第2节介绍候选属性名称的获取方法;第3节介绍候选属性名称的验证方法;第4节给出实验结果与实验分析;第5节给出与相关工作的比较;第6节总结全文,并且讨论进一步的工作。
2 概念候选属性名称的获取方法
为了方便陈述,我们先引入一些概念,并通过例子加以解释。
在一个属性词中,我们称其中具有语义的最小单元为属性元(attribute element)。例如,在属性“IT产业增速”中,“IT”、“产业”、“增速”均为属性元。
属性词中的各属性元的地位并不是平等的,有一个是处于核心地位的,也有依存在其他属性元上以修饰它们的[7-9]。 有一类属性元,它们经常出现在属性词的结尾而被其他属性元所修饰,我们称它为属性后缀(简称后缀)。表1中给出了一些常见的属性后缀。
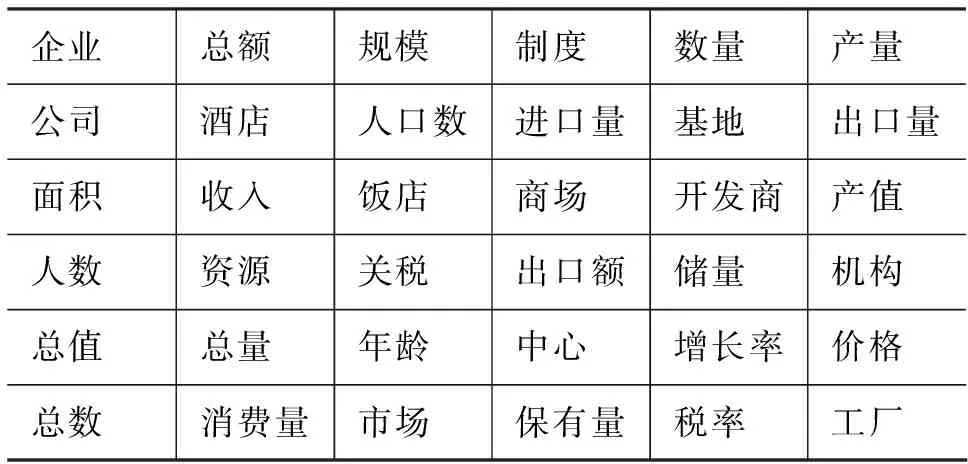
表1 一些常见的属性后缀
出现在属性开头的属性元称为属性前缀(简称前缀),它们充当属性的修饰性成分。表2中给出了一些常见的属性前缀。
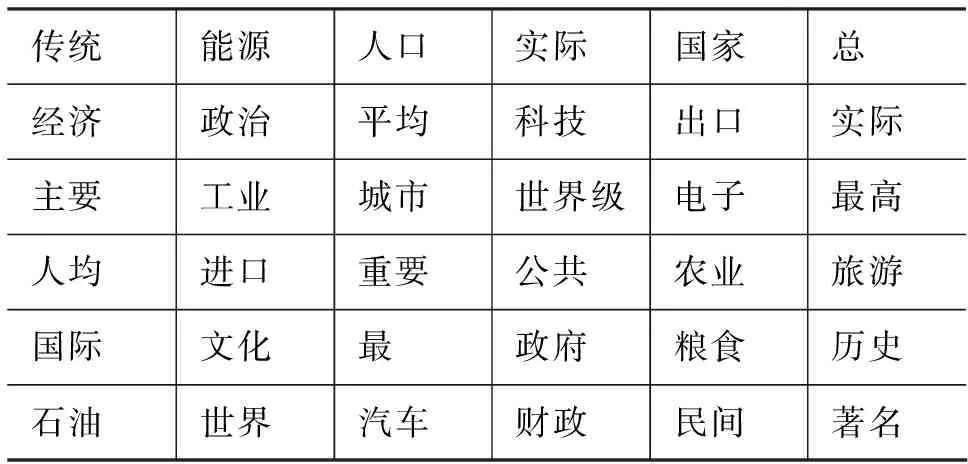
表2 一些常见的属性前缀
前缀和后缀是属性名称中重要的元素。我们对手工获取的属性名称进行统计,结果表明约53%的属性包含前缀,97%的属性包含后缀。因此,基于这种观察,我们提出了一种基于前后缀的属性名称获取方法。
概念C和其属性A的搭配常常满足一定的句法结构,例如,A[的]C[是|为|包括],其中方括号[]中间的内容表示可省。如对“中国”这一概念,我们常常会说: “中国的国土面积”、“中国总人口数为”、“中国的GDP”,等等。
我们把概念C的所有属性名称构成的集合称为C的属性空间,记为RC。
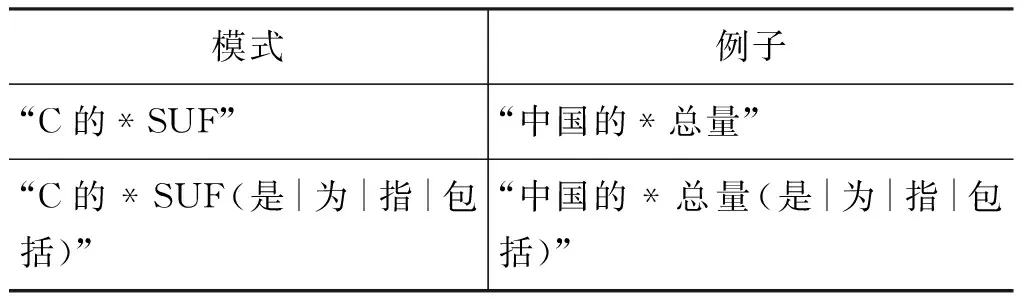
一般而言,给定属性空间RC中常见的后缀集合SUF={SUF1…SUFi…SUFk},我们就可以构造一批简单的查询模式,从Web网页中提取语料,如“C的**SUFi”和“C的*SUFi(是|为|包括)”。在Google支持的查询模式中,一个通配符“*”匹配一个词。得到语料后,可以将通配符匹配到的序列和SUFi一起提取出来作为候选属性名称。
同样,如果有一组前缀词集合PRE={PRE1…PREi…PREk},也可以构造类似的查询模式,如“C的PREi**(是|为|包括)”。得到语料后,可以将PREi(包括PREi)以及通配符匹配到的序列提取出来作为候选属性名称。
这种基于属性前后缀的获取方法提取简单,且结果具有一定的准确率。但人工给定的前后缀词典毕竟数量有限,而且对不同类型的概念,其前缀后缀的差异也较大。如果对每个概念,将前后缀词典中所有的元素均尝试一次,则不仅耗时,还会得到许多错误的结果,影响结果的准确率。因此,我们对每类概念,给出一批人工验证过的正确属性(这些属性可能是手工整理的,也可能是自动获取后经过人工校验的)作为种子集合Seeds,依据属性前后缀词典,从Seeds中提取前后缀,使用这些前后缀进行获取。同时,为了打破前后缀词典和Seeds的限制,我们提出了一种前后缀扩充的迭代获取方法。
本方法的基本思路是: 首先从种子属性中提取新的前后缀,然后使用新的前后缀从Web中获取新的候选属性,并验证得到正确属性;然后从验证过的正确属性中提取新的前后缀,并使用新的前后缀继续从Web中获取新的候选属性,如此反复迭代。具体的算法见图1。

属性迭代获取算法(AIAAlgorithm)Step1:SUFnewproduceNewSuffix(Seeds);PREnewproduceNewPrefix(Seeds);Step2:While(SUFnew!=null||PREnew!=null){ As'getcandidateattributesbysuffix(SUFnew); AsvalidateAs'; putAsintoRC; putproduceNewPrefix(As)intoPREnew; As'getcandidateattributesbyprefix(PREnew); AsvalidateAs'; putAsintoRC; clearPREnew; SUFnewproduceNewSuffix(As);}图1 属性迭代获取算法AIA
在算法AIA中,
(1) 算法在同一概念C的属性空间RC中执行;
(2) SUFnew表示新产生的后缀词,PREnew表示新产生的前缀词;
(3) 函数produceNewSuffix(Para)是从属性集合Para中生成新的后缀词;函数produceNewPrefix(Para)是从属性集合Para中生成新的前缀词。
对于produceNewSuffix(Para),我们给出了一种比较简单的训练方式: 根据Suffixes Dictionary(属性后缀词典),从Para中得到未曾使用过的后缀词,加入到返回结果中;同时,对于Para中不出现在Suffixes Dictionary(属性后缀词典)中的结尾词,如果其在Para中的频率大于等于频繁阈值s,也将它们作为潜力后缀词加入到返回结果中。produceNewPrefix (Para)的训练方式类似,只不过是依据Prefixes Dictionary(前缀词典),从Para中属性的开头词中提取。
3 候选属性名称的验证方法
3.1 候选属性名称的预处理
每一次对概念C的属性空间RC扩充时,需要对新的候选属性集合As′进行验证。As′中有几种常见的错误,以下列出3个主要错误,并分析产生错误的原因,同时给出预处理策略。
1. 需要剥离。例如,从源句子“中国的很多工业产品产量已经跃居在世界的第一位”,我们获得了候选属性为“很多工业产品产量”。为消除此类错误,我们将候选属性开头的程度副词“很多”剥离掉。
2. 是句子片段。例如,从源句子“根源是中国的传统文化轻视技术”,我们获得了候选属性“传统文化轻视技术”。由于属性名称均是名词短语,因此对每个候选属性,我们采用基于句法模式的概念识别方法[10-11],如果该候选属性无法通过名词短语识别,则直接丢弃。
3. 不完整。例如,从源句子“中国的进口价格指数出现了比较大的上升”,我们获得了候选属性“进口价格”。通过观察源句子,知道正确的属性应该是“进口价格指数”。作为预处理,如果发现“价格”后面还有新的后缀词“指数”,则将“进口价格”和“进口价格指数”一起作为候选属性进行验证。
经过以上的预处理,我们由As′得到候选属性集As″。下一步将对As″进行验证。
在验证中,本文引入了以下两条启发式规则,并通过例子来说明。
启发式规则1(示例):
已知“自行车保有量”是“中国”的属性,那么“机动车保有量”也可能是“中国”的属性。
其理由是“自行车”和“机动车”有某种程度的相似性。
启发式规则2(示例):
已知两个属性“IT产业增速”、“GDP年均增速”是“中国”的属性,那么“信息产业年均增速”也可能是“中国”的属性。
其理由是“IT”和“信息”有某种程度的相似性;而通过“GDP年均增速”可以认为在“中国”的属性空间中“年均”可以搭配“增速”以修饰它。同样如果已知“钢铁行业发展状况”,“经济发展前景”是“中国”的属性,那么“钢铁行业发展前景”也可能是“中国”的属性。
基于以上的启发式规则,我们提出了一种基于相似性的属性验证模型。
3.2 属性元相似度
在启发式规则示例中,我们知道属性元之间存在某些相似性。
在汉语构词和构字中,包含了丰富的语义信息。比如“自行车”、“机动车”均以“车”结尾,预意着它们都是一种“车”。同样,能确定上下位关系等受限语境的词,借鉴文献[12],我们也能定义它们之间的语义相似性。但是对于绝大多数属性元,很难得到这样的语义信息。所以,我们提出了一种更一般的属性元相似度定义方式。
前面的例子表明,我们更关心的是结构相似,即属性元依存关系之间的相似性。
我们不易直接把握“需求量”和“总产值”之间的语义相似度,但是如果我们得到了以下候选属性: “煤炭需求量”、“煤炭总产值”,“钢铁需求量”、“钢铁总产值”,我们会认为“需求量”和“总产值”之间的相似度较高,因为它们被相同的属性元修饰。据此,我们得到以下假设。
假设在一个概念的属性空间中,如果两个属性元AE1和AE2频繁被相同的属性元修饰(即被相同的属性元所依存),那么AE1,AE2之间的相似度较高;反之,则相似度越低。
考虑到依存关系,我们定义函数D(x,用它来表示依存在x上的属性元集合。例如,D(“需求量”)={“煤炭”,“钢铁”…}。
基于这个假设,借鉴文献[13]的方法,我们提出一种建立在依存关系上的属性元相似度,如式(1)所示。
(1)
其中,I(S=-∑f∈SlogP(f,
P(f)为属性元f在训练语料中的概率,-logP(f)表示f的信息量;
与以上假设同理,如果两个属性元AE1和AE2频繁修饰相同的属性元(即依存在相同的属性元上),那么AE1和AE2之间的相似度较高;反之越低。例如,我们有以下候选属性: “煤炭消费量”、“煤炭需求量”、“煤炭进口量”、“石油消费量”、“石油需求量”、“石油进口量”,我们会认为“煤炭”和“石油”之间的相似度较高,因为它们修饰着相同的属性元: “消费量”、“需求量”等。我们定义函数BD(x,用它来表示x所依存的属性元集合。例如,BD(“石油”={“需求量”,“进口量”,“消费量”…}。则: 概念C上两个属性元在被依存关系上的相似度定义为式(2)。
(2)
综合以上考虑,我们定义概念C上AE1和AE2的相似度如式(3)所示。
Sim(AE1,AE2|C
=λ·SimD(AE1,AE2|C+
(1-λ·SimBD(AE1,AE2|C
(3)
其中,λ[0,1]为加权系数,根据具体应用或试验确定。
为了简化陈述,下文定义的所有公式均是指在概念C上的。
3.3 属性元依存对相似度
在属性元相似度基础上,我们引入依存对(P,P′的相似度如式(4)所示。
(4)
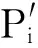
例如, 对依存对“(IT,产业)”和“(信息,产业)”之间的相似度,表示为Sim(IT,信息)×Sim(产业,产业)
对有相似关系的属性名称A和A′,若A中的依存对P能在A′中找到相似的依存对P′,则构造从P到P′的映射,称这个过程为对齐。
在属性名称对齐时,需要依存对的两个属性元都相似才能将其对齐。
设A1=“IT产业增速”,依存结构见图2;A2=“GDP年均增速”,依存结构见图3;A3=“信息产业年均增速”,依存结构见图4。图5中给出了A1和A3对齐后的结构图。
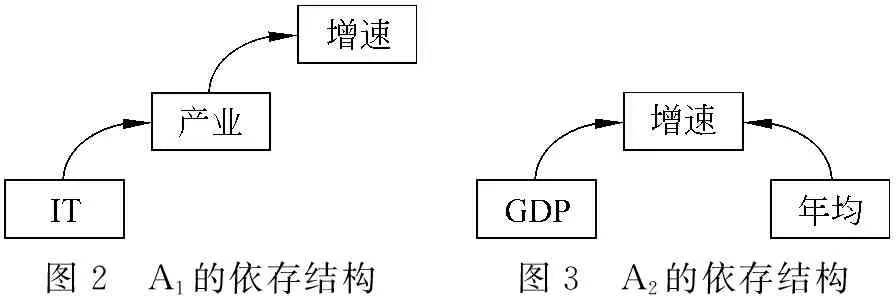
图2 A1的依存结构图3 A2的依存结构
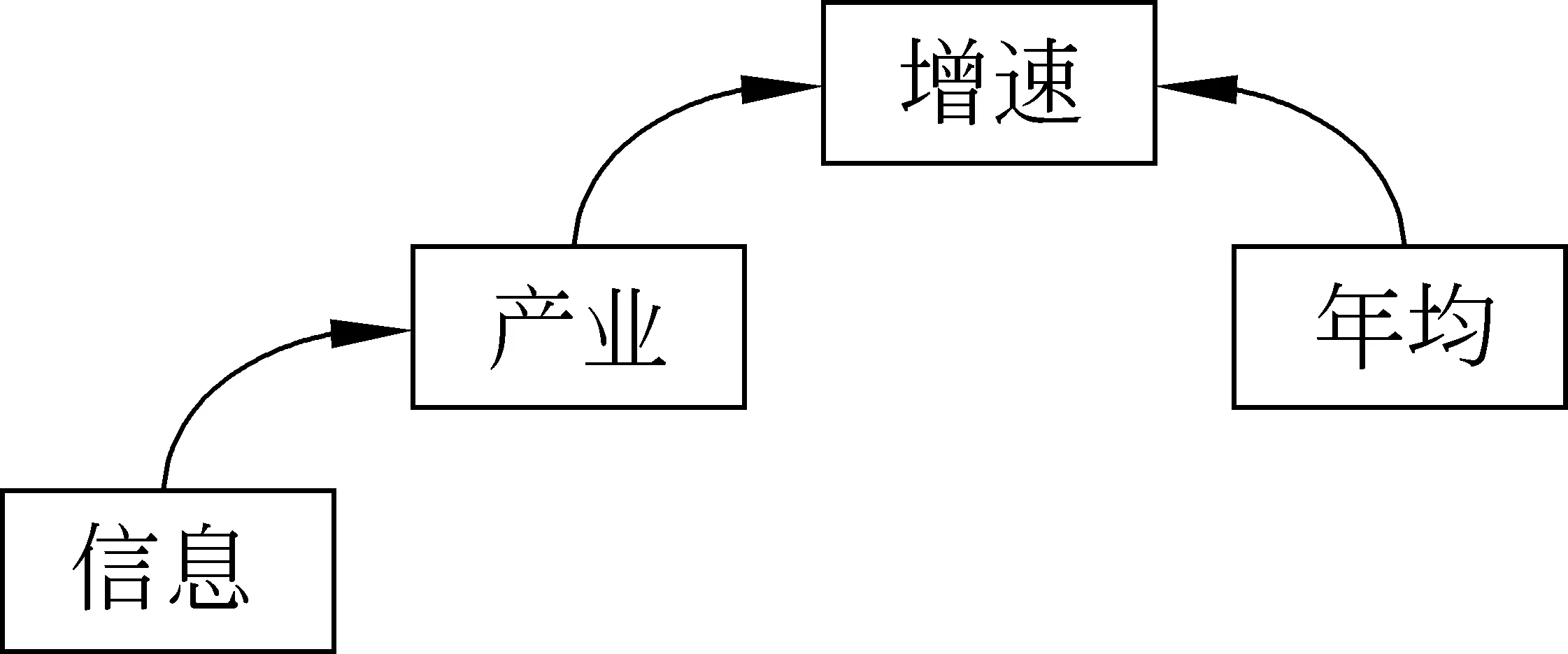
图4 A3的依存结构

图5 A1和A3对齐后的结构
3.4 属性相似度
在依存对相似度的基础上,我们引入马尔科夫假设,认为属性的各个依存对之间彼此独立,于是我们定义属性A和A′之间的相似度如式(5)所示。
(5)
其中,
(1) Pi(A),Pi(A′)表示为A和A′的第i个对齐的依存对;
(2) Max_Pair(A,A′为A,A′依存对数量的较大值。
根据图5中A1和A3的对齐结果,计算A1和A3之间的相似度,如果“IT”与“信息”的相似度为0.8,则如式(6)所示。
Sim(A1,A3)=(0.8×1+1×1)/3=0.6(6)
3.5 属性置信度
引入定量指标属性置信度D (D∈[0,1]) 来描述属性的正确性。
如果已知候选属性A′的置信度D(A′;A和A′的相似度为Sim(A,A′);A的置信度未知,我们定义:
定义1由A′推导出A的属性置信度如式(7)所示。
真实的属性空间中,和A相似的属性数量常常会大于1,令其相似属性集合Sim(A)={A1,A2,…An}。我们可以在Sim(A)上定义A的置信度。如,我们可以在Sim(A)中,找到一个与它最相似的属性Ai,用D(Ai→A)作为A的置信度,如式(8)所示。
属性置信度1
其中i=argmaxiSim(Ai,A)
同样,也可以在Sim(A)中,将得到的推导置信度的最大值作为其置信度,如式(9)所示。
属性置信度2
类似于属性置信度,我们也可以得到依存对P的两种置信度定义方式,用来描述依存关系的稳定程度,分别为式(10)、式(11)所示。
依存对置信度1
其中i=argmaxiSim(P(Ai),P)
依存对置信度2
定义依存对置信度的意义将在3.7节中说明。
在上述例子的A1,A2,A3中,只有当A1和A2都为正确属性时,即关系(IT,产业)、(产业,增速)、(年均,增速)都合理时,才有可能认为A3也是正确属性。尽管A1和A3可能最相似,但A3的真实置信度和A1,A2都相关,而不仅仅取决于其中的某一个。因此,如果对A3中的依存关系做划分。(信息,产业)、(产业,增速)由A1决定,而(年均,增速)由A2决定,则可以由A1,A2得到的A3的置信度。于是,我们得到式(12)。
属性置信度3
其中
(1) t为划分个数;
(3) 选择t最小化原则进行划分;若t最小时存在多个划分,选择D3(A)最大化进行划分。
3.6 属性验证算法
在属性置信度的基础上,我们提出了一个属性验证算法。算法的基本思想是: 对种子属性和待验证的候选属性做属性元分解和依存关系解析,然后根据属性元之间的相似关系,构建属性空间图,图中的节点为属性,边表示相似关系。然后从种子属性开始,采用广度优先搜索计算相邻节点的置信度。详细的验证算法(AV Algorithm)如图6所示。

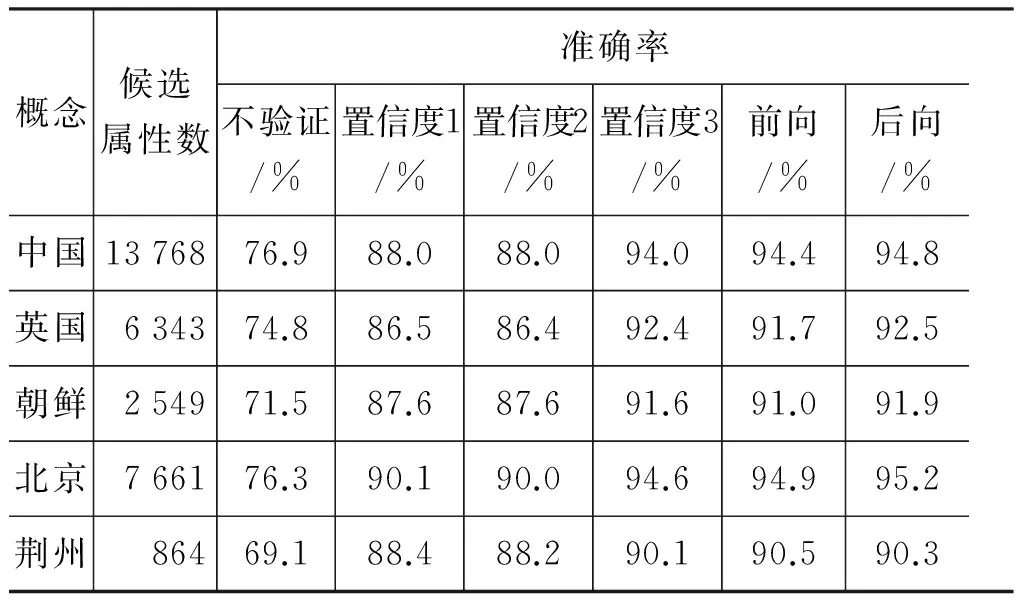
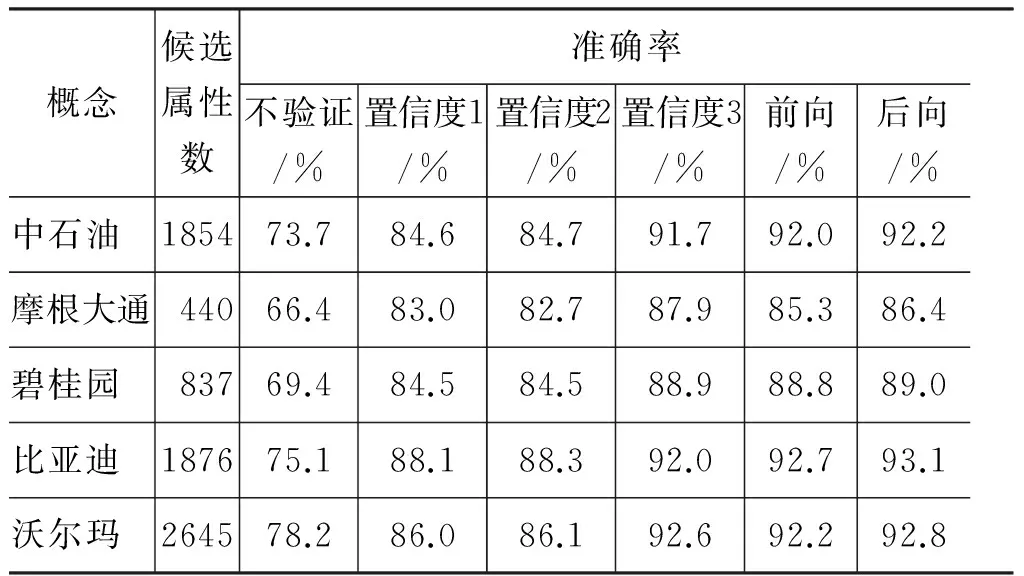
属性验证算法(AVAlgorithm)Step1:marktheDsofallSeedsas1;Step2:puttheSeedsandCandidateattributesintoA;Step3:generateattributesspaceGraphasG:for(i=0;i 在算法AV中,analyze(Ai)表示对Ai做属性元分解和依存关系解析。 前面定义的属性置信度以依存对为基础,它认为属性的构成满足二元的依存关系,即依存对之间彼此独立。而实际的属性构成经常会是树形方式(例子中的A2和A3),或是链式(例子中的A1)。因此,我们提出一种基于属性元序列(attribute elements sequence,AES)的验证方法。 我们可以给出了一个AES的递归定义,但是为了便于理解,这里仅给出AES的直观感受: 如果把属性依存树看成是一个无向图,则属性元序列AES是这个图的连通子图(连通子图中的任意两个节点都必须是边可达的)。 在例子A3中: “信息产业”,“产业增速”,“年均增速”,“信息产业增速”,“产业年均增速”,“信息产业年均增速”均为属性元序列。而: “产业年均”则不是属性元序列。通过例子发现,属性元序列具有相对完整的语义。 属性元序列之间存在相似关系。对依存对相似度进行扩展,我们引入属性元序列S和S′的相似度如式(13)所示。 此公式要求计算相似度的两个序列的长度(属性元个数)相同;序列的相似度为对应位置属性元相似度的乘积。 用属性元序列置信度D来描述序列依存关系的稳定程度。扩展定义1,得到: 定义2由S′推导出的属性元序列S置信度,如式(14)所示。 同理,若令S的相似属性元序列空间Sim(S={S1,S2,…,Sn},我们扩展依存对置信度1和2,也可以得到S的置信度计算公式如式(15)、式(16)所示。 属性元序列置信度1 其中i=argmaxiSim(Si,S)。 属性元序列置信度2 对于包含N个属性元的序列S,我们提出了一种基于(分解→组合)的置信度计算方法,即将该属性元序列分解为多个已经计算过D值的子序列{subS1,subS2,…subSk},并以这些D值为基础,组合计算新的值作为S的D值。 如果子序列是纵向关系,则认为它们彼此相关,将子序列的D值衰减求积。比如已知“钢铁行业发展”的D值为a,“发展前景”的D值为b,则“钢铁行业发展前景”的 D值为: λ×a×b;其中λ为衰减系数。 采用前向序列分解的方法是优先从序列S(属性词也是属性元序列)的开头起,向后找最长的子序列,使其置信度已经计算过(或者其相似序列的置信度计算过),以此子序列作为分解点。 比如对“钢铁行业发展前景”,如果其子序列subS1=“钢铁行业发展”,subS2=“发展前景”,subS3=“钢铁行业”,subS4=“行业发展前景”均已计算过D值,则前向的分解方式为subS1和subS2。 在汉语中,重心往往靠右,我们在计算时,也可以优先去计算靠近后缀的那些序列。采用后向的分解方法与前向类似,只不过是优先从序列的结尾开始向前找。对“钢铁行业发展前景”,基于后向的分解方式为subS3和subS4。 实验表明,若采用前向或后向的分解方式计算,去掉重复后,实际分解得到的子序列总数约为属性空间中节点数的2倍。 由于属性词本身也是属性元序列,因此候选属性的置信度可采用前向或是后向的分解方法来计算。在计算前,先对种子属性做序列分解,并将得到的所有子序列置信度标记为1.然后依据序列相似关系构建属性空间图,并采用广度优先搜索依次计算候选属性的置信度。 我们选择地域类、商业主体类实体概念作为获取对象。因为这两大类相对具有较大的属性空间,以及较好的前后缀倾向,便于发现我们方法的优缺点。对地域类实体,我们选择“中国”、“英国”、“朝鲜”、“北京”和“荆州”作为实验对象,它们代表了发展中国家、发达国家、社会主义国家、资本主义国家、大型现代化城市、普通中小型城市等,因此不仅具有代表性,也具有多样性。基于类似的考虑,我们在商业主体类中,选择了“中石油”、“摩根大通”、“碧桂园”、“比亚迪”和“沃尔玛”作为实验对象。 在最近几年的本体建设中,我们总结了8 470个概念,共计获得了25 753个属性;从这些属性中,通过我们的算法,结合人工校对,总共获得了2 292个属性后缀和1 377个属性前缀,形成了本文实验的Suffixes Dictionary和Prefixes Dictionary。 对每组概念,我们给定一批人工验证过的种子属性。在这里,我们是对每组概念给定一批,而不是每个概念给定一批。因为相同类型的概念,会有很多共同的属性前后缀[14]。例如,对概念“中国”和“北京”都具有“国内生产总值”、“耕地面积”等相同或是相似的属性名称,同时也共享一批相同的前后缀,如“年均”、“一般”、“总量”、“面积”等。 对每组概念,我们依据前后缀词典,从种子属性中提取一组前后缀词以合成Google查询模式。 表3给出了2个基于后缀的获取模式。 表3 基于后缀的获取模式 表4给出了2个基于前缀的获取模式。 表4 基于前缀的获取模式 在实际的Google查询模式中,我们会生成1至4个通配符*,以匹配1至4个词。 对每个查询模式,我们提取Google反馈的前100项锚文本作为候选结果,经过预处理后,采用前面定义的5种验证模型(即基于属性置信度1、属性置信度2、属性置信度3、基于前向序列分解、基于后向序列分解)分别验证。 在对正确属性和候选属性做属性元分解时,采用一般的分词程序,分词后得到词,我们认为它们为属性元。在依存关系解析时,我们初始假设属性元之间是线性依存关系,然后对包含强前缀(例如,“年均”、“平均”,“总”等)的属性做依存关系调整(类似于上文给出的例子中的A2和A3)。这样不仅具有较好的效果,而且具有较高的解析效率。 在属性元相似性训练时,对加权系数λ,根据多次试验,我们发现取经验值λ=0.6时效果较好。直观的解释是: 在汉语中,重心常常靠右,因此搭配相同的更重要的词,可能权重会略高些。 在属性词对齐时,我们设定属性元相似度阈值。在实验中,根据经验值,设定属性元相似度大于0.1时,才认为它们之间有相似关系,则两个依存对,它们对应位置的属性元之间相似度都大于0.1时,才认为依存对之间相似。 属性空间图中,节点标记为属性词,而边表示属性词之间的相似关系。实际上,几乎所有的属性都能在属性空间里找到与它有相似关系的节点。而且在每个独立的连通子图中,候选属性都有已经标记了置信度的种子属性与之相连接(因为属性空间里总有和它前缀或后缀相同的正确属性词),若采用属性置信度1和2,对于所有的候选属性,都能计算。 基于划分的验证模型(属性置信度3,前向分解,后向分解)中,有一些的依存对,在已经验证过的属性中找不到对应的相似关系,因此对这批属性,我们采用基于最大相似度的方式计算其置信度。最终对每个概念,我们得到5组验证结果。 其中,在前向分解和后向分解中,对相似属性元序列,我们采用属性元序列置信度1(式15)中定义的公式计算置信度。 我们对未进行验证的结果做抽样统计,准确率分布在65%~80%之间。理想情况下,使用验证模型计算后,越是正确属性,置信度则越高,错误的结果得到的置信度最低;如果我们对计算后的结果依据置信度做倒序排序,那么,前80%的结果应集中了所有的正确结果。在统计中,我们认定这80%的结果作为正确结果。表5和表6是经过一轮迭代后的获取结果,其中验证后的准确率也就是前 80%结果的准确率。 表5 地域类概念的获取结果 表6 商业主体类概念的获取结果 实验结果表明,我们提出的基于前后缀迭代的获取方法得到的初始结果也具有较高的准确率,经过验证后,准确率又有了较大的提升。 另外,在5组验证模型中,基于最大相似度(置信度1)和基于最大置信度(置信度2)的验证效果较为接近,原因可能是这两种模型考虑的基本因素是一致的;而基于划分(置信度3)的验证效果较佳,因为这种验证模型考虑了属性名称中的每个依存对。但是基于划分的验证模型无法计算所有的属性置信度,对于它不能计算的部分,必须借用置信度1或置信度2的验证模型。 基于前向和后向序列分解的验证模型尽管考虑了中文属性词的语法结构,但由于计算高度依赖于子序列的分解,以及相似属性元序列的对齐。而这种运算都很难得到较高的准确率,同时,大部分属性词只包含2,3个属性元,且搭配结构简单,对它们来说,这2种模型的计算效果与基于划分的效果等价。所以综合来看,这2种模型的验证效果相比基于划分的验证,并没有明显的提高。同时,基于前向和后向属性元序列的验证模型本质上也是基于划分的,因此也存在模型3的缺点。 前人方法的结果数量一般都在100以内,且偏重于Top N结果的准确率,而忽略了真实属性空间的庞大和多样性。实际上,每种类型的概念,其真实的属性空间一般远远超过了他们获取得到的数量,且属性类型丰富多样,其中很多属性尽管不是很常见,但在某个领域却很重要(例如,对类型“国家”来说,“货币供应量增长率”,“淡水人均拥有量”就是不常见但是分别在经济和环境领域却很重要的属性),而他们的方法一般无法获取到这种不常见的属性,也就无法满足构建大型知识库的需求。而我们方法的获取规模都在千级或万级,且能覆盖大多数类型的属性,能较好的满足上述需求。 在我们原先手工整理的种子库中,地域类中有96个不同概念,共6 378个属性(共3 689个不同属性),每个概念平均66.4个属性。商业主体类有263个不同概念,共2 860个属性(共1 435个不同属性),每个概念平均10.9个属性。采用我们的获取方法,对地域类概念,一次迭代后,获取到22 427个不同的属性(其中20 829个不在种子库中),为该类的种子属性库的扩充5.6倍,而为具体某个概念(如“中国”)的属性空间扩充大于100倍。对商业主体类概念获取到4 426个不同属性(其中3 644个不在种子属性中),为该类的种子属性库的扩充2.5倍,而为具体某个概念(如“比亚迪”)的属性空间扩充接近100倍。因此,我们的方法对原有种子库具有很好的扩充效果,能较好地适用于大规模知识获取。 在本文中,我们设计了一种基于前缀后缀迭代的属性名称获取方法,并提出了一组属性的验证模型。同时,在地域类和商业主体类实体概念上运用了该方法,并比较了各模型的验证效果,证明了我们的获取方法具有较好的扩充率,同时也具有很好的验证效果,得到了较高的准确率。 通过实验我们发现,不同的前后缀具有各不相同的扩充效果,有些前后缀扩充效果很好,有些则很差,有些甚至会得到大量错误的结果;有些前后缀能帮助我们得到很多不易得到的属性,而有些前后缀则能得到比较大众化的属性;不同的前后缀(尤其是后缀)还有不同的属性类型的偏好。因此,如何从大量的被验证过的结果中选择种子属性以及选择前后缀进行迭代是我们下一步面临的主要问题。 本方法在地域类和商业主体类概念上具有较好的获取效果。尝试将本方法运用到其它类型的概念上,也是我们后续研究的问题。同时,总是会有一些属性很难通过自动的方式得到验证,于是,我们想提出一种人工干预的模型对这类属性进行交互验证,实现一种人机互动的系统,以较少的人工干预,得到较大的验证效率和效果。 另外,根据我们的统计估算,约1.41%的属性既不包含前缀也不包含后缀,它们中有些可能是比较常见而重要的属性;而有些虽然包含前缀或后缀,但却不一定能通过前后缀迭代的方法获取出来,因此如何利用现有的资源解决这类问题,也是我们下一步面临的重要工作。 [1] 田国刚.受限中文语料的自监督文本知识获取研究[D]. 中国科学院大学博士学位论文. 2007. [3] Naoki Yoshinaga, Kentaro Torisawa. Open-Domain Attribute-Value Acquisition from Semi-Structured Texts[C]//Proceedings of the 6th International Semantic Web Conference (ISWC-07).Workshop on Text to Knowledge: The Lexicon/Ontology Interface (OntoLex-2007) , Busan, South Korea, 2007: 55-66. [4] Wladmir C. Brandão,Edleno S. Moura, Altigran S. Silva. A Self-Supervised Approach for Extraction of Attribute-Value Pairs from Wikipedia Articles[C]//Proceedings of the Int’l Symp,on String Processing and Information Retrieval. 2010: 279-289. [6] Joseph Reisinger, Marius Paca. Low-Cost Supervision for Multiple-Source Attribute Extraction[C]//Proceedings of 10th International Conference on Intelligent Text Processing and Computational Linguistics, 2009:382-393. [7] 郭艳华,周昌乐.一种汉语语句依存关系网协动生成方法研究[J]. 杭州电子工业学院学报. 2000,20(4):24-32. [8] 李彬,刘挺,秦兵等. 基于语义依存的汉语句子相似度计算[J]. 计算机应用研究. 2003,12: 15-17. [9] 赵妍妍,秦兵,刘挺等. 基于多特征融合的句子相似度计算[C]. 全国第八届计算语言学联合学术会议(JSCL-2005). 南京,2005:168-174. [10] Shi Wang,Yanan Cao, Xinyu Cao, et al. Learning Concepts from Text Based on the Inner-Constructive Model[C]//Proceedings of the KSEM. 2007:255-266. [11] 王石.中文实体名称的识别和语义分析方法研究[D]. 中国科学院研究生院博士学位论文. 2009. [12] Shi Wang,Yanan Cao,Han Lu et al. Measuring Taxonomic Similarity between Words Using Restrictive Context Matrices[C]//Proceedings of the FSKD. 2008:193-197. [13] Dekang Lin. An Information-Theoretic Definition of Similarity[C]//Proceedings of the 15th International Conference on Machine Learning(ICML),Madison, WI, 24-27,1998:296-304. [14] 卢汉,曹存根,王石.基于元性质的数量型属性值自动提取系统的实现[J]. 计算机研究与发展. 2010,10:1741-1748.3.7 基于属性元序列的验证
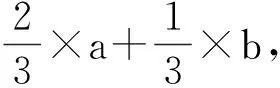
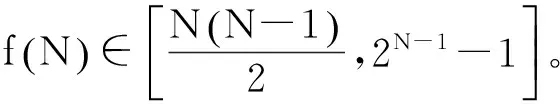
4 实验和分析
5 与相关工作比较
6 结束语和进一步工作
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
计算机应用(2018年5期)2018-07-25
计算机系统应用(2018年4期)2018-05-04
中国新通信(2016年17期)2016-11-17
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年13期)2016-10-17
股市动态分析(2016年11期)2016-10-11
股市动态分析(2016年10期)2016-09-30
