
添加冒号和分号分类标签特征的汉语逗号分类
2014-02-27 07:07:37李艳翠谷晶晶周国栋
中文信息学报 2014年5期
李艳翠,谷晶晶,周国栋
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 河南科技学院 信息工程学院,河南 新乡 453003;3. 苏州大学 自然语言处理实验室,江苏 苏州 215006)
1 引言
标点符号是书面语言的重要组成部分,同一种标点往往有不同的句法或篇章功能,例如,逗号有分隔小句、主谓关系和短语并列等不同的语言功能[1]。有效识别标点的功能,有助于句法分析、篇章分析、机器翻译等自然语言处理技术效果的提高。
在句法分析方面,李辛等[2]引入标点处理进行汉语长句句法分析,利用部分标点符号的特殊功能将复杂长句分割成子句序列,把整句的句法分析分成两级来进行,从而提高了复杂长句分析的正确率和召回率。Jin等[3]提出利用逗号对汉语长句进行划分,通过汉语句子的上下文识别逗号左右两边的子句是并列关系还是从属关系,并利用这两种关系对逗号进行分类,进而提高句法分析的性能。在篇章分析方面,Xue等[4]进行表示句子边界的逗号识别研究,提出逗号可等同于句子边界时要满足两点要求: 一是逗号前后子句有完整的句法结构(即具有一个完整的IP结构,存在主谓宾);二是具有独立的句义且逗号前后子句间没有紧密的句法关系。Yang等[5]对逗号的使用方法进行了更详细的分类,共分为七类: SB、IP_COORD、VP_COORD、ADJ、COMP、SBJ和Other。Yang等采用了两种基于句法信息的方法实现逗号的自动分类。谷晶晶等[6]提出一种基于汉语句子的分词与词性标注信息做逗号自动分类的方法,结果表明利用词与词性进行逗号分类的方法是可行的。在机器翻译方面,黄河燕等[7]利用标点符号和关联词等把复杂长句进行切分,简化为多个独立的简单句,再进行翻译处理,以此提高机器翻译的性能。
从以上的研究可以发现,逗号功能识别是标点研究中的重点和难点,本文主要研究汉语逗号的功能分类。文献[8]统计显示汉语宾州树库(CTB6.0)中句号、问号、叹号、分号、逗号和冒号等标点的使用频率,其中句号、问号、叹号共占29.55%,逗号高达67.17%,其次是冒号(1.69%)和分号(1.85%)。由于逗号所占比例较大并且具有较多不同的功能,因此非常有必要进行逗号的功能分类研究。汉语句子中使用频率最高的除了逗号,还有冒号和分号,本文分别将CTB6.0语料中含有冒号和分号的句子抽取出来,进行逗号的自动分类识别实验。实验结果发现(见表1),含冒号句子的语料和分号句子的语料中,逗号自动分类的总体正确率都严重低于全体语料的总体正确率,尤其是句子边界(SB)分类逗号的F值严重下降。说明含有冒号或分号的句子中逗号多元分类的自动识别效果不好,文献[6]中的错误分析也指出了IP_COORD类与SB分类容易混淆。

表1 全体语料与局部语料总体正确率对比
说明: 实验采用文献[6]的特征和最大熵分类器。含冒号语料是指从全体语料中抽取出来每个句子中至少包含一个冒号的语料;含分号语料是指从全体语料中抽取出来的每个句子中至少包含一个分号的语料。
逗号、冒号和分号在使用上存在一定的层次关系。通常情况下,分号的层次比逗号更接近根节点。在冒号作用域内,分号层次低于冒号,高于逗号。这些标点符号丰富的使用方法导致了汉语句子长度较长且语义复杂。逗号分类是标点分析的一个重要工作,由表1可知,含有冒号和分号的语料中逗号的分类效果较差,所以有必要专门进行处理,看能否增加逗号分类的正确率。
本文主要研究添加冒号和分号分类标签为特征后的逗号自动分类。主要从以下3方面进行展开: 首先给出标点分类方法;然后介绍基于此分类方法的标点分类语料库;最后给出冒号和分号对逗号分类影响的实验结果与分析。
2 标点分类
2.1 逗号分类
本文借鉴Yang等[5]提出的逗号分类标准,将逗号使用方法划分为7类。首先把逗号的使用方法在总体上分为两种,即所连接的两子句之间存在关系和不存在关系。两子句之间存在的关系又分为并列关系和从属关系。并列关系有3种类型(SB、IP_COORD与VP_COORD),从属关系也有3种类型(ADJ、COMP与SBJ)。每种类别的具体说明见文献[6],图1展示了逗号分类类别。下面对每种类别进行简单说明,实例中属于此类的逗号用c1...cn标识,如例1中的c1和c2属于类别SB,例2中的c3属于IP_COORD类。
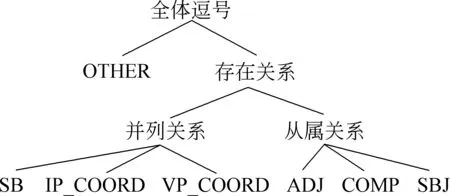
图1 逗号分类类别
SB(SentenceBoundary): 分割句子边界的逗号。该类逗号是指在某些语境下,起句子边界的作用。该类逗号要求逗号左右的子句都是IP结构,父节点为根节点。如例1中的c1和c2。
例1陕西省目前批准的外资项目已达两千四百多个,c1协议利用外资额四十多亿美元,c2实际引进外资超出十六亿美元。
IP_COORD(IPCoordination): 分割父节点为非根节点的并列IP结构的逗号。如c3和c4。
例2他指出,中国共产党在农村改革中形成了一整套基本政策,c3实践证明是正确的,c4必须保持稳定性和连续性。
VP_COORD(VPCoordination): 分割并列动宾短语的逗号。这一类的逗号与IP_COORD类逗号相似,都是分割嵌套结构中的并列结构。
例3中国银行是四大国有商业银行之一,c5也是中国主要的外汇银行。
ADJ(Adjunction): 分割附属从句与主句的逗号。附属从句是指在句子中担当某种句子成分的主属结构。虽然从句部分的句子结构是完整的,但它并不能脱离主句部分独立完整地表达意思。
例4为了在运行机制上与保护区相配套,c6宁波保护区率先在中国实施了企业依法注册直接登记制的试行一站式管理。
COMP(Complementation): 分割句子谓语与宾语的逗号。通常出现在“表示”、“指出”、“认为”、“介绍”等提示性动词之后。
例5业内人士认为: c7它将为中韩两国经贸界提供一次扩大交流与合作的良机。
SBJ(SententialSubject): 分割句子主语和谓语的逗号。SBJ类逗号表示的是逗号分割开了句子的主语与动宾结构。
例6出口快速增长,c8成为推动经济增长的重要力量。
Other: 其他类型。本文将不属于上述6种类型的逗号都划分为Other类型。
2.2 冒号分类
[1],本文将冒号的使用方法归纳为7类(如图2): 引用、动宾、边界、总分、解说、提示、Other。其中引用、动宾和边界又归为话语引用类,而总分、长解说和短解说又归为解释说明类。Other分类是对冒号的一些不经常使用的用法归类。下面对每种类别的冒号进行举例说明。

图2 冒号分类标准
例7秦牧: c9要学好语文,必须注意多读、多写、多思索。
动宾(VP): 该类冒号分割开了谓语动词与宾语。常用的谓语动词有: 问、答、说、曰、云、想、是、证明、宣布、例如、如下等。
例8克莱因说: c10“普遍的观点是人以群分,人们总喜欢和自己相似的人,所以有理论提出多样化不利于团结。”
边界(SB): 该类冒号被定义为句子边界,冒号前后的句子都是一个完整的IP结构,可独立存在。冒号后的句子一般是对冒号前句中主语的话语引用,由左右双引号界定。
例9凤姐连忙告诉小丫头传饭: c11“我和太太都跟着老太太吃。”
总分(ZF): 冒号前的句子是总说,冒号后面的句子是对前面句子的分说。
例10本文将冒号的使用方法归纳为七类: c12引用、动宾、边界、总分、短解说、提示、Other。
解说(LJ): 后面的句子是对冒号前面的词语的解释说明。
例11有人曾做过对比实验: c13两个病情相近,年龄和体重相差无几的手术患者,每天食用一只海参的患者,会比另一个患者提前20天左右全面康复。
提示(SJ): 该类是生活中常用的、位于提示短语后的冒号。该类冒号是从解说类中分离出来的一类,冒号后的内容也是对冒号前词或短语的解说,该类冒号前通常只有一个词或短语。
例12电话: c14 8888888
Other: 本文设置一个Other类,是因为存在一些使用方法出现频率较低的冒号,有分总类冒号、呼语类冒号以及作者与作品之间的冒号,例如,“朱自清: 《背影》”。这些使用方法的冒号都可单独作为一类,但由于实际语料中出现的频率较低,故将这些使用方法统归为Other类。
2.3 分号分类
参考文献[1],本文对分号设置3类标注标签,分别是: 并列关系(BL)、非并列关系(FB)和条款类(TK)。其中,并列关系是指分号两边的多个子句是并列的关系,而非并列关系是指两边的多个子句间存在转折、因果等非并列关系。条款类是指分条或分行列举的分句之间使用的分号,这类分号通常用在冒号的作用域内。标注方法与标注冒号的分类标签方法相同。
例13语言,人们用来抒情达意;c15文字,人们用来记言记事。
例14我国年满十八周岁的公民,不分民族、种族、性别、职业、家庭出身、宗教信仰、教育程度、财产状况、居住年限,都有选举权和被选举权;c16但是依照法律被剥夺政治权力的人除外。
例15中华人民共和国行政区域划分如下: c17(一)全国分为省、自治区、直辖市;c18(二)省、自治区分自治州、县、自治县、市;c19(三)县、自治县分乡、民族乡、镇。
例13中的分号为并列关系类,例14中的分号属于非并列关系类,例15中的分号属于条款类。对于条款类的分号,有时一个分句为一行,如例15中的(一)(二)(三)可以分别作为一个段落,这时的分号相当于段落间的分割符号。识别该类分号对于基于段落的篇章分析有一定的帮助。
3 标点分类语料
3.1 逗号分类语料
据统计,CTB 6.0语料中共有51 886个逗号,各分类所占的逗号数量比例如表2所示。采用与文献[6]中相同的训练语料和测试语料划分方式,训练语料包含了42 497个逗号,测试语料包含了5 436个逗号。
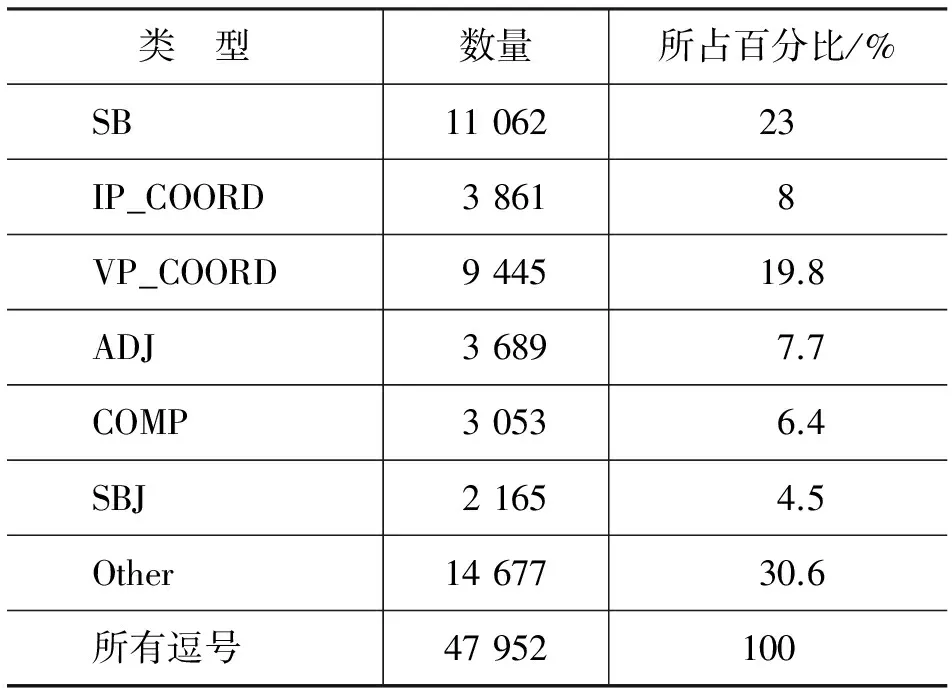
表2 CTB 6.0语料中各类逗号分布
3.2 冒号分类语料
本文的冒号语料实验数据是从逗号自动分类与识别语料(CTB6.0)中抽取出来的。抽取出的冒号语料大小为原始全体语料的9%,具体标注的冒号数量和冒号语料中逗号的数量如表3所示。由表3可以看出,语料中含有的冒号的个数只是逗号个数的50%左右,但是位于冒号后的逗号占逗号总数的78%。由此也可以预见,添加冒号分类标签特征后,将对逗号的自动分类与识别产生影响。在逗号分类的训练语料和测试语料中分别抽出所有包含冒号的句子,构成新的训练语料和测试语料。对抽取出来的训练语料和测试语料,首先分别进行预处理,再分别进行人工标注汉语冒号分类标签。所标注的冒号分类标签参考2.2中的冒号分类,主要标注7类标签,分别是引用(Nm)、动宾(VP)、边界(SB)、总分(ZF)、解说(LJ)、提示(SJ)和Other。
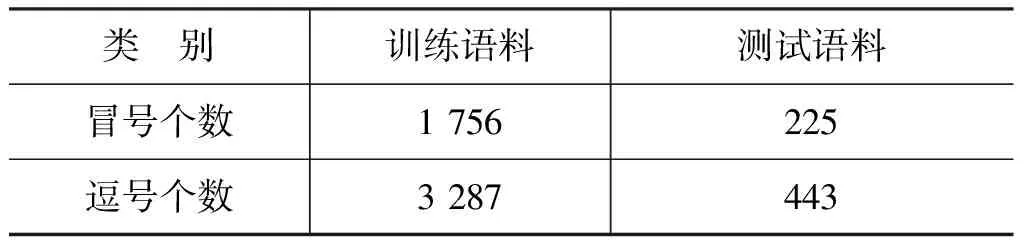
表3 冒号语料中各标点个数
冒号语料中存在与例16类似的句子,即句子中只含有冒号而没有逗号,且冒号位于句末,这种情况的句子不在本文实验的考察范围之内。类似例16中的冒号一般是位于一个段落的结尾处,下面紧跟着的一个段落或者是多个段落都在该冒号作用域内,但这些段落中的逗号分类与识别已经不受该冒号的影响,故该类冒号不在本文的考察范围之内。
例16港台会师看新局:
3.3 分号语料
分号语料同样是从逗号自动分类与识别语料中抽取出来的。采取和冒号语料同样的处理方法,经过预处理后再进行人工标注。
分号语料中含有的分号和逗号个数统计结果如表4所示。据统计,抽取出的分号语料大小为原始全体语料的5.5%。相比于冒号,分号数量更少。
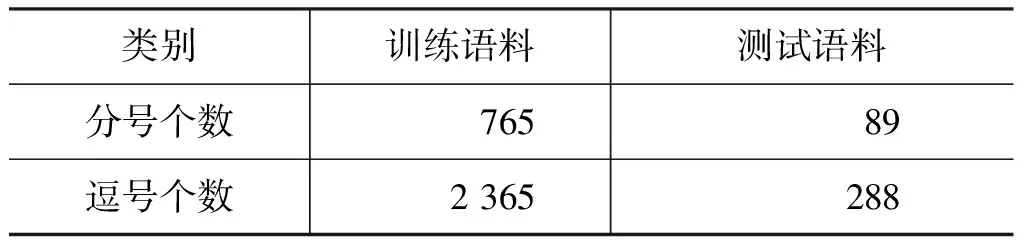
表4 分号语料中各标点个数
4 实验结果与分析
本节分别进行了添加冒号分类标签特征、添加分号分类标签特征和同时添加这两种标点分类标签特征的实验。这3个实验采用了基本相同的方法,流程如图3所示。根据Yang等人[5]一文中介绍的逗号各分类对应的句法模型,预处理系统每次读入一个带句法信息的句子,对句中逗号,分别提取逗号分类的三元组文件,即[句子标号,逗号序号,逗号分类标签]。通过对CTB 6.0句法树库的自动提取(即预处理系统),可以得到该实验训练模型时所需要的逗号训练样例(即三元组文件)和测试样例。

图3 添加冒号(分号)分类标签特征的逗号分类流程图
本文基本特征选取和文献[6]相同: 1) 子句主干特征,从分词与词性标注的序列中,选取3个能表示子句主干的词;2) 当前逗号序号及序号前的逗号分类类别,通过提取这些特征可以间接反映句子的层次结构;3) 词汇特征,提取词汇特征是为了得到体现逗号左右子句特点的词,比如存在介词、连词、副词等。另外,分别添加冒号或分号的分类标签为一组新特征。
4.1 添加冒号分类标签特征的实验结果及分析
4.1.1 冒号语料的实验结果
按照文献[6]的最大熵模型实验提取上下文特征的方法,在提取原特征的基础上,将当前逗号前的冒号分类标签作为一个新的特征加入到特征集合中。实验的结果如表5所示。

表5 冒号语料中逗号自动识别结果
从表5可以看出,逗号分类的自动识别整体正确率提高了9.9%,说明通过添加冒号分类标签特征来提高逗号自动识别正确率的方法是可行的,而这两类标点符号之间是存在影响的。表5中,各分类逗号的F值都有不同程度的提高,尤其是SB分类和IP_COORD分类,分别提高了32.3%和23.0%。说明添加的冒号分类标签,对这两类逗号识别正确率影响最大,一些被错分为SB分类的逗号,在本实验中被正确识别为IP_COORD分类。至于SBJ分类的自动识别F值为零,是由于属于该分类的逗号在训练样例中只出现了3次,在测试样例中只有1个。
4.1.2 全体语料的实验结果
在冒号语料的实验取得成功后,本实验将标注了冒号分类标签的语料带入到全体语料中,替换没有被标注的冒号句子。在标注了冒号分类标签的全体语料上,再次进行实验,新实验同样是在添加冒号分类标签特征后进行多元逗号分类。实验结果如表6所示。
表6列出了添加冒号分类标签前后,分别采用最大熵模型和CRF模型的实验结果。基于最大熵模型的全体语料整体正确率提高了0.7%,基于CRF模型的全体正确率提高了0.8%,由此也再次说明基于CRF模型的自动分类识别正确率要高于基于最大熵模型的自动识别正确率。由表3统计的数据可知,冒号语料中的逗号个数占全体语料中逗号个数的6.9%,而由表5添加冒号分类标签特征的冒号语料逗号分类总体正确率提高9.9%,表6全体语料总体正确率提高0.8%,实验说明冒号语料和全体语料在添加冒号分类标签特征后,提高的总体正确率是成比例的。
同时,SB分类和IP_COORD分类的逗号在全体语料的实验中,结果都有一定的提高。在全体语料上,SB分类并没有IP_COORD分类F值提高的多,因为在全体语料中,SB分类共有1311个,而IP_COORD分类只有506个。
4.1.3 边界识别
引言中提到冒号对IP_COORD分类和SB分类的逗号存在明显影响,由于SB分类属于逗号标示句子边界的情况,所以本文将同样考察冒号对识别逗号作为句子边界情况存在的影响。识别SB分类,即为识别句子边界(EOS,End Of a Sentence)。结合本文的实验,只需将SB分类归为EOS,余下的6类归为非句子边界(Non-EOS,Not the End Of a Sentence)。表7列出了基于最大熵模型的全体语料在添加冒号标签特征前后,识别逗号标示句子边界的实验结果。
由表7可以看出,在添加冒号标签特征后,逗号标示句子边界的实验结果在总体正确率上提高1.2%,EOS和NEOS分类的F值也分别有所提高。再次说明,冒号分类标签对逗号的分类自动识别存在影响。
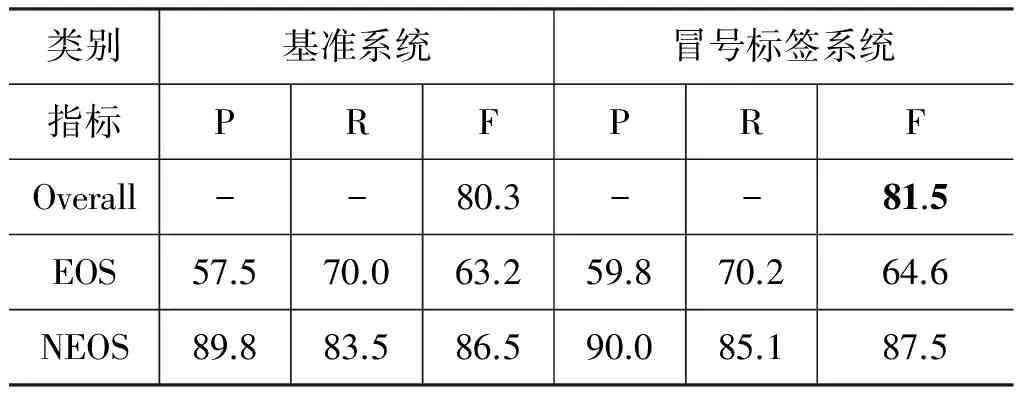
表7 逗号标示句子边界的识别结果
4.2 添加分号分类标签特征的实验及分析
4.2.1 分号语料的实验结果
添加分号分类标签特征的实验与添加冒号分类标签特征的实验类似。在提取原有特征的基础上,将当前逗号前的分号分类标签作为一组新的特征添加到特征集合中。实验结果如表8所示。

表8 分号语料中逗号分类自动识别结果及对比
表8中分号语料基准系统的实验是基于最大熵模型的,添加分号分类标签特征的实验分别采用了最大熵和CRF两种模型。CRF模型的自动识别正确率比最大熵模型的更高,但这里主要对比添加分号分类标签特征前后的最大熵模型的实验结果。由表8可知,基于最大熵模型的实验结果中,逗号分类的自动识别整体正确率提高了4.6%。
表8中,各分类逗号的F值都有不同程度的提高,但并不像添加冒号分类标签的实验结果中SB分类和IP_COORD分类正确率提高的幅度那样大。正确率提高相对较高的是ADJ类逗号和VP_COORD类逗号。实验表明添加分号分类标签特征提高逗号自动识别正确率的方法是可行的。
4.2.2 全体语料的实验结果
在分号语料的实验取得成功后,本文同样将已标注的分号语料反馈到原语料中。同样的方法,实验结果如表9所示。

表9 添加分号标签后的全体语料实验结果及对比
由表9可知,添加新特征后最大熵模型的总体正确率提高了0.2%,而CRF模型的总体正确率提高了0.5%。在添加冒号分类标签特征的实验结果(表6)中,CRF模型和最大熵模型分别提高了0.7%和0.8%。添加分号分类标签特征效果没有添加冒号分类标签特征明显与它们在语料中所占的比例有关,由3.2和3.3节可知,冒号语料占全体语料的9%,而分号语料明显较小,占全体语料的5.5%。
比较表6和表9可知,CRF模型比最大熵模型效果要好。因为CRF模型计算了全局最优的输出节点的条件概率,而不是只通过当前的状态来定义下一个节点的状态。通过分析冒号和分号的作用域可以发现,冒号的作用域是从冒号后的第一个字符开始到句末标点结束;而分号的作用域不止包含在分号后面的句子部分,它的作用域为当前分号前后相邻的两个分号(相邻不是分号时,为句子开始字符和句子结束字符)之间。故在添加分号分类标签特征的实验中,更能体现CRF模型的优越性。
4.3 同时添加冒号和分号分类标签特征的实验
同时添加冒号和分号分类标签为特征的实验,是指同时添加当前逗号前的冒号的分类标签和分号的分类标签作为一组新的特征进行实验。实验结果如表10所示。
通过对全体语料的基准系统和分别添加其中某一个标点的分类结果对比,该综合实验的总体正确率及各项的分类的F值都有所提高,说明本文提出的添加其他标点符号的分类标签特征辅助逗号多元分类的自动识别方法是可行的,且取得了相对较好的成绩。CRF模型的总体正确率达到69.2%,已经非常接近Yang等基于句法信息的71.5%的总体正确率。
5 结论
本文主要研究了分别添加冒号和分号分类标签,以及同时添加两类标点的分类标签特征后,对逗号自动分类结果的影响。实验结果表明,在分别添加冒号或分号分类标签特征后,逗号多元分类的自动识别正确率都有所提高。在同时添加这两类标点分类标签特征时,逗号识别的正确率达到69.2%。本文实验说明分号和冒号分类对逗号分类是存在影响的,合理地利用冒号或分号分类标签可以提高逗号分类的正确率。
参考文献
[1] 中华人民共和国国家质量监督检验检疫总局、中国国家标准化管理委员会. GB/T15834-2011标点符号用法[M].北京:中国标准出版社, 2011.
[2] 李幸, 宗成庆. 引入标点处理的层次化汉语长句句法分析方法[J]. 中文信息学报, 2006, 20(4): 8-15.
[3] Mei xunjin,Mi-Yong kim,Dongi kim, et al. Segmentation of Chinese long sentences using commas[C]// Proceedings of 3rd ACL SIGHAN Workshop. Barcelona,2004: 1-8.
[4] Nianwen Xue, Yaqin Yang. Chinese sentence segmentation as comma classification. [C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, 2011: 631-635.
[5] Yaqin Yang, Nianwen Xue. Chinese Comma Disambiguation for Discourse Analysis. [C]//Proceedings of Annual Meeting on Association for Computational Linguistics (ACL), 2012: 786-794
[6] 谷晶晶, 周国栋. 基于分词与词性标注的汉语逗号自动分类[J]. 计算机工程与应用,http://www.cnki.net/kcms/doi/10.3778/j.ssn.1002-8331,2014: 1310-0034.
[7] 黄河燕, 陈肇雄. 基于多策略分析的复杂长句翻译处理算法[J]. 中文信息学报, 2002, 16(3): 1-7.
[8] 李艳翠, 冯文贺, 周国栋. 基于逗号的汉语子句识别研究[J].北京大学学报,2013,49(1): 7-14.
猜你喜欢
红蜻蜓·低年级(2022年9期)2022-10-14 06:47:58
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:58
小天使·一年级语数英综合(2020年11期)2020-12-16 02:57:22
环球时报(2018-12-18)2018-12-18 04:27:47
作文周刊·小学二年级版(2018年21期)2018-09-06 11:00:08
阅读与作文(初中版)(2016年12期)2016-12-07 22:34:33
作文周刊·小学一年级版(2015年38期)2015-05-30 10:48:04
作文周刊·小学一年级版(2015年42期)2015-05-30 00:05:39
