
基于内容的Hadoop/MapReduce架构图像检索方法
2014-02-06 06:53蔡丽娟
福建开放大学学报 2014年5期
蔡丽娟
(福建广播电视大学漳州分校,福建漳州,363000)
基于内容的Hadoop/MapReduce架构图像检索方法
蔡丽娟
(福建广播电视大学漳州分校,福建漳州,363000)
运用Hadoop/MapReduce并行海量图像处理框架进行基于内容的海量图像检索,将海量图像数据分布式存储在众多节点上,运用优化的ACCC算法在各节点上进行基于内容的图像搜索分析算法一体化处理,通过与传统并行计算方法和单节点方法试验对比,演示本方法在存储能力和计算检索效能的优势。
Hadoop/MapReduce;并行处理;图像处理
基于内容的图像检索(CBIR)方法几十年来一直是海量图像检索与分析的研究热点,但由于海量图片数据量巨大,对计算能力要求极高,因此尚不能达到实时处理的能力,无法实现实际应用。[1]目前大多数的CBIR研究论文往往集中在研究算法的改进和局部应用实验方面上,如一种基于内容的联合查询图像检索系统已被提出,[2][3]用于实现图像查询和相关特征反馈,该系统虽然在准确性方面性能表现突出,但在处理海量图片数据时,单机基于多线程的架构无法满足实时要求,在效率方面不能令人满意。许多研究人员也试图通过使用分布式计算解决这个问题[4][5](例如利用集群计算),如陆永泉等人[6]提出了一种并行计算方法进行图像特征提取,并设计了基于集群架构的图像特征相似性比较方案。实验表明,该集群很好地提高了检索性能,但始终没有很好的解决系统高效存储和负载均衡的问题。
随着大数据Hadoop系统和MapReduce计算架构的出现,为海量图像高效存储和实时处理提供了可能。本文在Hadoop/MapReduce并行图像处理框架基础上,提出了一种有效的颜色特征提取方法——自动颜色相关图算法Auto Color Correlogram and Correlation(ACCC),[7]用于提取图像低级特征,该方法与MapReduce计算架构有效结合到一起,显著提高了下检索不同来源图像相似性的能力。[8][9]
一、Hadoop/MapReduce架构
Hadoop采用开放式源代码框架,[1]具备大型数据处理能力,其中的MapReduce分布式模型实现了资源虚拟化管理、调度和共享,是当今应用最为广泛的开源大数据编程平台。
为了简化系统,HDFS集群中只部署一个NameNode(选择相对性能较好的计算机),其余节点各运行一个DataNode。当然,NameNode节点性能足够好,也可在该机上部署一个或多个DataNode。同理,同一物理机上的DataNode数量是没有规定的,只要计算机的存储能力能够满足要求。
如图1所示,HDFS采取的是主从架构,每个HDFS集群均有一个NameNode和多个DataN原ode。其中,NameNode为主服务器,负责管理HDFS系统,接受客户端请求;DataNode是从服务器,作用为存储数据;HDFS将一个文件分割成多个块,这些块可存储在一个或多个DataN原ode上。同时,采用HBase存储半结构化和非结构化的松散数据,提供高列存储、高性能、可伸缩、可靠的实时读写服务。
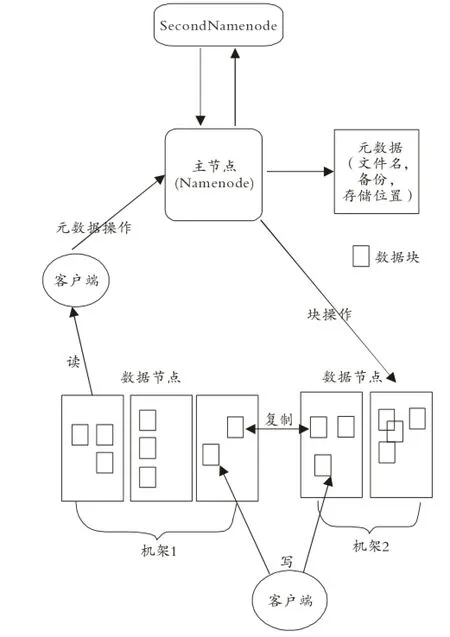
图1 HDFS体系架构
MapReduce是Hadoop架构的基础计算模型,其将输入海量图像数据划分为大小确定数据块(默认64MB)进行处理的过程,过程称为MapReduce的“映射与归约”。这种分布式并行映射任务的实现方法,意味着每一数据块处理时间相对于整个海量数据任务处理时间会大幅度缩短。且分区处理数据少并且性能高的设备,可以处理更多数据块,因此参加并行计算的每个分区负载会更加平衡。对于大量性能相近的计算硬件设备,只要任务分区合理,负载平衡能力可取得令人满意的效果。但数据块过小,分区管理和创建映射任务开销占总任务开销的比例会增大。对于大多数的进程,合适的分区大小取决于分布式文件系统数据块的大小,这可以通过集群技术(对所有刚被创建的文件)或文件创建时指定方法加以解决。
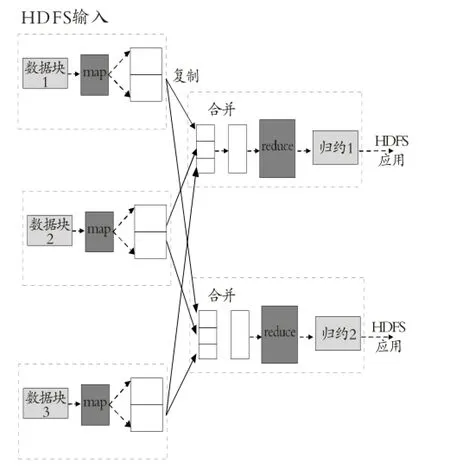
图2 MapReduce的映射与归约
MapReduce程序主要在“映射Map”和“归约Reduce”这两个阶段执行,每个阶段由数据处理函数定义,这些函数分别称为“映射函数”和“归约函数”。在映射阶段,MapReduce接受输入数据并且将每个数据元素发射到“映射器”;在归约阶段,归约函数处理所有来自映射器的数据,映射归约任务流程如图2所示,方格表示节点,虚线箭头表示数据的逻辑映射与归约,实线箭头表示节点间的实际数据传输。可以看出,海量图像数据块被映射为多个单元,计算完成后规约为统一结果输出,且在多重映射过程中,每一次映射信息记录均独立保存。
二、基于内容的图像检索系统的MapReduce框架
本文采取MapReduce方法对海量图片进行并行检索处理,映射函数的输出值在输入到归约函数之前,需经过MapReduce进行处理,这一过程是通过一系列关键词对键值的分类和组合完成的。所有的归约函数必须循环通过每个HDFS文件进行图像整理和分类。图3展示了MapReduce是在CBIR整个系统实现原理。首先,将海量图像文件通过映射分割成若干HDFS分区文件,实现了再HDFS的分布式存储;其次,通过映射与规约计算机制提取其图像特征;最后,实现图片特征向量相似性匹配并输出结果。可以看出,Hadoop/MapReduce系统通过“节点”来访问图像数据。MapReduce把输入的数据拆分成独立的数据块,并且这些并且并行实现数据块的数据处理及算,最后把输出结果归类后给Reduce规约输出。输入和输出过程都存储在一个文件系统里(HDFS文件),Hadoop/ MapReduce框架保管调度任务,监测并再次执行失败了的任务。
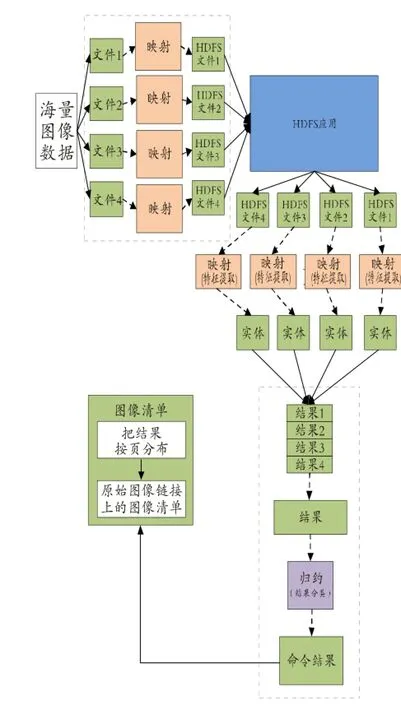
图3 基于内容的图像检索系统的MapReduce框架
三、图像的特征计算
本文上节提出了MapReduce架构用以高效处理海量图像数据,但要得到更好的系统效能,我们依然需关注CBIR系统自身图片特征提取方法,也就是如何提高提取图像颜色特征可靠性和实时性的问题。基于此,我们将颜色索引技术的自相关函数(ACC)[10]扩展,提出了一种新的图像特征提取自动颜色相关图算法(ACCC)。其中的自相关函数描述了如何求取像素cj和其相距为k-th的任意像素的计算平均颜色值。通常,图像I(x,y),x=1,2,…,M;y=1,2,……,N的ACC可定义为:
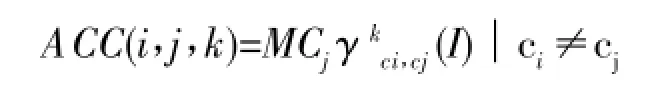
在这里,原始图像I(x,y)可被量化为颜色特征C1,C2,…Cj等,任意两个像素间的距离且属固定值(例如图片的长度和宽度),那么MCj可表示在图像I(x,y)中从像素Cj到像素Ci距离为k的图像颜色特征,计算方法如下:
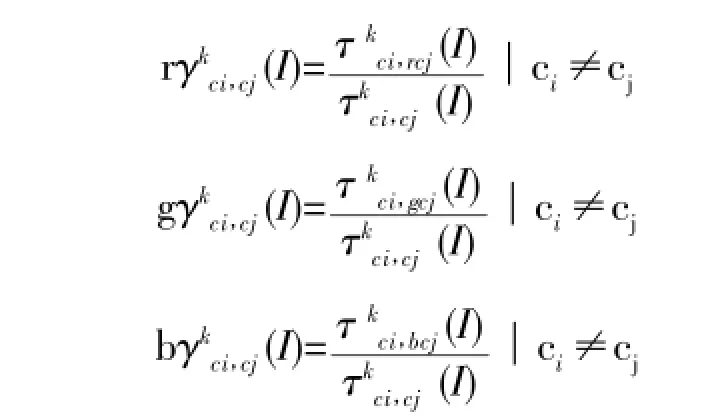
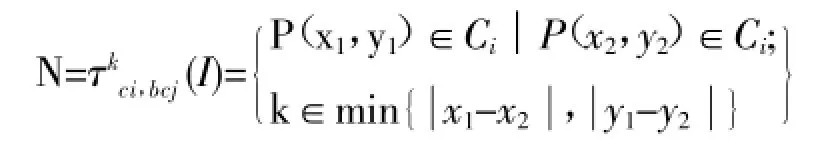
我们提出方法,实在基于自相关函数的上扩展的自关联技术(ACCC),它是将自相关函数和自动颜色关联技术进行的整合。由此,AC原CC可定义为:
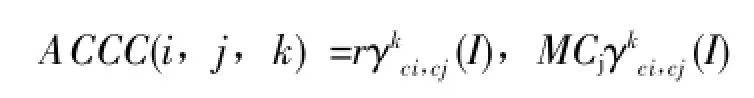
根据以上原理,ACCC的伪代码科表示为:
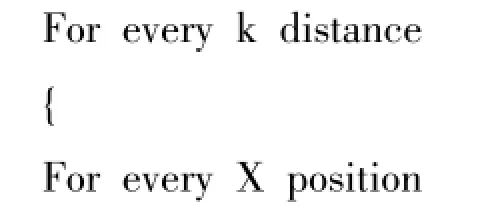

图像检索根据特征相似度矩阵来进行度量,在个颜色特征范围内,使得ACCC成对的出现在和里。图像相似性可用AC和ACC之间的距离度量,[11]如下式所示:
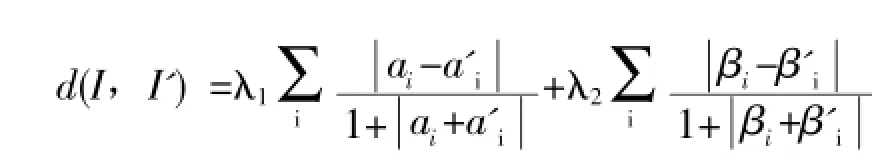
式中姿1和姿2在函数自相关和颜色关联的加权常量。根据实验经验,可得姿1=0.5和姿2=0.5。ai和βi定义如下:
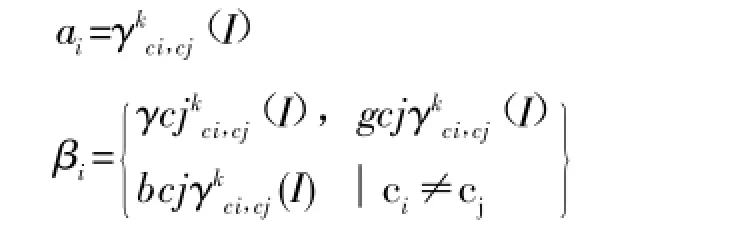
四、性能对比实验
(一)存储性能对比
在硬件设备性能基本一致的前提下,采用本文提出的Hadoop/MapReduce并行ACCC图像处理框架,与传统并行集群系统及B/S单点检索系统进行实验对比,在处理图像数量不同、节点不同情况下,图像存储时间如图4所示。可以看出,当数据达到一定数量时,本文方法图像存储时间更短,使得整体性能得以提高。
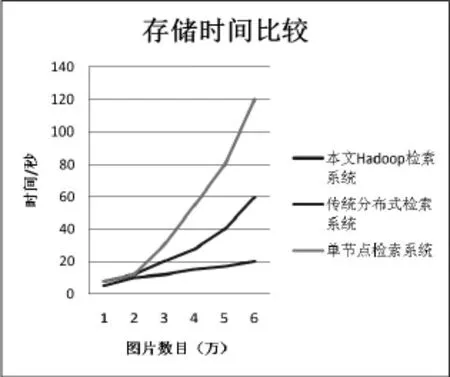
图4 三种系统的图像存储时间对比
(二)检索效率对比
对不同规模的图像库进行试验,图像检索耗时如图5所示。可以看出,由于Map砸educe的并行计算优势,节点越多,检索速度越快,增加节点数,可以提高图像检索系统性能。
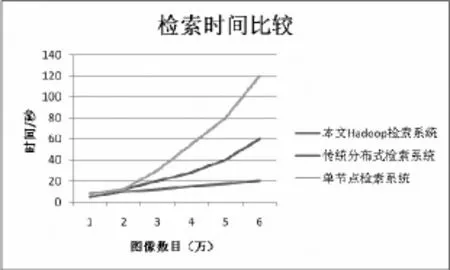
图5 三种系统的图像检索效率对比
结论
文章表述了一种使用Hadoop/MapReduce方法进行基于内容的图像检索的框架,并基于CBIR提出了ACCC算法,用于减少特征计算的运行时间。仿真测试结果表明,Hadoop/MapRe原duce图像检索系统提高了图像存储和检索效率,获得较优的检索结果。未来的工作重点是提高Map任务与砸educe任务之间数据传输速度,减少更多由于传输信息所产生的时间消耗,进一步提高现有图像检索系统的执行效率。
[1]Anucha,T.&P.Wichian.On-line Content-Based Image Retrieval System using Joint Querying and Relevance Feedback Scheme[J].WSEAS Transaction on Computers,2010,(5):26-38.
[2]Change,E.Y.Content-based soft annotation for multimodal image retrieval using Bayes point machines[J].IEEE Transactions on Circuits and Systems for Video Technology,2003,(1):26-38.
[3]Cohn,D.The missing link-a probabilistic model of document content and hypertext connectivity[J].Advances in Neu鄄ral Information Processing Systems,2001,(5):25-31.
[4]Kao,O.Scheduling aspects for image retrieval in cluster-based image databases[C].IEEE/ACM Cluster Computing and the Grid.Urbana:University of Illinois Press,2001:329-336.
[5]Ling,Y.Image Semantic Information Retrieval Based on Parallel Computing[C].International Conference on Com鄄puter Vision.New York:Cambridge University Press,2008:255-259.
[6]Gonzalez,R.C.Digital Image Processing[M].London:Prentice-Hall,2009:135-127.
[7]Anucha,T.Spatial Color Indexing using ACC Algorithms[C].International Conference on Computer Vision.Urbana: University of Illinois Press,2009:113-117.
[8]Newman,D.Distributed Inference for Latent Dirichlet Allocation[C].Neural Information Processing Systems(NIPS). Urbana:University of Illinois Press,2008:1081-1088.
[9]Tong,S.Support Vector Machine active learning for image retrieval[C].ACM international conference on Multimedi鄄a.New York:Cambridge University Press,2001:107-118.
[10]Anucha,T.Spatial Color Indexing using ACC Algorithms[C].IEEE Transactions on Circuits and Systems for Video Technology.New York:Cambridge University Press,2009:113-117.
[11]Lee,Y.H&K.H.Lee.Spatial Color Descriptor for Image Retrieval and Video Segmentation[J].IEEE Transaction on Multimedia,2003,(3):358-367.
[责任编辑:陈晓蔚]
TP3911.41
A
1008-7346(2014)05-0041-09
2014-08-30
蔡丽娟,女,福建石狮人,福建广播电视大学漳州分校讲师。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年14期)2019-08-26
意林图解作文(小学版)(2019年6期)2019-07-16
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
中学数学杂志(初中版)(2016年5期)2016-11-01
专利代理(2016年1期)2016-05-17
测绘科学与工程(2014年2期)2014-02-27
