
基于改进Rocchio算法的短文本自动分类研究
2013-12-20 08:24:40郑秋生翟琳琳
中原工学院学报 2013年1期
郑秋生,翟琳琳
(中原工学院,郑州450007)
随着互联网的快速普及和发展,人们的生活方式也在发生着变化,博客、论坛、微博、聚合新闻(RSS)等成为人们表达感情、传播思想的主要渠道.短文本信息,通常是指文本篇幅较短、字数不超过200个的文本,比如来自微博、即时通讯、新闻评论、贴吧等的信息,都可以归结为短文本信息.近年来,短文本信息因其内容长度较短、表达方式灵活而备受人们青睐.面对扑面而来的大量短文本,如何能够快速分门别类,找到用户所关注的信息和类别?这就使短文本的自动分类问题的研究显得尤为重要.
目前,对长文本信息的自动分类研究很多,提出了多种分类算法,如K近邻算法、朴素贝叶斯算法、决策树算法、支持向量机算法等.但是,这些适用于长文本的自动分类算法在短文本信息分类的应用中有一定的局限性.基于此,本文提出利用简单向量距离算法(Rocchio)[1]来对短文本进行分类,在实施分类过程中,改进了训练集和分类算法,使得分类效果更好.
1 Rocchio算法描述
简单向量距离法是一种基于向量空间模型的分类算法.该算法的分类思路十分简单,根据算数平均为每类文本集生成一个代表该类的原型向量,然后在新文本到来时,确定新文本向量,计算该向量与每个类的原型向量的距离(相似度),最后判定文本属于与文本距离最近的类.具体步骤如下:
(1)计算每类文本集的原型向量,计算方法为训练集中所有文本的算数平均.
(2)新文本到来后经过预处理,然后将文本表示为特征向量.
(3)计算新文本特征向量与每个类原型向量的相似度.
(4)比较每个类原型向量与新文本向量的相似度,将文本分到相似度最大的那个类别中.
2 基于改进Rocchio算法的文本分类
文本自动分类的过程通常包括文本预处理、文本特征表示、特征选取、建立模型并分类、模型评价.
2.1 文本预处理
预处理是进行文本分类的必经阶段,主要是对训练集中的文本和新到来的文本进行去除停用词和稀有词、过滤非法字符、进行分词等[2]工作.短文本信息内容精炼,噪音相对较少,预处理过程主要是分词.目前的分词工具很多,这里采用中科院的ICTCLAS对文本进行分词和词性标注.
从词性方面来说,对文本所属类别影响最大的是名词.因此,预处理过程中选择保留所有的名词,并将这些名词作为文本的特征项.这样,训练集中已经分好类别的文本集经过预处理就形成了一部由若干个“小词典”(每个类中的名词组成的词典)组成的“大词典”(整个训练集中的名词组成的词典).对于训练集,这里选择搜狗实验室和复旦大学提供的长文本语料库,这样可以丰富、扩充形成的“大词典”,提高分类精度.
2.2 文本表示
文本表示模型有3种:布尔逻辑模型;向量空间模型(VSM);概率模型.其中,向量空间模型使用最为广泛.VSM的思想是将预处理后的文本D表示成一个向量V=(T1,W1;T2,W2;T3,W3;…;Tn,Wn).其中,T表示短文本中的特征项;W 表示特征项在文本中的权重值(特征项在文本中的重要程度),简单记为V=(W1,W2,W3,…,Wn)[3].
目前广泛使用的权重计算方法是TF-IDF.TF-IDF是一种统计方法,多用来评估某个字或者词在一个文件集或语料库中的某份文件中的重要程度.字或者词的重要程度与它在文件中出现的频率成正比,与它在文件集或语料库中出现的频率成反比[4].TF-IDF公式表示为:

其中,Wik表示文本Di中第k个特征项的权重值;TFik表示特征项Tk在文本Di中出现的频率;IDFik是反文档频率.TF-IDF公式经过归一化处理后表示为:
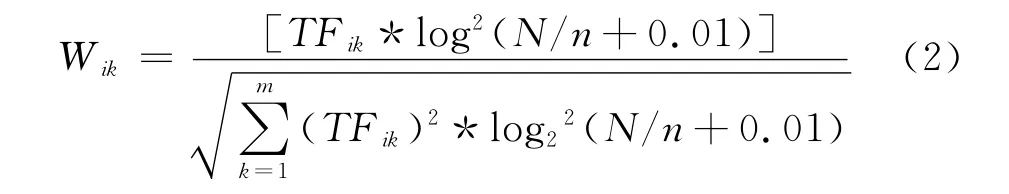
其中,N代表所有训练文本的数目;n代表训练文本中出现该特征项的文本数;m代表文本Di中特征项的数目.
本文采用的权重计算方法是将原有TF-IDF公式作了改进,使其更适用于短文本信息的自动分类.改进后TF-IDF公式表示为:
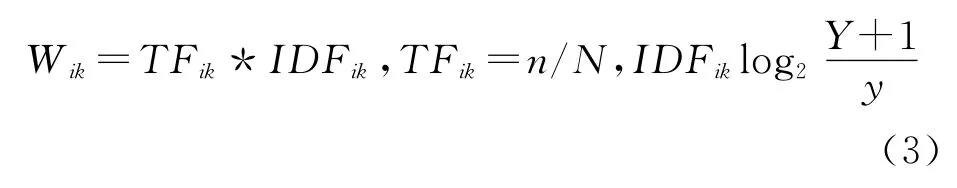
其中,Y和y分别表示第k个特征项在“大词典”和“小词典”中出现的次数.
改进后的TF-IDF公式经过归一化处理后表示为:
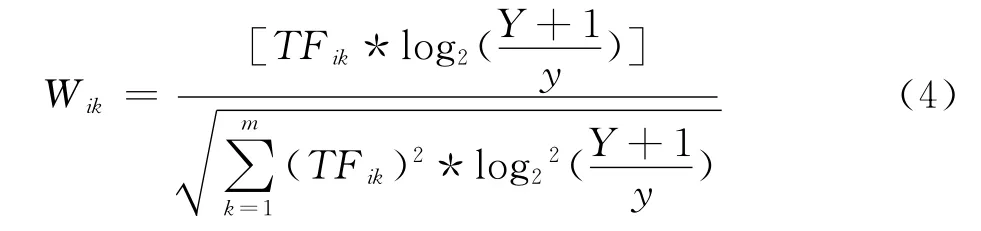
其中,m代表文本Di中特征项的数目.
2.3 特征选取
在对长文本分类过程中,通常采用文本频率(DF)、信息增益(IG)、x2统计量、互信息(MI)等方法进行特征提取,这样既可以降低文本向量空间维度,还能提高分类效率和精度[5].短文本内容短小,文本表示成向量后的维数也不高,并且预处理中留下的名词就能够代表文本的类别特征,所以将文本中的名词都作为特征项,这也是本文中特征选取方法的特别之处.文本表示成向量的维数没有一定的限制,可以根据实验结果做适当的调整.
2.4 建立模型并分类
建立分类模型是实施文本分类的核心部分.分类模型主要由分类方法来完成.一般将分类方法划分为训练和分类2个子过程.训练是通过对训练集进行学习,建立分类器,然后使用该分类器对新到来的短文本信息进行分类[6].训练集的大小和质量对分类的结果有很大的影响.考虑到短文本内容较短、字数较少等原因,本文使用的训练集中的文本全是长文本,这样既可以丰富词典,还可以提高分类器的准确度.
在Rocchio算法基础上,本文对训练集中每个类别的原型向量的计算方法做了改进,改进后计算方法如公式(5)所示.
对于训练集中的文本类别C,其原型向量中第k项特征的权重Vk定义如下:

其中,Vk是文本类别C的原型向量中第k项的权重值;|Rc|是文本类别C中的总文本数;i是文本类别C中的文本序号;Wik是第i个文本中第k项特征的权重值.从公式(5)中可以看出,原型向量就是文本类别C中所有训练文本对应的特征项权重的平均值.
对于新到来的短文本信息,将其表示成向量后,本文采用计算新文本向量与每个原型向量夹角的cosine值来度量两者的相似度sim(di,dj),其公式表示为:
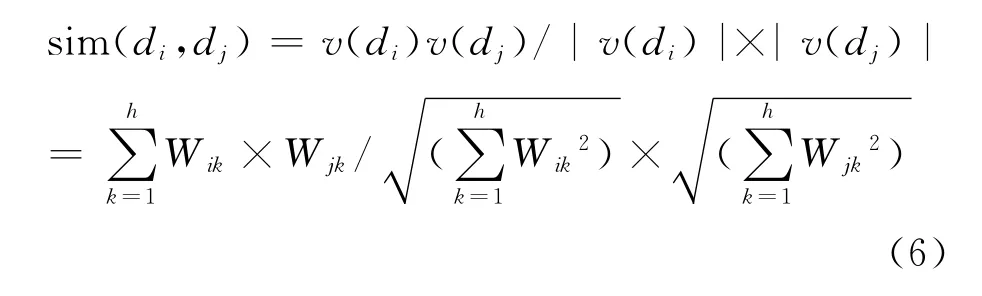
其中,v(di)表示新到来的短文本向量;v(dj)表示原型向量;h是短文本向量的维数.计算得出的相似度值越大,表示新文本与该类别越相似;反之,两者的差距越大.根据公式(6)计算新到来的短文本与训练集中所有类别的原型向量的相似度,最终将新文本归入相似度值最大的类别中.
2.5 模型评价
模型评价主要考虑分类结果的效率和准确度两方面[7].目前真正适用于短文本信息分类的模型不多,并且每种模型都不完美,都有一定的局限性;这就需要不断地实验,并在实验过程中做适当调整和改进,尽量使效率和准确度都有所提高.
3 实验结果及分析
实验中采用的2个语料库分别来自搜狗实验室和复旦大学.搜狗实验室提供的语料库中共有9个类别,其中每个类别有训练文本1 999篇[8];复旦大学语料库提供的语料库中共有20个类别,去除部分重复文本和损坏文本后,有训练文本8 214篇[9].这里从2个语料库中选取6个文本类别进行实验,如表1所示.测试文本选用从互联网上搜取的短文本信息,共计1 336篇,如表2所示.

表1 训练语料库情况篇

表2 测试文本集情况篇
采用3个通用的评价指标对分类结果进行评价:准确率P、召回率R 和平均F1值[10-11].
准确率P=c/a*100%召回率R=c/r*100%
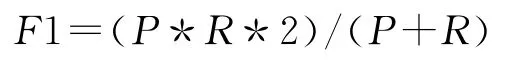
其中,c是正确分到某类的文本数;a是实际分到某类的文本数;r是应分到某类的文本数.
其中,|C|是训练集中类别的数目;b是训练集中的某个类别;Pb和Rb分别表示某个类别的准确率和召回率.
采用改进的Rocchio算法实现短文本的分类,并与改进之前进行对比,比较结果如表3所示.
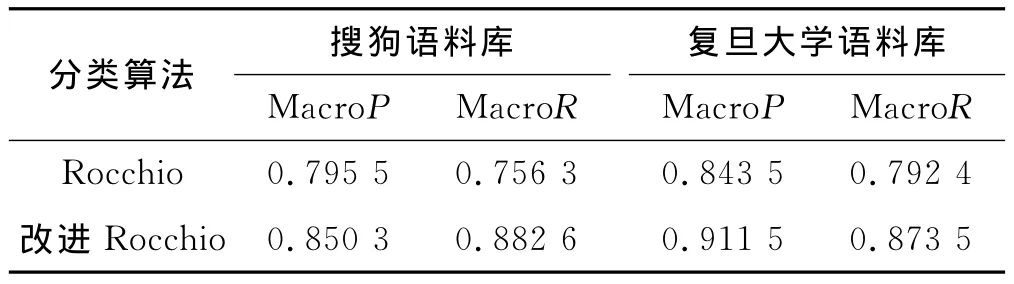
表3 两种分类算法在不同语料库中的比较
根据F1值的计算方法,可以得到各个类别的F1值,结果对比如图1所示.

图1 两种分类方法的F1值对比图
从表3和图1可以看出,改进后的Rocchio算法的平均F1值整体上要高于改进前的算法.
4 结 语
本文采用大量长文本作为训练集,以此形成词典,并对传统Rocchio算法中的特征项权重计算公式(TF-IDF)做了改进,最后利用改进的Rocchio算法对短文本信息进行分类.实验结果表明,改进的Rocchio算法分类效果较好.
[1]王治和,杨延娇.对简单向量距离文本分类算法的改进[J].计算机科学,2009,36(1):236-238.
[2]张爱华,荆继武,向继.中文文本分类中的文本表示因素比较[J].中国科学院研究生院学报,2009,26(3):401-403.
[3]郭庆琳,李艳梅,唐琦.基于 VSM 的文本相似度计算的研究[J].计算机应用研究,2008,25(11):3257-3258.
[4]施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009,29(6):168-170.
[5]Salton G,Wong A,Yang C S.A Vector Space Model for Automatic Indexing[J].Communications of ACM,1975,18(11):613-620.
[6]David D Lewis.Feature Selection and Feature Extraction for Text Categorization [C]//Proceedings of Speech and Natural Language Workshop.Morgan Kaufmann:Defense Advanced Research Projects Agency,l992:212-217.
[7]Yang Yiming.An Evaluation of Statistical Approaches to Text Categorization[J].Information Retrieval,1999,1(2):69-90.
[8]Jasper’s Java Jacal.关于复旦大学自然语言处理实验室基准资料[EB/OL].(2008-06-21).http://www.sogou.com/labs/dl/c.html.
[9]Jasper’s Java Jaca.文本分类技术[EB/OL].[2012-11-02].http://www.nlp.org.cn/docs/doclist.php?cat_id=16&type=15.
[10]Zelikovitz S,Marquez F.Transductive Learning for Short Text Classification Problems Using Latent Semantic Indexing[J].International Journal of Pattern Recognition and Artificial Intelligence,2005,19(2):143-163.
[11]Fabrizio Sebastiani.Machine Learning in Automated Text Categorization[J].ACM Computing Surveys,2002,19(5):1-34.
猜你喜欢
小资CHIC!ELEGANCE(2021年45期)2021-01-11 03:51:12
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
英美文学研究论丛(2018年2期)2018-08-27 01:56:18
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
剑南文学(2016年14期)2016-08-22 03:37:42
新校长(2016年8期)2016-01-10 06:43:59
人间(2015年20期)2016-01-04 12:47:08
语言与翻译(2015年4期)2015-07-18 11:07:45
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
