
基于Hadoop的小文件分布式存储技术研究
2014-02-11 03:47袁晓春
机电工程技术 2014年12期
袁晓春
(广东电网有限责任公司惠州供电局,广东惠州 516001)
基于Hadoop的小文件分布式存储技术研究
袁晓春
(广东电网有限责任公司惠州供电局,广东惠州 516001)
HDFS(Hadoop Distributed File System)以其高容错性、高伸缩性等优点,允许用户将Hadoop部署在低廉的硬件上,广泛适用于大文件存储。然而对于海量小文件,因为内存开销过高,因此对数据的存储技术提出了更高的要求。基于Hadoop分布式文件系统(HDFS)架构,研究小文件在Hadoop架构下的数据处理策略,通过实验将其与传统的文件系统的读写、计算速度进行比较。
分布式存储;HDFS;MapReduce
0 引言
Hadoop是开源的分布式计算平台,允许用户在低廉的硬件上部署分布式集群,所以用户可以利用Hadoop轻松地组织计算机资源,充分利用计算机集群的计算和存储能力进行海量数据处理[1]。HDFS是由Namenode和Datanode组成的,由于Na⁃menode将文件系统的元数据放置于内存中,所以文件系统所容纳的文件数目会受到Namenode内存大小的限制[2],不能很好地解决海量小文件存储问题(例如现实生活中图片、音乐、日志等比较零散的数据存储,都属于小文件存储)[3-5]。
1 Hadoop小文件分布式系统
小文件是指文件容量小于HDFS的分块(block)大小的文件。HDFS是为大文件存储、读取而开发的,若访问海量小文件则需要在Datanode间不停跳转,影响效率。显然,因为任务启动将耗费大量时间在启动和释放任务上,系统处理海量小文件总和的速度,显著低于同等容量下的大文件处理速度。
针对小文件的解决方案,Hadoop框架提供了几种解决方案,分别为:Hadoop Archive,Se⁃quence file和Combine File Input Format[3]。Hadoop Archive简称HAR,它将多个小文件打包成一个HAR文件,放入块中,以减少Namenode内存使用。HAR也有缺陷,创建后Archives便不可更改,要增加或删除其中文件必须重新创建。Se⁃quence files是由二进制的(Key,Value)对组成的,定义键Key为小文件名,值Value为文件内容,将海量小文件合并成大文件,并实现快速查找。Combine File Input Format是则定义了一种新的数据格式,可以将多个文件合并成一个单独的分块[3]。
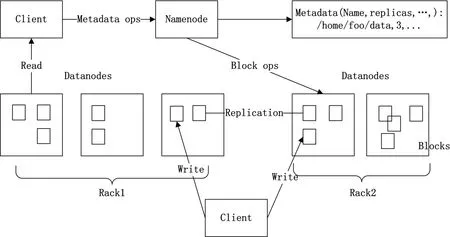
图1 HDFS架构
2 小文件分布式文件系统优化
2.1 HDFS系统框架
如图1所示,HDFS是一个分布式文件系统的超级大集群。该系统有一个以上的公共节点和两个服务器,这可同时用作服务器是HDFS文件系统和MapReduce名称服务器计算平台作业调度器(JobTracker),不仅是作为HDFS文件系统的数据节点的其余节点(Datanode),而且还作为一个计算平台的MapReduce任务执行(Task Tracker)。将大规模的网络数据变成“本地处理”,大大提高海量数据处理速度,实现高效率计算。存储在HDFS大量存在于一个块的形式的文件,在相同块中的文件的大小,用不同的块大小的文件的其他文件只有最后一个块。对于容错,属于文件块需要复制保存。复制该文件的大小的块的数目,并可以为每个文件设定。HDFS符合一次编写原则,同一时刻只允许单个用户写入。Namenode节点负责文件块复制管理,将各Na⁃menode节点块复制的日志反馈,根据日志判断复制目标块。
HDFS与其他分布式文件系统功能不同的是其性能和相关数据块副本的位置选择比较大的可靠性。HDFS使用感知机制(rack-aware)策略以提高数据可用性和利用网络带宽的可靠性。一般在大型计算机集群系统运行的HDFS实例,不同的服务器集群可以跨机柜部署,相异节点之间通过交换机相互连通。通常相同机柜比不同机柜节点之间的通信速度更快,因为机柜内失效的概率比机器故障的概率小得多,这样部署可以在不降低数据的可靠性和可用性的条件下,有效降低机柜内的写入流量,大大提高写入性能。
在启动时不发生文件块的复制称为Namenode节点安全模式。每个数据块记录副本的某个最小数值,当Namenode的节点发现数据库有多个副本的最小数值时,说明副本已被安全复制。Nameno⁃de节点则自动退出安全模式的条件是有足够的块来完成副本复制。
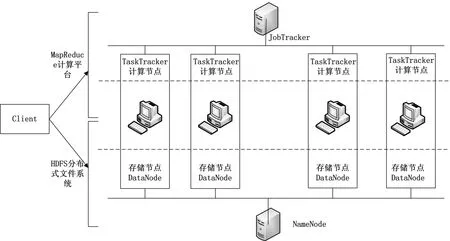
图2 基于Hadoop的文件系统计算框架
基于Hadoop的文件系统计算框架如图2所示。
文献[4]针对WebGIS数据,将相邻的小文件合并为大文件,并对所有小文件建立全局哈希索引,有效提高小文件的存取效率。文献[5]针对BlueSky系统中的文档文件,将同类PPT小文件合并成为一个大文件,并对每个大文件建立局部索引,以上两种方法充分利用了计算机缓存机制,提高了小文件的存取效率,是目前比较适用的小文件存储方法。
2.2 小文件处理方法在HDFS框架下的实现
本节试图在系统层面解决HDFS小文件存储,存储流程如图3所示。
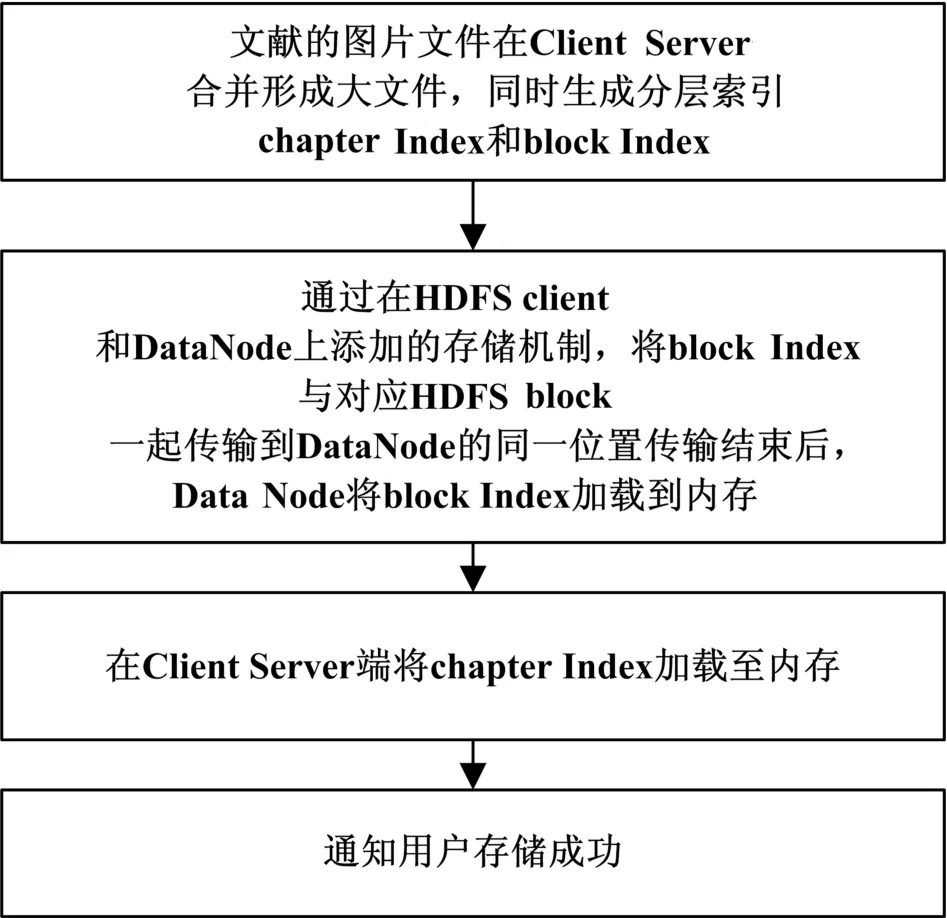
图3 基于Hadoop的小文件系统存储流程
读取流程如图4所示。
3 实验与数据
3.1 实验目的
根据本文设计的框架设计相关的实验来验证本文设计框架的可操作性。实验数据被分成两组,一组是采用传统的分布式计算方案,使用Shell脚本处理日志,另一组为使用本文设计的系统框架运行分布式算法进行计算。
3.2 实验环境的配置
实验建立四个服务器的Hadoop集群,一台做Namenode,三台做Datanode,客户端通过Na⁃menode提交数据。所述网络服务器内用于内网系统的24 G实验数据记录,由10万个200~250 kB的日志记录组成。表1是一个具体的机器实验室环境。
3.3 实验结果分析
图5和图6是传统HDFS MapReduce工作和小文件框架下统计计算的对比,从中可以清楚地看到,小文件框架工作运行时间比传统HDFS运行时间显著缩短。在内存方面传统HDFS则明显耗费了大量的内存。
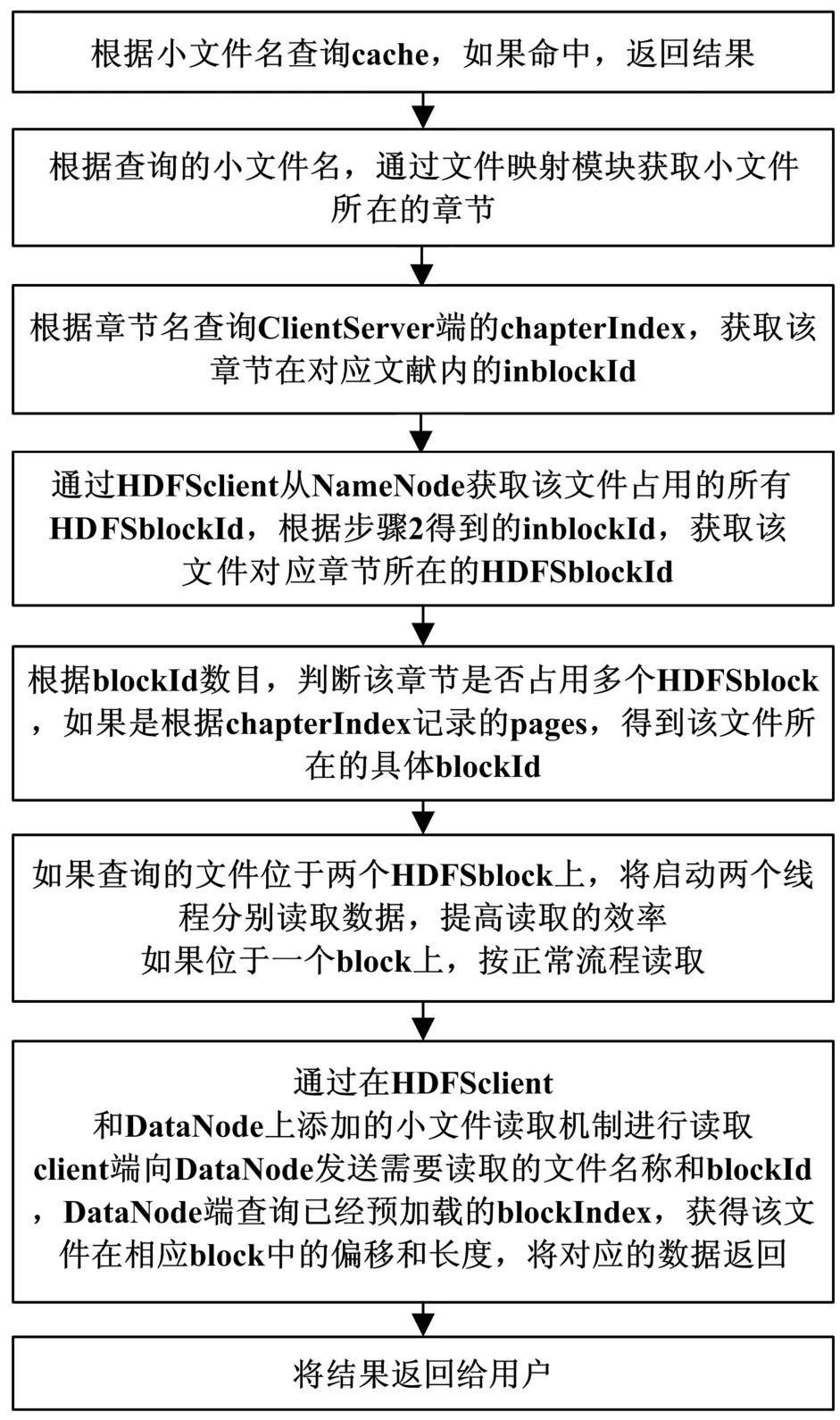
图4 基于Hadoop的小文件系统读取流程
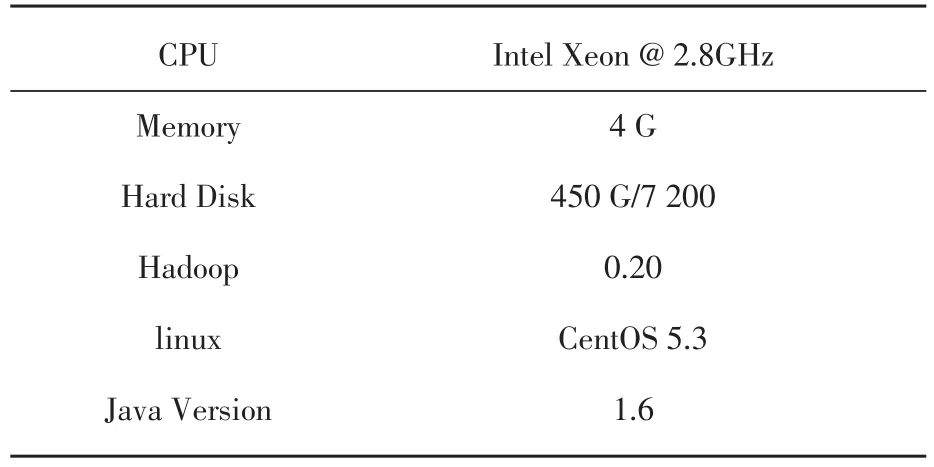
表1 集群服务器配置信息
4 总结
Hadoop中目前还没有通用的解决HDFS小文件问题的解决框架,现有的框架包括Hadoop Ar⁃chive,Sequence file和Combine File Input Format,需要用户按需自定义程序逻辑,比较繁琐,本文在对Hadoop集群架构研究的基础上,给出了一个基于Hadoop的小文件分布式存储方法。实验结果表明,该平台可以大大提高小文件在HDFS框架下的读写速度。
Research on Storage of Hadoop Distributed Small File System
YUAN Xiao-chun
(Huizhou Power Supply Bureau,Huiizhou516001,China)
HDFS(Hadoop Distributed File System)for its high fault tolerance,high scalability,etc.,allows the user to deploy Hadoop inexpensive hardware,is widely used in large file storage.However,for the mass of small files,because the memory overhead is too high,so the data storage technology put forward higher requirements.Based on Hadoop distributed file system(HDFS)architecture,small file data processing policy in the Hadoop framework,by comparing the read and write test with the traditional file system,the calculation speed.
distributed storage;HDFS;MapReduce
TM73
:A
:1009-9492(2014)12-0159-03
10.3969/j.issn.1009-9492.2014.12.040
2014-11-14
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
仪器仪表用户(2021年10期)2021-11-27
铁道通信信号(2020年9期)2020-02-06
军事运筹与系统工程(2019年4期)2019-09-11
当代陕西(2019年14期)2019-08-26
电子制作(2018年11期)2018-08-04
电子测试(2017年12期)2017-12-18
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
中学数学杂志(初中版)(2016年5期)2016-11-01
