
聚类分析算法在入侵检测中的应用研究
2013-12-09 09:35:10耿风
黄河水利职业技术学院学报 2013年3期
耿 风
(黄河水利职业技术学院,河南 开封 475004)
0 引言
网络安全是现代社会稳定的重要组成部分。 入侵检测作为一种积极主动的安全防护技术,提供了对内部攻击、外部攻击和误操作的实时保护[1],可以在网络系统受到危害之前拦截和响应入侵,成为防火墙的合理补充。 但是,现有的大多数实用入侵检测系统只是将收集到的网络数据与已有的攻击模式库进行比较,从而发现违背安全策略的行为。 这种模式匹配的方法对于已知的入侵攻击检测效率很高,但对于一些未知攻击却无法准确地检测。
数据挖掘是从大量数据中提取或挖掘有用的知识,高度自动化地分析原有的数据,做出归纳性的推理,从中挖掘出潜在的模式,并预测出对象的行为[2]。 将数据挖掘技术用于入侵检测,把入侵检测看成是一个数据分析过程,通过提取出用户的行特征、总结入侵行为的规律,对于未知的入侵攻击行为进行检测,可以提高入侵检测系统的准确性、扩展性和自适应性。 数据挖掘有多种模型和算法,应用到入侵检测中的数据挖掘算法主要集中在关联规则算法、序列模式算法、分类算法和聚类分析算法,每种算法都有不同的适用范围。 本文主要研究了K-means 算法、 基于相似度的聚类算法和蚁群聚类算法,并将其应用到入侵检测系统中,通过测试数据进行实验测试、对算法进行比较,提出将聚类算法融合的思想。
1 聚类分析算法概述
聚类分析是一种无监督的学习方法。 它将一些未知模式分成若干类,若特征向量之间的距离在一定误差范围内相等,则认为它们是同一类型。 通过聚类分析,能发现新型的和未知的入侵类型。 目前,可以应用到入侵检测的聚类算法有很多,这里主要介绍K-means 算法、基于相似度的聚类算法和蚁群聚类算法。
1.1 K-means算法概述
K-means 算法是一种基于划分的算法。 若给定包含n 个数据对象的数据集和所要形成的聚类个数k,K-means 算法将对象集合划分为k 个子集(k≤n),每一个子集均代表一个聚类,聚类的结果就由k 个聚类中心来表达。 基于给定的聚类目标函数,算法采用迭代更新的方法,每一次迭代过程都是向目标函数值减小的方向进行的,最终使目标函数值取得极小值,达到较优的聚类效果。 这时,同一聚类中的对象是“相似”的,而不同聚类中的对象是“不相似”的。
1.2 基于相似度的聚类算法概述
基于相似度的聚类算法是一种无指导的学习过程,它根据聚类间的相似度来判断两个类之间的相似或相异程度,以“距离”作为相似度与相异度的度量标准[3]。 数据聚类的输入数据是一个数据集(包含了大量的数据), 每个数据用一个n 维向量X(x1,x2,x3,…,xn)来表示,数据的每一个属性值用xi表示(i=1,2,…,n)。 该算法聚类的输出是一个簇间具有最大相异度、簇内具有最大相似度的若干个聚类。
1.3 蚁群聚类算法概述
蚁群聚类算法是由模拟真实蚂蚁觅食过程而提出的[4]。 蚁群在寻找食物的过程中,每个蚂蚁通过感知信息素的存在和强度,倾向于向信息素浓度大的方向移动,使得整个蚁群的集体行为构成了信息素的正反馈过程,从而找到较好路径。 即某一路径经过的蚂蚁越多,则积累的信息素就越多,强度就越大,该路径在下一时间内被其他蚂蚁选择的概率也越大。 目前,蚁群算法已在组合优化问题求解,以及电力、通信、化工、交通、机器人、冶金等多个领域中得到应用,都表现出了令人满意的性能。
2 聚类分析算法在在入侵检测中的应用
2.1 K-means算法在入侵检测中的应用
K-means 算法具有较小的计算复杂度和良好的扩展性,还可以满足网络入侵检测对于实时性的要求。 应用K-means 算法进行入侵检测的步骤为:收集连接记录,并对其进行标准化后,获得进行聚类分析的数据集;利用K-means 聚类算法,对该数据集进行分类, 区分出哪些是正常的连接记录,哪些是异常的连接记录[5]。 其算法可描述如下:
1)输入。输入聚类个数k、包含n 个数据的数据集、阈值α。
2)输出。 标记为正常或异常的k 个聚类。
3)计算方法。
(1)任意选取k 个数据作为初始的聚类中心;
(2)do
{以数据与聚类中心值的距离最近为标准,将每个数据划分到一个聚类;
更新聚类的中心值,即重新计算每个聚类中所有数据的平均值;}
(3)while(划分不再发生变化);
(4)do
if(聚类中的数据个数>=) 标记为正常;
else 标记为异常:
(5)while(所有聚类标记结束);
2.2 基于相似度的聚类算法在入侵检测中的应用
基于相似度的聚类分析方法主要是:以给定的水平值为标准,对某一时刻收集到的原始数据进行分类,并根据分类结果,把新的检测数据关联到与其相似度最大的簇中(如果原始数据值与聚类结果存在很大的差异,那么这个新的异常数据就可能在聚类计算中产生新的簇)。 在此基础上,判断是否有入侵行为发生。 其算法描述如下:
1)输入。 原始数据集、相似度水平值α。
2)输出。 标记为正常或异常的k 个聚类
3)计算方法。
(1)随机抽样产生n 个原始数据,初始化n 个聚类;
(2)do
{计算n 个聚类两两之间的相似度,不必考虑距离方向,将相似度值表示为n 阶下的三角矩阵;
比较得出最大相似度simmax;
if(simmax>=)合并相似度最大的两簇;
n=n-1;}
(3)while(simmax<);
(4)do
if(聚类中的数据个数>=)标记为正常;
else 标记为异常;
(5)while(所有聚类标记结束);
2.3 蚁群聚类算法在入侵检测中的应用
在基于蚁群聚类的入侵检测算法中,可将数据实例视为不同属性的蚂蚁,将聚类中心看作蚂蚁所要寻找的“食物源”。 即将数据聚类过程看成一种蚂蚁寻找食物源的过程。 蚁群聚类方法最大的特点是:不需设定最终产生的聚类数目;聚类中心是动态变化的;可以发现任意形状的聚类。 该算法实质上是K-means 算法和基于蚂蚁觅食原理的蚁群聚类算法的有机结合,是对K-means 算法的一个改进。蚁群聚类算法在入侵检测中应用的算法可描述如下:
1)输入。 聚类个数k、预设聚类半径R、初始概率P0、初始统计误差、阈值α。
2)输出。 标记为正常或异常的k 个聚类。
3)计算方法。
(1)初始化聚类中心,任取不同的数据赋予Cj;
(2)do
{取不同于Cj 且未被标识过的Xi;
计算Pij;
if(Pij≥P0)标识Xi 并归到Cj;}
(3)while(所有数据均被处理);
(4)计算εj,ε0;
(5)if(>=)更新Cj 和ij 并返回2;
(6)do
if(聚类中的数据个数>=)标记为正常;
else 标记为异常;
(7)while(所有聚类标记结束);
3 实验测试与结果分析
通过仿真实验来检验3 种聚类算法在入侵检测中的检测效果。
3.1 测试条件
从KDD Cupl999 网络数据集中随机选取3 组数据样本集(包含Normal、Probe、DoS、R2L、U2R5 种类型), 每个数据集中有2 000 个正常连接、100 个异常连接,而且使异常连接的种类尽可能平均。 实验平台的主要部件为CPU 为酷睿2.8GHz、 内存容量2GB、Windows XP 操作系统、Visual C++语言环境。
3.2 测试结果分析
3 种聚类算法的入侵检测结果如表1 所示。
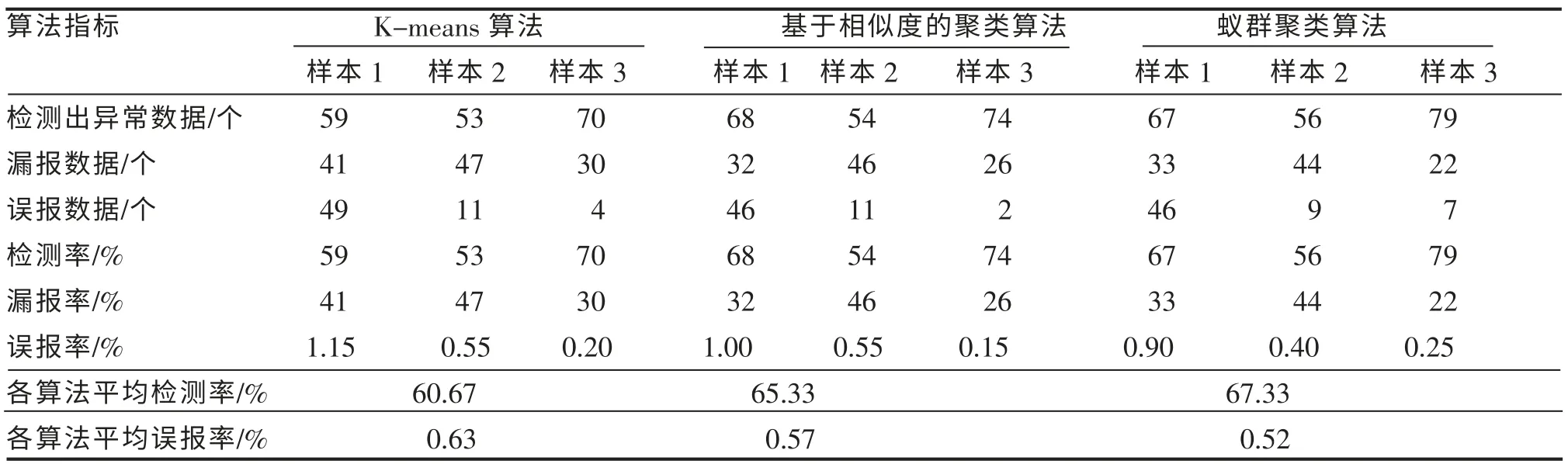
表1 三种聚类算法的检测结果Table 1 Three kinds of clustering algorithm testing results
检测率和误报率是衡量入侵检测系统的主要标准,一个好的系统应该使检测率尽可能大,而误报率则尽可能小[6]。 由表1 可知,3 种算法对于未知入侵行为的检测都是可行和有效的,但3 种检测方法相比,基于相似度的聚类算法的检测率和误报率都优于K-means 算法,而蚁群算法则更优。
4 结语
实际上,由于攻击方法的多样性及检测环境的多变性,单一使用某种算法来进行入侵检测并不能达到良好效果, 因为各种算法都有一定的局限性。因此,可以尝试将多种聚类算法融合起来,协同进行入侵检测,使各种算法都能发挥自身优势,将它们应用到适合自身特点的步骤当中,使其能互相配合、综合发挥作用,提高入侵检测系统的可行性、实时性、有效性及其稳定性。
[1] 唐正军,李建华. 入侵检测技术[M]. 北京:清华出版社,2004:26-30.
[2] HAN JIAWEI,KAMBER M. 数 据 挖 掘 概 念 与 技 术[M].范明,孟小峰,译.北京:机械工业出版社,2001:85-92.
[3] 刘学诚,李云. 基于聚类算法的入侵检测研究[J]. 计算机与数字工程,2007(9):101-103.
[4] 张惟皎,刘春煌,尹晓峰. 蚁群算法在数据挖掘中应用研究[J]. 计算机工程与应用,2004,40(28): 171-173.
[5] 李洋. K-means 聚类算法在入侵检测中的应用[J]. 计算机工程,2007,33(14),154-156.
[6] 张巍. 基于数据挖掘技术的智能化入侵检测模型[J]. 计算机工程,2005,31(8):134-136.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电子测试(2017年15期)2017-12-18 07:19:27
少儿科学周刊·儿童版(2017年5期)2017-06-29 01:27:44
电力与能源(2017年6期)2017-05-14 06:19:37
学苑创造·A版(2017年3期)2017-04-27 13:17:17
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
学苑创造·A版(2014年6期)2014-08-04 03:48:20
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
