
科研信息采集整合系统研究
2013-12-27 01:06:02王冬艳敦冬梅羊红光
河北省科学院学报 2013年4期
王冬艳,成 彬,敦冬梅,羊红光
(1.河北省科学院应用数学研究所,河北石家庄 050081;2.河北省信息安全认证工程技术研究中心,河北石家庄 050081;3.河北华烨冀科信息技术有限责任公司,河北石家庄 050081;4.石家庄职业技术学院,河北石家庄 050081)
科研信息采集整合系统研究
王冬艳1,3,成 彬1,2,敦冬梅4,羊红光1,2
(1.河北省科学院应用数学研究所,河北石家庄 050081;2.河北省信息安全认证工程技术研究中心,河北石家庄 050081;3.河北华烨冀科信息技术有限责任公司,河北石家庄 050081;4.石家庄职业技术学院,河北石家庄 050081)
科研信息服务需要专业的信息检索与信息整合。科研信息采集整合系统利用Nutch实现数据的采集与索引,针对公网网页和专业数据库的类型采用不同相关度计算方法,实现了科研信息的有效整合。
科研信息;采集;整合;数据关联
互联网时代采集科研信息的渠道有很多,比如专业学术数据库、专利数据库、电子图书、网络博客、学术论坛等,这些数据依靠人工已不能完成采集、定制、分析、整合。实现科研信息服务定制需要用户与专门的信息环境共同完成,一方面要根据科研用户构建该学科领域在学科资源体系下的资源与服务框架,一方面要构建专门用于科研信息服务的搜索工具及数据整合系统[1]。
科研信息定制环境下的信息检索不能是单纯的信息检索,而是以发现文献信息之间的关系更快、更全面、可定制的检索服务[2]。
基于Nutch面向科研信息服务进行定制开发的信息系统,开展科研信息的定向采集、识别与提取、分析与整合等信息加工,可实现科研信息的准确细致分类与存储。
1 科研信息服务的服务需求
科研用户在科研项目立项、前沿课题追踪、项目研发等科研活动中,必须对特定的科研方向有一个准确及时的了解。科研信息的采集主要包括几个方面:一是文摘数据库、全文数据库、电子图书等这些正式出版物;二是重要学术机构、国内外学术会议、专家的学术报告等学术信息;三是网络中的技术博客、学术交流论坛、百度百科等学术信息。总的来说,这些信息一些是公众网络的网页,一些是专业数据库。
科研用户根据自身科研信息需求往往需要跟踪某一领域的研究进展,常常在互联网及专业数据库中搜索一些固定的主题关键词来获取想要的内容,然而搜索出来的内容中有很多是不相关的。从网络采集的科研信息往往是异构数据,这些数据应先进行过滤清洗处理,然后再由服务器端向客户端进行映射与集成。科研信息服务需要有广泛的信息采集、快速的数据索引、有效的数据整合等功能[3]。
科研用户需求的科研信息资源不是广泛的采集集合。而是具有高度相关性的信息集合,因此需要对采集来的信息按照合适的算法进行关联性计算,清洗过滤掉与主题相关度不高的数据,再将处理过的数据进行分类存储,为用户建立可定制的信息索引库。
因此科研工作者需要一个能根据自身需要定制检索主题,自动加入检索入口并生成关键词,主动进行信息采集与加工,智能过滤冗余的信息噪音,整合和细分用户需要的信息资源,从而获得一个与主题相关度高、有一定主题内容分类的信息整合系统。
2 Nutch搜索引擎
Nutch完全构建在Hadoop分布式计算平台上,可实现多节点抓取和索引,具有网址解析、网页去重、网页排序等功能。Nutch搜索引擎是一个开放源代码的搜索引擎。
2.1 Nutch的主要组件
Nutch拥有抓取器和搜索器两个重要的组件(图1)。在抓取操作中,抓取器既可以从互联网上抓取网页,也可以从内部局域网上抓取数据,抓取的方式是以广度优先搜索的;抓取的数据被存储到CrawlDB和Link DB数据库中,再由内置的解析器解析这些文档。最后存储解析结果到index DB和SegmentsDB数据库,以供搜索器搜索使用[4]。
在搜索操作中,可通过网页上的输入框输入相应关键词,之后调用Nutch搜索接口(Nutch Query Interface)。Nutch索引器在index DB上展开搜索,这个过程是调用Lucene引擎来完成的。接下来搜索接口收集从索引器返回的URL、标题、锚和从SegmentsDB返回的内容。排序完成后,搜索接口返回搜索结果。
Nutch构建在Hadoop分布式文件系统之上具有集群扩展能力,并可以由map/reduce实现对CrawlDB,Link DB,SegmentsDB和Index DB等数据库的操作。

图1 Nutch搜索引擎架构
2.2 Nutch的工作流程
整个系统的工作流程可以分解为以下6个步骤[5-6]:
(1)原始种子站点建立。根据科研用户提供的站点和主要的学术数据库作为原始种子站点,这种方式获得的站点更加可靠、准确。
(2)抓取任务创建和分解。依照系统资源配置和抓取任务实现种子站点的合理分组,采用多次迭代定量抓取的方法,以保证抓取任务的快速、平稳进行。
(3)子任务抓取。依据爬虫迭代深度、限制每次迭代中前N条记录、Fetcher线程数、爬取记录的保存目录,完成完整的爬取过程。根据预先设定的抓取深度、线程数、结果存放路径,将抓取任务分解成多个子任务后依次抓取。
(4)数据过滤与去重。在合并多个子任务获取的数据成一个数据文件前,可选择性地过滤指定内容。通过运行URLFilter过滤数据库中的URL,以滤去不需要的URL,所有版本的元数据被聚合起来,新的值代替先前的值。同样通过调用Nutch命令实现数据去重。
(5)抓取数据合并。每一个子任务完成后都生成一个索引目录,调用Nutch命令合并后的索引存储目录。
(6)获取新的种子站点。在抓取过程中统计不在原始站点中的出现较多的站点,将他们作为新站点开展新抓取,并重复以上数据操作。
3 科研信息采集整合系统
3.1 科研信息采集整合系统框架
对于科研信息采集整合系统来说,重要的对数据的整合过程。在数据整合中,应研究数据间的关联性方法及实现机制[7-10]。采集整合系统框架见图2。
对数据进行相关性分析,需要在关联数据集合中通过有效的挖掘关联数据来处理复杂的知识关联,从公共网络和专业数据库中抓取相关的数据,在通过执行各类相关数据的交互实现预定科研信息的筛选、分类以及知识发现。
数据关联中的查询包括数据采集、预处理、合并、结果存储等几个步骤。查询方式可以是中心化也可以是分布式,对于科研信息采集整合系统来说前者将在数据聚合、索引计算开销、数据存储速度等方面无法达到要求,而采取后者能有效解决这些问题。
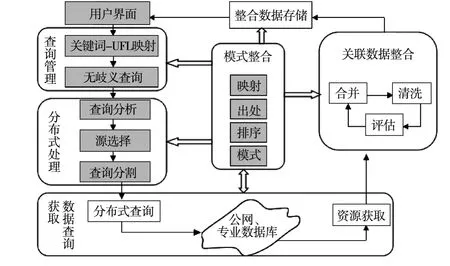
图2 科研信息采集整合系统框架
关联数据整合模块负责数据的合并、清洗和评估,可将各类相关数据合并到一起,并进行分类。
整合数据存储模块负责对整合后的数据进行存储,并建立临时缓存和永久存储两种模式,能提供标准的数据访问和调用接口。
模式整合模块负责构建通用和专用词汇之间的映射,解析数据间的关联关系。
查询管理模块负责将异构数据转化为符合关联数据查询的形式。
数据查询与获取模块利用Nutch技术奖网络数据和专用额数据库数据进行采集和索引,为数据分析查询提供数据来源。
分布式处理模块利用云计算技术保障高效的数据查询。
3.2 网页主题相关项的近似度
根据主题关键词利用网页特征项和主题相关项统计来计算网页的相关度,实现网页内容的筛选、排序和清洗。
用网页特征项来描述主题关键词,用统计特征项进行关键词匹配、搜索结果排序。设计的特征项计算公式如下:

其中A是主题相关项集合,Ra是关联关系集合,τai是主题相关项a i的权重,num ai是主题相关项ai的出现数量,d[ai,aj]是主题相关项ai和a j的关联度,const是调整参数。
3.3 文献资源的数据相关度
文献资源主要由各类文档构成,通过计算文档相关度来实现主题相关项的筛选、排序和清洗。文档的相关度就是文档和主题的相关度,因为这个值是为了度量文档和主题相关的程度,也称作文档的主题相关性。计算文档的相关度只要求两个向量的距离即可。
利用向量空间模型的排序策略分析,构建主题关键词二元组向量KW,KW={<kw1,role1>,<kw2,role2>,……,<kw N,roleN>},通过对一些主题网站和专业文献数据库的分析,得到的主题关键词向量。
主题关键词向量和文档关键词向量分别用t和d表示,文档的主题相关性用space(dt)示。计算文档相关度的过程中要求向量t和d的元素个数要一样。
在向量t和d中取出关键词作为新向量dt。将改变后的t记作二元组tt,其关键词为dt中的关键词,role为t中的role,当tt中与t中的关键词不一致时role为0。将改变后的d记作二元组dd,其关键词为dt中的关键词,role为d中的role,当tt中与d中的关键词不一致时role为0。这样计算t和d的距离只要计算tt和dd的距离。
计算tt和d d的距离的公式为:

4 结语
科研信息采集整合系统是科研工作的一个有力工具,本系统利用Nutch技术可以轻松实现网页、数据库内容的采集和索引。该系统的难点在于数据的清洗与整合,对于不同类型的科研信息数据,采用不同的科研信息数据关联计算方法,实现了科研信息数据的有效整合,便于查询与应用。
[1]王巍.高校图书馆个性化科研信息服务探究[J].江西图书馆学刊,2013,2:67-69.
[2]白光祖,吕俊生,吴新年.科研个性化信息环境初探[J].情报科学,2009,27(4):502-506.
[3]梁田.个性化科研主题信息环境构建技术方案实践[J].图书情报工作,2012,R(2):103-105.
[4]陈相如.针对结构化商品数据的多样性搜索系统的设计与实现[D].上海:上海交通大学,2013.
[5]王春华.基于Nutch的农业搜索引擎检索结果排序策略的研究[D].杨凌:西北农林科技大学,2010.
[6]陆小丽,何加铭.基于Map/Reduce的索引数据云存储模型研究[J].宁波大学学报(理工版),2011,24(3):29-33.
[7]李楠.基于关联数据的知识发现研究[D].北京:中国农业科学院,2012.
[8]T Baker,J keizer.Linked Data for Fighting Global Hunger:Experiences in setting standards for Agricultural Information Management[J].Linking Enterprise Data,2010,2:177-201.
[9]C Bizer.The Emerging Web of Linked Data[J].Intelligent Systems,2009,24(5):87-92.
[10]H Chowdry,C Crawford,L Dearden,et al.Widening participation in higher education:analysis using linked administrative data[J].Journal of the Royal Statistical Society:Series A,2013,176(2):431-457.
Research on science research Information collection and Integration system
WANG Dong-yan1,3,CHENG Bin1,2,DUN Dong-mei4,YANG Hong-guang1,3
(1.InstituteofAppliedMathematics,HebeiAcademyofSciences,ShijiazhuangHebei050081,China;2.HebeiAuthenticationTechnologyEngineeringResearchCenter,ShijiazhuangHebei050081,China;3.HebeiHuayejikeinformationTechnologyCo.LTD,ShijiazhuangHebei050081,China;4.ShijiazhuangVacationalTechnicalInstitute,ShijiazhuangHebei050081,China)
Science research information services require more excellent Information Retrieval and information integration.With the nutch technology,Information Collection and index can be achieve in Science Research Information Collection and Integration system.The implementation of science research information Integration by different relativity calculation methods for web pages and specialized databases.
Research on Science;Research Information;Collection;Integration data association
TP317.1
:A
1001-9383(2013)04-0022-05
2013-08-25
王冬艳(1977-),女,河北赞皇人,工程师,主要从事计算机技术应用研究.
猜你喜欢
肉类研究(2022年7期)2022-08-05 04:47:20
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
信息安全研究(2016年4期)2016-12-01 06:06:54
公民与法治(2016年22期)2016-05-17 04:20:26
电子测试(2015年18期)2016-01-14 01:22:58
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机与网络(2014年7期)2014-03-25 10:57:07
电脑迷(2012年4期)2012-04-29 06:12:13
