
面向CPU+GPU异构平台的模板匹配目标识别并行算法
2014-02-27 08:01:40马永军
天津科技大学学报 2014年4期
马永军,袁 赢,李 灏
(1. 天津科技大学计算机科学与信息工程学院,天津 300222;2. 天津瑞和天孚科技有限公司,天津 300384)
面向CPU+GPU异构平台的模板匹配目标识别并行算法
马永军1,袁 赢1,李 灏2
(1. 天津科技大学计算机科学与信息工程学院,天津 300222;2. 天津瑞和天孚科技有限公司,天津 300384)
针对大数据量导致模板匹配目标识别算法计算时间长,难以满足快速检测的实际需求问题,在采用最新NVIDIA Tesla GPU构建的CPU+GPU异构平台上,设计了一种模板匹配目标识别并行算法.通过对模板图像数据常量化、输入图像数据极致流多处理器片上化和简化定位参数计算3方面优化了并行算法,并对算法进行性能测试.实验表明,该算法在保证识别效果的同时实时性明显提高.
模板匹配;目标识别;并行计算;统一设备计算架构;图形处理器
模板匹配运动目标识别已广泛应用到视频监控等领域,然而随着视频信息高清化、数字化发展,在视频处理领域中基于模板匹配的运动目标识别算法的计算代价高,实时性降低,因而迫切需要提高计算能力.目前在此领域已取得了一些成果:于志华等[1]提出一种基于FPGA的并行超标量匹配处理架构加速算法,但仅局限于语音系统;李俊山等[2]提出基于K元2-立方体网络结构的图像模板匹配并行算法,适用于LS MPP(Li-Shan massive parallel processing)计算机.另外,赵东明等[3]利用DNA计算的并行性实现模板匹配算法的并行化;马永军等[4]利用多核平台使用OpenMP对模板匹配进行加速.这2种算法均基于CPU实现,而CPU并不擅长并行计算,无法解决在高清环境下视频数据量大、实时处理性能不佳的问题.Rajasekaran[5]通过FFT技术获得有效的模板匹配并行算法,但存在算法计算量巨大的问题;Anderson等[6]通过GPU对模板匹配进行加速,但没有充分挖掘异构平台的优势,仍有提升空间.因此,提高基于模板匹配目标识别算法性能具有现实意义.
NVIDIA公司最新的Tesla系列图形处理单元(GPU)完全针对并行计算而设计,利用NVDIA公司统一设备计算架构(compute unified device architec-ture,CUDA)的高可扩展性,完全可以满足高性能计算机的需要.而且,由CPU+GPU组成的异构处理平台相比传统的同构多处理机系统,能够提供更好的计算性能和功耗效率,已经成为解决大数据量引发的计算复杂、代价高等问题的主流并行解决方案.其中,如何高效地利用异构系统中CPU和GPU进行协同并行计算是目前研究的热点问题[7].
本文提出一种采用最新的NVIDIA Tesla GPU构建CPU+GPU异构平台,并进行CUDA并行编程的方法,利用CPU+GPU异构多核的高并行能力,使用最新的NVIDIA Tesla K20c GPU对模版匹配目标识别并行算法进行设计.
1 GPU和CUDA编程介绍
Tesla GPU凭借开普勒(Kepler)架构可以提供强大的处理功能以及优化,并具有提高GPU上并行执行工作负载的新方法.Kepler架构GPU的核心是极致流多处理器(next generation streaming multiprocessor,SMX)[8],与上一代Fermi架构使用的流多处理器(streaming multiprocessor,SM)相比,计算和功能单元的数量、安置方式有了很大变化.这一新型的流式多处理器设计让应用到处理核心上的空间比例远高于应用到控制逻辑单元上的空间比例,从而可实现更高的处理性能和效率.
CUDA核心包含线程组层次、共享存储器和栅栏同步3个重点抽象,用于引导程序员将问题划分为可以被多个块内线程独立并行处理的细粒度子问题;然后,每个子问题在1片SMX上被1个块内线程并行协作处理,以提高执行效率.
由于CUDA并未封装存储器系统的异构性,用户可以针对具体存储器的特点,有选择地使用[9]. CUDA将优化程序的自主权交给了用户,可提高用户自主解决问题的灵活性.
2 模板匹配目标识别的GPU并行算法设计
2.1 滑动模板匹配目标识别算法分析
滑动模板匹配算法的匹配过程如图1所示.模板匹配目标识别算法的基本原理是让包含目标的模板图像T在输入图像I中滑动,对模板图像和其覆盖的对应输入图像区域利用去均值归一化相关系数公式(式(1))[10]进行定位参数计算,选择相关系数最优值所在位置作为最佳目标匹配位置.

由式(1)可以看出,在滑动模板匹配过程中,每次仅计算1个像素点位置的定位参数,按照匹配顺序依次计算每个像素点的定位参数,完成整幅输入图像匹配的过程需要大量简单、计算方式相同的重复计算.因为在滑动匹配过程中,各个像素点的计算过程是相互独立、互不干扰的,所以适合通过大规模的线程并发执行来加速计算.
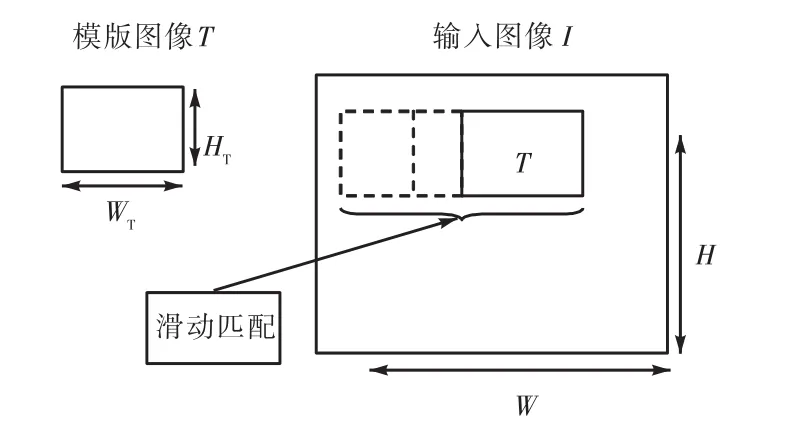
图1 滑动模板匹配算法的匹配过程Fig. 1Matching procedure of sliding template matching algorithm
2.2 模板匹配并行算法总体设计
为了通过GPU执行大量并发线程,发挥高性能并行计算优势,实现减少模板匹配过程时间的目的,将图像区域模板匹配的并行算法按照“先整体区域分块,再局部并行计算”的策略分为2步实现(图2):第1步,在GPU中将图像区域对应的CUDA线程分块(Block),进行图像数据分配;第2步,在每个Block中对每个CUDA线程对应的像素点进行定位参数计算,存储局部统计结果,然后汇总局部结果,求整体极值得到整幅输入图像中的最佳匹配位置.
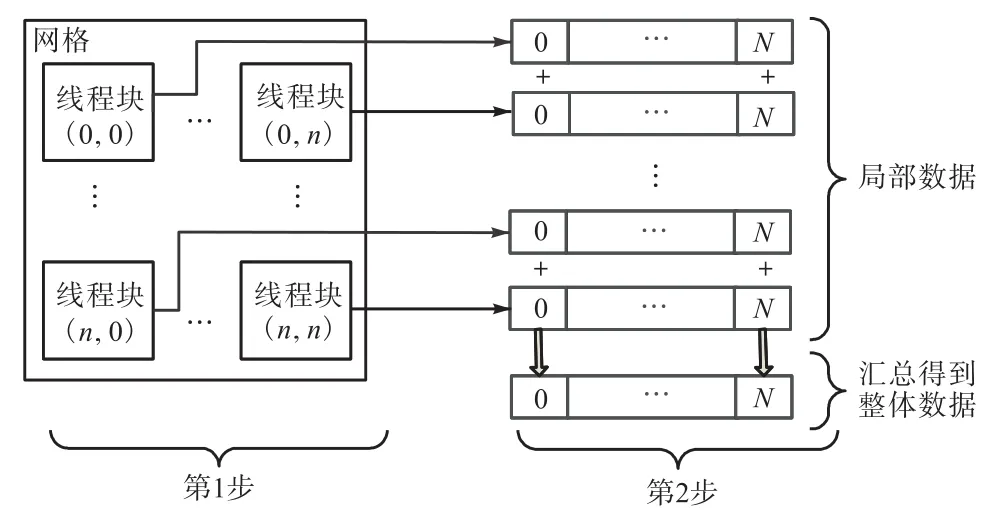
图2 模板匹配并行算法总体设计Fig. 2Overall design of parallel sliding template matching algorithm
根据滑动匹配的过程,将每个像素点位置处的匹配过程映射到CUDA线程上,1个线程处理与之对应的1个像素点的匹配过程.其中,并行化过程中需要在满足线程映射关系的前提下进行线程关键参数计算,程序如下:

2.3 并行算法的优化
根据GPU硬件特性可知,GPU存储系统中各存储单元为层次结构,其中包括:常量存储器、共享存储器、纹理存储器、全局存储器等,它们的作用域和访问效率各不相同[9].基于GPU的编程框架并未封装存储器系统的异构性,在总体设计的第1步中,针对模板图像数据在计算过程保持不变的特点,选用常量存储器存储模板图像数据,进行常数化参数存储优化;针对存储在纹理存储器中的输入图像数据访问延迟大的特点,选用SMX片上共享存储器存储局部数据,进行SMX片上数据存储优化,从而提高算法访问图像数据和存储计算结果的效率.
另外,在总体设计第2步中,可以通过简化定位参数的计算过程降低并行化过程中的计算量,进一步提高计算效率.
2.3.1 模板图像参数常数化
针对模板图像的参数在匹配操作的相关系数计算过程中始终保持不变的特点,算法中将与模板图像相关的参数提前计算出来存储于GPU的常量存储器中,从而实现模板图像参数常数化存储.然后,在定位参数计算过程中可直接读取存储器中的参数.虽然常量存储器仅有64,KB[8],但是访存速度要比设备存储器快,通常在1~100个时钟周期内就可以获取所需要的数据.
假设输入图像为W像素×H像素,在计算任意像素点定位参数时,模板图像的参数都会被计算1次,整个图像则会被重复计算WH次.通过利用常量存储器,计算次数为原来的1/WH,在模板图像参数获取上的性能提高了WH倍.具体过程见图3.

图3 模板图像数据复用原理Fig. 3 Reuse of template image data
2.3.2 输入图像数据SMX片上化
用于存储输入图像数据的GPU纹理存储器属于SMX片外存储器,通常有几百个时钟周期的访问延迟.因此,如何缩短纹理存储器的访问时间是加速的关键.
存储器层次结构如图4所示.其中SMX片上共享存储器的访问速度比纹理存储器快10倍左右[9].因此,在计算过程中把在本线程块中使用到的局部输入图像的数据存储在SMX片上共享存储器中,然后用SMX片上共享存储器中的局部原始输入图像与常量存储器中的模板图像数据进行定位参数计算.通过充分利用SMX片上共享存储器解决纹理存储器访问效率低下的问题.

图4 存储器层次结构图Fig. 4 Memory hierarchy
在串行算法中,图像数据在主机内存中始终只有1份,而在CPU+GPU异构平台下,需要拷贝纹理存储器中的图像数据到SMX片上共享存储器中保留第2份副本.这样做虽然使用了更多的GPU存储空间,但是减少了运算时间,可取得更好的算法性能.
2.3.3 简化定位参数计算


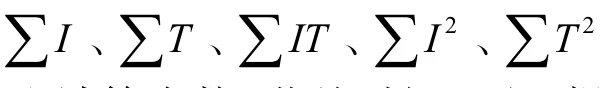
而且,由于NVIDIA Tesla K20c GPU中的极致流多处理器(SMX)包含用于整数乘法和加法的硬件结构,因此能够在GPU上快速实现该函数的求值.
2.4 模板匹配目标识别并行算法总体流程
根据模板图像数据常数化、输入图像数据SMX片上化和简化定位参数计算3方面的优化,在Tesla GPU的核心上建立大量线程,将像素点与CUDA线程一一对应,并为每个像素的计算开辟空间,利用GPU将多个像素计算的时间缩短成和1个像素点计算的时间相似,从而提高算法执行效率.基于GPU加速的模板匹配目标识别并行算法流程见图5.

图5 模板匹配目标识别并行算法流程Fig. 5 Float chart of template matching target recognition parallel algorithm
3 实 验
3.1 实验环境
硬件平台:超云服务器,GPU为Tesla K20c,含有13颗极致流多处理器,每个极致流多处理器上有192颗CUDA核心,其核心频率为706,MHz,显存带宽为320,bit,显存为4,GB;CPU为Intel Xeon CPU 3.1,GHz;系统内存为16,GB.
软件平台:操作系统为Microsoft Windows 7中文专业版;集成开发平台为Visual Studio C++ 2010;并行开发环境包括CUDA 5.0,CUDA Toolkit 5.0;计算机视觉库采用OpenCV 2.4.3.
3.2 实验结果与分析
为了验证算法的并行加速效果,采用固定模板图像大小为52像素×52像素、变化输入图像大小的4组数据(图6),对比基于CPU的串行模板匹配目标识别算法(方法1)、基于GPU的未优化并行模板匹配目标识别算法(方法2)、基于GPU的优化并行模板匹配目标识别算法(方法3)的执行效果.为了减小实验误差,算法分别运行50次,记录平均运行时间.

图6 输入图像和模板图像Fig. 6 Input image and template image
3种方法的实验对比见表1.分析表1可知:(1)对同一幅图像进行特征点检测时,方法3(基于GPU的优化并行模板匹配目标识别算法)与方法1(基于CPU的串行模板匹配目标识别算法)和方法2(基于GPU的未优化并行模板匹配目标识别算法)相比,极大地提高了算法的实时性,能够满足实际需求.(2)对于本实验,虽然将串行算法(方法1)翻译成在GPU上运行的并行程序(方法2)提高了算法效率,但是优化后的算法(方法3)能够取得更好的算法实时性.可见,并行算法的设计和开发需要根据算法本身和所使用的GPU硬件特性,有针对性的优化之后才能更好地发挥GPU的性能,获得满意的加速效果.

表1 串行算法、并行算法、优化并行算法的平均运行时间Tab. 1 Average processing time of serial algorithm,parallel algorithm and optimal parallel algorithm
4 结 语
本文在构建的CPU+GPU异构平台基础上设计了模板匹配目标识别并行算法,给出了实现的步骤和性能优化的方法,并在NVIDIA Tesla K20,c GPU上进行性能测试.结果表明,在Kepler架构下利用CUDA编程模型进行程序并行化处理和优化可明显提高算法的实时性,能够适应现在视频高清化、数字化、网络实时性等方面的要求.
[1] 于志华,张兴明,杨镇西,等. 一种高性能固定语音识别并行处理架构[J]. 计算机应用研究,2013,30(8): 2419–2421.
[2] 李俊山,沈绪榜. K元2–立方体网络SIMD计算机图像模板匹配并行算法[J]. 计算机学报,2001,24(11):1296–1301.
[3] 赵东明,罗亮. 基于DNA计算的图像模板匹配算法[J]. 华中科技大学学报:自然科学版,2013,41(2):97–101.
[4] 马永军,吴文旭,何锵锵. 一种利用多核计算的目标检测算法[C]//Proceedings of 2010 International Conference on Services Science,Management and Engineering. Hongkong:IITA,2010:209–212.
[5] Rajasekaran S. Efficient parallel algorithms for template matching[J]. Parallel Processing Letters,2002,12(3/4):359–364.
[6] Anderson R F,Kirtzic J S,Daescu O. Applying parallel design techniques to template matching with GPUs[M]. High Performance Computing for Computational Science:VECPAR 2010. Berlin,Heidelberg:Springer Berlin Heidelberg,2011:456–468
[7] 张保,董小社,白秀秀,等. CPU-GPU系统中基于剖分的全局性能优化方法[J]. 西安交通大学学报,2012,46(2):17–23.
[8] NVIDIA. NVIDIA CUDA C Programming Guide:Version 5.0[EB/OL].[2012–10–01]. http://www.nvidia. cn/object/maintenance-cudazone-cn.html.
[9] 仇德元. GPGPU编程技术:从GLSL,CUDA到OpenGL[M]. 北京:机械工业出版社,2011.
[10] Yoo J C,Han T H. Fast normalized cross-correlation [J]. Circuits,Systems and Signal Processing,2009,28(6):819–843.
责任编辑:常涛
Parallel Algorithm of CPU and GPU-oriented Heterogeneous Computation in Template Matching Target Recognition
MA Yongjun1,YUAN Ying1,LI Hao2
(1. College of Computer Science and Information Engineering,Tianjin University of Science & Technology,Tianjin 300222,China;2. Tianjin Ruihe Tianfu Science & Technology Ltd.Co.,Tianjin 300384,China)
Moving object recognition algorithm with high-definition video data suffers from large computation complexities and slow speed. With NVIDIA Tesla K20,c GPU,a method of accelerating the template matching target tracking algorithm with the heterogeneous system integrated with CPU and GPU was proposed. The parallel algorithm was designed by three optimizing means:constant memory,the internal memory of SMX and the brief calculation of correlation coefficient. Finally,the program was coded on compute unified device architecture and tested. The results show that the designed algorithm can obviously improve the real-time performance of the algorithm and guarantee the recognition effect.
template matching;target recognition;parallel computing;compute unified device architecture(CUDA);graphic processing unit(GPU)
TP311
A
1672-6510(2014)04-0048-05
10.13364/j.issn.1672-6510.2014.04.011
2014–02–24;
2014–05–04
天津市科技支撑计划重点资助项目(12ZCZDGX02400)
马永军(1970—),男,吉林长春人,教授,yjma@tust.edu.cn.
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
科技创新导报(2021年31期)2021-05-10 14:55:00
环球市场(2017年36期)2017-03-09 15:48:21
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:43
环球时报(2014-06-18)2014-06-18 16:40:11
电子设计工程(2014年23期)2014-02-27 12:02:22
电子设计工程(2014年18期)2014-02-27 12:00:14
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
空间控制技术与应用(2009年3期)2009-01-20 13:47:23
