
移动环境下个性化推荐系统的设计实现
2013-12-10 14:07:14西安电子科技大学经济管理学院
电子世界 2013年5期
西安电子科技大学经济管理学院 田 亮 宋 薇
东软集团大连有限 公司 黄少冰
1.引言
近年来,随着移动互联网的迅速发展,特别是国内3G牌照发放后,移动互联网用户增长迅速。根据中国互联网络信息中心(CNNIC)发布的《第30此中国互联网络发展状况统计报告》显示,2012年上半年中国互联网电脑网民规模达到5.38亿,而手机网 民数量将达到3.88亿。据DDCI互联网数据中心预测,到2013年中国手机网民将达7.2亿,首次超越电脑网民[1]。随之而来的是移动互联网上各类信息的爆炸式增长,使得人们通过移动网络获取信息更加方便的同时,也使得人们获取有价值的信息愈发的困难。
为解决Internet上信息淹没的现状,个性化推荐技术得到了广泛的应用。针对移动互联网的特殊性,本文把传统Internet上个性化推荐技术应用到移动互联网上,提出了移动个性化推荐的离 线解决方案,并且设计了基于J2ME的移动个性化推荐系统。
2.A TC与CF结合的推荐模型
2.1 相关技术概述
为解决文本分类中人为因素的影响,自动文本分类(Automatic Text Categorization)技术得到了快速的发展与应用。目前比较常用的有KNN,朴素贝叶斯分类,SVM等分类方法。这些方法都是建立在统计学的基础上,通过特征提取来标注文本文档,建立文档模型后不同的方法应用不同的分类器来进行文本分来处理。文本分类建立在大量文档的基础之上,从而消除了不同的人对文档文类不同的分歧,使得分类过程不受人为因素的影响。
协同过滤(Collaborative Filtering,CF),又称协作型过滤,是在信息过滤与信息发现领域非常受欢迎的技术。一个协作型过滤算法通常的做法是对一大群人进行搜索,从中找出与当前用户喜好相同的一小群人,并且对这些人的偏好内容进行考察,将结果组合起来构造出一个经过排名的推荐列表[2]。协同过滤技术分为基于用户相似性的协同过滤(User-based),基于推荐项目的协同过滤(Item-based)与基于模型的协同过滤(Model-based)三种基本方式。Userbased协同过滤是发现相似用户群体,根据相似用户的浏览记录来进行兴趣发现并推荐给用户;Item-based协同过滤计算推荐项目之间的相似性,把与用户以前浏览的项目相似的项目推荐给用户;Modelbased协同过滤首先建立个性化推荐的数学模型,根据数学模型来计算推荐集。
本文主要应用朴素贝叶斯分类器与基于项目的协同过滤算法来构建移动网络的个性化推荐系统。
2.2 个性化推荐模型
基于J2ME的移动网络个性化信息推荐系统整体架构如图1所示,系统模型基于C/S结构设计,客户端采用J2ME技术实现手机客户端信息浏览系统,服务器端采用Servlet实现。
由图1可以看出推荐模型可以分为四个主要部分:
1)用户信息采集分为显性的信息采集与隐性信息采集方式。显性的信息采集方式为在用户的终端浏览界面设置信息反馈栏目,在该栏目中用户可以设置自己的使用偏好信息;隐性的信息采集方式为根据用户对信息的浏览时间,对信息是否保存,对信息是否转发等情况对信息内容做出隐性的评价。本文使用5分制规则,对信息保存,转发评分为5分,根据用户对信息浏览时间的长短为信息设置1-5分的分值。
2)信息发布系统主要负责添加推荐信息,在此过程中使用朴素贝叶斯文本分类器对文本类别进行划分。
3)个性化推荐引擎采用基于用户背景信息分类与历史记录可信度加权的Item-Based协同过滤算法产生推荐信息集。
4)终端系统采用基于J2ME技术实现,提供信息浏览与用户偏好采集功能等。
2.3 朴素贝叶斯文本分类
文本分类是将未知的文本类型划分到规定好的类别中,从而降低人为因素的影响。朴素贝叶斯分类以古典数学理论为基础,分类效率稳定,同时模型构建简单,性能优越。因此本文选取朴素贝叶斯分类器作为文本分类的工具。
本文使用的基于朴素贝叶斯分类的文本分类过程如下:
(1)训练文本的向量空间表示
生成向量空间模型的步骤有文本分词处理,除去停用词,特征选择等。经过各个阶段,最终将确定一组特征词作为特征词空间W={w1,w2,w3,…,wm},w表示特征词。将文本映射到该组特征词空间,使文本的表示形如T(A)={pA1,pA2,pA3,…,pAm},pAi为文档频率法表示词wi在文档A上的权重。pAi还可以通过信息增益法,开方拟合检验等其他方法表示[3]。
(2)计算每个特征词所属类别的概概率分布
计算每个特征词属于每个类别的概率,具体计算方法:分别计算每类文件的质心,并计算出每个词能够代表每个类别的概率,最终形成如表1所示的特征词-文本类别对应矩阵。关于文件集质心的计算可以
[4][5]。
(3)向量空间模型的形成
根据已选定的特征词空间,将待分类文本映射到特征词空间中,使其表示为向量空间形式:T(X)={pX1,pX2,pX3…pXm}。
(4)根据特征词的概率分布情况,计算待分类文本所属类别的概率
确定待分类文本T(X)属于分类Ck(Ck∈{C1,C2,C3…Cn})的概率R(k),R(k)的计算方法如公式1所示。

(5)确定待分类文本的类别
按(4)中所提计算公式分别计算待分类文本属于每个类别的概率R(k),具有最大值R(k)的类别即为该待分类文本的最终分类。
2.4 基于用户分类与记录可信度加权的协同过滤算法
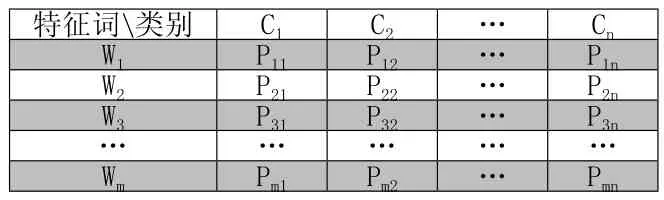
表1 特征词——类别对应概率分布

图1 基于J2ME的移动网络个性化推荐模型
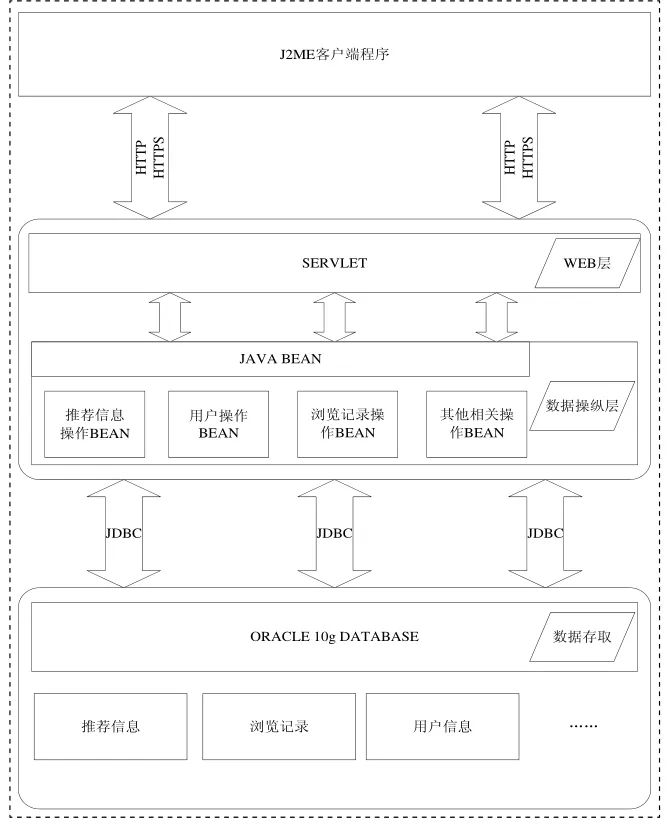
图2 软件层次模型

图3 客户端软件流程图
本文提出的改进的协同过滤算法与传统的协同过滤算法的区别主要有两点:依据用户的背景信息进行分类与用户的历史记录信息加权。按用户背景信息进行过滤的想法源于一个假设:相同背景信息的用户具有相似的信息需求,根据用户的背景信息去除关联度小的用户群体记录,可以降低历史评分记录的维数,提高程序的运行速度;考虑到用户的偏好可能随着时间的推移而变换,历史的评分记录不能真实反映当前的用户偏好,因此对用户的历史评分记录进行加权处理,使得距离当前时间较近的评分记录拥有较高的权限,这样既考虑历史记录的影响,又可以突出最新评论的真实性。
(1)用户分类方法
对用户进行分类,就是要筛选出影响用户获取信息类别的关键背景信息,又称为关键因素。以获得的关键因素作为分类标准对用户进行分类。
用户分类主要有三个步骤:
1)统计用户最关注信息的所属类别,也就是用户的偏好情况。
2)计算出用户信息基本信息集的信息熵。
3)计算用户基本信息中每个属性的信息增益,从中选择信息增益最大的属性作为影响用户获取信息的关键因素,并以此关键因素作为用户背景信息分类标准来进行用户分类。

图4 系统运行界面
当用户背景信息分类量较大,或者用户历史记录信息量非常大时,可以采用多个用户背景信息组合的方法获取关键因素。信息增益与信息熵的相关用法可以参考ID3分类算法[6],此外还有一些基于信息增益的特征选取方法,文献[7]给出了一种改进的特征选取方法。
(2)信息相似度计算
研究发现“用户的最新评价信息拥有最高的权重,而距离当前时间越远的记录拥有的权值越小”,项目加权便是建立在这个基础上进行的。由此可知项目可信度函数具有单调递增性。另外,为了确保近期不同用户的评分信息具有大致相同的权值,可信度函数应是一个凸函数。所以,可信度函数要综合考虑长期情况下数据权重的差别性和短期内数据权重的相似性。最终设定可信度函数为:以项目排列顺序为自变量的函数f(Sui),1≤Sui≤M,M为记录总数,并且0<f(Sui)≤1。根据以上条件我们选择对数函数作为可信度函数,并将函数进行归一化处理。这里设置可信度函数为如公式2所示:

从公式1中可见f(Sui)值域为[0,1],符合上述描述条件。
计算项目相关相似度的方法有很多,包括余弦相似度法,Pearson相关性[8]等。本文采用余弦相似度法来获取相似性,公式3为改进的余弦相似度公式[9]。

其中,U表示项目Ii,Ij已经评价的用户集;Vui为用户u对Ii项目的评价分数;Sui为用户u对Ii项目评价记录的标识序号;f(Sui)则表示用户u针对Ii项目评价记录所占的权值。
(3)改进的协同过滤算法描述
输入:推荐用户u基本信息,所有用户背景信息及历史评论信息。
输出:对用户u的Top-N推荐
具体步骤:
1)找出影响用户分类的关键因素
2)以1)中获得的关键因素为基础,选取所属类别相同的用户群体。根据分类规则和个体用户的基本资料获取与该用户所属类别相同的用户群组。
3)获取用户群的历史记录,按时间排序。
4)根据3)所得的记录顺序进行记录可信度加权,获得评分矩阵。
5)在用户参与评论的条目中搜寻未经用户评论条目的最近邻居集。
6)预测用户对未浏览和未评论过的条目的评价情况,生成推荐集。获取评价排序的TopN条信息推荐给用户。
3.移动个性化推荐系统设计
3.1 整体架构
如图2给出了基于J2ME的移动网络个性化信息推荐系统的层次模型,主要分为客户端数据获取层,Web层,数据操纵层,数据存储层。客户端主要负责向终端用户显示推荐信息并且获取用户的显性输入的信息和用户隐性输入的信息;Web层主要由Servlet,JSP实现,负责向系统的数据库中添加推荐信息,并且提供Servlet访问接口供J2ME客户端程序以HTTP/HTTPS方式获取或添加信息;数据操纵层主要是一些JAVA BEAN,这些JAVA BEAN封装了数据操纵API,向外界提供统一的访问接口;数据存储层主要应用Oracle 10g数据库管理软件。
3.2 客户端程序流程
客户端通过一个主MIDlet程序启动,提供了推荐信息显示,信息收藏,信息检索,用户个人偏好反馈等主要功能模块,主要功能的程序流程图如图3所示。首次使用客户端程序需要注册用户名、密码等信息,以后应用可以直接利用保存在J2ME记录管理系统(RMS)中的个人信息进行登录,经过验证成功后的用户可以进行相关操作。
3.3 服务器端程序结构
服务器端程序主要模块为文本分类模块,个性化推荐模块。为降低用户等待时间,这两个模块的运行均采用离线运行的模式执行。即设定固定的运行时间或手动运行来更新特征词空间,概率分布信息,以及用户的分类属性,推荐集信息等。
文本分类模块负责将文本分类相关的数据信息保存在文本文件或数据库中,以便输入文本时无需再次计算相关参数,可以直接进行分类运算,提高实时性。
个性化信息推荐模块负责产生与维护用户对用户的推荐信息集,该过程要保证推荐信息的新颖性,因此需要在后台启动一个运行线程,实时更新推荐集信息。
3.4 客户端-服务器通信方法
JAVA ME API提供了J2ME MIDlet程序与服务器端通信两种方法:基于socket连接的方式和基于超文本传输协议的HTTP通信方式,本文使用HTTP方式实现客户端-服务器端通信。客户端与服务器通过HTTP输入/输出流的方式进行数据交换,程序的一端使用特定的编码格式向输出流(OutputStream)中写数据,在另一端打开输入流(DataInputStream),并且从流输入流中读取数据,解码后完成信息的传递。下面给出了一个Post方式提交信息的Http方式连接服务器的代码片段。

4.系统仿真实验结果
系统仿真环境:采用HP Compaq dx7408 PC,开发软件MyEclipse 7.0,Oracle 10g,Wireless Toolkit 2.5.2。
在上文提出的移动个性化信息推荐模型的基础上,本文作者在实验室环境下设计开发了一种基于J2ME的移动个性化信息推荐原型系统,系统运行界面如图4所示。
为测试系统推荐的正确性,在实验室六名志愿者的参与下,根据他们前四天的浏览记录推荐第五天的偏好信息,推荐正确率在80%左右。
5.结束语
本文为解决移动网络上的信息过载状况提出了一种解决方案,设计实现了基于J2ME的移动网络个性化推荐原型系统,并且取得了较好的推荐效果。由于时间有限,该原型系统在推荐效率和通用性方面仍然有待改进。
参考文献
[1]工业和信息化部运行监测协调局[EB/OL].http://yxj.miit.gov.cn/n11293472/n11295057/n11298508/14741971.html.
[2]Toby Segaram.Programming Collaborative Intelligence[M].O’Reilly Media,2007(8).
[3]陆玉昌,鲁明羽,李凡,周立柱.向量空间法中单词权重函数的分析和构造[J].计算机研究与应用,2002,10(10):1205-1210.
[4]Lertnattee V,Theeramunkong T.Effect of Term Distributions on Centroid-based Text Categorization[J].Information .ciences,2004,158(1):89-115.
[5]E Han,G Karypis.Centroid-based document classi fi cation:Annlysis & experimental results.In: European Conf on Principles of Data Mining and Knowledge Discovery(PKDD).Berlin:Springer-Verlag,2000:424-431.
[6]J.Han and M.Kamber.Data Mining:Concept and techniques Second Edition[M].北京:机械工业出版社,2006(4).
[7]朱颢东,钟勇.基于改进的ID3信息增益的特征选择方法[J].计算机工程,2010,4(8):37-39.
[8]刘枚莲,从晓琪,杨怀珍.改进邻居集合的个性化推荐算法[J].计算机工程,2009,6(11):196-168.
[9]黄少冰.基于J2ME的移动网络个性化信息推荐研究[D].西安电子科技大学(硕士论文),2010.
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21 02:08:14
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
中国机械工程(2017年22期)2017-12-02 01:52:34
新校长(2016年8期)2016-01-10 06:43:59
中文信息学报(2015年4期)2015-04-21 08:29:12
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
