
一种用于FTTx网络规划的频繁序列挖掘算法FSM+
2014-02-23 07:06:14宋楚平
重庆邮电大学学报(自然科学版) 2014年2期
宋楚平
(南通纺织职业技术学院,江苏南通 226007)
0 引言
近年来,随着光纤接入(fiber to the x,FTTx)网络技术日趋成熟,以及用户对宽带的更高需求,基于无源光网络(passive optical network,PON)技术的FTTx接入模式和解决方案在国内外得到越来越广泛的应用[1]。在 FTTx网络规划过程中,如何在现有光线路终端 (optical line terminal,OLT)、光纤分布网 (optical distribution network,ODN)和光网络单元 (optical network unit,ONU)数据的基础上,结合城市发展规划和用户对宽带业务需求的发展趋势,提前发现FTTx网络中OLT,ODN,ONU建设规模随城市发展和用户需求的关联关系,挖掘其中规律,识别最佳的未来网络规划路径,成为促进FTTx网络应用的研究热点和挑战。本文提出的频繁序列挖掘算法(命名为FSM+)采用频繁项集扩展序列枚举树,根据频繁序列特征和频繁序列扩展性质,从电信网路规划海量数据中挖掘基于最小支持度的频繁路径,完成对FTTx网络工程数据进行分析和处理,发现网络规划中重要的建设路径,使网络规划更加有序和科学,提高FTTx网络规划的效率。
1 相关性质和理论

近年来随着序列模式挖掘算法的改进和优化,序列模式挖掘在网络规划方面也得到了应用。但现有算法有很多不足之处,如传统FP-Growth算法生成大量的频繁候选项集,并且支持度计算比较繁琐[3]。SPADE算法利用基于格的搜索技术和简单交运算降低了数据库的扫描次数,算法效率有了明显的改善,但仍有大量非频繁项集参与序列的扩展计算,算法的性能和可伸缩性有待改善[4]。也有一些改进算法采用多次对数据库扫描,在候选项集的产生与选择上花费大量的时空代价[5-6],影响了挖掘的效率。因此,如何利用格的方法通过减少对数据库扫描次数以及控制候选项集的产生就成为研究的重点。

2 频繁序列改进算法FSM+
2.1 算法基本思想
FTTx网络规划频繁序列挖掘工作主要分为3个步骤:①构建网络规划路径树;②计算并标记树中各点未来时间的预计总流量和用户选用该点的概率;③基于最小支持度阀值来挖掘频繁序列路径[7]。在数据挖掘前,要经历以下3 个阶段[8]。
1 )数据抽取与预处理:挖掘数据的结构和内容不一致,需进行预处理转换成规范、统一的数据结构,以增强数据分析的通用性。如原来施工时用来表示网络实体拓扑关系的格式为(OLT_Id,Sm Id,time,Persion Id),(OBD_Id,Sm Id,time,PersionId),(ONU_Id,Sm Id,time,Persion Id),现统一将其转化为(OLT_Id,OBD_Id,ONU_Id,time)。
2 )数据清理与压缩:利用同一用户在不同时间网络开通数据的扫描,以及新的建筑群成批网络注册的扫描,可以对数据进行清理和压缩,以尽可能降低数据冗余,加快对数据的处理。
3 )路径确定:将同一 OLT_Id,OBD_Id,ONU_Id依据时间进行排序,就可得到网络部署路径,所有的路径构成了挖掘数据的项目集。
频繁模式是指在时间序列中出现次数大于最小支持度的子序列[9]。分析网络信号从OLT,ODN到ONU所经过的所有流动过程称为路径选择。同一用户的网络接入可以有不同的路径选择。因此,路径选择有经济可比性和施工难易可比性。根据上述频繁序列特征和频繁序列扩展性质,从电信网络规划海量数据中挖掘基于最小支持度的频繁路径。
本算法共有2步。第1步挖掘频繁size(1)-序列,第2步挖掘size(k)-序列。第1步显然可以利用当前有效的频繁项集挖掘方法,如 FP-Growth,FPTree 等进行处理[3,10]。对于 size(k)-序列的挖掘,则采用第1个子任务得到的频繁项集,结合频繁项集序列扩展运算枚举出所有频繁size(k)-序列。整个过程如下。
1 )扫描数据库1次,找出所有频繁项集合F1;
2 )遍历序列节点,进行支持度检查,找出所有的繁项集合FI,亦找到size(1)-频繁序列集合FS;
3 )采用深度优先对频繁size(1)-序列α逐个进行序列扩展,得到候选序列Cs;
4 )对Cs进行支持度检查,若Cs是频繁序列,则放入频繁序列集合FS中;
5 )重复步骤3),4),最后输出FS。
2.2 算法描述
输入:序列数据库D,最小支持度阀值min_sup。

注意,算法FSM+没有进行非频繁项集的扩展,明显减少了无效候选序列的数量。但在枚举过程中,仍产生了一定量的无效序列扩展候选。
3 实验结果与分析
FTTx网络决策与支撑系统数据项多、数据量大,OLT编码、OBD编码、IAD编码、ONU编码、BAN箱编码、用户网络安装信息等采用人工输入,各设备的空间物理位置(posX,posY)采用北京超图Super-Map采集。对网络拓展数据的频繁模式挖掘,可以得出未来某一区域满足最小支持度的频繁路径[11]。以此进行业务用户数量预测和业务量预测,作为最佳网路规划路径的基础,以便合理安排施工计划,降低施工成本,以及为未来用户预留合适的网络容量,支持城市快速信息化发展。为验证FSM+算法的性能,我们用VC++6.0在内存1 GByte,CPU为Pentium(R)Dual2.4 GHz、操作系统为Windows XP的环境下进行了 FSM+算法与经典算法 SPADE,FPGrowth的性能比较测试。利用某电信公司2009至2012年48个月采集的FTTx网络用户装机数据来进行实验。序列的持续时间定为60 min,时间间隔为60~120 min。从48个月的数据中抽取2个数据集 DS1,DS2,如表 1 所示。

表1 实验数据Tab.1 Experimental data
保持2种规格的数据集不变,改变最小支持度min_sup,对比算法 FSM+与 SPADE,FP-Growth 的执行时间,结果如图1、图2所示。
由图1可以看出,本文提出的FSM+算法在数据集较小时,时间性能与SPADE,FP-Growth相比没有明显的效率优势。但在数据集较大时,如图2所示FSM+的时间性能明显提升,为SPADE的5倍多,是FP-Growth的7倍多。其主要原因在于:①FSM+算法产生的候选序列是由频繁项集序列扩展得来的,序列中没有非频繁项集,候选序列数量得到明显缩减。②FSM+采用了位图输入序列压缩存储技术[12],对扩展预算和支持度计算提供了有效的支持,提高了算法的效率。在支持度较小时,FSM+的性能优势更为明显,此时有更多频繁模式输出。而在支持度 min_sup较大时,FSM+与 SPADE,FPGrowth算法的执行效率没有明显的差距,主要原因在于:FSM+算法在计算过程中保留了所有频繁项集的位图,占据了大量的内存空间,这在一定程度上影响了FSM+算法的效率。而SPAM仅存储了频繁项的位图,所需内存空间较少。FP-Growth采用频繁模式树保留项集相关信息,当数据量较大时,算法的I/O代价较大,造成算法效率较低。

图1 在数据集DS1上的时间性能比较Fig.1 Time performance comparison in DS1
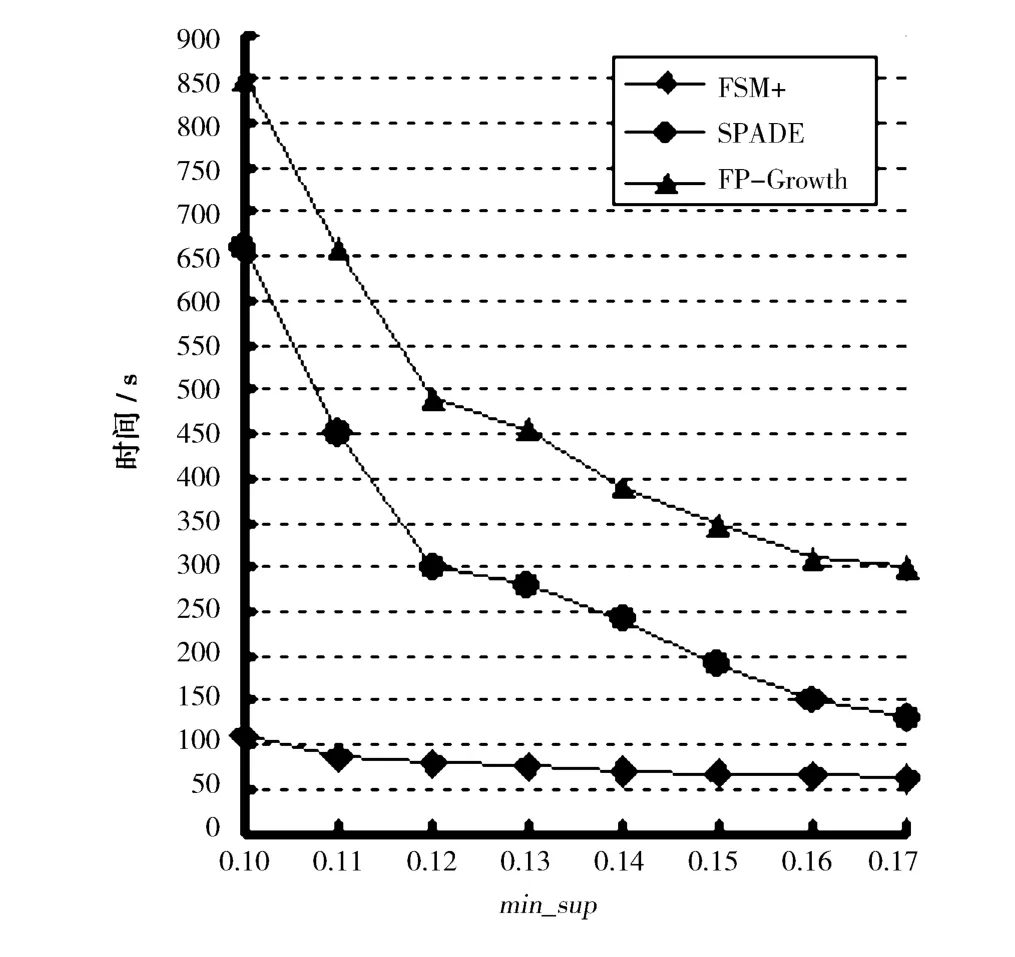
图2 在数据集DS2上的时间性能比较Fig.2 Time performance comparison in DS2
在准确性测试方面,采用历史数据,设定相同最少支持度,分别执行算法 SPADE,FP-Growth和FSM+,其挖掘出的频繁序列均是相同的,验证了FSM+挖掘结果是准确的,该算法是可行的。另外由于FSM+算法具有较高的运行效率,因此在实际应用过程中,可以在较大的最小支持度一定区间范围内,多次计算信任度较高的频繁模式,并与人工经验干预相结合,进一步来保证预测数据准确有效。
4 结语
本文提出的挖掘算法FSM+在某电信公司的FTTx网络决策与支撑系统中得到了实施与应用。FSM+算法是基于对FTTx网络规划行为分析,得到某区域一定时间内FTTx网络用户安装的规律;也就是说,在一定时间序列内找到了一种具有一定可信度的企业共性的网络规划模式。它可以帮助电信等企业分析网络施工的特点,乃至未来网络规划和管理等问题。实验和实践证明,和已有的经典算法SPADE,SPAM等相比,FSM+算法更能有效发现频繁模式,能较为准确预测FTTx网络规划的下一节行为。
为了更全面、更高效地挖掘与利用FTTx网络施工数据,下一步的研究将集中在算法的剪枝策略上,来有效减少候选序列产生的数量,尽可能缩减非频繁序列的枚举,进一步提高算法效率。同时,对序列数据的时间约束进行合理的评估,使FTTx网络施工数据得到更充分的利用。
[1]张海飞,曲豫宾,刘全.GIS技术在FTTx网络接入规划中的应用[J].武汉科技大学学报:自然科学版,2011,34(5):395-397.
ZHANG Haifei,QU Yubin,LIU Quan.Application of GIS technology to FTTx network access planning[J].Journal ofWuhan University of Science and Technology:Natural Science Edition,2011,34(5):395-397.
[2]AGRAWAL R,SRIKANT R.Mining Sequential Patterns[C]//In Proceedings of the Eleventh International Conference on Data Engineering(ICDE 1995).Taipei:IEEE Computer Society Press,1995:3-14.
[3]杨云,罗艳霞.FP-Growth算法的改进[J].计算机工程与设计,2010,31(57):156-158.
YANG Yun,LUO Yanxia.Improved algorithm based on FP-Growth [J].Computer Engineering and Desig,2010,31(57):156-158.
[4]郭平,刘潭仁.基于图结构的候选序列生成算法[J].计算机科学,2004,31(1):136-139.
GUO Ping,LIU Tanren.Graph-Based Candidate Frequent Patterns Generating Algorithm [J].Computer Science,2004,31(1):136-139.
[5]MASSEGLIA F,PONCELET P,TEISSEURE M.Incrementalmining of sequential patterns in large database[J].Data and Knowledge Engineering,2003,46(1):97-121.
[6]LIN M Y,LEE SY.Incremental update on sequential pat-terns in large databases[C]//Proceedings of 10th IEEE International Conference on Tools with Artificial Intelligence.Taipei:IEEE,2001:24-31.
[7]RAJANISH Dass.An efficient algorithm for frequent patternmining for real-time business intelligence analytices in dense datasets[C]//Proceedings of the 39 Annual Hawaii International Conference on System Sciences,HICSS’06.Kauai,HI,United States:Institute of Electrical and Electronics Engineers Computer Society,2006:145-147.
[8]田景红,潘晓弘,王正肖.基于频繁模式挖掘的实时供应链数据分析[J].浙江大学学报:工学版,2009,43(12):261-265.
TIAN Jinghong,PAN Xiaohong,WANG Zhengxiao.Data analysis in real-time supply chain based on frequent patternmining[J].Journal of Zhejiang University:Engineering Science,2009,43(12):261-265.
[9]万里,廖建新,朱晓民.一种时间序列频繁模式挖掘算法在WSAN行为预测中的应用[J].电子与信息学报,2010,32(3):682-686.
WAN Li,LIAO Jianxin,ZHU Xiaomin.Time Series Frequent Pattern Mining Algorithm and its Application to WSAN Behavior Prediction [J].Journal of Electronics&Information Technology,2010,32(3):682-686.
[10]陈晨,鞠时光.基于改进FP-tree的最大频繁项集挖掘算法[J].计算机工程与设计,2008,29(24):6237-6239.
CHEN Chen,JU Shiguang.Algorithm for mining maximal frequent itemset based on improved FP-tree[J].Computer Engineering and Design,2008,29(24):6237-6239.
[11]杨胜琦.基于复杂网络的大规模电信数据分析研究[D].北京:北京邮电大学,2010:52-56.
YANG Shengqi.The analysis and research of large-scale telecom data based on complex network[D].Beijing:Beijing University of Posts and Telecommunications,2010:52-56.
[12]DURDICK D,CALIMLIM M,GEHRKE J.A maximal frequent itemsetalgorithm for transactional database[C]//In Proceedings of 17th international conference on Data Engineering.Taipei:IEEE Computer Society Press,2001:450-452.

(编辑:田海江)
猜你喜欢
甘肃教育(2020年14期)2020-09-11 07:57:42
领导决策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中国卫生(2016年2期)2016-11-12 13:22:16
中国工程咨询(2016年4期)2016-02-14 07:28:28
时代英语·高二(2015年1期)2015-03-16 00:08:11
中国卫生(2014年11期)2014-11-12 13:11:32
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
体育师友(2011年2期)2011-03-20 15:29:29
