
基于MapReduce数字图像处理研究
2014-01-16 05:58田进华张韧志
电子设计工程 2014年15期
田进华,张韧志
(黄淮学院 河南 驻马店 463000)
以互联网为计算平台的云计算,将会涉及非常多的海量数据处理任务[1],海量数据处理是指对大规模数据的计算和分析,通常数据规模可以达到TB甚至PB级别。当今世界最流行的海量数据处理可以说是MapReduce编程模式。MapReduce分布式编程模型允许用户在不了解分布式系统底层实现细节的情况下开发并行应用程序。用户可以利用Hadoop轻松地组织计算机资源,进而搭建自己的分布式计算云平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
1 Map Reduce计算模型
Hadoop是一个开源分布式计算平台。以分布式文件系统HDFS和MapReduce为核心的分布式计算和分布式存储的编程环境[2]。MapReduce是用于大规模数据集分布式的计算模型,实现一个MapReduce应用,首先,通过Map程序将数据切割成小块,然后,分配给大量服务器处理,最后,通过Reduce程序将处理后的结果汇整输出给客户端。MapReduce的整个架构是由Map和Reduce函数组成,当程序输入一大组Key/Value键值对时,Map负责根据输入的Key/Value(键值)对,生成中间结果,这生成中间结果同样采用Key/Value(键值)对的形式。开发者只需要实现Map和Reduce函数的逻辑,然后提交给MapReduce运行环境,计算任务便会在大量计算机组成的集群上被自动、并行地调度执行。MapReduce的运行环境是有两个不同类型的节点组成:Master和Worker。Worker负责数据处理,Master主要负责任务分配和节点之间数据共享。需要实现或指定以下编程接口:
Map 函数:接收输入的键值对<kl,vl>,计算生成一组中间的键值对<k2,v2>
Reduce函数:接收键值对集合<k2,v2的列表>,聚集计算得到新键值对<k3,v3>。
Combiner函数:它是对Map函数输出的中间数据在本地执行归并,将处理结果再传输给Reduce节点。Combiner可以降低Map任务节点和Reduce任务节点之间的通信代价。
InputFormat,OutputFormat:InputFormat 支 持 Hadoop 作业输入数据键值对的转换;OutputFormat表示Hadoop作业计算结果存储在HDFS中的格式。
Partitioner函数:用于对Map函数输出的中间结果进行划分,Map任务点根据所提供的Partition函数,将数据结果划分给相应Reduce任务节点。
Hadoop运行MapReduce作业的流程图如图1所示。MapReduce作业包含四个相对独立的模块。客户端主要负责MapReduce作业代码的编写,配置作业相关参数,向JobClient实体提交作业;JobTracker节点主要负责用户提交作业的初始化,调度作业,与所有的TaskTracker节点进行通信,协调用户提交作业的执行;TaskTracker节点负责自主与JobTracker节点进行通信,根据所分配的数据块执行Map或Reduce任务,调用用户定义的Map或Reduce函数;HDFS负责保存作业的数据、配置信息和作业结果等。
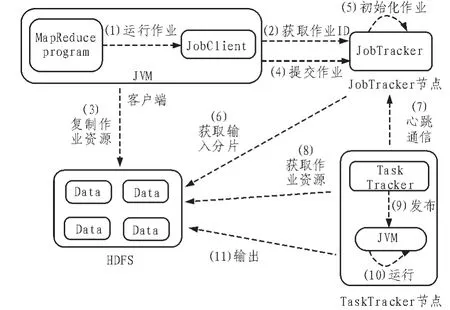
图1 Hadoop运行MapReduce作业流程图Fig.1 MapReduce job’s flow chart on Hadoop
2 构建图像处理云平台
在MapReduce计算框架中,Hadoop将输入数据划分成等长的作业分片,每个Map任务处理一个作业分片,这些Map任务是并行执行的[3]。Hadoop又将每个作业分片划分为多个相同的键值对,每个Map任务对该分片中每个键值对再调用map函数来进行处理。本系统把一个图像文件作为一个作业分片,再把整个作业分片作为一个键值对来处理[4]。这样每个Map任务只需调用一次map函数来处理一个图像文件,进而实现多个图像文件的并行化处理。本系统只定义了一个Reduce任务,其调用reduce函数对每个键值对进行简单的输出操作。
1)键值对类型的设计
Hadoop中map和reduce函数的输入和输出是键/值对(Key/Valuepair),MapReduce框架并不允许任意的类作为键和值的类型,只有支持序列化的类才能够在这个框架中充当键或者值[5]。Hadoop有自己的序列化格式 Writable,实现Writable接口的类可以作为值类型。Writable接口定义了两个方法:一个将其状态写到DataOutput二进制流,另一个从DataInput二进制流读取其状态[6]。实现WritableComparable<T>接口的类既可以作为键类型也可以作为值类型,该接口继承自Writable和java.lang.Comparable接口。
WritableComparator是对继承自WritableComparable类的RawComparator类的一个通用实现,提供了两个主要功能:第一,对原始compare()方法的默认实现,能反序列化将在流中进行比较的对象,并调用对象的compare()方法;第二,充当的是RawComparator实例的工厂。Hadoop自带的org.apache.hadoop.io包中有广泛的Writable类,它们形成了如图2所示的层次结构。

图2 Writable类层次结构图Fig.2 Writable class's hierarchical structure
本系统使用的键类型为Text,用来存储图像文件的名;值类型为Image,实现了Writable接口,用来存储图像文件的内容。本系统的键值对在Map任务和Reduce任务数据变化流程如图3所示。任务调用map函数对每个键值对进行处理,处理前后键Filename的内容不会发生改变,而存储图像信息的值Image的内容会发生变化。Reduce任务调用reduce函数实现对其输入的键值对进行简单的键值对输出操作。
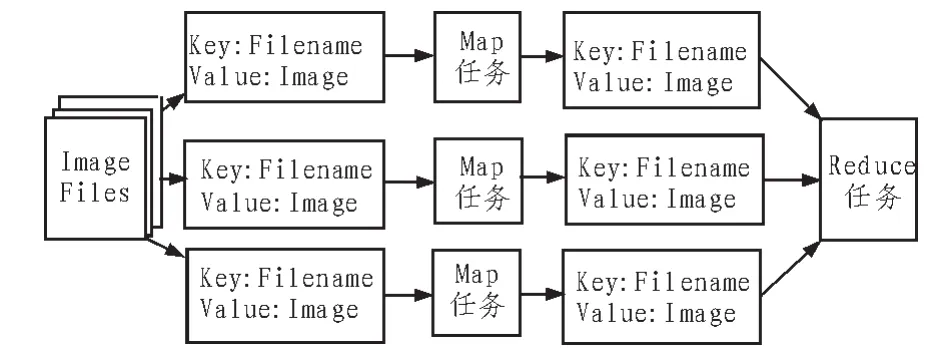
图3 本系统Map任务和Reduce任务数据流Fig.3 Map task and reduce task’s data flow in this system Map
2)作业的输入格式设计
一个输入分片(split)就是由单个Map任务处理的输入块,每个分片被划分为若干个记录,每条记录就是一个键值对,map函数一个接一个处理每条记录。map函数用该实现从InputSplit中读取输入的键值对。本系统设计了ImageFileInputFormat类继承自 FileInputFormat<Text,Image>类的实现,把一个图像文件作为一个输入分片,不进行文件分 割 ;ImageRecordReader 类 继 承 自 RecordReader<Text,Image>类的实现,把输入分片转化为一个键值对,即图像文件名作为键Text类型的一个实例,图像文件内容作为值Image类型的一个实例。ImageRecordReader类实现解码读取存储在HDFS上作为输入分片的图像文件,获得其字节流,然后将字节流转化为上一节实现的值类型Image的一个实例,图像文件的名字作为键类型Text的一个实例,其核心代码如下:
FileSplit split=(FileSplit)genericSplit;
Configuration conf=context.getConfiguration();
Path file=split.getPath();
FileSystem fs=file.getFileSystem(conf);
FSDataInputStream fileIn=fs.open(split.getPath());
byte[]b=new byte[fileIn.available()];
fileIn.readFully(b);
image=new Image (cvDecodeImage (cvMat (1, b.length,CV_8UC1,
new BytePointer(b)),iscolor));
fileName=split.getPath().getName().toString();
3)作业的输出格式设计
MapReduce作业的输出样式用OutputFormat描述。根据OutputFormat,MapReduce框架检验作业的输出;看作业初始化的配置与验证输出结果类型是否一致;通过RecordWriter用来输出作业的结果,输出文件保存在Hadoop的文件系统上。要定义OutputFormat抽象类。FileOutputFormat是所有使用文件作为其数据源的OutputFormat实现的基类。系统设计了 ImageOutputFormat 类 继 承 自 FileOutputFormat<Text,Image>类的实现,把一个键值对作为内容进行输出;ImageRecordWriter类继承自 RecordWriter<Text,Image>类的实现,把键Text类型的实例作为图像文件名,值Image类型的实例作为图像文件内容,生成一个图像文件存入Hadoop文件系统中。ImageRecordWriter类实现编码值类型Image的一个实例,作为图像文件内容的字节流,根据作业初始化的输出目录,再结合值类型FileName的一个实例,作为图像文件的文件名,生成图像文件,存储在分布式文件系统HDFS中。
4)图像处理功能
网上的数字图像一般是一个大的二维数组,该数组的元素称为像素,其值为一整数,称为灰度值。图像处理就是利用计算机对数字图像的灰度值信息进行处理,从中提取有用的信息或得到某种预期的效果。数字图像处理的过程:首先是获取图像,对数字图像缩放处理和图像增强处理,图像缩放常用的插值方法有最近邻插值、双线性插值、使用象素关系重采样和立方插值。本文使用双线性插值算法来实现在map函数中对图像进行0.5倍的缩放。然后进行图像复原和彩色图像处理,利用小波与多分辨率对图像处理,将一幅图像分割成小的图像,最后进行特征提取和目标识别。
对数字图像的边缘检测是进行图像分割、目标区域识别、区域形状提取等图像分析的技术基础。对于连续图像f(x,y),边缘检测就是求梯度的局部最大值和方向。利用Canny边缘检测算子,在map函数中实现对图像的边缘检测,从而实现对图像文件的并行化边缘检测。边缘检测步骤如下:
首先用2D高斯滤波模板与原始图像进行卷积,以消除噪声。其次利用导数算子,找到图像灰度沿着两个方向的导数GxGy,并求出梯度大小。 然后利用2)的结果求出了边缘的方向,就可以把边缘的梯度方向大致分为 4 种(0°、45°、90°、135°),并可以找到这个像素梯度方向的邻接像素。接着遍历图像。若某个像素的灰度值与其梯度方向上前后两个像素的灰度值相比不是最大的,那么将这个像素值置为0,即不是边缘。最后使用累计直方图计算两个阈值。凡是大于高阈值的一定是边缘;凡是小于低阈值的一定不是边缘。如果检测结果在两个阈值之间,则根据这个像素的邻接像素中有没有超过高阈值的边缘像素,如果有,则它就是边缘,否则不是。
5)MapReduce程序的编写
为了使用 Hadoop中MapReduce来进行海量图像数据挖掘,需要编写 MapReduce程序。目前大多数 MapReduce程序的编写都可依赖于一个模板及其变种。当撰写一个新的MapReduce程序时,通常会采用一个现有的MapReduce程序,并将其修改为所希望的样子。编写 MapReduce程序的第一步就是要了解数据流,设计所需的键值对类型。Hadoop自身只提供处理简单数字或字符的键值对类型,根据实际的需要设计相应的类型。例如本文第四章,设计了名为Image的值类型,而键类型采用 Hadoop自带的Text类型。MapReduce程序由三部分组成,分别是用户定义的 map函数、用户定义的 reduce函数和作业驱动程序;map函数在Map任务执行时被调用,reduce函数在 Reduce任务执行时被调用,作业驱动程序用于初始化作业的配置。
3 结束语
Hadoop[7]云平台的图像处理系统设计,把一个图像文件作为一个作业分片,再把整个作业分片作为一个键值对来处理。这样每个Map任务只需调用一次map函数来处理一个图像文件,进而实现多个图像文件的并行化处理。节点可以自由地扩充,通过键值对的设计、作业的输入与输出格式的设计,可以实现海量图像文件信息的并行化处理。整个云平台提供的计算和存储能力近乎是无限的。随着图像文件量的增加,MapReduce处理数据的最佳速度最好与数据在云平台中的传输速度相同,系统的利用率会有随之提高。
[1]刘鹏.云计算[M].2版.北京:电子工业出版社,2011.
[2]朱义明.基于Hadoop平台的图像分类[J].西南科技大学学报,2011(2):70-73.ZHUYi-ming.Imageclassification based on hadoop platform[J].Journal of Southwest University of Science and Technology,2011(2):70-73.
[3]CHUCK LAM.Hadoop in action[M].Manning,2010
[4]TOM WHITE.Hadoop the definitive guide[M].O'Reilly|Yahoo!PRESS,2009.
[5]崔朝国,刘志明,李婧,等.一种基于Hadoop的Scool云存储平台[J].电脑知识与技术,2013(2):405-408,411.CUI Chao-guo,LIU Zhi-ming,LI Jing,et al.A scool cloud storage platform based on the hadoop[J].Computer Knowledge and Technology,2013(2):405-408,411.
[6]多雪松,张晶,高强.基于Hadoop的海量数据管理系统[J].微计算机信息,2010(13):202-204.DUO Xue-song,ZHANG Jing,GAO Qiang.A mass data management system based on the hadoop[J].Microcomputer Information,2010(13):202-204.
[7]赵庆.基于Hadoop平台下的Canopy-Kmeans高效算法[J].电子科技,2014(2):29-31.ZHAO Qing.Canopy-Kmeans efficient algorithm based on Hadoop platform [J].Electronic Science and Technology,2014(2):29-31.
猜你喜欢
词学(2022年1期)2022-10-27
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
电脑爱好者(2020年18期)2020-09-26
火控雷达技术(2018年4期)2019-01-15
电脑爱好者(2017年9期)2017-06-01
档案管理(2017年1期)2017-01-17
网络与信息(2009年9期)2009-10-30
网络与信息(2009年9期)2009-10-30
中小学教学研究(2009年8期)2009-09-08
