
翻译规则剪枝与基于半强制解码和变分贝叶斯推理的模型训练
2014-02-27 07:06:42高恩婷段湘煜巢佳媛
中文信息学报 2014年5期
高恩婷,段湘煜,巢佳媛,张 民
(1. 苏州科技学院 电子与信息工程学院,江苏 苏州 215011;2. 苏州大学 计算机科学与技术学院,江苏 苏州 215006)
1 引言
目前,统计机器翻译(SMT)通常采用启发式方法训练翻译模型。首先,利用启发式方法(包括intersection, grow, grow-diagonal, grow-diagonal-final和union)在训练数据上构建双向词对齐。然后,在词对齐的基础上抽取翻译规则,抽取方法同样也是利用启发式方法,通过设置不同的剪枝阈值,例如,最大规则高度/宽度、每个跨度的最大规则数目、结点数量等,控制翻译规则的数量。最后,对于抽取出的翻译规则集进行概率计算,其概率通常定义为规则的相对频率。启发式方法的主要优点在于它的简洁性,便于理解和实现。因此,启发式方法广泛用于统计机器翻译模型训练中。
但是,启发式方法的理论基础不够完善,训练过程独立于解码和建模过程。因此,启发式方法的翻译模型非最优,且学习到的大量翻译规则都是冗余规则。针对这两个问题,本文采用变分贝叶斯EM算法(Variational Bayesian EM, VBEM)来训练翻译模型[1-4]。VBEM算法是传统EM算法的扩展,且两者的总体框架相似[5]。VBEM算法的E步对训练集进行强制对齐,M步更新模型。VBEM算法和EM算法主要区别在于目标函数,体现在M步如何对模型进行更新。VBEM算法的优点在于,引入先验知识克服EM算法过估计“大规则”而忽视“小规则”的过度拟合问题。与启发式方法相比,VBEM算法能得到最终在翻译派生路径中实际使用的翻译规则,可确保训练过程更符合解码和建模过程。因此,VBEM算法能兼顾小规则集,并且使翻译概率更精确。在NIST汉英翻译任务上的实验结果显示本文方法有效。
2 相关工作
本节分别从两个方面介绍相关工作: SMT模型剪枝和模型训练。
SMT模型剪枝的相关研究[6-11]都采用基于某些统计量(或启发式)的方法来实现模型剪枝,其所使用的剪枝策略与翻译模型训练和解码相对独立。与之相比,本文没有利用启发式方法,而是通过训练过程和强制对齐来决定所需规则。由于使用了稀疏先验分布,本文学得的翻译规则较小,具有较强的泛化能力,并且因为强制对齐的应用,翻译规则由实际派生路径上抽取而得,与实际解码过程在统计意义上一致。
SMT模型训练的相关研究中,存在两类方法不使用启发式方法进行模型训练。一类是基于EM算法的方法[12-16]。另一类是基于贝叶斯学习的方法[17-21]。这两类方法与启发式方法的主要区别是如何获取对齐结构。启发式方法第一步先获得词对齐信息,第二步再在词对齐的基础上抽取更高层次的结构对齐,这些结构对齐必须和词对齐相一致,但无法保证合法的派生路径(解码路径),从而使相对频率的估计也不准确。这两步之间在统计意义上相互独立,对齐结构的获取缺乏理论依据,从而引起了放弃启发式方法的研究,主要包括上述提及的基于EM算法的方法和基于贝叶斯学习的方法,这两类方法直接学得结构对齐,不使用割裂的中间步骤。
基于EM算法的方法的首先提出者是Marcu和Wong[12],将词对齐模型(IBM模型)扩展到短语对齐模型。但由于EM算法存在过度拟合问题,导致往往较长的短语对被抽取出来,在极端情况下整个句对会被作为一个短语对抽取出来。这个问题随后被深入地进行分析[13],并先后有相应的方法加以解决,但都是在较小规模上进行实验,没有证据表明这些方法具备进行大规模应用的能力。因此,基于EM算法的方法不能有效解决基于启发式方法的模型训练存在的问题。
基于贝叶斯学习的方法可通过引入稀疏先验分布调整过度拟合问题,得到的后验分布往往比EM算法得到的分布更加稀疏,即只有较为常用的对齐结构的概率较大,出现稀疏的概率峰值,而不是EM算法得到的比较平均的概率值。其中代表性的方法有针对树到串对齐结构的方法[21]和针对短语对齐结构的方法[18],实验表明具有较强泛化能力的对齐结构可以通过贝叶斯学习的方法获得。由于关注一步得到结构对齐,贝叶斯学习方法具有较高的复杂度。Blunsom等[18]提出了局部Gibbs抽样方法,可以避免对整个平行句对进行计算的较高复杂度,但是局部Gibbs抽样方法有较慢的混合(mixing)速度,即样本抽样会陷落在一个局部最优点附近而不易产生新的抽样。为克服混合速度慢的问题,块化的Gibbs抽样被应用于树到串对齐结构抽样上[21],使得整个平行句对同时被抽样,易于脱离局部最优点。
本文利用变分贝叶斯推理训练翻译模型,不仅克服了在结构对齐学习中容易出现的过度拟合问题,而且通过引入平均场(Mean Field)降低了推理算法的复杂度。本建模方法不依赖于启发式方法(如限制规则数量,或通过词法概率进行平滑)。相较于EM算法,变分贝叶斯推理可以获得较为稀疏的对齐结构;相较于基于贝叶斯学习的抽样方法,变分贝叶斯推理性能更好且容易实现,能解决对大规模语料和长句进行参数估计时存在的问题。
3 基于变分贝叶斯推理和强制解码的翻译模型剪枝和训练
本文所用方法的模型训练框架概述如下:
1) 利用传统的基于启发式方法的模型作为初始Bootstrapping模型;
2) 用现有的模型对训练语料进行强制解码;
3) 利用步骤2中的训练语料,更新现有的模型;
4) 在开发集上对模型权重调参,返回到步骤2直到收敛至最优。
本文不使用额外的语言学资源,而是通过简化训练过程来获得相应规则,并从训练语料中获得规则的相应概率。
3.1 变分贝叶斯推理
变分贝叶斯推理根据先验知识能解决传统EM算法的过度拟合问题。变分贝叶斯推理寻找近似后验概率的分布(用KL距离度量),便于计算后验概率[22]。贝叶斯学习系统通常将Dirichlet分布作为先验知识。因为贝叶斯学习系统简易且有效,本文对Dirichlet先验知识使用平均场变分贝叶斯EM算法来最大化后验概率。平均场是一个近似完全分解的变分推理。平均场便于理解和实现,包括两个步骤[4]:
1) E步: 参照传统EM算法计算期望值;
2) M步: 分为以下三步:
a. 加入Dirichlet 超参数α到期望Cr。


由上述步骤可知,平均场在使用digamma函数得到Dirichlet先验知识的基础上,重新计算期望值,动机来源于更有效的规则重用。基于EM算法的SMT模型训练、翻译规则(通常规模小)能提高最终翻译概率,但难以泛化未知数据。平均场通过Dirichlet先验知识对难以使用的规则进行惩罚,这是本文的核心思想,而另一个则是强制解码。
3.2 利用平均场进行SMT模型训练
本文的剪枝与训练过程是强制解码与平均场算法的融合。主要包含以下两个步骤:
1) 使用启发式方法抽取传统模型进行自训练;
2) E步:
a. 利用现有的模型对训练语料进行强制解码。
b. 根据传统EM算法计算每个规则的期望值Cr。
3) M步
c. 计算规则r的翻译概率如式(1)所示。
其中,α是Dirichlet的超参数,参考本文中3.1节的2.b步骤的。
4) 在开发集上,对更新的模型权重调参,返回到步骤2直到收敛至最优。
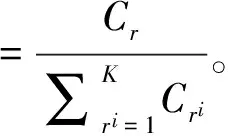
3.3 强制和半强制解码的对比
强制解码主要分三个步骤: 首先训练得到所有在标准翻译系统中使用的模型,接着使用MERT[23]方法在开发集上进行模型参数调试以获得良好的BLEU得分,再接着使用这些模型和参数在训练集上进行解码,解码路径包含着结构对齐信息。在这些结构对齐的基础上,我们可以重新估计翻译规则的概率,而使其他模型保持不变。上述三个步骤重复迭代,直至前后两次迭代之间的解码路径不存在显著差异。强制解码的优势在于使得模型训练和解码过程一致,克服了启发式方法的模型训练与解码过程割裂开来的缺点,具有统计意义上的理论基础。
强制解码也存在实际应用的不足: 往往较长的翻译规则被保存在最终的解码路径上。这是因为解码路径上的分解的翻译规则越少,解码路径的概率越高,从而使强制解码倾向于使用较少的翻译规则来完成解码,导致较长的翻译规则被最终保留。为克服这个不足,Wuebker等[16]使用leaving-one-out方法对各个结构对齐的概率进行平滑,以降低较长的对齐结构的概率,提高过低的泛化能力高的对齐结构的概率。本文使用另外一种方法来克服此种不足,通过3.1节所述的变分贝叶斯引入稀疏先验分布,寻找泛化能力高的翻译结构。
此外,强制解码要求部分假设必须与参考相兼容,最终翻译必须与参考相一致。但由于翻译规则的抽取未必能覆盖整个平行句对,导致某些平行句对不能产生有效的解码路径。与西方语言翻译到英文相比,汉英翻译中这个问题更加明显,部分句对不能成功强制解码。本文汉英实验数据结果显示,使用Moses[23]强制解码的句对中只有72.2%能成功解码。同样,使用重新实现的基于森林的树到串句法系统强制解码,显示只有31.4%句对能成功解码。
为使强制解码达到100%的成功率,且确保翻译结果与参考尽量相似,本文采用半强制解码的方法。该方法引入一个新的特征度量翻译结果与参考译文的相似性,这个特征可由WER(错误率)、PER(位置独立的WER)或BLEU[24]表示,并在部分训练集上调整特征权重。
4 实验结果和讨论
4.1 实验设置
本文在两个SMT系统上进行评估,这两个系统分别是基于短语的统计机器翻译系统Moses[23]和重新实现的基于森林的树到串系统[25-26],并在两个解码器上实现强制/半强制解码功能。以下是两个系统的实验设置,NIST 2002测试集作为开发集,而NIST 2003和NIST 2005测试集作为测试集。GIZA++[27]和启发式方法“grow-diag-final-and”被用于生成汉英双语词对齐,并在两个系统中采用默认特征。本文利用改良后的Koehn’s MERT训练器[23]作为MERT训练器[28],使用Zhang[29]的实现进行显著性实验,并采用区分大小写的BLEU-4[24]进行翻译质量评估。
对于基于句法的系统,训练数据来源于LDC NIST-MT的子集,包含3万个句对。本文利用SRILM工具[30]和改良后的Knese-Ney平滑方法[31]在训练数据的目标端建立三元语言模型,并在中文CTB5.0上训练Charniak分析器[32],对分析器修改后使其输出封装后的森林。
基于短语的系统,训练数据是24万个汉英句对(21万个FBIS和3万个NIST-MT数据)。本文利用SRILM工具和改良后的Knese-Ney平滑算法,在训练语料和英文Gigaword的新华社语料上,对目标端训练得到四元语言模型。
4.2 规则剪枝的实验结果
为公平比较,本文首先用传统模型的过滤技巧删除部分规则,例如,每个源短语或树保留20个目标翻译,删除非功能词没有被翻译的语法规则等。上述技巧被广泛用于当前系统[23],且被证明不会降低翻译的精确性。
在基于句法的系统中,本文用到的规则剪枝如下:
1) 利用最优维特比算法搜集所有规则来生成一个小规则集。
2) 在小规则集上重新调参和测试

表1 规则剪枝(基于句法的系统)
表1显示本文所用剪枝方法的有效性,可以看出,剪枝后的模型规模由856M减小到30M,缩小856/30=28.5倍(表明减少(856-30)/856=96.5%的冗余规则),且翻译的精确性明显提高(p<0.01)。主要原因是保留重要的规则同时删除大量的不良规则(见表2和表3,主要是局部词汇化规则)。这说明对于基于句法的机器翻译系统,局部词汇化规则没有其他规则重要。由于更大的搜索空间使解码器能够搜索到最优的结果,所以最终导致搜索错误得到了减少。
表2显示规则集中多数为局部词汇化规则,而本文能够将其规模降低约40倍。局部词汇化规则由于具有较细的颗粒度,容易引起过适应问题,从而导致翻译模型的泛化能力变弱。本文所用方法尝试保留具有高度泛化能力的翻译规则,因而倾向于使用具体的词汇信息越少越好。可以看到,通过本文中所提出的剪枝策略,低泛化能力的局部词汇化信息被过滤掉。另外,不同类型的规则的减少率是不同的。这表明本文的方法能够自动检测不同类型的有用规则,并改变最终剪枝模型的分布。
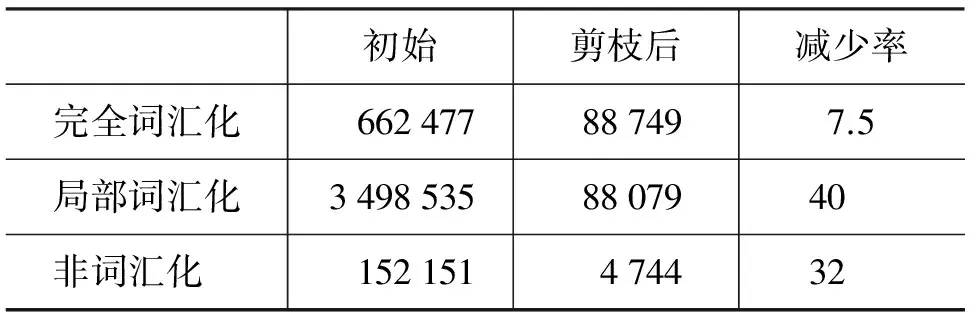
表2 不同类型规则的减少率
表3中,F1K指从训练集中前1 000句的统计信息。由于NIST 03和NIST 05句子数目分别为919和1 082,所以我们用F1K便于公平比较。N03和N05表示在测试集中有用规则的类型分布,可以看出,F1K、N03和N05的分布一致性高。这表明,本文所用方法选择的规则与有用规则具有相同的分布。此外,非词汇化规则只占剪枝规则的2.6%,而在测试集与F1K中的比重超过6%。这是因为非词汇化规则是最泛化的规则,比其他两种类型规则的频率大。随着语料规模的扩大,会出现比非词汇规则更多的词汇化规则,在这种情况下,非词汇化规则的比重趋于减小。可以看到,剪枝后规则类型的比例发生了显著变化,非词汇化规则所占比例在剪枝后上升,但由于颗粒度较粗,仍然只能占很小的一部分比例,占绝大多数比例的翻译规则还是具有词汇化信息的规则,体现了泛化能力和准确性的一种平衡。

表3 规则类型分布
表4为基于短语的SMT规则剪枝的实验结果。可以看出: 1)基于维特比路径的剪枝方法能减少95.7%的翻译规则,同时BLEU值没有降低;2)基于100-best的剪枝方法能减少76%的翻译规则,且显著性提高(p<0.05);3)剪枝方法在基于句法的系统的性能优于基于短语的系统,主要因为基于句法的SMT产生大量的泛化的局部词汇化规则。
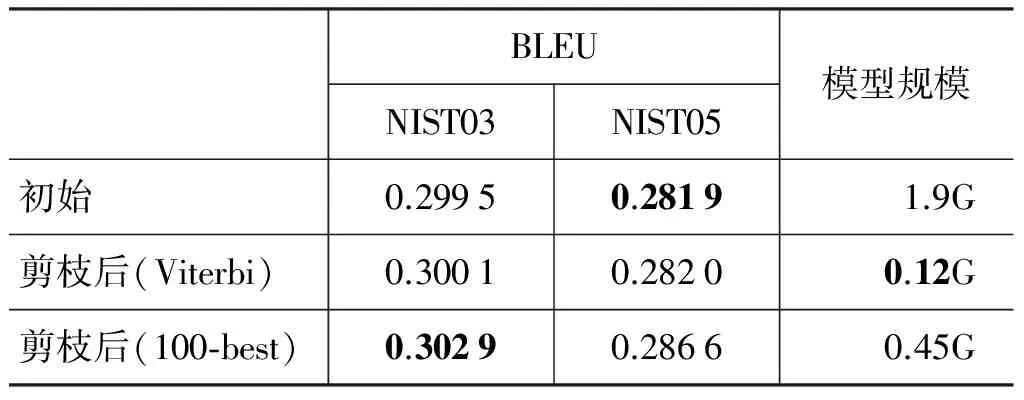
表4 规则剪枝(基于短语的系统)
注: 由于训练数据和语言模型不同,表4中的BLEU值不同于表1中的BLEU值。
相较于基于启发式规则剪枝方法,本文所用方法是基于模型的,实验结果显示对基于句法和基于短语的SMT都很有效。
4.3 模型训练的实验结果
本文在剪枝模型的基础上,使用平均场和半强制解码重新训练模型,主要内容参考3.2和3.3节。实验结果如表5和表6所示。
从表5和表6可以看出,与初始模型与剪枝后的模型相比,重新训练模型后的性能显著提高(p<0.01),且模型规模与剪枝后的模型相差不多。表5和表6是关于剪枝后的模型,其所使用的概率仍为原始启发式方法中的相对频率,概率估计不准确。当重新训练后,模型所使用的概率为从派生路径中统计出的值,保证了统计量和派生路径一致,最终实验结果显示翻译质量也由于概率估计得更加准确而得到显著提升。

表5 重新训练模型(基于句法的系统)

表6 重新训练模型(基于短语的系统)
5 总结和展望
本文提出一个通用框架,该框架通过半强制解码和变分贝叶斯EM对SMT模型进行剪枝和优化。相较于启发式方法和基于EM算法的框架,该方法在翻译模型上的数学理论基础更强。实验结果显示,该框架对模型的剪枝和优化非常有效。以后的工作将致力于建立更完善的翻译系统,从而降低对启发式方法[17]的依赖。
[1] Antoniak C E. Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems[J]. The annals of statistics, 1974: 1152-1174.
[2] Blei D M, Jordan M I. Variational inference for Dirichlet process mixtures[J]. Bayesian analysis, 2006, 1(1): 121-143.
[3] Kurihara K, Welling M, Teh Y W. Collapsed Variational Dirichlet Process Mixture Models[C]Proceedings of the IJCAI, 2007, 7: 2796-2801.
[4] Mark Johnson, Sharon Goldwater. Improving nonparameteric Bayesian inference: experiments on unsupervised word segmentation with adaptor grammars[C]//Proceedings of the HLT-NAACL, 2009: 317-325.
[5] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society. Series B (Methodological), 1977: 1-38.
[6] Gonzalo Iglesias, Adri`a de Gispert, Eduardo R. Banga, et al. Rule filtering by pattern for efficient hierarchical translation[C]Proccedings of the . EACL, 2009.380 388.
[7] Zhongjun He, Yao Meng, YajuanLj, et al. Reducing SMT Rule Table with Monolingual Key Phrase[C]//Proceedings of the ACL-IJCNLP (short paper), 2009: 121-1245.
[8] Katerina T. Frantzi, Sophia Ananiadou. Extracting nested collocations[C]Proceedings of the COLING, 1996: 41 46.
[9] Zhiyang Wang, YajuanLv, Qun Liu et al. Better Filtration and Augmentation for Hierarchical Phrase-Based Translation Rules[C]//Proceedings of the ACL (short paper), 2010: 142-146.
[10] Eck M, Vogel S, Waibel A. Translation model pruning via usage statistics for statistical machine translation[C]//Proceedings of the Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers. Association for Computational Linguistics, 2007: 21-24.
[11] Howard Johnson, Joel Martin, George Foster et al. Improving translation quality by discarding most of the phrasetable[C]Proceedings of the EMNLP-CoNLL, 2007. 967 97
[12] Daniel Marcu, William Wong. A Phrase-based, Joint Probability Model for Statistical Machine Translation[C]//Proceedings of the EMNLP, 2002: 133-139.
[13] DeNero J, Gillick D, Zhang J, et al. Why generative phrase models underperform surface heuristics[C]//Proceedings of the Workshop on Statistical Machine Translation. Association for Computational Linguistics, 2006: 31-38.
[14] Daniel Marcu, W. Wang, A. Echihabi et al. SPMT: Statistical Machine Translation with Syntactified Target Language Phrases[C]//Proceedings of the EMNLP, 2006: 44-52.
[15] May J, Knight K. Syntactic Re-Alignment Models for Machine Translation[C]//Proceedings of the EMNLP-CoNLL, 2007: 360-368.
[16] JoernWuebker, Arne Mauser, Hermann Ney. Training Phrase Translation Models with Leaving-One-Out[C]//Proceedings of the ACL, 2010: 475-484
[17] DeNero J, Bouchard-C t A, Klein D. Sampling alignment structure under a Bayesian translation model[C]. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2008: 314-323.
[18] Blunsom P, Cohn T, Dyer C, et al. A Gibbs sampler for phrasal synchronous grammar induction[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. Association for Computational Linguistics, 2009: 782-790.
[19] Blunsom P, Cohn T, Osborne M. A Discriminative Latent Variable Model for Statistical Machine Translation[C]Proceedings of the ACL. 2008: 200-208.
[20] Blunsom P, Osborne M. Probabilistic inference for machine translation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2008: 215-223.
[21] Trevor Cohn, Phil Blunsom. A Bayesian Model of Syntax-Directed Tree to String Grammar Induction[C]//Proceedings of the EMNLP. 2009. 352-361.
[22] Percy Liang, Dan Klein. Structured Bayesian Nonparametric Models with Variational Inference[C]//Proceedings of the ACL Tutorial.-2007.
[23] Philipp Koehn, H. Hoang, A. Birch, et al. Moses: Open Source Toolkit for Statistical Machine Translation[C]Proceedings of the ACL (poster), 2007: 77-180
[24] Kishore Papineni, Salim Roukos, ToddWard et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the . ACL, 2002. 311-318.
[25] HaitaoMi, Liang Huang, Qun Liu. Forest-based translation[C]//Proceedings of the ACL-HLT, 2008: 192-199.
[26] Zhang H, Zhang M, Li H, et al. Forest-based tree sequence to string translation model[C]//Proceedings of the ACL, 2009: 172-180.
[27] Franz J. Och, Hermann Ney. Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings of the ACL, 2002: 295-302.
[28] Franz J. Och. Minimum error rate training in statistical machine translation[C]//Proceedings of the . ACL、 2003: 160-167
[29] Min Zhang, Hongfei Jiang, Aiti Aw, Haizhou Li, Chew Lim Tan, Sheng Li. A Tree Sequence Alignment-based Tree-to-Tree Translation Model[C]//Proceedings of the ACL-HLT, 2008: 559-567
[30] Andreas Stolcke. SRILM - an extensible language modeling toolkit[C]//Proceedings of the . ICSLP, 2002: 901-904.
[31] Reinhard Kneser, Hermann Ney. Improved backing-off for M-gram language modeling[C]Proceedings of the ICASSP, 1995: 181-184
[32] Charniak E. A maximum-entropy-inspired parser[C]. Proceedings of the 1st North American chapter of the Association for Computational Linguistics conference. Association for Computational Linguistics, 2000: 132-139.
[33] Yang Liu, Qun Liu, Shouxun Lin. Tree-to-String Alignment Template for Statistical Machine Translation[C]//Proceedings of the COLING-ACL, 2006: 609-616.
[34] Agresti, Alan. An introduction to categorical data analysis [M]. New York: Wiley, 1996.
[35] Birch A, Callison-Burch C, Osborne M, et al. Constraining the phrase-based, joint probability statistical translation model[C]//Proceedings of the workshop on statistical machine translation. Association for Computational Linguistics, 2006: 154-157.
[36] Peter F Brown, Stephen A Della Pietra, Vincent J. Della Pietra et al. The mathematics of statistical machine translation: Parameter estimation [J]. Computational Linguistics, 19(2): 263-311
[37] David Chiang. A hierarchical phrase-based model for SMT[C]//Proceedings of the ACL. 2005: 263-270
[38] Nicola Ehling, Richard Zens, Hermann Ney. Minimum bayes risk decoding for BLEU[C]//Proceedings of the ACL. 2007: 101 104.
[39] Jesus-Andres Ferrer, Alfons Juan. A phrase-based hidden semi-markov approach to machine translation[C]//Proceedings of the EAMT. 2009: 132-139.
[40] Ferguson T S. A Bayesian analysis of some nonparametric problems[J]. The annals of statistics, 1973: 209-230.
[41] Michel Galley, Mark Hopkins, Kevin Knight et al. What's in a translation rule?[C]Proceedings of the HLT-NAACL, 2004: 273-280.
[42] Michel Galley, J. Graehl, K. Knight, et al. Scalable Inference and Training of Context-Rich Syntactic Translation Models Proceedings of the COLING-ACL, 2006: 961-968.
[43] Abraham Ittycheriah, Salim Roukos. Direct translation model 2[C]//Proceedings of the HLT-NAACL, 2007: 57 64
[44] Mark Johnson. The DOP estimation is biased and inconsistent[J]. Computational Linguistics, 2002, 28(1): 71-76
[45] Dan Klein, Christopher D. Manning. Accurate Unlexicalized Parsing[C]Proceedings of the ACL, 2003: 423-430.
[46] Philipp Koehn, Franz J. Och, Daniel Marcu. Statistical phrase-based translation[C]Proceedings of the HLT-NAACL, 2003: 127-133
[47] Philipp Koehn. Statistical significance tests for machine translation evaluation[C]Proceedings of the EMNLP, 2004: 388-395
[48] Percy Liang, Alexandre Buchard-Cté, Dan Klein, et al. An End-to-End Discriminative Approach to Machine Translation[C]Proceedings of the COLING-ACL, 2006. 761 768
[49] HaitaoMi, Liang Huang. Forest-based Translation Rule Extraction[C]//Proceedings of the EMNLP, 2008: 206-214
[50] Franz J. Och, Hermann Ney. The alignment template approach to statistical machine translation [J]. Computational Linguistics, 2004, 30(4): 417-449
[51] Franz Josef Och, Daniel Gildea, Sanjeev Khudanpur, et al. A Smorgasbord of Features for Statistical Machine Translation[C]//Proceedings of the . HLT-NAACL, 2004: 161-168.
[52] ChristophTillmann, Tong Zhang. A block bigram prediction model for statistical machine translation[J]. ACM Transactions Speech Language Processing, 2007,4(3): 6.
[53] TaroWatanabe, Jun Suzuki, Hajime Tsukada, et al. Online large-margin training for statistical machine translation[C]//Proceedings of the EMNLP, 2007: 764 773.
[54] Dekai Wu. Stochastic inversion transduction grammars and bilingual parsing of parallel corpora[J]. Computational Linguistics, 1997, 23(3): 377-403
[55] Kenji Yamada, Kevin Knight. A syntax-based statistical translation model[C]//Proceedings of the . ACL, 2001: 523-530
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
数学杂志(2020年3期)2020-07-25 01:39:30
数学物理学报(2019年6期)2020-01-13 06:08:18
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
数学物理学报(2017年6期)2018-01-22 02:26:49
天津诗人(2017年2期)2017-03-16 03:09:39
