
粗糙集与SVM的组合算法在人工林地力评价中的应用
2013-12-27 13:17:49魏善沛
中南林业科技大学学报 2013年5期
魏善沛,章 景,王 凯
(中南林业科技大学 计算机与信息工程学院,湖南 长沙 410004)
粗糙集与SVM的组合算法在人工林地力评价中的应用
魏善沛,章 景,王 凯
(中南林业科技大学 计算机与信息工程学院,湖南 长沙 410004)
采用粗糙集(Rough Set,RS)与支持向量机(Support Vector Machine,SVM)相结合的组合算法,寻求人工林地力等级评价的新方法。利用地力样本数据及指数和法评价结果构建RS决策表,应用RS的穷尽算法对决策表进行约简,并用约简后的评价指标作为SVM的输入,对SVM进行训练,建立人工林地力等级的RSSVM评价模型。应用该方法对湖南会同集水区杉木林土壤肥力质量等级进行评价,在同样的训练样本的情况下,RS-SVM模型、SVM模型及BP神经网络模型评价正确率分别为78%、78%、67%。与单一SVM评价方法相比,RS-SVM模型在保证评价精度的同时,降低了算法的空间和时间复杂度,提高了训练效率,同时具有比人工神经网络更高的评价精度。
人工林;地力评价;粗糙集;支持向量机
林地地力评价是林地管理的基础,也是精准林业决策的重要内容。它可以评估林地的生产能力水平,指导其合理开发利用,对合理利用现有的林地资源,治理或修复受污染、退化以及沙化的土壤提供科学依据,为基层林业技术人员和林业决策者提供决策支持,保障林业可持续发展。因此,对林地地力评价的研究具有重要的科学价值和实际意义。林地地力等级评价一般沿用了耕地地力评价的方法。目前,地力等级评价的方法归纳起来大概有如下几类:一是基于数值的方法,如模糊综合评价法、指数和法、层次分析法及灰色关联度分析法等;二是基于地理信息系统(GIS)技术和数据挖掘技术的方法,如基于决策树的方法;三是基于人工智能机器学习的方法,如人工神经网络方法、SVM方法等。基于数值的方法大多数需要领域专家选择评价因子和确定权重,评价的结果受主观性影响较大,并且因为较少考虑土壤各属性间的依赖关系,所以较难表达环境变量和土壤性质间的非线性关系[1]。地理信息系统和挖掘技术的方法工作量比较大,而且评价的步骤也比较的复杂。基于神经网络(Artif i cial Neural Networks, ANNs)的方法处理非线性关系的能力虽然比较强,但却存在网络结构难以确定,局部最优及泛化能力比较弱等一些比较难以克服的缺陷[2]。同时,上述方法或者使用单一,或者较少考虑各评价各因子间相互依赖关系。RS理论是一种处理不确定性和不完整性的比较好的数学工具。它在保留关键信息的前提下对数据进行化简并求得知识的最小表达,识别并评估数据之间的依赖关系,从经验数据中获取最小规则,所以在很多领域都得到了广泛应用[3]。SVM是一种基于统计学习理论的新的机器学习方法。它通过寻求结构风险最小化来实现经验风险最小化,比较好地解决了神经网络的固有问题,已被成功应用于模式识别、时序预测、回归分析等领域[4-9]。基于RS理论在消除冗余信息和处理不确定性信息等方面的优势及SVM在解决小样本、非线性及高维模式识别问题中表现出许多优势,本文将RS理论和SVM算法相结合,提出基于RS和SVM的人工林地力等级评价方法。
1 算法理论基础及评价步骤
1.1 粗糙集理论
属性约简是RS理论中的核心内容之一。属性约简是在保持原信息系统的决策或分类能力不变的前提下,删除不重要或不相关的冗余属性,使原系统得到简化。属性约简一般都不会惟一,同时也已经证明寻找属性的最小约简都是NPH(非确定性多项式难题)问题。目前,约简的方法比较多。本文采用其中的穷尽算法进行约简,其基本思想是:通过构造分辨矩阵导出分辨函数,然后应用吸收律对分辨函数进行化简,使之成为最小析取范式,进而求得数据属性集的约简[2]。该算法存在算法复杂度高的缺点,一般适用于较小的数据集,不过它可以求出所有的约简。本项目属性集比较小,可以采用穷尽算法,同时,本项目将直接采用Rosetta数据分析软件(挪威科技大学和波兰华沙大学的科技人员合作开发)穷尽算法对人工林地力等级评价指标进行约简。
1.2 支持向量机
1.2.1 两类分类算法
分类思想:对于样本集T={(x1,y1),(x2,y2), …,(x1,y1)},xi∈ Rn,yi∈ {1,-1},通过一个非线性映射Φ(·)将xi映射到一个高维特征空间 ,然后在这个空间中构建一个超平面,要求这个超平面不但能将样本集中的两类点完全正确地分开,还要使分类间隔2 /‖w‖最大,这个超平面用w·Φ(x)+b=0表示。
然后通过求解公式(1)式的优化问题来确定w和b:

其中: C为惩罚参数,ξi为松弛变量。
公式(1)的对偶形式:
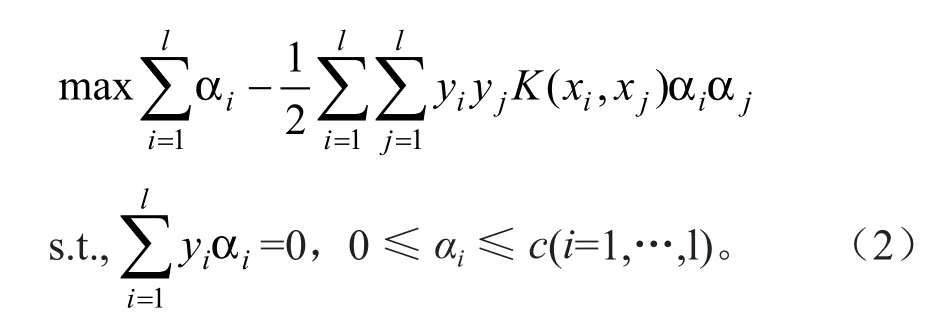
其中,K(xi,xj)=Φ(xi),Φ(xj)为核函数。因为全局性核函数学习能力较弱泛化能力强,而局部性核函数学习能力强泛化能力较弱,所以为获得学习能力和泛化能力都较强的核函数,本文选用如公式(3)所示的混合核函数,它由4阶多项式核全局核函数和高斯径向基核局部性核函数构成的,

其中r(0≤r≤1)为调节高斯径向基核和多项式核作用大小系数,σ为高斯径向基核宽度。求解公式(2)得最优解为α*=(α*1,…,α*1) ,计算
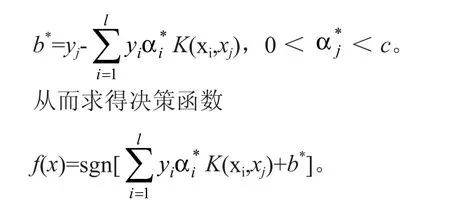
1.2.2 多类分类算法
SVM本质上是两类分类器,人工林地力等级评价结果有多类,需要用SVM多类分类的方法。比较常用的多类分类方法有一对一方法,一对多方法及SVM决策树方法等。一对多方法只需求解N个两类分类机,所以训练时间比较的短,可适用于分类较多的情况。不过当分类类别数较大时,这种方法存在某一类的训练样本将大大少于其他类训练样本总和的问题,这样一来需-要采用类别补偿SVM来解决。SVM决策树方法是将SVM和决策树结合起来,构成多类分类器。这种方法的缺点是如果在某个分类节点路径上发生分类错误,则会把这种错误延续到它的下级节点。本文采用一对一的方法。其思想是:为任意两个类构建超平面,共需训练N(N-1)/2个两类分类器。这种方法的缺点是分类器的数目随分类数的增加而迅速增加,导致分类速度慢。不过,人工林地力等级类别一般都只有几个,所以采用一对一方法影响不大。
2 评价步骤
本文基于RS和SVM相结合的组合算法对人工林地力等级进行评价,具体步骤如下:
第一步:选取评价指标,确定指标权重,确定地力划分等级。评价指标的选取要遵循有效性、敏感性、实用性、通用性等原则。也就是说在评价指标选取的过程中要立足综合的、系统的观点,通过分析各种土壤特性在土壤质量形成中的主次作用,选取那些有重要影响的,对表征土壤功能是有效的,对土壤变化足够敏感的,要易于定量测定的指标,同时不要无限制地扩大指标的选择面,使整个指标体系复杂化。在土壤质量评价中需要根据不同的土壤、不同的评价目的,按照上述指标选择原则因地制宜对这些指标进行取舍组合。
第二步:数据采集。首先确定评价单元和采样点,进行土壤样品采集和分析测试,然后对样本进行量化、离散化处理,得到离散化后的数据集。
第三步:对处理后的数据集利用指数和法计算地力等级。
第四步:利用处理后的数据集和指数和法评价结果,构建RS决策表,进行属性约简,剔除冗余的评价指标,得到约简后的指标集。
第五步:利用第二步得到的数据集、第三步得到的评价结果及第四步得到的约简指标集,建立SVM样本集数据集,并将它分成训练样本集和测试样本集。
第六步:通过训练样本对SVM进行训练,建立SVM的评价模型,然后用测试样本对SVM模型进行测试;
第七步:利用第六步得到的SVM模型对待评价单元的地力进行等级评价。
3 实例分析
3.1 评价区域概况
会同杉木林集水区位于湖南省怀化市会同县广坪镇境内,地处湖南省西南边陲,属中亚热带气候区,为云贵高原向长江中下游过渡地带,地貌为山地丘陵,海拔高度:270~390 m,土壤母质以震旦纪板溪系变质岩、页岩为主体,分化程度深,土壤为中有机质厚层山地森林黄壤,土层厚度约80~100 cm,地下水位深度6 m,年平均湿度78%,无水土流失和盐碱化现象。
3.2 评价区评价体系的构建
根据湖南会同站杉木林历史调查土样数据,按照有效性、敏感性、实用性、通用性原则,选取会同站集水区杉木人工林土壤肥力质量评价指标及采用专家经验法确定的各指标权重见表1。根据评价区的具体情况及考虑到以后的通用性将会同站集水区杉木人工林土壤肥力质量划分为4个等级,具体见表2。
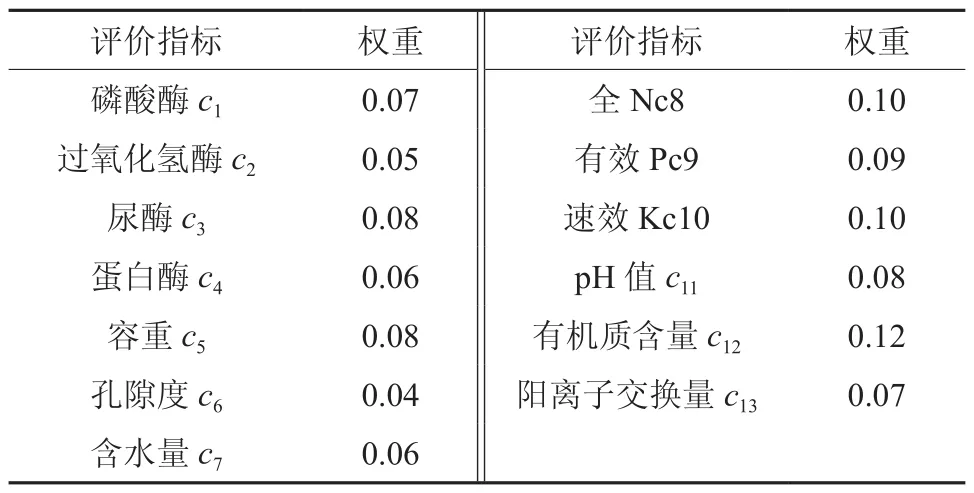
表1 会同站集水区杉木人工林土壤肥力质量评价指标及权重Table 1 Chinese fir plantation soil quality evaluation index and weight in catchment of Huitong

表2 会同站集水区杉木人工林土壤肥力质量评价等级划分标准Table 2 Grading standard of chinese fir plantation soil quality evaluation in catchment of Huitong
3.3 数据采集
根据操作规范对集水区5.89 hm2杉木人工林进行地力调查取样,取土样共18个。对土样量化、离散化处理后的样本集见表3。土壤因子变化具有连续性,本文对各评价指标采用连续性的隶属度函数进行离散化处理。根据主成分因子负荷量值的性质确定隶属度函数分布的升降性。升型分布函数和降型分布函数的计算公式如下:
Q(xi)=(xi-ximin)/(ximax-ximin)。 (4)
Q(xi)=(ximax-xi)/(ximax-ximin)。 (5)
其中:Q(xi)为表示各土壤因子的隶属度值,xi为表示各因子值,ximax和 ximin—分别表示第i项因子中的最大值和最小值。
3.4 指数和法评价结果

表3 会同站集水区杉木人工林土壤质量因子的隶属值及指数和法评价结果Table 3 Membership values of chinese fir plantation soil quality evaluation of in catchment of Huitong and its evaluation results by integrated productivity factors method
3.5 粗糙集属性约简
根据表3所示的离散化结果集与指数和法评价结果。利用离散化结果集,形成条件属性集C,将指数和法评价结果作为决策属性D,构建RS决策表。然后使用Rosetta数据分析软件对RS决策表进行属性约简。得到磷酸酶、过氧化氢酶、尿酶、蛋白酶、容重、含水量、全N、有效P,速效K,pH值,有机质含量,阳离子交换量12个关键指标。
3.6 构建RS-SVM评价模型
利用上述12个评价指标与指数和法评价结果,建立构造RS-SVM评价模型的样本集。从18个土样中选择9个典型样本(1,3,5,7,8,10,14,16,18)作为RS-SVM训练样本,其余9个土样号样本作为测试样本,用于测试RS-SVM模型的性能。用DOTNET平台(C#)编程实现SVM算法(根据样本数据自动进行参数优化)。用训练样本构建好RS-SVM评价模型后,对测试样本进行评价计算,评价结果见表4。
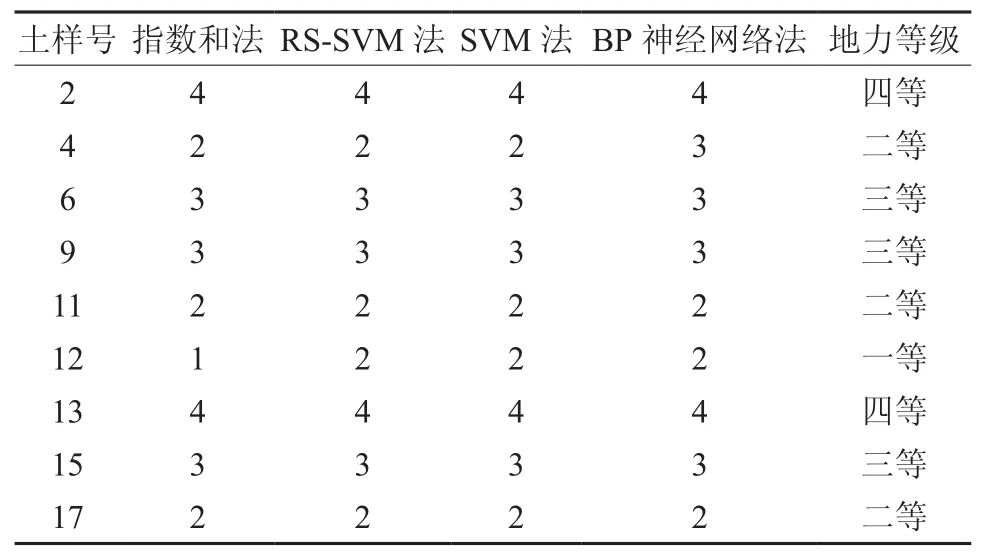
表4 BP 神经网络法、SVM法与RS-SVM 法评价结果比较Table 4 Comparison of results of BP neural network method, SVM method and RS-SVM method
3.7 评价结果及比较
用未约简评价指标数据与指数和法评价结果,采用跟构建RS-SVM模型同样的方法构造SVM评价模型并对测试样本进行计算,评价结果见表4。
同理,用约简前的评价指标样本数据与指数和法评价结果,分别作为BP神经网络的输入输出,采用改进的3层BP神经网络构造BP神经网络评价模型。然后用测试样本进行评价计算,评价结果见表4。
纵观表4可以看出,RS-SVM法、SVM法与BP神经网络法评价正确率分别为89%、89%、78%。实验表明,SVM评价方法比BP神经网络评价方法正确率要高;通过RS属性约间后,SVM评价方法在保证精度的同时减少了输入指标,降低了空间和时间复杂度,提高了训练效率。指数和法步骤比较复杂,工作量也比较大,且主观性比较强,在少量评价单元的地力评价工作中可以采用。在本项目中用其评价结果构建RS决策表和作为训练样本的输出,是进行属性约简的依据,也是BP神经网络法和SVM法的训练样本的来源。
4 结 论
基于小样本统计学习理论的SVM具有很强的泛化能力,有效地克服了神经网络局部极小、过学习等不足,在地力等级评价实验中,具有比BP神经网络更高的精度。将RS理论与SVM算法结合起来构建的RS-SVM评价模型,在保证评价精度的同时降低了空间和时间复杂度,提高了效率。实际地力等级评价中,到评价区的每一处采样和测量是非常困难的,在大规模地力评价中,特别是样本有限的情况下,采用RS-SVM方法进行地力等级评价,是一种可行的方案。
[1] 陈桂芬,马 丽,董 玮,等.聚类、粗糙集与决策树的组合算法在地力评价中的应用[J].中国农业科学,2011,44(23):4833-4840.
[2] 赖红松,吴次芳.基于粗糙集和支持向量机的标准农田地力等级评价[J].自然资源学报,2011,26(12):2141-2154.
[3] 曹丽英,孙学生,赵月玲,等.一种基于决策树算法的耕地地力等级评价[J].东北林业大学学报,2011,(2):93-96.
[4] 吴鹏飞,孙先明, 龚素华,等.耕地地力评价可持续研究发展方向探讨[J].土壤,2011,43(6):876-882.
[5] 张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.
[6] 田大伦.森林生态系统卷-湖南会同杉木林站(1982-2009)-中国生态系统定位观测与研究数据集[M].北京:中国农业出版社,2011.
[7] 李 浩,王卫文,杨红梅,等. 基于粗糙集的广州木本绿化植物配置模式评价因子分子分类研究[J].中南林业科技大学学报,2011,31(7):8-11.
[8] 王传立.粗糙集和BP神经网络对自重应考试模型的改进[J].中南林业科技大学学报,2011,31(8):211-216.
[9] 王 刚.杉木人工林土壤肥力指标及其评价[D].南京:南京林业大学,2008.
Application of combinatorial algorithm of rough set and support vector machine in productivity evaluation of plantation
WEI Shan-pei, ZHANG Jing, WANG Kai
(School of Computer and Information Engineering, Central South University of Forestry & Technology, Changsha 410004, Hunan, China)
By using the combinatorial algorithms of rough set (RS) and support vector machines (SVM), a new method for plantations fertility level evaluation was studied. The RS decision-making table was built up, and the table was reduced by employing RS exhaustive algorithms, then the SVM was trained with the reduced evaluating indicators as the SVM’s input, thus the RS-SVM evaluating model for plantations fertility level evaluation was established. The soil fertility quality grades of China fi r plantation in the catchment in Huitong,Hunan were evaluated. The fi ndings were as followings: under the condition of same training sample data, the evaluation correctness rates of the RS-SVM model, SVM model and BP net model were 78%, 78%, 67% respectively; compared with the single SVM, the RSSVM model, under the condition of ensuring the accuracy of the evaluation, reduced the space and time complexity of the algorithm, and improved the training eff i ciency, and at the same time, had a higher evaluation accuracy than the artif i cial neural network model.
artif i cial forest; productivity evaluation; rough set; support vector machine
S714.8
A
1673-923X(2013)05-0001-05
2012-12-19
国家林业公益性行业科研专项(201004014)
魏善沛(1956-),男,江西赣州人,教授,硕士生导师,研究方向:Web数据库、信息处理;E-mail:weishanpei1@163.com
[本文编校:吴 毅]
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
自动化学报(2018年2期)2018-04-12 05:46:01
现代园艺(2017年19期)2018-01-19 02:50:08
现代园艺(2017年21期)2018-01-03 06:42:24
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
山东林业科技(2016年5期)2016-07-05 00:43:04
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
广西林业科学(2016年3期)2016-03-16 05:43:30
