
英语口语机考评分系统研究与实现*
2013-12-29 10:32:44汪文棣刘健刚
电子器件 2013年5期
汪文棣,刘健刚,曹 蕾,董 静,姜 浩
(1.东南大学教务处,南京210096;2.东南大学研究生院,南京210096;3.东南大学外国语学院,南京210096;4.东南大学计算机科学与工程学院,南京210096)
杨晶佩宜在评述大学英语口语考试的文章中认为,大学英语口语考试中的试题设计、考生在考试中的真实表现以及考试评估所存在的差异等仍然值得进一步研究和讨论[1]。基于计算机和网络的大学英语四、六级考试项目于2008年12月20日在全国53所高校实施四、六级网考试点考试。基于计算机的英语口语考试则是英语四、六级网考中一个不可缺少的有机部分。然而,目前四、六级网考中的口语考试部分仅仅涉及“模仿”部分,不能含盖英语口语考试的全部测试内容,在考试内容设计上存在漏洞[2]。
大学英语口语考试的目的在于测试中国全口制高等院校在校非英语专业大学生英语口语水平。根据全国大学英语考试委员会的规定,英语口语考试时间长度为20 min,考查内容分为三个部分:(1)自我介绍(热身练习);(2)描述和评论一幅图画,并进行讨论;(3)指定话题提问。金艳认为大学英语四、六级网考项目的总体目标是建立“以试卷库为基础的计算机网络系统,尽可能在适当时间、适当地点为考生提供以听力测试为主,包含说读写译测试在内、重点考查英语学习可持续发展能力的计算机考试”[3]。显然口语测试在大学英语网考中占有一席之地.但是,“跟读句子”是不能全部替代英语口语测试的全部内容。英语口语测试的内容必须还原于全国大学英语考试委员会规定的英语口语测试内容。
口语考试可以以被定义为“一种能鼓励人说话并且根据其话语内容进行评估的考核”[4]。对说话人内容的评估显然在口语考试中占有十分重要的地位,如果在测试中删除了对内容的评估,那么这样的口语考试就没有任何意义,从考试的效度上说是零效度,更谈不上可信度。
本文重点研究的是在基于语音识别技术的最新成果,根据全国大学英语考试委员会规定的英语口语测试内容,从技术实现的途径上提出了一条可行的英语大学英语网考中口语考试的系统模型,从而设法解决英语网考口语单一“模仿评估”的低效度缺陷。
1 基于语种识别的方法实现
基于语种识别方法的实现在英语大学英语网考中口语考试的系统模型设计中很重要。东南大学前几年试用了高等教育出版社的《大学体验英语®》,在原则与特点上注重实用口头和书面表达能力的训练与培养,以适应中国入世以后对外交往的需要,为英语教学网络化及使用多媒体等现代化教学手段提供了立体、互动的英语教学环境。《大学体验英语®》的《听说教程》首先以简短的引导语(Leadin),引出单元的主题。引导语后面一系列精美图片展示了与主题有关的方方面面,为学生提供了联系自我、“高谈阔论”的素材(如图1所示)。老师则进入管理系统,对学生的学习和在线测试进行管理(如图2所示)。

图1 口语测试素材示意图
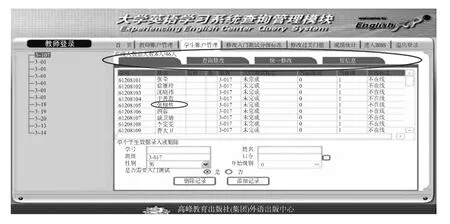
图2 老师管理平台示意图
体验英语《听说教程》的教学内容和课程体系是东南大学在英语教学和测试改革方面所作的一次大胆尝试,具有前瞻性和革命性,当然,也存在着技术上的疏漏,包括本节要解决的问题:非英语语种识别问题。我们现在在校的学生大多是80后,创新意识强,具有突出的个性色彩与表达欲望。学生在堂下进行网络课程自学过程中会进行各种“奇思妙想”,在进行口语测试练习中,根据如图1所上文提示的英文,不是进行英语回答,而是用中文或老家土语进行回答。于是,一传十,十传百,有些勇敢的学生就这个问题向老师提出质疑,怀疑计算机进行口语测试打分的可靠度和可信度。
对于这个问题,本文作者之一刘健刚和董静老师在2011年8月在本刊上刊登了《英语口语机考系统中语种识别方法的研究》的文章,阐述了几种语种识别的方法,这里就不累赘叙述。
2 基于语音识别的方法实现
语音识别技术在英语口语网考中占住着最重要的地位。语音识别技术过不去,英语口语网考中对说话人的内容进行评估就无从谈起。因此基于语音识别的技术要根据口语评估的要求,在现有成熟技术的条件下,尽可能贴近实际测试内容来展开。
基于特征比较的语音评分机制是英语口语学习系统的核心技术,主要用计算机来自动评断一个人的英语发音是否标准,并和标准音进行匹配。全国大学英语考试委员会在这方面已经做了大量工作,并得到了实证确认,人、机评分对比的相似率高达82.7%(如图3所示)。

图3 人、机评分对比相似率示意图
此方法的实现,通过对受试者的发音进行评价,即对发音段中单个音素(如英语的音素)进行评价,还对超发音段(英语的重音调)、单词的发音、句子中词与词之间的协同发音、句子的语速
和流利程度等进行评价(如图4所示)[6]。

图4 (语音)跟读评分实现示意图
3 语音文本转换文字文本的方法实现
语音识别系统是建立在语音技术、信号处理、模式识别等学科的有关数学模型基础上,运用不同的计算机算法来实现的。上世纪90年代初,IBM、Apple、AT&T Bell和NTT等很多大企业都投巨资支持语音识别系统的实用化研究。
客观地说,随着3G手机、GPS导航设备等移动通信终端和MP3、电子词典等便携式消费电子产品的日益普及,语音识别技术在嵌入式设备中的应用越来越广泛,但是在教育系统的平台却始终落后于市场平台,直到四、六级网考试点考试开始。即便如此,也仅仅停留在语音匹配的语音识别技术的层面,不敢越雷池一步,惟恐出现事故。
其实在2004年间,冯嘉礼、方红峰提出的数学模型及软件编程就已经实现了英语语音转换成英文文字[7]。其从语音文本到文字文本实现的技术途径通过对声音文本的语音(单个词汇、连续词汇、寂声段时长以及声调)进行处理,将语音标点符号识别出来,从而为计算机转化文字奠定了语法规范[8]。根据语言语法规范,将识别出来的文字进行准确断句,然后生成文字(如图5所示)。目前我国语音识别的技术实现率(未学习的样本),可以达到72%[7]。

图5 语音文本转换文字文本实现途径示意图
4 文字文本自动评分的方法实现
在对72%实现率的语音转换为文字文本后,我们通过数据挖掘的技术就可以对文字文本作自动评分。一般而言,对于文本内容的评估,考虑到受试者表达习惯、知识水平的不同,对同一个概念可能有不同的表达方式,我们采用LSA(Latent Sematic Analyser)的方法来检测内容。
LSA假设文字文本中存在某种潜在的语义结构。这种潜在的语义结构隐含在文字文本中词语的上下文使用模式中,可通过利用统计方法获得。其核心思想是通过奇异值分解,将文档向量和词向量投影到一个低维空间,使得相互之间有关联的文字文本,在没有相同词匹配的情况下,也能获得相同的向量表示[9]。以LSA为模型的文字文本内容评估,基于东南大学外语教学中采集的大量作文集合。从这些大量的作文集合中,采用统计的方法可以计算出那些单词对于评分较为关键。计算机自动提取出那些对评分高低影响较大的单词项作为特征项,从而来衡量文字文本与英语口语主题内容的相关度。这样的设计,有效防止了受试者回答问题偏题的棘手问题,也防止了一些与考题无关但语言方面优秀的答案获取高分评估。
在计算机自动评分系统的平台上,我们设计了嵌入式软件,采用了语义词典WordNet来作为语料库,用来匹配与关键词语义相关的词。然后根据在受试者语音文本转换为文字文本中文字命中率情况来对英语口语的内容方面进行评分。
5 英语口语机考评分系统的实现
系统依托我们开发的第一代智能语音交互技术,主要完成英语口语语音的智能评测和学习功能。测试功能大体上包括口语测试、听力测试两大部分;学习功能上主要包括英语朗读,口语对话两大部分。图示如图6。
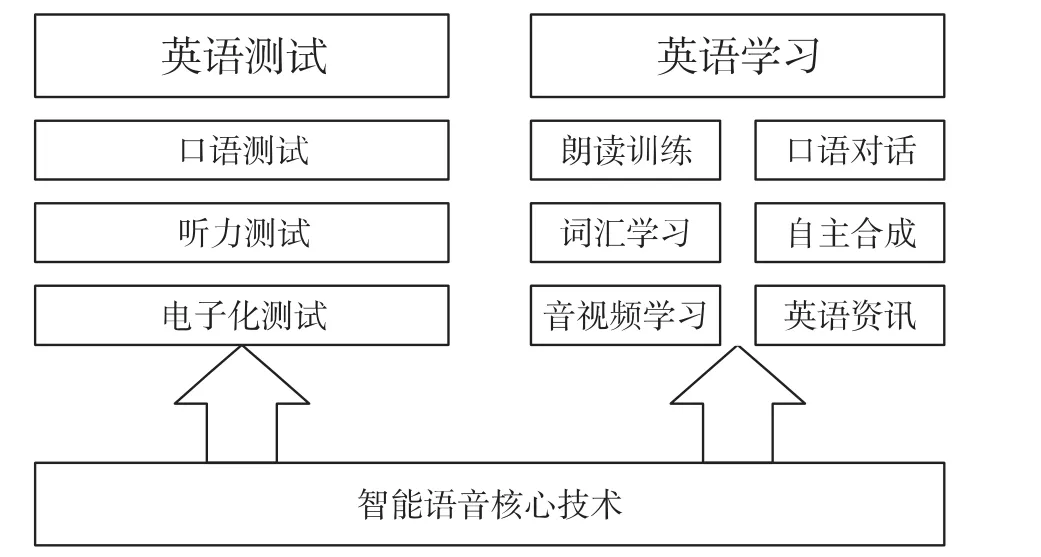
图6 第一代智能语音交互技术示意图
为了开发第一代智能语音交互平台和便于携带的英语评分系统,我们把语音识别等功能在基于DSP的硬件系统上进行了实现。系统的DSP采用TMS320C54X系列芯片实现,它是TI公司于1996年推出的16 bit定点低功耗数字信号处理器。它采用先进的修正哈佛结构,片内有8条总线、CPU、片内存储器和在片外围电路等硬件,加上高专业化的指令系统和6级深度的指令流水线,使得C54X具有功耗小、高度并行等优点[10]。本系统采用了C54X系列的TMS320C5416定点DSP来实现说话人识别装置,其结构如图 7所示。因为TMS320C5416是定点的数字信号处理器,对定点数据处理很快,却对浮点数据的处理却很慢。为了能在实际应用中满足用户的需求,说话人自动识别系统应能以尽可能快的速度来完成识别过程,最好能达到实时。因此在开发过程中,我们对所有的浮点数据进行定点化,以提高程序执行的效率。C5416 DSP的片上资源有限,片上数据存储器为64 kbyte,片上程序存储器也是64 kbyte。为了防止数据空间不够,在该系统中我们把所有的提示语音存放在程序存储器里,而所有的码本及采样的语音数据都存放在数据存储器里。
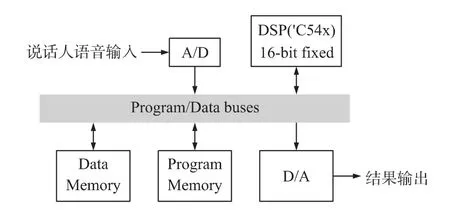
图7 DSP说话人识别装置示意图
系统的实现主要包括语音信号的预处理,特征提取,训练,测试和实时识别过程。在本设计中需要做的预处理及特征提取是预加重、加窗、分帧、求线性预测分析系数,最后求出LPC倒谱系数和倒谱系数的r阶线性回归系数以及估计基音和差值基音周期。
精度问题在定点DSP中是相当重要的,它将直接影响到识别的效果,为了能使系统有很高的正确识别率同时又不消耗过多的时间和内存资源,我们在开发系统时尽可能地合理分配计算位数,在保住精度的同时减少资源消耗。在定点化的过程中对各模块进行了定点模拟并分析比较其误差,确保计算的可靠性。
第1个实验是非特定人英语连续语音识别实验。利用日本电子协会标准噪声数据库中的行驶中的汽车(2 000 cc组,一般道路)内的噪声(平稳噪声)和展览会中的展示隔间内的噪声(非平稳噪声),把这些噪声按一定的信噪比(SNR)叠加进无噪连续数字语音中组成带噪语音。识别结果如表1所示。
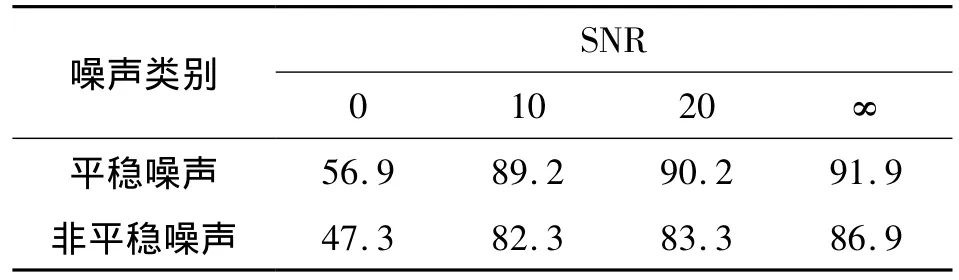
表1 连续英语语音识别结果 %
第2个识别实验是户外实际场所的英语语音识别实验。实验是利用在学校门口、交通道路和学校食堂3种不同的环境下采集的英语语音进行的。结果是这3种环境下的识别概率分别是86%、80.4%、82.4%,达到了较高的识别精度。
6 结论
文章论述了目前四、六级网考试点考试中口语测试中效度的不足。阐述了英语口语机考应该像传统的口语测试一样,检测评估受试者的语音、语法和内容这几个方面,而不应该仅仅拘泥于“跟读”模仿能力的评估。文章提出了英语口语机考评分实现途径,既通过语种识别、语音识别、语音文本转换文字文本、文字文本评分四个环节来实现英语口语机考的自动评分。本文提出的方法能够较好地实现四、六级网考中英语口语评估的难题,对大规模展开英语口语机考具有十分重要的指导作用和现实意义。
[1]杨晶佩宜.大学英语口语考试介评[J].昆明学院学报,2010,32(1):135-137.
[2]Liu Jiangang,Zheng Yuqi,Chen Meihua,et al.A Study on the Feasibility of CET Oral Test Based on Automatic Essay Marking[J].Journal of Southeast University(English Edition),2012,28(4):410-414.
[3]金艳,吴江.大学英语四、六级网考的设计原则[J].外语界,2009,133(4):61-68.
[4]Underhill N.Testing Spoken Language[M].Cambridge:Cambridge University Press,1987:21.
[5]宫力,梁维谦,丁玉国.大规模英语口语考试跟读题型采用机器阅卷的可行性分析与实践研究[J].外语电化教学,2009,126:10-21.
[6]黄晓勇,虞维.语音识别技术在外语口语学习中的应用[J].计算机系统应用,2006,6:18-21.
[7]方红峰,冯嘉礼,韦梦芸,等.英语语音转换英文文字的软件实现[J].哈尔滨工程大学学报,2006,27:584-586.
[8]刘健刚,储琢佳,赵力.语音文本的标点符号特性初探[J].语言科学,2013,12(2):405-410.
[9]黄涛.四、六级考试英语作文自动评分研究[D].南京:东南大学计算机科学与工程学院,2011.
[10]彭启.TMS320C54X实用教程[M].成都:电子科技大学出版社,1999:189-215
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
文苑(2018年22期)2018-11-19 02:54:18
疯狂英语·新策略(2017年7期)2018-01-03 06:50:36
疯狂英语·新策略(2017年8期)2017-05-31 08:13:19
学生天地(2017年10期)2017-05-17 05:50:44
小天使·三年级语数英综合(2016年6期)2016-05-14 15:41:17
当代教育实践与教学研究(2015年2期)2015-02-27 08:03:04
