
基于深度学习的微博情感分析
2014-02-27 06:33:39柴玉梅原慧斌昝红英
中文信息学报 2014年5期
梁 军,柴玉梅,原慧斌,昝红英,刘 铭
(1. 郑州大学 信息工程学院,河南 郑州 450001;2. 中国核科技信息与经济研究院 北京 100048)
1 引言
随着社交网络的不断发展,人们更愿意通过微博、博客社区来表达自己的观点,发表对热点事件的评论,从而使通过微博、博客、影评以及产品评价等来了解社交网络用户的情感倾向得到了学术界的广泛关注。根据微博数据进行情感分析是一个具有挑战性的任务,近年来引发了学者极大的兴趣[1]。
目前,情感分析的主要研究方法还是一些基于机器学习的传统算法,例如,SVM、信息熵、CRF等。这些方法归纳起来有3类: 有监督学习、无监督学习和半监督学习。而当前大多数基于有监督学习的研究都取得了不错的成绩[2],但是由于有监督学习依赖于大量人工标注的数据,使得基于有监督学习的系统需要付出很高的标注代价。相反的,无监督学习不需要人工标注数据训练模型,是降低标注代价的解决方案,但由于其完全依赖算法学习结果,往往效果不佳,难以达到实际要求。而半监督学习则是采取综合利用少量已标注样本和大量未标注样本来提高学习性能的机器学习方法,它兼顾了人工标注成本和学习效果,被视为一种折中方案。本文围绕半监督学习方法基于自编码算法提出一种新的分析中文微博情感倾向的深度学习算法。
已有研究所采用的方法大多数都基于词袋模型,而这种模型无法捕获到很多有关情感倾向性分析的语言现象特征。例如,“反法西斯联盟击溃了法西斯”和“法西斯击溃了反法西斯联盟”这两个词组拥有相同的词袋模型表示方法,而前一个带有积极的感情色彩,后一个带有消极的感情色彩。除此之外,还有很多研究者使用人工标注的数据(情感词典及句法分析等),虽然采用这些方法可以有效的提高情感分析的准确性,但由于需要较多的人工标注数据,从而限制了这些方法在其他领域以及跨语言的推广。
本文采用深度学习方法,不使用任何人工标注的情感词典以及句法分析结果,仅使用少量标注训练集和测试集,使用递归神经网络进行情感分类。本文首次将句子中每个词语的标签关联考虑在内提出情感极性转移模型,通过实验发现加入该模型可明显提高算法准确率。
2 相关工作
2.1 深度学习
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如,图像,声音和文本。随着深度学习方法在图像处理和语音识别方向的成功应用,越来越多的深度学习的方法也被应用于自然语言处理方向。Bengio等[3]2003年提出用神经网络构建二元语言模型的方法。随后,Ronan Collobert和Jason Weston[4]于2008年推出SENNA系统,使用词向量方法去完成自然语言处理中的各种任务,例如,词性标注、命名实体识别、短语识别、语义角色标注等。Andriy Mnih和Geoffrey Hinton于2008年提出一种层次的思想训练语言模型[5],Mikolov[6-8]最终使用Log-Bilinear模型成功将深度学习的模型降低到可接受范围内,并随后在谷歌推出word2vec将词语转换成词向量的工具[9]。Socher[10]于2012年提出基于递归自编码器(Recursive AutoEncoder , RAE)的树回归模型用来分析句子的情感倾向性,但该模型无法准确捕获文本中的情感极性转移现象,本文采用RAE这种深度学习模型,引入词语间前后的关联性对其进行改进使得更适合于中文微博情感分析任务。
2.2 情感分析
情感分析自从2002年由Bo Pang提出之后,获得了很大程度的关注,特别是在在线评论的情感倾向性分析上获得了很大的发展。本文主要关注无监督的情感分析方法,由于不需要大量标注语料,无监督情感分析方法一直受到许多研究者的青睐,但同时效果也低于有监督的情感分析方法。Turney[11]首次提出基于种子词(excellent,poor)的非监督学习方法,使用“excellent”和“poor”两个种子词与未知词在搜索网页中的互信息来计算未知词的情感极性,并用以计算整个文本的情感极性。后续的非监督情感分析方法大都是基于生成或已有的情感词典或者相关资源进行情感分析。例如,Kennedy和Inkpen[12]考虑文本中词的极性转移关系并基于种子词集合进行词计数决定情感倾向。朱嫣岚[13]等人将一组已知极性的词语集合作为种子,基于HowNet对未知词语与种子词进行语义计算,从而判别未知词的极性。Lin等[14]采用LSM模型、JST模型、Reverse-JST模型构建了三种无监督的情感分析系统。但是由于深层情感分析必然涉及到语义的分析,以及文本中情感转移现象的经常出现,所以基于深层语义的情感分析效果并不理想,本文针对中文文本中经常出现的情感转移现象提出情感极性转移模型,提高了深层语义情感分析的分析效果。
3 基于RAE的深度学习模型
为了实现用于微博情感分析的深度学习模型,本文提出一个基于RAE的情感极性转移模型。该模型首先将文本数据转为低维实数向量表示,建立表示文本特征的矩阵,然后将其作为基于RAE的情感极性转移模型的输入,最后使用LBFGS算法多次迭代生成最终的模型。该模型可对低维实数向量表示的文本进行情感分类输出其情感极性。
3.1 使用词向量表示词语
不同于传统的词袋模型,在使用神经网络解决自然语言处理问题时,通常采用一个低维的实数向量来表示词语以避免数据维数灾难[3-4]。例如,使用向量[0.3 0.1 0.6]T表示“深度”,向量[0.2 0.5 0.7]T表示“学习”。然后将这些实数向量作为神经网络的输入。通常情况下,将每一个词语映射到n维实数向量空间上,即x∈n,将这些向量堆放在一起构成一个词向量矩阵L∈n×|V|,其中|V|是词表的大小。给定句子c[1:n],它包含n个词ci,1≤i≤n。其中ci的特征向量为矩阵L的第ki列,可表示为式(1)。
其中eki∈|V|是|V|中的第ki个单位向量(除第ki个分量为1外其他分量均为0)。这样该查询操作可视为一个简单的映射层。
3.2 递归自编码
自编码的目的是学习输入数据中隐含着的特定结构,本部分将具体介绍如何使用递归自编码获取非叶子结点的低维向量表示。例如,“深度”的向量表示为[0.3 0.1 0.6]T,“学习”的向量表示为[0.2 0.5 0.7]T,那么该如何表示“深度 学习”呢?假定“深度 学习”是“深度”、“学习”的父节点p,“深度”是第一个子节点c1,“学习”是第二个子节点c2,那么p可由函数f从c1、c2映射得到,如式(2)所示。
其中[c1;c2]∈2n,由向量c1、c2联接得到;w(1)∈n×2n是一个参数矩阵;b(1)∈n为偏置项;编码器函数f(·)在这里选取双曲正切函数tanh(·)。
按照公式(2)可以得到父节点的n维向量表示[0.8 0.2 0.7]T。对整个句子递归使用这种神经网络结构,使用贪心算法每次选取两个节点结合之后父节点得分最高的节点组合,最终可以得到整个句子的n维向量表示,如图1所示。

图1 递归自编码结构图,圆形节点表示原始节点,矩形节点表示重建节点
为了验证父节点p对子节点c1、c2的表示度,在父节点p上建立一个重建层,重建两个子节点为式(3)。

这种神经网络被称为递归自编码[10],图1展示了应用于一个二叉树的递归自编码网络,其中圆形节点表示原始节点,矩形节点表示重建节点。对二叉树的每一个节点使用自编码器,那么该二叉树最终可由一个三元组(例如,(p1→c1c2),p是父节点,c1、c2是子节点)集合表示。图1中的二叉树可表示为: (y1→x1x2),(y2→y1x3)和(y3→y2x4)。
仔细分析发现,按照上面的自编码方式进行训练可能出现两个问题: (1) 节点的向量表示为零向量,这会导致该节点的重建误差Erec为零,事实上这是没有意义的; (2)节点c1和节点c2可能包含的叶子节点数有很大差异,计算重建误差时会导致不平衡。
为了解决问题(1),可以使用单位向量来表示节点p(p表示任一节点)即式(5)。
通过对父节点的向量进行正则化,可以有效避免优化算法因最小化重建误差而导致父节点向量为零向量。
为了解决问题(2),可以在计算重建误差Erec时,为每个子节点添加权重,权重的设定根据每个子节点所包含叶子节点数计算,假定节点c1的叶子节点数为n1,节点x2的叶子节点数为c2,重新定义重建误差Erec,如式(6)所示。
通过节点权重的添加,可以使得计算重建误差时更多地偏向子节点数目更多的节点,从而达到平衡误差的效果。
3.3 情感极性转移模型
使用递归自编码可以得到二叉树中每个节点的n维向量表示,根节点则是整个句子的n维向量表示。为了得到句子的情感倾向性,可以再加一层输出层如式(7)所示。
其中w(3)∈k×n(k是情感标签的数量,本文仅关注负向和正向两类,即k=2);b(3)∈k为偏置项;激活函数μ(·)选择softmax(·)函数。如图2所示,其中三角形节点表示输出层,输出句子的情感倾向性。

图2 加入输出层的递归自编码模型,其中三角形节点表示输出层
定义情感标注集Τ={正,负},这样得到的s(p;θ)中的每一个分量si就对应该句的情感倾向为Ti的得分。为了验证该得分的准确性,采用交叉熵作为代价函数(假定ti表示句子情感倾向性为Ti的真实概率),如式(8)所示。
对于情感分析这样的自然语言处理任务来说,一个句子中的各个词语之间存在很强的依赖性。例如,“不 喜欢”这样的子句,“不”的情感倾向为负,“喜欢”的情感倾向为正,而“不 喜欢”子句的情感倾向性显然为负。当连续两个词语的情感标签由Τ中的第i个ti变为第j个tj时,引入相应的转换分数Aij(Aij∈{A01,A00,A10,A11}),如图3所示。

图3 加入情感转换因子的递归自编码模型,Aij为x1到x2的极性转换因子
根据3.2节得到的重建误差函数和3.3节得到的标签误差函数,可以得到情感极性转移模型的代价函数为(数据集假定为S,每个数据对象包含一个句子c和对应的情感标签t)式(9)。
(9)
其中,E(c,t;θ)=αErec+(1-α)Ece(α为可调参数),λ也为可调参数。具体模型的算法描述:

训练情感分析模型输入:训练语料S及其对应标签t输出:θ={w(1),w(2),w(3),A,b(2),b(3)}1)使用高斯分布初始化训练语料的词向量表示;2)while不收敛doÑJ=0forall
4 实验
为了保证结果的可靠性,本文选用两个数据集来验证模型的有效性。(1)COAE2014微博数据集,采用人工标注的方式,标注了10 000条数据,带有情感色彩的有2 740句,其中带有消极情感的有1 608句,带有积极情感的有1 132句。(2)COAE2014微博数据集完整版,共计40 000条数据,其中包含已标注过的10 000条数据。
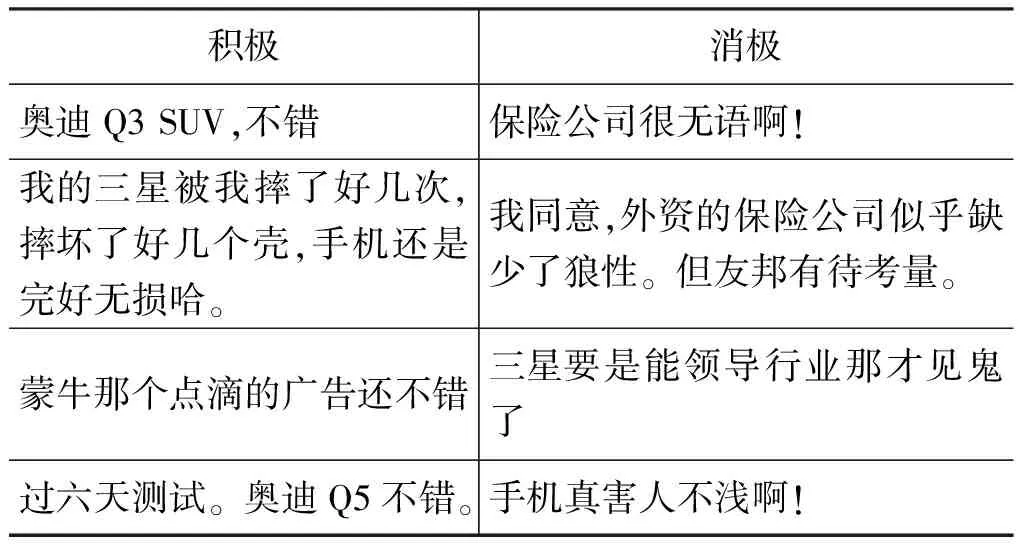
表1 COAE2014数据集样例
本文共设计3个实验来验证情感极性转移模型的有效性。实验一: 可调参数选择,用来确定可调参数对算法的影响并选择一组最优的参数;实验二: COAE2014数据集封闭测试,用来对比在相同实验集上未使用其他人工标注数据的情感极性转移模型与其他传统方法的效果;实验三: 对比实验,比较本文提出的改进模型与RAE模型的优劣。
4.1 可调参数选择
本实验用来测试可调参数(具体包括算法迭代次数、正则惩罚项系数、重建误差权重),对算法性能的影响。实验数据采用人工标注2 740句带有感情色彩的句子进行十折交叉验证(即随机抽取2 466个句子作为训练集,274个句子作为开发集)。

图4 迭代次数、惩罚项系数和重建误差权重对算法的影响
通过实验可以发现,随着迭代次数的增加模型对训练数据的拟合越来越好,F值可以达到95%,带随之而来的就是过拟合问题,导致模型的泛化能力下降,对比发现当迭代次数为10次数在训练数据和测试数据上的F值都能达到80%左右。观察惩罚项系数对算法性能的影响曲线可知: 当惩罚项系数为0.001时,对于训练数据和测试数据均可以达到较好的结果,随着惩罚系数的减小,过拟合问题越来越严重(测试数据准确率下降)。根据图4结果,可以发现,当重建误差占误差比20%时算法的性能达到最好。
4.2 COAE2014数据集封闭测试
本实验数据采用COAE2014微博数据集完整版(与实验一的训练集、开发集不同,该数据集共计40 000条数据,包含实验一采用的2 740句数据)作为测试集,进行完全封闭实验,不采用任何评测外数据集,并与其他应用于该评测数据集的结果做比较。

图5 比较不同系统在COAE数据集上的性能
SA为本文系统,与COAE2014上其他系统相比,在准确率上均与最好水平接近,且通过分层训练模型大大降低了深度学习的训练时间复杂度,达到了可以应用的水平。
4.3 对比试验
本实验选用除标注数据外的30 000条数据作为测试数据,在实验数据上分别使用递归自编码模型和情感极性转移模型,对比情感极性转移模型相对于传统递归自编码模型的优劣。

表2 可调参数的设置
按照表2设定可调参数,在相同条件下对比情感极性转移模型相对于传统递归自编码模型,结果如表3所示。

表3 两个模型对比结果
通过对比,发现在加入情感极性转移因子后,该模型明显有了较大程度的提升。因为句子中的情感发生转移在中文句子中是很常见的,而传统RAE模型没有考虑该因素。
5 结语
本文提出了一种基于RAE的情感极性转移模型,在不增加神经网络复杂度的前提下,提高了模型对中文微博情感分析的准确性,算法的表现已经很接近当前采用许多手工标注特征的传统算法的性能。
深度学习方法在情感分析上的研究还存在很多问题需要进一步探讨。例如,从上面的实验结果可以看出,神经网络模型由于参数数量较多在训练模型时很容易出现过拟合的情况。下一步工作将深入研究如何降低模型的结构风险,从而寻找到更适合情感分析的深度学习算法。
[1] B. Pang, L. Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales[C]Proceedings of the ACL, 2005: 115-124.
[2] 唐慧丰,谭松波,程学旗.基于监督学习的中文情感分类技术比较研究[J].中文信息学报 2007, 6(2):88-94
[3] Y. Bengio, R. Ducharme, P. Vincent, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003,3:1137-1155.
[4] Collobert R, Weston J. A unified architecture for natural language processing: Deep neural networks with multitask learning[C]//Proceedings of the 25th international conference on Machine learning. ACM, 2008: 160-167.
[5] Mnih A, Hinton G E. A Scalable Hierarchical Distributed Language Model[C]//Proceedings of NIPS. 2008: 1081-1088.
[6] Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]//Proceedings of INTERSPEECH. 2010: 1045-1048.
[7] Mikolov T, Kombrink S, Burget L, et al. Extensions of recurrent neural network language model[C]//Proceedings of Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on. IEEE, 2011: 5528-5531.
[8] Kombrink S, Mikolov T, Karafiát M, et al. Recurrent Neural Network Based Language Modeling in Meeting Recognition[C]//Proceedings of INTERSPEECH. 2011: 2877-2880.
[9] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[10] Richard Socher, Jeffrey Pennington, Eric Huang, et al. Manning Conference onEmpirical Methods in Natural Language Processing (EMNLP 2011, Oral ) Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions.2011.
[11] Turney P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 417-424.
[12] Kennedy A, Inkpen D. Sentiment classification of movie reviews using contextual valence shifters[J]. Computational Intelligence, 2006, 22(2): 110-125.
[13] 朱嫣岚, 闵锦, 周雅倩等. 基于 HowNet 的词汇语义倾向计算 [J]. 中文信息学报, 2006, 20(1): 14-20.
[14] Lin C, He Y, Everson R. A comparative study of Bayesian models for unsupervised sentiment detection[C]//Proceedings of the Fourteenth Conference on Computational Natural Language Learning. Association for computational linguistics, 2010: 144-152.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
时代英语·高一(2019年5期)2019-09-03 02:09:34
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
电测与仪表(2016年11期)2016-04-11 12:20:42
新高考·高二数学(2015年11期)2015-12-23 18:17:44
