
基于ElasticSearch的大日志实时搜索的软件集成方案研究
2014-01-15 01:54郭贺彬
吉林师范大学学报(自然科学版) 2014年1期
白 俊,郭贺彬
(北京京北职业技术学院 机电工程系,北京 101400)
0 引言
巨头公司们每天有数以十亿计的日志事件产生,从事大日志挖掘商业价值是一个极大的挑战,因为传统技术不能处理这么大规模的数据.例如,如果载入数万亿的日志事件到Oracle数据库,那么Oracle必须有集群.如果Oracle集群扩展,那么性能会降低,一些传统SQL的功能也会丢失[1].
时间就是金钱,如果我们想搜索和实时分析日志,oracle集群压力巨大,传统RMDBS无法在一个合理的响应时间内处理如此大量的数据.
Hbase是一个基于Hadoop的新型非关系数据库[2], 它是专为大数据的实时访问而设计.Rowkey是Hbase唯一个键值,这意味着在Hbase中没有二次索引[3].所以当我们想从Hbase搜索时,如果不直接使用rowkey,查询数据时需要从硬盘导入更多的数据到内存中.
Lucene是许多互联网公司的标准搜索引擎,但它不适合大数据和云计算环境[4].Solr和ElasticSearch都基于Lucene,它们两个都是开源项目.Solr适用于独立的应用程序,ElasticSearch是专为现代云计算环境设计[5].
ElasticSearch最大的特点是提供近乎实时的搜索服务.虽然它是用Java实现的,但是集成了有很多客户端支持比如 PHP,Ruby,Perl,Python,Scala.NE,JavaScript,Erlang和Clojure. Django,Couchbase 和SearchBox 也集成到ElasticSearch中. MongoDB,CounchDB,RabbitMQ、RSS、Sofa、JDBC、文件系统,Dropbox,ActiveMQ,LDAP,亚马逊,SQS,St9,OAI和Twitter可以直接导入到ElasticSearch[6].Zookeeper and internal Zen Discovery 可用于发现自动节点,所有的分片和副本可以移动到任何节点的ElasticSearch集群中[7].索引可以分发到指定的分片和节点,而且它是RESTFUL架构的.
收集实时的均等的日志是检索和分析的第一步,在这个测试中,Flume是用来做这项工作[8].
1 系统设计要点
Flume代理从最终用户机器收集日志事件,在Flume收集器侧,Hbase插件用于为Hbase提供日志事件.ElasticSearch插件用于分析日志事件和索引提供给ElasticSearch集群.图1显示了日志事件收集、索引和存储.
ElasticSearch首先根据搜索条件得到需要的rowkey列表,Hbase用这些rowkey直接从数据库中得到数据,展示如图2.搜索条件包括:主机名,日志文件路径,日志文件名,日志文件类型,环境,关键字和事件体,开始时间和结束时间.
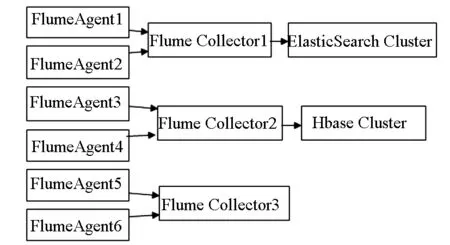
图1 日志事件收集和索引流
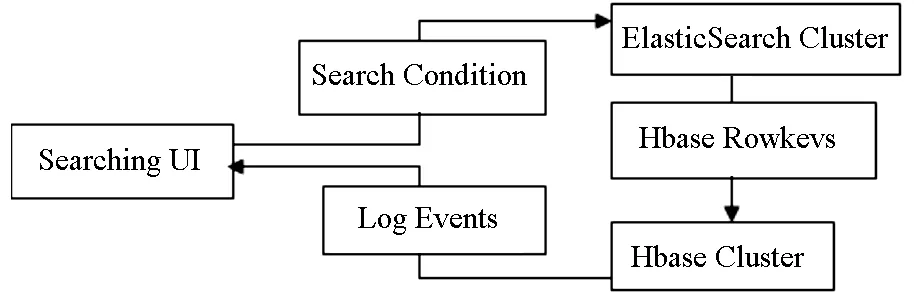
图2 搜索流量
2 数据结构和算法
假设所有的日志由应用程序均等分组,通过一些公司调查发现,SA喜欢把所有的日志单屏浏览.为了给用户一个视觉友好的展示,日志事件应该按他们的生成的序列出现,所以hbase rowkey设计为顺序的rowkey[9].顺序rowkey适合顺序读取是因为相关的数据在同一个的数据块内.
Hbase rowkey模式设计为:appid时间戳,nanotime主机名.因为我们想支持全文检索,所以需要为每一条日志建立索引;但同时,日志事件在一定时间后自动可以被丢弃.ElasticSearch的设计模式如下:
{
"_default_" :{
"_ttl" :{ //Default TTL is 6 months.
"enabled" :true,
"default" :7776000000},
"_source" :{
"enabled" :false},
"properties" :{
"env" :{ //whole env is used as term in Lucene.
"type" :"string",
"index" :"not_analyzed"},
"eventbody" :{ //log event body is
indexed.
"type" :"string"},
"hostname" :{
"type" :"string",
"index" :"not_analyzed"},
"logfilename" :{
"type" :"string",
"index" :"not_analyzed"},
"logpath" :{
"type" :"string",
"index" :"not_analyzed"},
"logtype" :{
"type" :"string",
"index" :"not_analyzed"},
"timestamp" :{ //timestamp and nanotime are used for sorting
"type" :"long",
"ignore_malformed" :false},
"nanotime" :{
"type" :"long",
"ignore_malformed" :false}
}}}
3 测试环境
由于没有足够的资金支持,基于硬件创建了虚拟机[10-11].虽然商品硬件可以足够支持Hadoop,但在生产环境中最好使用更强大的服务器.这就需要使用强大的硬件支持ElasticSearch.Hardware的硬件测试环境如表1.
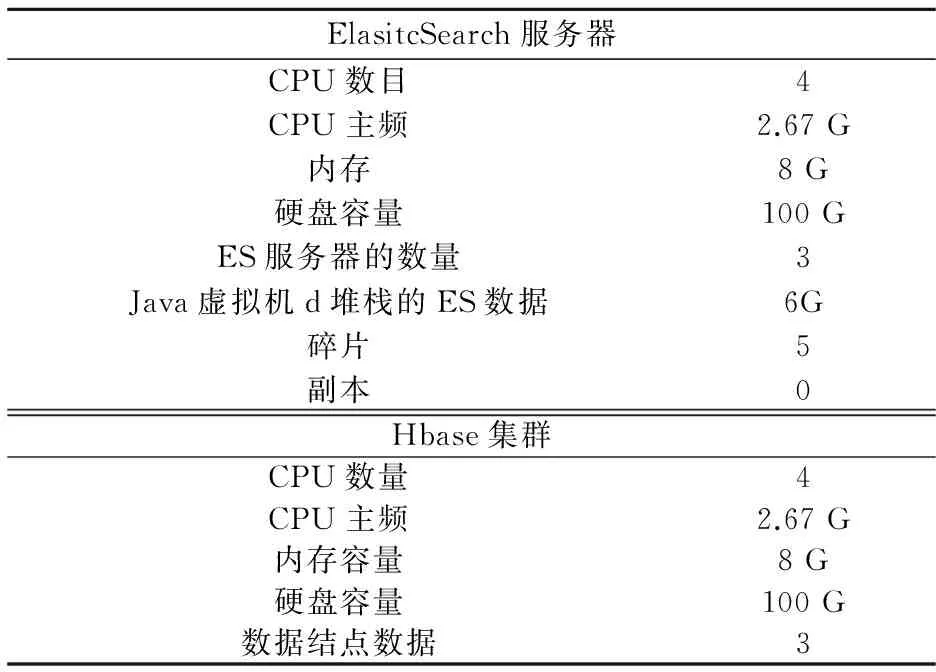
表1 硬件测试环境
3.1 试验结果矩阵
在这个实验中,从一个日志文件中载入足够多的日志事件,ElasticSearch缓存是禁用的,因为想对比真实的搜索性能.共有7 gb日志文件和有148928992个日志事件,搜索关键字是“bigdata”,总匹配日志事件的数量是4375.如果只是想获得前25条匹配的日志事件,它将需要6 s,测试结果矩阵如表2所示.
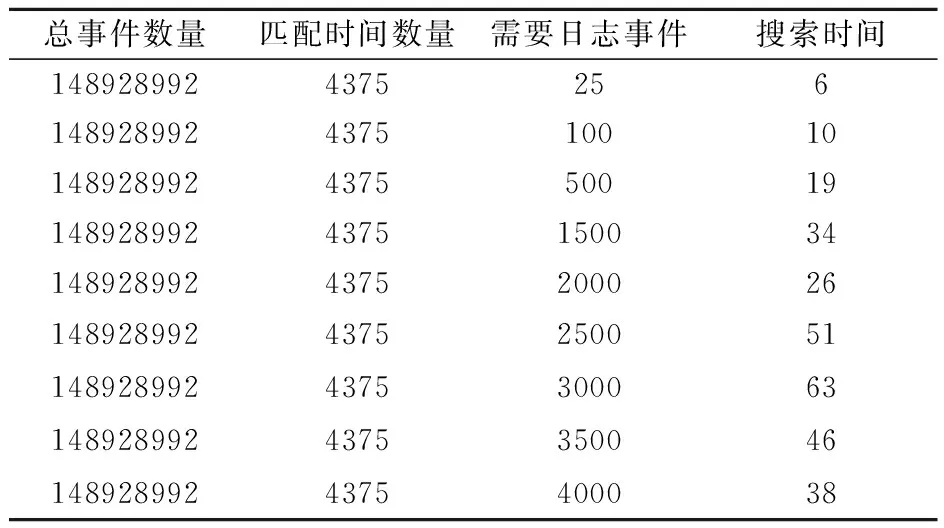
表2 测试结果矩阵
3.2 测试结果图
测试矩阵可视化图如图3所示.
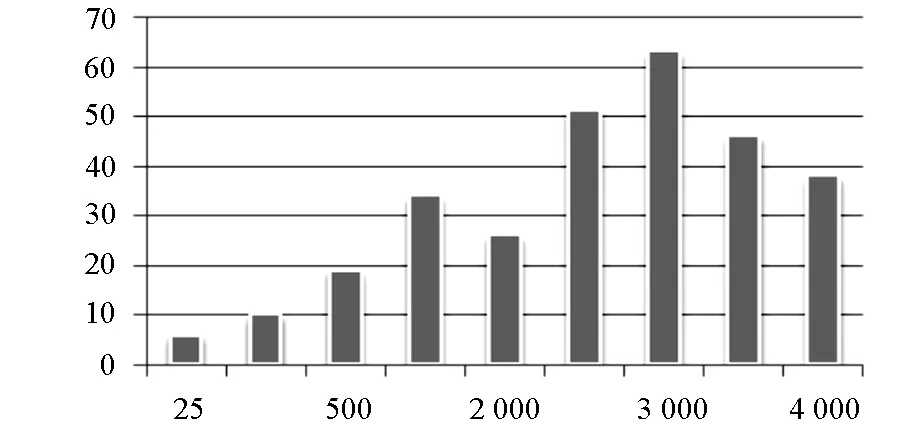
图3 测试结果图
3.3 测试结果分析
基于文中设计的虚拟机环境,设计基于顺序rowkey的ElasticSearch的设计模式,得到实验结果和矩阵可以总结出日志事件可以由Flume实时收集,在Flume收集器侧,Hbase插件用于为Hbase提供日志事件.ElasticSearch插件用于分析日志事件和索引提供给ElasticSearch集群.日志事件可以使用ElasticSearch被实时的索引和搜索出来,随着搜索更多的日志事件,反应时间不线性增加,并且它会在合理的时间返回结果,这是实验预期的性能,文中实验采用的是虚拟机环境,如果提供更强大的服务器到位,性能会更好.文中采用顺序的rowkey,顺序rowkey适合顺序读取是因为相关的数据在同一个的数据块内,又因为rowkey是Hbase的唯一关键性因素,在某些情况下可以重新设计rowkey来获得更多的分布式区域以提升性能.
4 结论
文中基于ElasticSearch 提出了实时进行大日志数据搜索的软件集成方案,并对设计方案进行试验,对试验数据进行分析.数据结果表明,随着搜索更多的日志事件,搜索反应时间不线性增加,说明基于云搜索引擎ElasticSearch实时搜索大数据日志具有可行性.
管理分布式集群不是一件容易的工作,应利用一些SCM工具管理Hadoop集群和ElasticSearch集群.当收集越来越多的日志事件时,索引文件将增长的非常大,搜索所有大型索引文件在生产中是不可能的,可以按每日或者每周来切分日志.Hadoop生态系统和Lucene可以看做是谷歌系统的一些开源实现,应该留意谷歌最新的出版物、FaceBook和其他互联网公司获得更好的想法.
[1] 赵春雷.“大数据”时代的计算机信息处理技术[D].世界科学,2012.
[2]White T.Hadoop权威指南(中文版)[M].北京:清华大学出版社,2010.
[3]杨寒冰,赵 龙,贾金原.Hbase数据库迁移工具的设计与实现[J].计算机科学与探索,2013,7(3):236~246.
[4]McCandless M.Lucene实战(第2版) [M].北京:人民邮电出版社,2011.
[5]Smiley D.Solr 1.4 Enterprise Search Server[M].Packt Publishing Limited,2009.
[6]王 珊,王会举.架构大数据:挑战、现状与展望[M].北京:数据工程与知识工程教育部重点实验室(中国人民大学),2011.
[7]Lars George.HBase权威指南[M].南京:东南大学出版社,2012.
[8]赵彦荣.基于Hadoop的高效连接查询处理算法CHMJ[M].北京:中国科学院计算技术研究所,2012.
[9]杨泽民,王文军,郭显娥.基于协同微粒群的股票数据关联规则挖掘[J].吉林师范大学学报(自然科学版),2012,33(3):31~34.
[10]吕增辉,陶振凯,唐 静.基于Lucene.net的对象持久化的实现[J].吉林师范大学学报(自然科学版),2009,30 (1):90~91.
[11]王俊生,施运梅,张仰森.基于Hadoop的分布式搜索引擎关键技术[J].北京信息科技大学学报,2011,26(4):53~61.
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
电子制作(2019年22期)2020-01-14
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
小学生(看图说画)(2017年6期)2017-11-06
中国交通信息化(2017年3期)2017-06-08
软件(2016年6期)2017-02-06
知识就是力量(2017年2期)2017-01-21
黑龙江工程学院学报(2015年5期)2015-12-04
