
Hadoop平台下基于资源预测的Delay调度算法
2013-12-03 05:24:44魏晓辉付庆午李洪亮
吉林大学学报(理学版) 2013年1期
魏晓辉, 付庆午, 李洪亮
(吉林大学 计算机科学与技术学院, 长春 130012)
计算机网络技术的高速发展和应用, 带来了数据规模的爆炸式增长, 使大规模数据的处理和存储成为目前高性能计算领域的研究热点. 传统的高性能计算系统多用于处理计算密集型作业, 并不适合解决数据密集型应用问题. Google提出的Mapreduce[1]计算模型和GFS[2]分布式存储系统, 为海量数据处理和存储需求提供了全新的方法. 近年来, Hadoop作为Mapreduce和GFS模型的开源实现, 得到了广泛的应用和认可. Hadoop平台是新一代的高性能计算和存储平台, 其系统结构有别于传统的高性能计算系统[3-8]. Hadoop的系统结构具有将数据资源(HDFS)和计算资源(Mapreduce)整合的特点. 该特点使Hadoop集群资源调度过程遵循一个基本思想: 移动计算不移动数据----将计算任务派到包含要处理的数据计算节点, 即任务本地化计算(task locality). 任务调度作为Hadoop系统的重要组成部分, 直接影响作业的执行效率和机群资源利用率. 目前的Hadoop调度方法优化多基于提高Locality比例优化作业的执行效率, 从而提高系统作业吞吐量.
本文基于对机群整体计算资源合理分配的调度思想, 针对Hadoop集群数据资源和计算资源整合的特点, 提出一种资源可用性预测方法----基于资源预测的Delay调度算法(resource forecast delay scheduling, RFD). 基于该方法, RFD控制任务进行合理的等待, 提高了系统的整体作业执行效率和系统作业吞吐量. 实验结果表明, 在Hadoop一般应用场景下, 本文提出的方法在保证任务Locality比例相近的前提下, 相比Fairshare算法[9], 平均作业执行效率提高了28.8%.
1 基于资源预测的Delay调度算法
1.1 算法思想及框架
Hadoop系统中作业的本地化计算比例(Locality)是影响作业执行效率和系统资源利用率的关键因素. 因此, 如何合理控制任务进行等待, 在保证系统Locality的同时, 合理分配资源是Hadoop调度程序要解决的关键问题. 本文提出一种基于资源预测的Delay调度算法(RFD). RFD算法以计算资源可用性为依据控制任务进行合理地等待, 提高作业的运行效率和系统的整体资源利用率.
数据的非本地化计算和作业等待过长都会导致机群整体计算资源浪费, FIFO和Fairshare算法都没能很好地解决这个问题. Delay算法虽然能提高本地化运算比例, 但难以适应资源可用性动态变化. 因此, RFD调度器基于Delay思想, 针对资源实时可用性的预测进行合理地等待, 在数据非本地化计算和作业等待时间之间取得更好的平衡, 以提高机群整体利用效率.
RFD算法包含一个资源可用性预测模块, 对各作业所需的资源可用性进行预测. 每个作业的资源需求不同和依赖的数据文件不同导致同一个资源对不同的作业可用性不同. 因此, RFD中使用作业的“可用资源期望”表达集群资源对作业的可用性. 图1为RFD调度示意图, job1的可用资源期望为2, 表示在未来一个调度周期中, 将到来的含有job1所需数据的节点请求数量为2. 在RFD算法进行资源分配前, 先根据历史数据估计出作业队列中各作业的资源期望值, 即可根据可用资源期望进行作业调度. 由图1可见, job1的可用资源期望为2, job2的可用资源期望为3. 因此, 这两个作业均可在本轮调度周期进行等待. 如果此时Tasktracker2有任务请求且该节点无job1要处理的数据块, 则可以让job1等待, 调度job2在该节点的本地化运算Map任务. 若job2也无本地化运行Map任务, 则继续等待, 匹配下一个作业(如图1中Tasktracker3的任务调度). 因此, RFD算法中任务等待是依据作业的资源可用性进行的, 这样的等待不会影响作业的运行.

图1 RFD调度示意图Fig.1 Scheme of RFD scheduler
另一方面, 为了在通用环境下能够高效运行, RFD调度器引入了FIFO简单而高效的设计思路, 强调作业的先后优先级别. 在为计算资源匹配本地化计算任务时, 按作业提交顺序进行匹配, 如图2所示. 在Delay时机选择方面, 本文遵循使总体效益损失最小的原则进行调度. 图2为RFD调度器基本流程, 对于Tasktracker的任务请求, 为提高整体作业Locality计算比例, 先匹配该Tasktracker数据本地化计算的Map任务; 若匹配不成功, 为了整体作业合理等待, 则根据作业等待判断模块计算的可用资源期望决定是否等待.
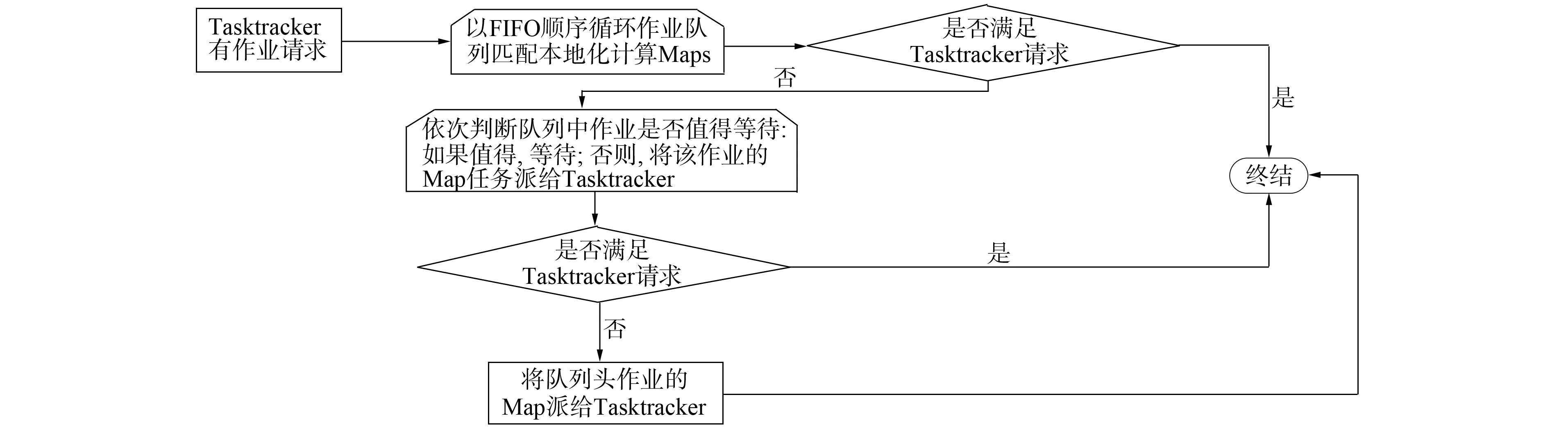
图2 本文调度算法基本框架Fig.2 Scheduling algorithm basic framework
1.2 RFD调度算法
针对RFD调度算法的需要, 本文对Hadoop系统进行如下定义:j为jobj;N为机群中的总机器数;Mj为作业j未运行的Map task;Kj为Mj未处理数据分布的机器数;TT为数据块在两个计算节点间传输所需的时间;Pj为下一个“心跳”的源机器上有jobj未处理数据块的概率:
Pj=Kj/N;
(1)
H为Jobtracker每秒钟接收的“心跳”数:
H=N/3;
(2)
S为每个Tasktracker上可运行的Map任务数;t为作业平均完成时间;Ph为某个“心跳”有作业请求的概率:
Ph=3×S/t;
(3)
Ej为在未来TT时间内, Jobtracker接收的“心跳”中, 有作业请求, 且该“心跳”的源机器上有jobj未处理的数据块的期望:
Ej=H×TT×Pj×Ph;Ej=(TT×N/3)×(kj/N)×(3×S/t)=TT×S×Kj/t.
(4)
期望Ej评判是否值得对作业j等待. 该期望值体现了一个数据块传输的时间内能收到本地化作业请求的期望, 如果Ej≥1, 表明对于该作业, 等待是值得的.
在作业进行等待的同时, RFD算法需要考虑资源竞争问题. 对于当前调度的作业, 如果在未处理的数据块机器上同样含有在它之前作业未处理的数据块, 则计算Ej时, 应考虑资源竞争的问题. 否则, 当计算该作业的Ej≥1时, 会出现与前面作业冲突, 前面的作业会占用与该作业有共同数据块的机器作业请求, 导致Ej值虚高, 容易使该作业出现饥饿. 因此, 本文引入如下两个变量:Rj为作业j与它前面作业的未处理数据块在同一台机器上的机器数; Prj为作业j与它前面作业会发生资源竞争的概率:
Prj=Rj/Kj;Ej=TT×S×Kj/t×Prj=TT×S×Rj/t.
(5)
RFD调度算法流程如下.
Begin
将作业调度队列JobQueue按提交顺序排列
assignedTasks=0; //标记已经派给Tasktracker的Map任务数
while(true)
If (assignedTasks==Tasktracker.请求作业数) then //满足Tasktracker作业请求
break;
endif
For jobiin jobQueue do
If jobi有数据块在发送“心跳”的机器上 then //Data-Local, 直接派作业
将jobi的数据本地化Map派到该机器上;
assignedTasks + +;
break;
endif
endfor
If (前面没有找到合适的Map任务) then //下面引入等待机制
For jobiin jobQueue do
根据式(7)计算作业 jobi的期望值Ei;
If (Ei<1) then //如果Ei<1, 不值得等待, 分非本地化计算的Map任务
将jobi的数据非本地化Map派到该机器上;
assignedTasks + +;
break;
Else then
continue; //等待, 调度队列中下一个作业
endif
endfor
If (前面没有找到分配Map任务) then //前面没有找到合适Map的任务
分配队首作业非本地化Map任务;
assignedTasks + +;
endif
endwhile
End.
RFD调度算法吸收了FIFO和Delay-Scheduling算法的简单高效特点, 避免了两种算法的各自缺点, 提高了作业本地化计算Map任务的比例, 同时不会产生过度的等待, 有效地提高了机群整体的资源利用率. 通过分析可知, 第一个循环以FIFO的顺序将队列中作业于请求作业的Tasktracker进行数据本地化匹配. 循环结束, 若未匹配, 则该Tasktracker在当前的情况下不能分配到数据本地化计算的Map任务. 进入算法的Delay机制, 考虑作业是否应该等待; 基于对作业的可用计算资源预测, 对作业是否值得等待进行合理的评估. 上述两次循环匹配都是基于整体计算资源的合理利用考虑. 如果还没有分配到Map任务, 则将作业队列队首的Map任务分配给Tasktracker, 这种情况较少.
2 实验结果和数据分析
2.1 实验环境及结果
实验机群由10台Dell optiple x380 PC服务器构成(英特尔酷睿4核处理器, 2 Gb内存, 200 Gb硬盘), 采用100 M以太网络相连, 实验软件采用Hadoop-0.21.0版本, 实验所用数据为某网站访问日志文件, 经过处理分成128 Mb~4 Gb不等10份样本, 实验用例是基于基本数据采样处理的Mapreduce 作业, 用于统计访问该网站的客户端IP登陆次数.
本文对FIFO算法、 Fairshare算法和本文提出的RFD调度算法进行对比实验. 为了反映真实的对比结果, 所用的实验环境、 数据分布及作业完全一致. Fairshare调度器采用默认Delay时间设置. 针对10份不同的数据样本, 每组测试6个作业. 在实验过程中, 重点关注各实验用例中作业的本地化计算任务数(比例)和作业的平均完成时间, 实验结果列于表1和表2.
由RFD算法分析可知, 调度器是否对作业进行等待取决于对资源的预测期望值Ej; 若Ej≥1, 则作业等待; 否则, 将该作业非本地化计算的Map任务派出去. 可见, 系统计算期望值Ej的准确性将对作业是否等待产生决定性影响, 若该期望值不符合机群的实际运行情况, 将导致机群计算资源的浪费, 降低作业执行效率.
由于该期望值是对未来一段时间内(TT)Jobtracker能够收到的包含某个作业未执行的Map任务要处理的数据块的Tasktracker任务请求次数. 因此, 要将在某个时刻计算的所有作业的期望值都记录下来, 对于某个作业, 记录在未来时间TT内, Jobtracker收到任务请求的Tasktracker中, 包含有该作业未处理的数据块的任务请求次数. 过了TT时刻开始输出记录每个作业真正收到的本地化计算Map任务请求; 实验测试中, 在调度器中启动一个统计线程, 该线程负责记录每个收到的命中每个作业的本地化计算Map任务请求数, 定时输出, 实验结果列于表3.

表1 作业平均完成时间(s)

表2 数据本地化计算Map任务比例(%)
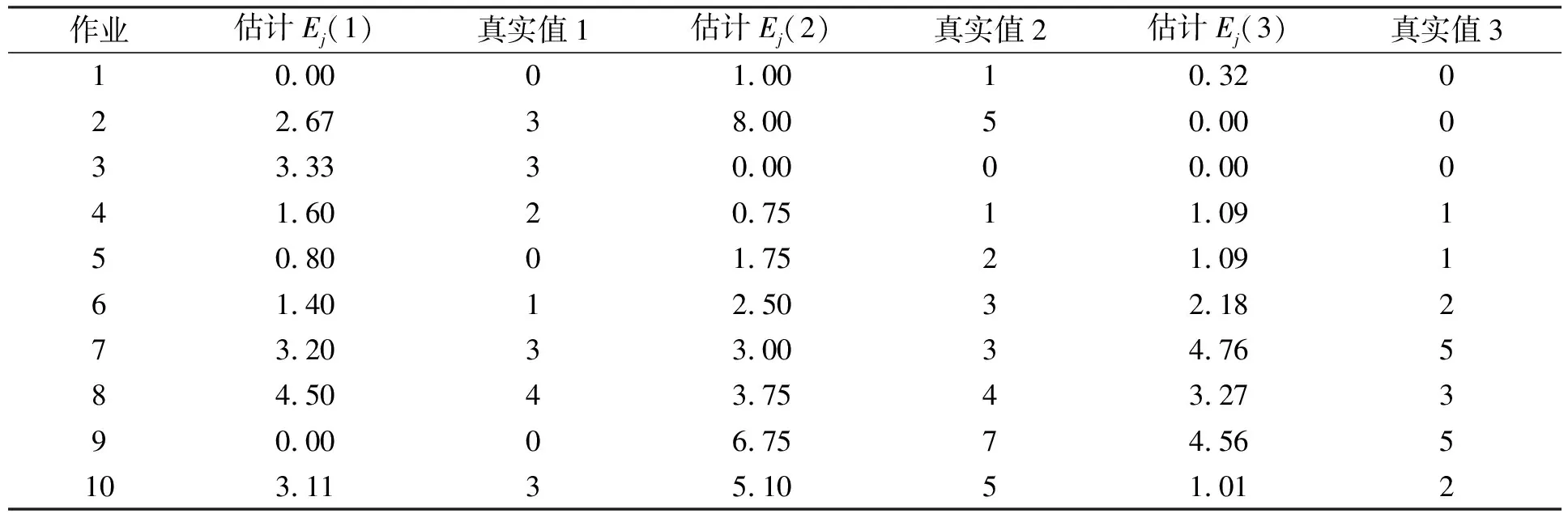
表3 资源预测准确性测试
由表3可见, 系统计算的资源预测期望值Ej与真实运行情况基本相同, 若将预测结果按四舍五入对应真实值, 预测准确度达90%以上, 表明本文基于资源预测的算法可行、 有效.
2.2 实验结果分析
实验结果可分为以下3种情况: 1) Map数为2, RFD调度器的本地化计算低于FIFO和Fairshare调度器, 作业运行时间高于后两种调度器; 2) Map任务数为4和8, RFD调度器的数据本地化计算Map任务比例和执行时间都优于FIFO, 但不如Fairshare调度器; 3) Map任务数为16~64时, RFD调度器的本地化计算Map任务比例和作业运算时间优于FIFO, 本地化计算比例与Fairshare调度器相当, 但作业执行时间优于Fairshare调度器, 如图3和图4所示. 情况1)和2)属于运行小作业的情况, Hadoop机群一般运行的作业都较大, 所以前两种情况不常见; 情况3)运行的是中型和大型作业, 是Hadoop机群实际应用中经常出现的情况, 更具代表性.
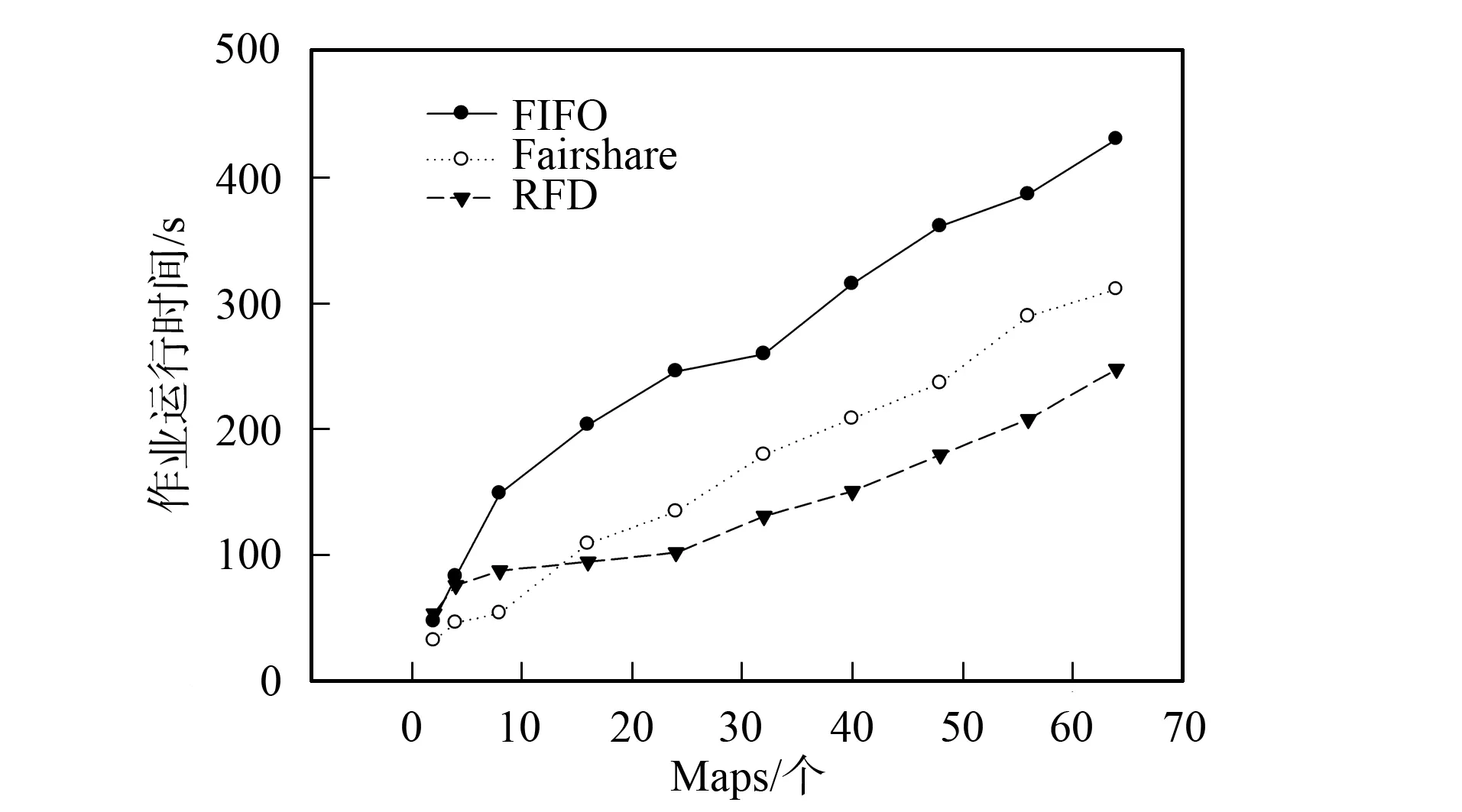
图3 作业运行时间Fig.3 Jobs’ running time
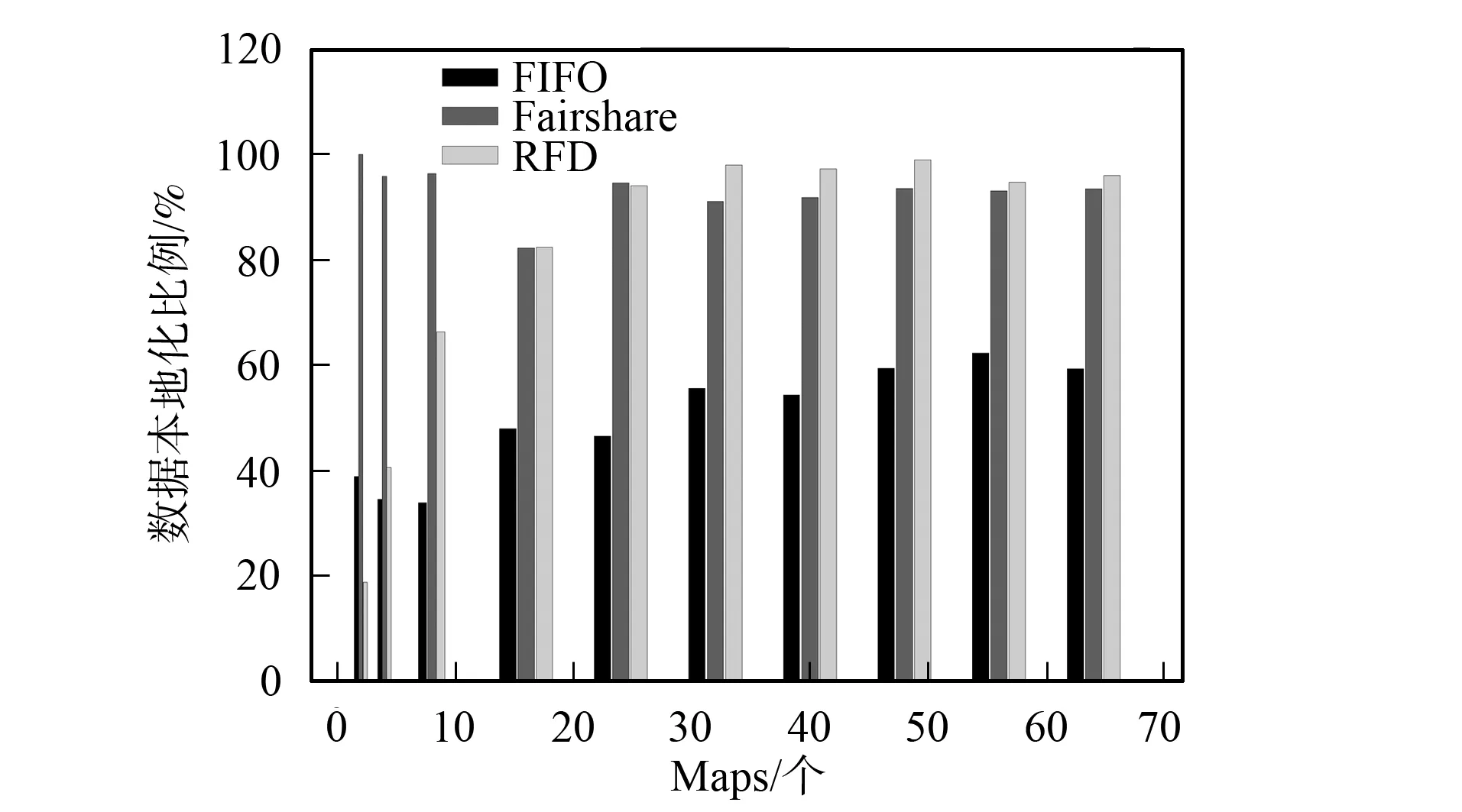
图4 Map任务本地化计算(Locality)比例Fig.4 Percentages of locality computing Map tasks
当Hadoop运行作业, 分配非本地化计算的Map任务时, 传输数据块和作业等待会导致作业运行时间增加; Delay算法是通过作业等待增加本地化计算Map任务数, 所以, 如何合理地等待是在这两者取得平衡、 降低作业运行时间的关键.
由上述分析可知, RFD算法是否等待与作业未处理的数据块分布机器数有关; Map任务数太少不会触动等待机制. 分配一个非本地化计算Map任务给某个Tasktracker会影响其他作业的本地化计算任务分配到该Tasktracker(Tasktracker上分布着多个作业数据块), 因此, Map任务较少时, RFD调度器会导致整体作业本地化计算Map任务比例低; Fairshare的等待时间是固定的4.5 s, 初始调度时, 调度器一定会收到一个Map本地化计算的作业请求(3 s就会收到Tasktracker一次“心跳”), 当Map任务数太少时, 本地化计算比例较高. FIFO调度器调度时只针对队首作业, 不会受多个作业的数据块分布在同一个计算节点的情况影响. 由图3和图4可见, 情况1)和2)中RFD调度器与Fairshare调度器相比, 在本地化计算任务比例低, 作业运行时间长; 但这两项指标优于FIFO调度器.
随着Map任务数增多, RFD调度器的等待机制被触动, 本地化计算Map任务数开始增加. FIFO调度作业时只对队首作业调度, 本地化计算Map任务数比例增长缓慢. 由图4可见, Fairshare的等待时间固定, 所以本地化计算Map任务数比例变化不大.
情况3)中, RFD调度器的本地化Map任务数比例明显上升(图3), 作业运行时间低于Fairshare调度器, 这是由于Fairshare调度器等待时机不合理所致. 若某Tasktracker没有一个作业的本地化计算数据会导致整个作业队列都在等待, 因此作业运行时间较长; RFD调度器在以动态可用资源预测为等待基础且以数据本地化调度优先, 等待时间较合理. 所以, 该情况下RFD调度器不仅本地化计算Map任务数比例较高, 且等待时间较合理, 作业运行时间也较少.
Hadoop的应用场景是处理大数据, 运行作业的Map任务数较多, 情况3)的出现概率远大于情况1)和2). 实验表明, RFD调度器在一般情况下比Fairshare和FIFO调度器的作业运行效率高, 且整体机群资源利用更合理. 根据Hadoop机群应用场景和本文的实验结果可知, RFD在一般情况下, 本地化计算Map任务数比例与Fairshare调度器相近; 但作业平均运行时间低于Fairshare调度器的28.8%.
对比实验表明, 本文提出的RFD算法与Fairshare算法相比, 一般情况下, 在保持系统高本地化作业执行比例(Locality)相近的同时, 优化了作业的整体执行效率(平均提高28%).
[1] Dean J, Ghemawat S. Mapreduce: Simplified Data Processing on Large Clusters [J]. ACM, 2008, 51: 107-113.
[2] Ghemawat S, Gobioff H, LEUNG Shun-tak. The Google File System [J]. ACM, 2003, 37: 29-43.
[3] Apache. The Oomepage of Hadop [EB/OL]. 2012-03-19. http://Hadoop.apache.org/.
[4] Shvachko K, KUANG Hai-rong, Radia S, et al. The Hadoop Distributed File System [J]. MSST, 2010, 1: 1-10.
[5] Amazon. The Homepage of s3 Distributed File System [EB/OL]. [2011-10-28]. http://aws.amazon.com/s3.
[6] Cloudstore. Cloudstore Distributed File System Website [EB/OL]. [2011-11-29]. http://kosmosfs.sourceforge.net/.
[7] GUO Dong, DU Yong, HU Liang. HDFS Based Cloud Data Backup System [J]. Journal of Jilin University: Science Edition, 2012, 50(1): 101-105. (郭东, 杜勇, 胡亮. 基于HDFS的云数据备份系统 [J]. 吉林大学学报: 理学版, 2012, 50(1): 101-105.)
[8] WEI Xiao-hui, Li Wilfred, XU Gao-chao, et al. Implementing Data Aware Scheduling on Gfarm by Using LSFTMScheduler Plugin [J]. Journal of Jilin University: Science Edition, 2005, 43(6): 763-767. (魏晓辉, Li Wilfred, 徐高潮, 等. 利用LSF调度程序的插件机制在Gfarm上实现Data aware调度 [J]. 吉林大学学报: 理学版, 2005, 43(6): 763-767.)
[9] Zaharia M, Borthakur D, Sarma J S, et al. Job Scheduling for Multi-user Mapreduce Clusters [J]. EECS Department, 2009, 55: 1-16.
猜你喜欢
科学技术创新(2021年18期)2021-06-23 07:53:06
小学生学习指导(高年级)(2021年3期)2021-04-06 08:49:44
微型电脑应用(2019年10期)2019-10-23 11:23:04
智富时代(2018年7期)2018-09-03 03:47:26
计算机测量与控制(2017年12期)2018-01-05 01:10:55
计算机技术与发展(2017年12期)2017-12-20 09:59:12
科技资讯(2017年18期)2017-07-19 09:58:51
现代计算机(2016年11期)2016-02-28 18:35:14
红土地(2016年7期)2016-02-27 15:05:54
中国卫生(2014年7期)2014-11-10 02:33:04
