
文本分类中基于综合度量的特征选择方法
2013-12-03 03:19:12杨杰明刘元宁曲朝阳刘志颖
吉林大学学报(理学版) 2013年5期
杨杰明,刘元宁,曲朝阳,刘志颖
(1.东北电力大学 信息工程学院,吉林 吉林 132012;2.吉林大学 计算机科学与技术学院,长春 130012)
随着IT应用的不断增长,人工管理文本数字信息已成为一项不可能完成的任务.自动文本分类技术是处理海量文本信息的有效方法,近年来已在许多领域得到广泛应用.目前,已有很多成熟算法应用于文本分类中,如Bayes分类器、支持向量机、决策树、K-近邻方法等.然而,文本分类中最大的特点是高维性,即使是一个并不太大的语料集,它的维度也能达到上万维甚至十几万维.在机器学习过程中,高维度会带来两方面的问题:1) 在高维环境中,大部分成熟算法不能得到高效的应用;2) 在高维环境中训练分类器时,不可避免地会产生过拟合现象[1].因此,降维成为文本分类中的一个重要研究方向.目前,降维主要有两种实现方式,即特征选择和特征提取.特征提取是在原有特征的基础上,通过组合、转换生成一组全新特征集合的技术,如特征项聚类、隐含语义索引[2]和独立分量分析[3]等.特征提取方式能捕获特征间的语义关系,但表示文本的特征不易理解、计算成本较高.特征选择算法是根据某种特征度量函数,衡量一个特征在分类中所起作用的重要度,并按重要度排序,然后根据排序结果从原有的特征集合中选择重要度最高的少数特征组成一个特征子集,最终实现文本的表示和分类器的训练.特征选择算法运算效率高、实现方便快捷,是当前文本分类中最常使用的降维方法[4-5].目前已有很多特征选择方法应用在文本分类的降维过程中,如文档频率(DF)、信息增益(IG)、卡方检验(CHI)[6-7]、正交质心(OCFS)[8]和特征质心(FCFS)特征选择算法[9]等.
本文提出一种新的特征选择算法,该算法从两方面综合度量一个特征对于分类的重要性,并在20-Newgroups,Reuters和WebKB这3个数据集上与文档频率、信息增益、卡方检验、正交质心和FCFS特征选择算法进行了对比.实验结果表明,该算法能有效提高文本分类性能.
1 问题描述及相关技术
1.1 问题描述
预先给定一个整数K,在尽可能保证文本分类性能不受影响的前提下,特征选择算法从原始的特征集合T中选择一个子集T′(|T′|≪|T|).Yang等[6]指出最佳的特征选择算法和合适的特征子集数量不但不损害分类器的性能,反而能提高分类效果.目前,应用在文本分类中的特征选择方法可分为3类,即嵌入式特征选择(embed)、融合式特征选择(wrapper)和过滤式特征选择(filtering).嵌入式的特征选择方法是将特征选择的过程直接嵌入到分类器的学习过程中,而融合特征选择方法是利用某个分类器学习算法作为特征的评价标准去选择特征子集,再利用该特征子集训练分类器.过滤式特征选择方法先利用一个独立的评价函数去度量一个特征对分类的重要程度,然后根据度量值对所有的特征进行排序,最后选择K个度量值最高的特征构成特征子集.由于易于操作、计算成本低、分类效果好等特点,因此过滤式特征选择方法应用广泛.本文提出的算法也是过滤式特征选择方法.
1.2 相关技术
1.2.1 文档频率 文档频率是一个简单而有效的特征选择算法,它计算包含某个特征的文档数量.主要思想是如果一个特征出现在很少的文本中,则该特征对分类没有用,甚至可能降低分类性能,所以该特征选择算法保留那些具有高文档频率的特征.该算法可表示为
DF(tk,ci)=P(tk|ci).
1.2.2 信息增益 信息增益是机器学习领域常用的算法.如果一个特征的信息增益值越大,则表明该特征对分类越有用.特征tk相对于类别ci的信息增益可表示为
1.2.3 卡方检验 卡方检验是数理统计学中用于度量两个变量独立性的方法.在文本分类中,卡方检验被用于确定特征tk与类别ci的独立性程度.如果χ2(tk,ci)=0,则表示特征tk和类别ci是相互独立的,即特征tk对类别ci不具有任何代表性;反之,卡方检验值越大,该特征对分类越有用.卡方检验公式定义为
1.2.4 正交质心 正交质心先计算一个特征在每个类别和在整个训练集中的质心,然后根据每个类质心与整个训练集质心计算出该特征的分值.特征的分值越大,该特征包含越多的分类信息.一个特征的正交质心公式定义为
1.2.5 FCFS特征选择算法 FCFS算法先计算特征tk出现在所有类别中的质心tck,然后将特征tk在类别ci中的特征频率与tck的偏差作为该特征度量,值越大则越具有类别代表性.FCFS算法可描述为
FCFS(tk,ci)=tf(tk,ci)-tf(tk)/|C|.
2 算法设计
目前,大多数特征选择算法都是在特征×类别矩阵的基础上进行的.在特征×类别矩阵中,行表示出现在训练集中的每个特征,列表示预定义的类别,矩阵中的元素表示某个特征出现在某一类别中的特征频率,见表1.
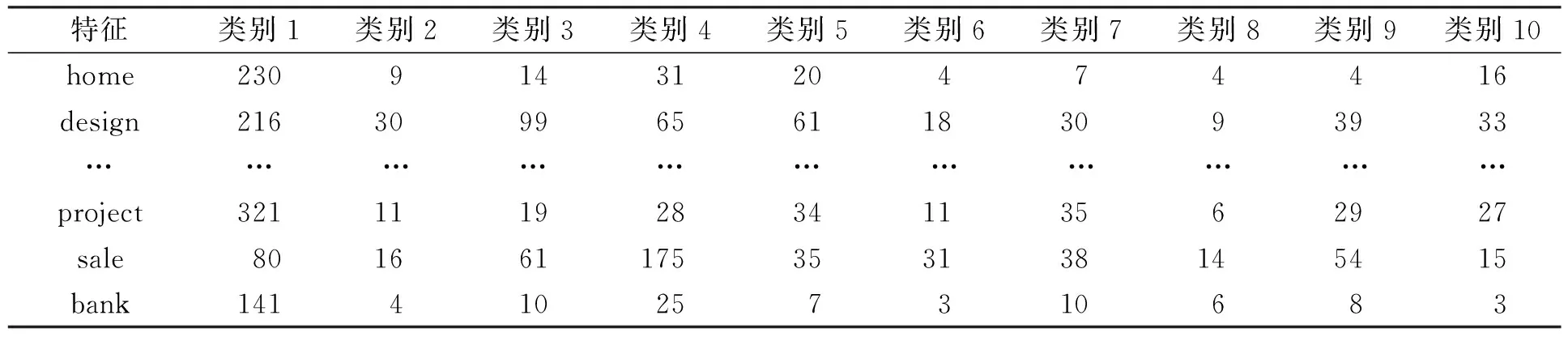
表1 特征×类别矩阵Table 1 Feature×category matrix
2.1 算法思想
FCFS算法根据一个特征在不同类别中出现的特征频率计算该特征在不同类别中的质心,然后计算该特征在某一类别中偏离该质心的距离.如果特征tk在类别ci中偏离质心的距离最大,则表明该特征tk拥有最多的类别ci信息.FCFS算法即为通过一个特征偏离类别质心的程度度量该特征在某一类别中相对于在其他类别中的重要程度.
正交质心特征选择算法首先计算所有特征在整个训练集中的质心及在每个类别中的质心,然后利用每个类别的质心和整个训练集质心计算出所有特征对分类的重要程度.正交执行特征选择算法主要是计算类别内部一个特征相对其他特征对分类的重要程度.
事实上,FCFS算法只关注了一个特征出现在某一类别中相对于出现在其他类别中的重要程度,而正交质心算法只考虑了某一类别中一个特征相对于其他特征的重要程度.上述两种算法都只分别考虑了特征×类别矩阵中的一方面,即FCFS算法只关注特征×类别矩阵的行,而正交质心只关注特征×类别矩阵的列.如表1中的特征,按照FCFS算法特征project包含类别1的信息最多,而从正交质心算法的角度看则是特征design最能代表类别1.基于上述原因,本文提出一种新的特征选择算法,该算法弥补了上述两种算法的不足,同时考虑特征×类别矩阵的行和列,综合度量一个特征对分类的重要程度.
2.2 算法描述
输入:V,D,K.其中:V表示特征×类别矩阵,包含T个特征,C个类别,矩阵中元素tf(i,j),1≤i≤T,1≤j≤C,表示第i个特征在第j类别中的特征频率;D表示类别中文本数量向量{d1,d2,…,dj},1≤j≤C,dj表示第j个类别中的文本数量;K表示要选择的特征数量.
输出:特征子集Vs.
算法如下:
1) 计算整个训练集中的特征质心向量,M={m1,m2,…,mi},其中mi表示第i个特征的质心,
3) for每个特征ti∈V;
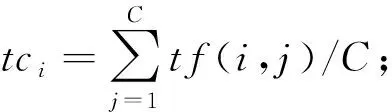
4) for每个类别ci∈C
计算特征ti在类别cj中相对于类间质心tci的偏移量,cp(i,j)=tf(i,j)-tci;
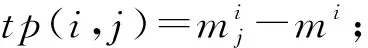
计算特征ti的总体重要性,ICFS(i,j)=tp(i,j)*cp(i,j);
end
end
5) 按照ICFS(i,j)对所有的特征进行排序;
6) 选择ICFS(i,j)值最高的K个特征构成一个新的特征集合Vs.
3 实验环境与结果
3.1 数据集
为了验证算法的有效性,本文在3个不同的数据集上进行实验验证.其中,20-Newgroups是文本分类中常采用的语料集,共包含19 997个文本,且所有的文本被平均划分到20个不同的类别中;Reuters-21578语料集中共包含21 578个路透社新闻报道,所有的新闻报道被不均匀的划分到135个类别中,本文采用文本数量最多的10个类别;WebKB语料集中包含4个不同大学网站的网页集合,8 282个网页被划分到7个不同的类别中.本文采用“course”,“faculty”,“project”和“student”4个类别作为训练集.
3.2 分类器
在实验过程中,本文使用两个不同的分类器.其中,Bayes分类器是建立在出现于一个文本中的特征与其他特征无关的假设基础上的分类算法.目前,Bayes分类器有两种常用模型: 多项式模型和多元Bernoulli模型[10].本文采用多项式模型.支持向量机是一个高效的文本分类器.本文采用libsvm工具包[11],并选择缺省参数和线性核.
3.3 评价准则
采用Micro-F1和准确率[12-14]度量本文提出特征选择算法的性能:
其中:P表示查准率;R表示查全率;TP表示正确划分为正类的数量;TN表示正确划分为负类的数量;FP表示错误划分为正类的数量;FN表示错误划分为负类的数量.
3.4 实验结果
3.4.1 Micro-F1性能比较 表2~表4分别列出了6个不同特征选择算法应用在20-Newgroups,Reuters-21578和WebKB语料集上时,Bayes分类器和支持向量机分类器的Micro-F1性能比较结果.由表2可见,当ICFS特征选择算法应用在20-Newgroups语料集时,Bayes和支持向量机的分类性能优于信息增益、文档频率和正交质心,次于卡方检验和FCFS算法.由表3可见,当ICFS算法应用在Reuters-21578语料集上时,Bayes和支持向量机分类器的性能均优于其他5个特征选择算法.由表4可见,ICFS算法应用在WebKB语料集上时,分类器的性能优于其他特征选择算法,特别是采用支持向量机分类器时.
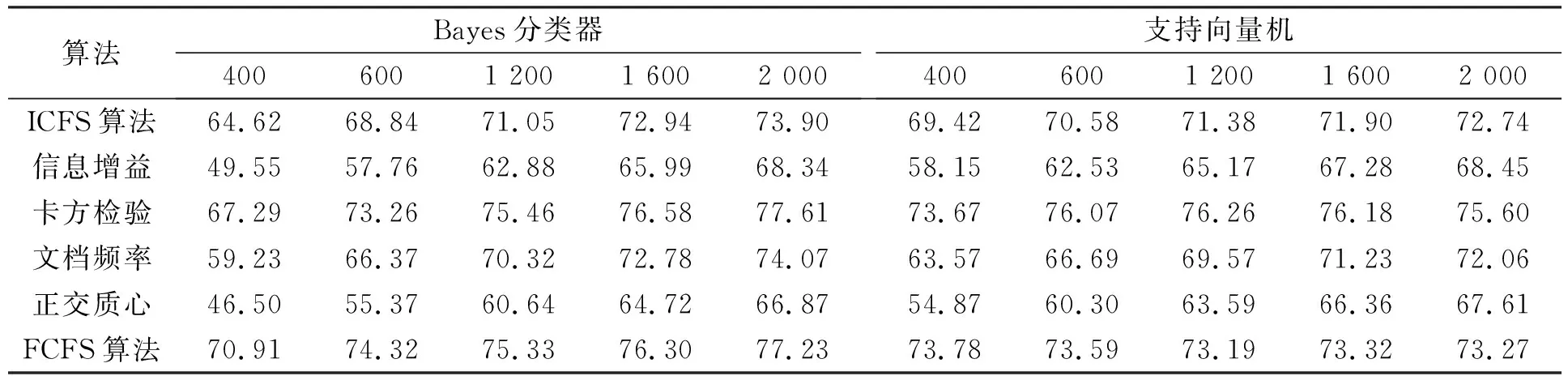
表2 6种不同特征选择算法应用在20-Newgroups语料集时Bayes分类器和支持向量机分类器的Micro-F1性能比较Table 2 Micro-F1 measure result by Naïve Bayes and SVM classifiers for 6 feature selection algorithms on 20-Newsgroups
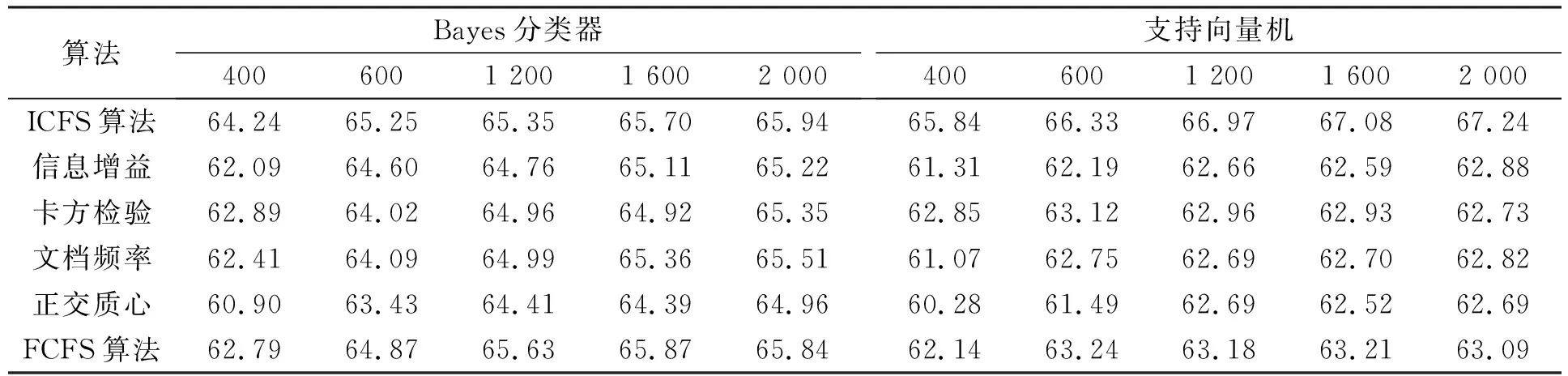
表3 6种不同特征选择算法应用在Reuters-21578语料集时Bayes分类器和支持向量机分类器的Micro-F1性能比较Table 3 Micro-F1 measure result by Naïve Bayes and SVM classifiers for 6 feature selection algorithms on Reuters-21578

表4 6种不同特征选择算法应用在WebKB语料集时Bayes分类器和支持向量机分类器的Micro-F1性能比较Table 4 Micro-F1 measure result using Naïve Bayes and SVM classifiers for 6 feature selection algorithms on WebKB
3.4.2 分类准确率性能比较 图1~图6为6种特征选择算法应用在3个不同语料集上时Bayes和支持向量机分类器的分类准确率性能曲线.由图1和图2可见,应用ICFS特征选择算法时的Bayes分类器和支持向量机分类器的准确率曲线高于信息增益、文档频率和正交质心算法,而低于卡方检验和FCFS算法.由图3可见,ICFS算法应用在Retuers-21578语料集上时,Bayes分类器的准确率曲线除了当特征数量为800~1 600时仅次于FCFS外,高于其他特征选择算法,特别是当特征数量较少时,性能的增加较明显.由图4可见,应用ICFS算法时,支持向量机分类器的分类准确率远高于其他特征选择算法,性能增加的幅度最高达到了1.6%.由图5可见,ICFS算法应用在WebKB语料集上时,Bayes分类器的分类准确率曲线整体上高于其他特征选择算法,但性能增加的幅度不大,低于0.6%.由图6可见,ICFS算法与支持向量机分类器配合应用在WebKB语料集上时,分类准确率远高于其他特征选择算法.
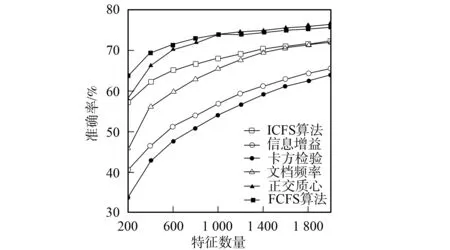
图1 6个特征选择算法应用在20-Newgroups 语料集时Bayes分类器的准确率曲线 Fig.1 Accuracy performance curves of Naïve Bayes combined with 6 feature selection algorithm on 20-Newsgroups

图2 6个特征选择算法应用在20-Newgroups语料 集时支持向量机分类器的准确率曲线 Fig.2 Accuracy performance curves of SVM combined with 6 feature selection algorithm on 20-newsgroups
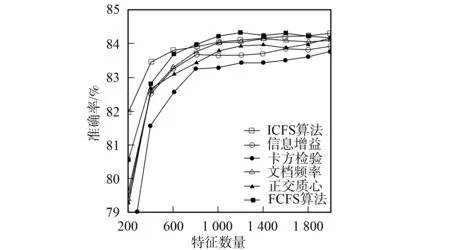
图3 6个特征选择算法应用在Reuters-21578语料 集时Bayes分类器的准确率曲线 Fig.3 Accuracy performance curves of Naïve Bayes combined with 6 feature selection algorithm on Reuters-21578

图4 6个特征选择算法应用在Reuters-21578语料 集上时的支持向量机分类器的准确率曲线 Fig.4 Accuracy performance curves of SVM combined with 6 feature selection algorithm on Reuters-21578
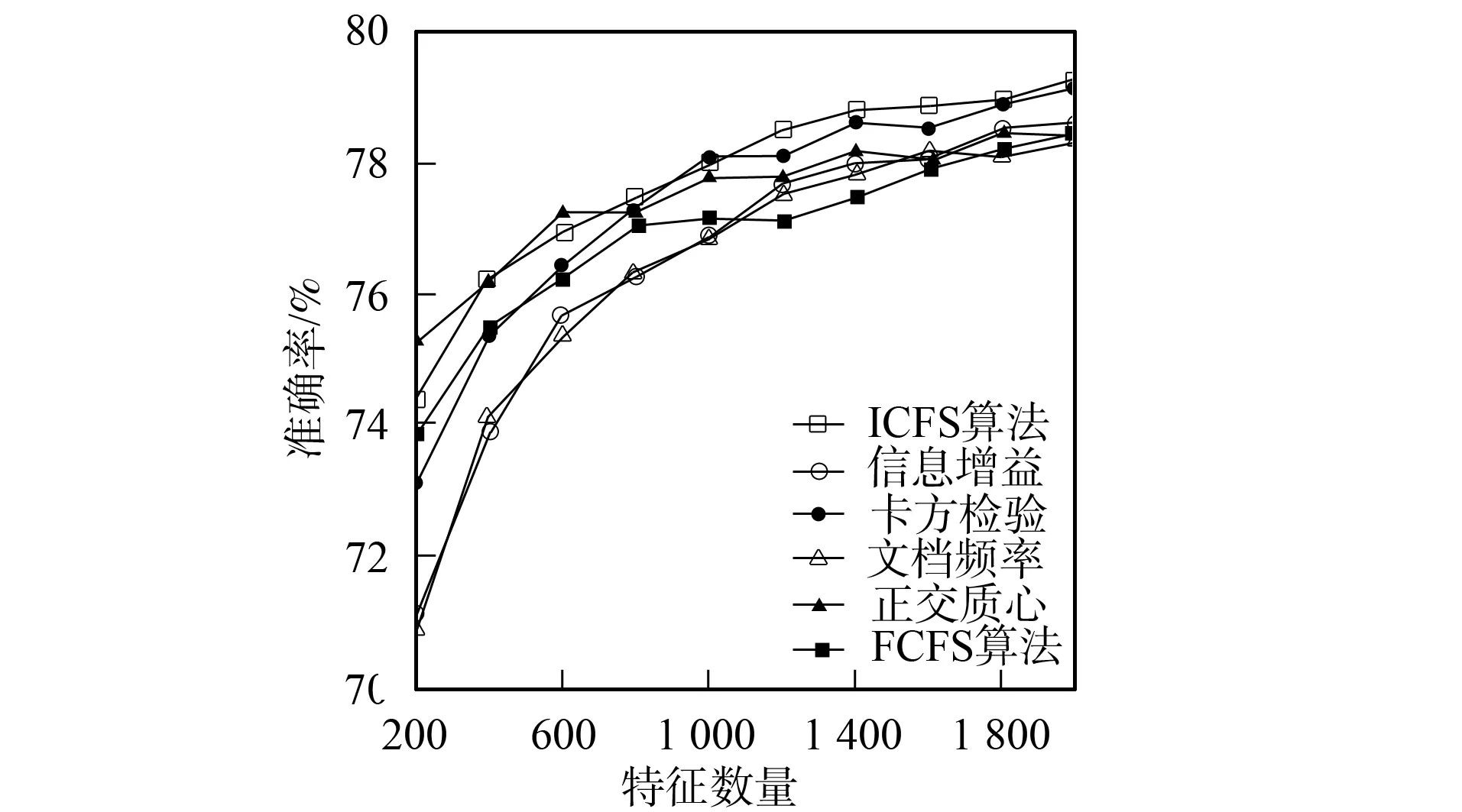
图5 6个特征选择算法应用在WebKB语料 集上时Bayes分类器的准确率曲线Fig.5 Accuracy performance curves of Naïve Bayes combined with 6 feature selection algorithm on WebKB
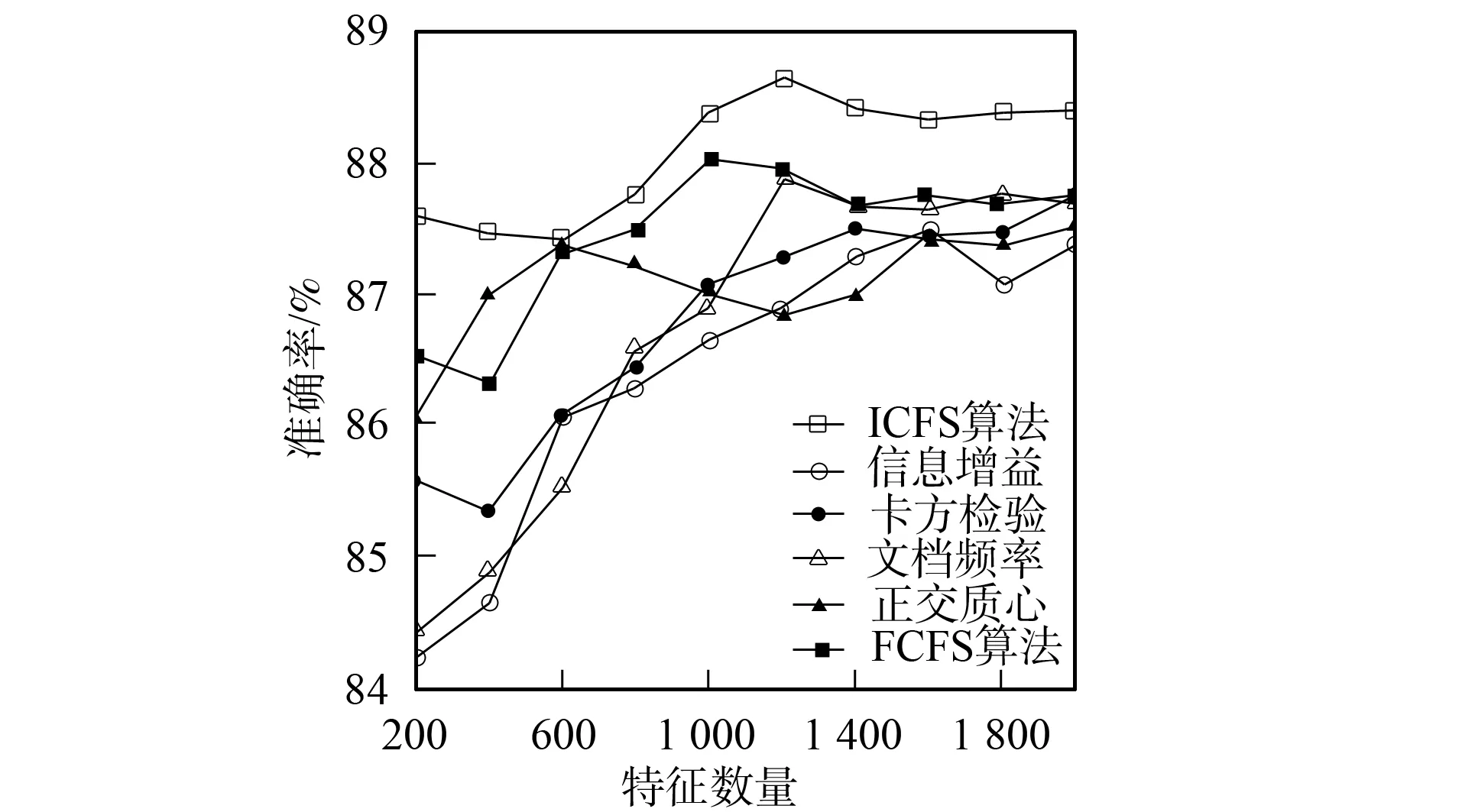
图6 6个特征选择算法应用在WebKB语料集 上时支持向量机分类器的准确率曲线 Fig.6 Accuracy performance curves of SVM combined with 6 feature selection algorithm on WebKB
由实验结果可见,本文提出的新的特征选择算法在20-Newgroups语料集上并未获得最优效果.主要是因为20-Newgroups语料集是一个平衡的语料集,而Reuters-21578和WebKB语料集都存在不同程度的不平衡性问题,所以本文提出的特征选择算法在不平衡的环境下能较好地发挥作用.
综上所述,本文提出的特征选择算法由两方面综合地度量了一个特征对分类的重要程度.实验结果表明,该特征选择算法能有效提高分类器的分类性能,特别在不平衡数据集上能产生较大幅度的性能提升.
[1] Sebastiani F.Machine Learning in Automated Text Categorization [J].ACM Computing Surveys,2002,34(1): 1-47.
[2] Deerwester S,Dumail S T,Furnas G W,et al.Indexing by Latent Semantic Analysis [J].Journal of the American Society of Information Science,1990,41(6): 391-407.
[3] TANG Lei,LIU Huan.Bias Analysis in Text Classification for Highly Skewed Data [C]//Proceedings of the 5th IEEE International Conference on Data Mining (ICDM-05).Washington: IEEE Computer Society,2005: 781-784.
[4] YANG Jie-ming,LIU Yuan-ning,LIU Zhen,et al.A New Feature Selection Algorithm Based on Binomial Hypothesis Testing for Spam Filtering [J].Knowledge-Based Systems,2011,24(6): 904-914.
[5] YANG Jie-ming,LIU Yuan-ning,ZHU Xiao-dong,et al.A New Feature Selection Based on Comprehensive Measurement Both in Inter-Category and Intra-Category for Text Categorization [J].Information Processing and Management,2012,48(4): 741-754.
[6] YANG Yi-ming,Pedersen J O.A Comparative Study on Feature Selection in Text Categorization [C]//Proceedings of the 14th International Conference on Machine Learning.San Francisco: Morgan Kaufmann Publishers Inc,1997: 412-420.
[7] Ogura H,Amano H,Kondo M.Feature Selection with a Measure of Deviations from Poisson in Text Categorization [J].Expert Systems with Applications: An International Journal,2009,36(3): 6826-6832.
[8] YAN Jun,LIU Ning,ZHANG Ben-yu,et al.OCFS: Optimal Orthogonal Centroid Feature Selection for Text Categorization [C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York: ACM Press,2005: 122-129.
[9] YANG Jie-ming,LIU Zhi-ying.A Feature Selection Based on Deviation from Feature Centroid for Text Categorization [C]//Proceedings of the Intelligent Control and Information Processing (ICICIP).Piscataway: IEEE Press,2011: 180-184.
[10] McCallum A,Nigam K.A Comparison of Event Models for Naïve Bayes Text Classification [C]//AAAI-98 Workshop on Learning for Text Categorization.[S.l.]: AAAI Press,1998.
[11] Chang C C,Lin C J.LIBSVM: A Library for Support Vector Machines [EB/OL].2011-09-03.http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[12] Forman G.An Extensive Empirical Study of Feature Selection Metrics for Text Classification [J].Journal of Machine Learning Research,2003,3: 1289-1305.
[13] WANG Gang,LIU Yuan-ning,ZHANG Xiao-xu,et al.Novel Spam Filtering Method Based on Fuzzy Adaptive Particle Swarm Optimization [J].Journal of Jilin University: Engineering and Technology Edition,2011,41(3): 716-720.(王刚,刘元宁,张晓旭,等.基于模糊自适应粒子群的垃圾邮件过滤新方法 [J].吉林大学学报: 工学版,2011,41(3): 716-720.)
[14] LIU Jie,JIN Di,DU Hui-jun,et al.New Hybrid Feature Selection Method RRK [J].Journal of Jilin University: Engineering and Technology Edition,2009,39(2): 419-423.(刘杰,金弟,杜惠君,等.一种新的混合特征选择方法RRK [J].吉林大学学报: 工学版,2009,39(2): 419-423.)
猜你喜欢
汽车实用技术(2022年14期)2022-07-30 06:24:26
北京航空航天大学学报(2021年4期)2021-11-24 01:13:12
电子制作(2017年23期)2017-02-02 07:17:06
海外华文教育(2016年1期)2017-01-20 08:21:58
西北工业大学学报(2015年4期)2016-01-19 03:31:47
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
航天器工程(2014年5期)2014-03-11 16:35:53
振动工程学报(2014年4期)2014-03-01 01:15:41
