
面向维吾尔文不平衡数据分类的特征选择方法
2013-11-30 05:02董瑞,周喜
计算机工程与设计 2013年1期
董 瑞,周 喜
(1.中国科学院研究生院,北京100080;2.中科院新疆理化技术研究所,新疆 乌鲁木齐830011)
0 引 言
由少数民族语言信息技术在不断发展,维吾尔文网页数目也随之飞速增长,相应的电子文本数目也越来越多,维吾尔文自动文本分类也越发受到重视。在文本分类中,特征空间维数过高是影响最终分类结果的重要因素。汉语大辞典中中文词条超过37万,维吾尔文词典词条超过100万,若以词为特征,将是一个非常高的特征空间。有效的特征选择算法可以很大程度上降低特征空间维数。现有的特征选择函数主要有文档频数(document frequency,DF),卡方检验(chi-square,CHI),互 信 息(mutual information,MI)等。目前,维吾尔文文本分类的研究尚少,且主要的维吾尔文自动文本分类研究都是基于平衡数据的,如文献[1-2]所述搭建了维吾尔文文本分类平台,却未考虑到维吾尔文不平衡数据问题。不平衡数据问题是指在某个分类问题中,有一些类的文本数目比另外一些多[3],通常的分类算法中都会忽略了正类(文本数目较少的类),而偏向负类(文本数目多的类)。正类和负类的不平衡比可能从1∶1到1∶100,甚至会更高。由于每个类别文档的数目不平衡,传统特征选择方法可能会导致正类被淹没,从而影响最终的分类精度,甚至导致分类器不可用。不平衡数据问题是普遍存在的,经常出现在如垃圾邮件过滤,文本过滤等自动文本分类的现实应用中。因此,维吾尔文不平衡数据集的研究非常必要且意义重大。研究表明,可以通过调整训练数据分布,改进特征选择算法,调整每个特征的权值表示方法,修改分类算法等方面来改善不平衡数据给最终分类结果带来的影响[4],本文试图从改进特征选择算法方面来解决该问题。
1 维吾尔文特性与预处理
正如中文不同于英文,需要分词处理一样,维吾尔文也有自身的语言特性。维吾尔文属于阿尔泰语系突厥语族,在结构语法上属于粘着语类型。现代维吾尔文是以阿拉伯文字为基础的拼音文字,字母共有32个,其中8个元音字母,24个辅音字母。维吾尔文字母形体因单独书写,或者在词首、词中、词尾的位置不同,而略有不同,32个字母共有126种书写形体。
维吾尔文中词与词之间采用空格隔开,不同于中文,需要进行分词。维吾尔文词通常是由词根或者词干添加词缀来构成的,词根和词干的区别在于词根可以结合构词附加成分构成新词,而词干只能和构形附加成分结合表示各种语法意义。词缀可以加在词根、词干之前,也可以加在之后。由于词缀的不同,包含相同词干的维吾尔文单词可以表示多种意思相同,但是形态、词性不同的表示方法。
这种丰富的形态变化方式使得维吾尔文的词汇量变的非常巨大,目前收集到的维吾尔文词干的数目大约为4万个,而维吾尔文词典收集到的单词数目超过100万。目前没有哪个文本分类方法可以在百万这个数量级的特征空间上表现良好,因此需要对维吾尔文文本特征空间进行降维处理。由于维吾尔文附加成分—词缀本身没有词义,可以对维吾尔文单词进行切分[5],去除不表示词义的词缀,仅使用词干和词根作为特征进行文本分类。
维吾尔文也有一些表示语气,量词等词语,对表示文本的意义没有帮助,而且出现频率较高会给分类带来噪音,因而可以去掉这些词条来降低特征维数。本文使用的停用词表是由人工收集的,共516个单词。
2 现有的特征选择方法
在统计机器学习中,特征选择就是通过选择特征空间的一个子集来构建一个好的学习模型。目前,有以下比较成熟的特征选择方法:卡方检验(chi-squared,CHI),信息增益(information gain,IG),让步比(odds ratio,Odds),文档频数(document frequency,DF)等。其中,CHI和IG在中文和英文文本分类中,分类效果要更好[6]。这些特征选择方法都是从全局的角度来度量特征,而没有考虑到不平衡数据集问题。
2.1 CHI(Chi-Squared)
CHI[7],其思想是通过观测实际值与理论值之间的偏差来确定假设理论是否成立。CHI值越大,表明相关度越高,反之相关度越小。CHI的公式如下
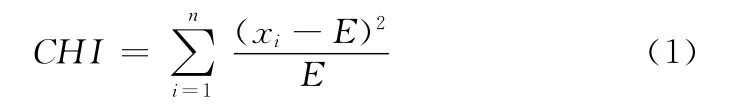
式中:E——期望,即理论值。xi——观测样本值。
设词条ti与类别Cj,那么可以按照含有词条ti的文档是否属于类别Cj的关系,得到如下关系表(见表1)。
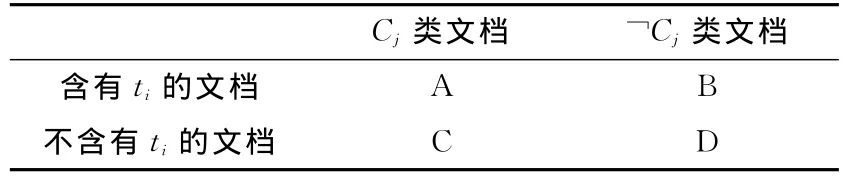
表1 词条与类别关系
其中:A指包含词条ti且属于Cj类的文档数;B指包含词条ti属于Cj类的文档数;C指不包含词条ti属于Cj类的文档数;D指不含有词条ti不属于Cj类的文档数;
CHI的化简公式为
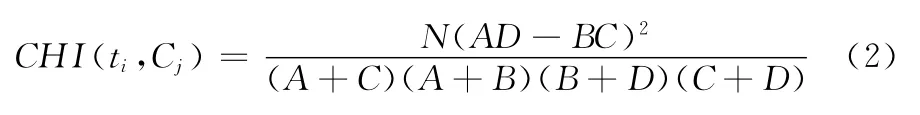
式中:n指样本集中所有的文档总数;
2.2 IG(Information Gain)
IG,IG经常被用在机器学习中,它是通过度量一个特征是否在某个文档中,看能够给分类系统带来多少信息,得到特征与类别之间的关联[8]。信息增益的公式如下
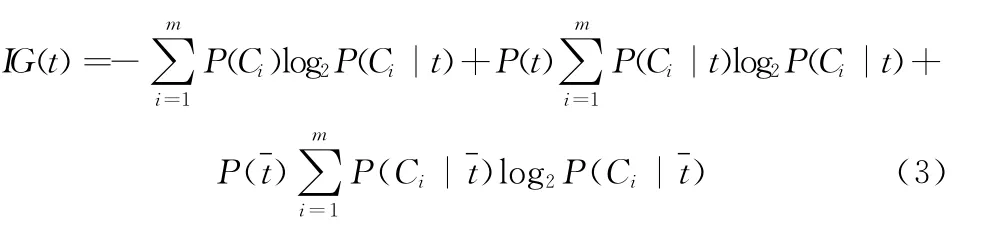
式中:t——词条,Ci——类别,P(t)——t出现的概率,m——类别数目。
3 改进的特征选择方法
CHI和IG在英文文本分类中相对于DF,MI来说,有更好的分类精度。但是这两种特征选择方法都有其缺点。CHI只考虑一个词特征是否出现在文档中,而忽略了词频信息,这就可能偏袒低频词,即 “低频缺陷”;IG考虑了一个词特征是否出现在某个文档中,但是IG只是从全局的角度出发,度量所有的特征词进行选择,没有考虑每一类中具有代表性的特征词。
由于不平衡数据集中正类的数目会远远少于负类,从而被负类淹没,而CHI和IG都是通过对比训练样本中所有的词,挑选相关度最高的特征,而忽视了那些能够更好的表示某一类别的特征词。试想一个极端的例子,如果正类中只有一篇文章,负类中含有无穷多的文档数,那么即使正类中的特征对于区分正类负类有着非常重要的作用,最终也会被忽略。
造成这一结果的原因在于正负两类文档数目偏差过大,使得正类被淹没,因此试图找到一个合适的方法,用来抑制负类文档数目过多这一问题。考虑idf(inverse document frequency)逆文档频数,即文档频数的倒数。由于负类的文档数目很多,那么能够很好的表示负类的词的文档频数也会较高,从而其idf值就会较小;对于能够很好的表示正类的特征词,由于正类的总文档数目较少,该特征词的idf值就会较大;对于在所有类别集合中都多次出现的特征词,这类特征词可能对分类没有特别大的帮助,如停用词等,其idf值也会较小。如上文所说,idf可以平衡出现在负类中文档频数较高、在正类中文档频数较低、以及整体数据集中文档频数较高的问题,从而使得所选择的特征更加合理。单一的使用idf进行特征选择效果并不理想[9],而多种特征选择方法想结合可能会得到更好的分类精度[10-11]。考虑将现有的特征选择方法和idf相结合,以提高维吾尔文不平衡数据集文本分类的分类精度。
综上所述提出一种改进的特征选择方法,CIDF——卡方检验和逆文档频数相结合的方法。
平滑后的idf公式为
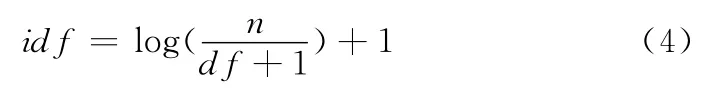
式中:n——训练集中总得文档数,df——文档频数。
CIDF公式如下
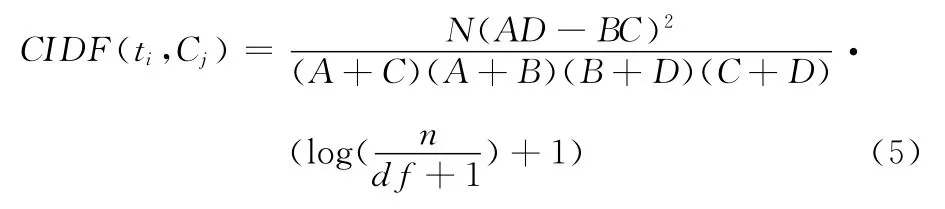
4 实验与分析
4.1 分类器
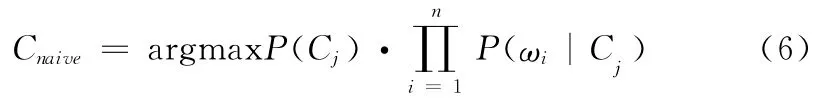
式中:C——类别集合,Cj——类别,P(Cj)——类别Cj出现的概率,P(ωi|Cj)——词条ωi出现在Cj中的概率。
4.2 数据集
由于维吾尔文文本分类的研究还处于初级阶段,没有一个统一的语料库,因而首先建立维吾尔文语料库。由于人民网维吾尔文版块的内容较为正规,方便整理,本文爬取了人民网维吾尔文新闻版块的内容,作为语料库。选取两类新闻网页作为不平衡数据集,类别信息表见表2。

表2 类别信息
实验数据共分9组,按照正类和负类的文档数目比例从1:10到9:10分组,其中负类的训练样本数目为948篇,正类的数目按照比例设定。测试样本,正类626篇,负类608篇,每组的测试样本都相同。
4.3 评价方法
目前主要的文本分类评价方法有3个[12],如下
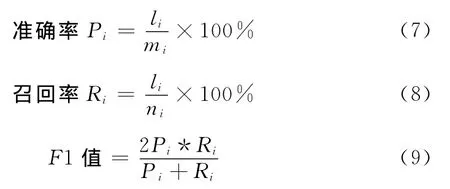
式中:li——分类的结果中被标记为第i个类别且标记正确的文本个数,mi——结果中表示被标记成第i个类的文本个数,ni——被分类的文本中实际属于第i个类别的样本个数。
由于不平衡数据集中正类的数目远远少于负类,选择准确率或者召回率作为评价标准容易忽视正类的性能,从而无法很好的表示不同特征选择算法对不平衡数据的影响。而F1值综合考虑的准确率和召回率,只有两个值都比较高的时候才能取得较好的F1值,F1值越高说明分类结果越好。本文选择宏平均F1作为评价公式
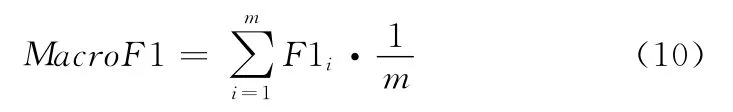
式中:F1i——第i类的F1值,m——总的类别数。
4.4 实验结果
为了能够更加直观的了解分类性能,分别从不同平衡比和不同特征维数两个方面描述实验结果。
图1是当特征维数为1000时,正类和负类不同比值的F1值图。对于CHI和IG来说,在高不平衡比的训练中,由于正类被负类淹没,使得正类的F1值趋近于0,这样使得整体的宏F1值变小,而文本提出的CIDF方法,由于使用idf抑制了负类的高文档频数,使得分类结果明显高于其它两种特征选择方法。当正类和负类的比值接近1:1时,3种特征选择方法的分类结果变得非常相似,这是因为由于两类的文档数目接近,使得idf失去作用,进而还可能使得分类精度下降。
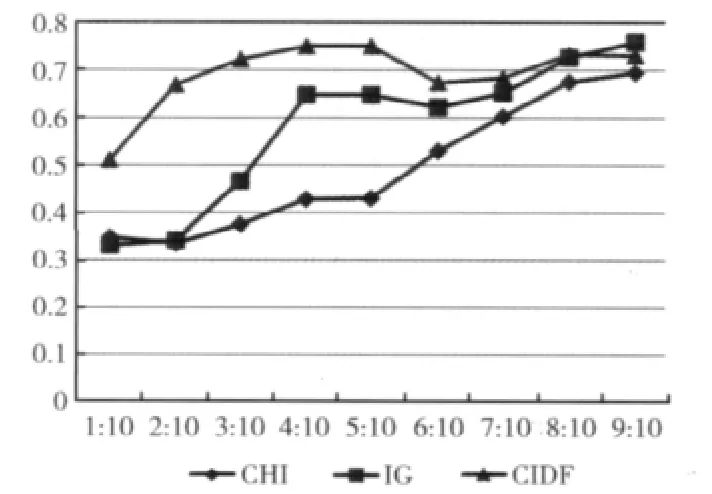
图1 特征维数为1000时的不同平衡比的F1值图
图2是正类和负类的文档数目比在3:10时的不同特征维数的F1值图。CIDF特征选择方法在不同维数都优于CHI方法。在低维空间时IG的分类结果高于CIDF,从400维开始,CIDF特征选择方法的结果开始高于IG方法,并且分类结果较为稳定,可以看出IG方法在特征维数增加的情况,下降很快。从上图得知,CIDF总体要优于CHI和IG方法。
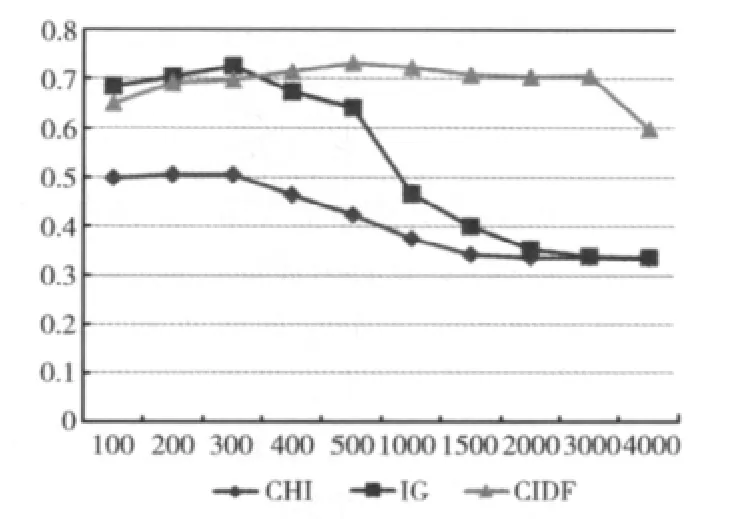
图2 不平衡比为3∶10时的不同维数F1值图
5 结束语
本文论述了维吾尔文的语言特征和不平衡数据集特有的问题,将CHI和IDF相结合,提出一种针对维吾尔文不平衡数据集的特征选择方法CIDF。使用宏平均F1值作为评价标准。实验证明该方法在维吾尔文不平衡数据集文本分类问题上优于CHI和IG这两种特征选择方法。在后续研究中,会继续完善维吾尔文语料库,寻找新的针对维吾尔文不平衡数据集的权重计算方法,通过分析和改进维吾尔文文本分类的各个环节,提供其在不平衡数据集上的分类精度。
[1]Alimjan AYSA,Turgun IBRAHIM.Machine learning based Uyghur language text categorization[J/OL].Computer Engineering and Applications,2012,48(5):110-112(in CHinese).[2011-07-14].http://www.cnki.net/kcms/detail/11.2127.TP.20110714.1549.012.html(in Chinese).[阿里木江·艾沙,吐尔根·伊布拉音.基于机器学习的维吾尔文文本分类研究[J/OL].计算机工程与应用,2012,48(5):110-112.[2011-07-14].http://www.cnki.net/kcms/detail/11.2127.TP.20110714.1549.012.html.]
[2]Halqam Aisa,Winira Musajan.Study on web document classification of Uyghur,Kazak,Kirgiz multi-lingual search engine[J].Journal of Xinjiang University(Natural Science Edition),2010,28(3):362-365(in Chinese).[海丽且木·艾莎,维尼拉·木沙江.维、哈、柯多文种搜索引擎中web文本分类的研究[J].新疆大学学报(自然科学版),2010,28(3):362-365.]
[3]Nitesh V Chawla.Data mining for imbalanced datasets:An overview[M].Springer,2010:875-886.
[4]LI Jun.Research on the imbalanced data learning[D].Changchun:Jilin University,2011(in Chinese).[李军.不平衡数据学习的研究[D].长春:吉林大学,2011.]
[5]XUE Huajian,DONG Xinghua,WANG Lei,et al.Unsupervised Uyghur word segmentation method based on affix corpus[J].Computer Engineering and Design,2011,32(9):3191-3194(in Chinese).[薛化建,董兴华,王磊,等.基于词缀库的非监督维吾尔语词切分方法[J].计算机工程与设计,2011,32(9):3191-3194.]
[6]YANG Fenqiang,LIU Yugui.A new feature selection method based on class-concept in text categorization[J].Computer Systems & Applications,2009,18(10):93-96(in Chinese).[杨奋强,刘玉贵.文本分类中基于类别概念的特征选择方法[J].计算机系统应用,2009,18(10):93-96.]
[7]PEI Yingbo,LIU Xiaoxia.Study on improved CHI for feature selection in Chinese text categorization[J].Computer Engineering and Applications,2011,47(4):128-130(in Chinese).[裴英博,刘晓霞.文本分类中改进型CHI特征选择方法的研究[J].计算机工程与应用,2011,47(4):128-130.]
[8]LIU Ting,QIN Bing,ZHANG Yu,et al.Information retrieval system introduction[M].Beijing:China Machine Press,2008:186-204(in Chinese).[刘挺,秦兵,张宇,等.信息检索系统导论[M].北京:机械工业出版社,2008:186-204.]
[9]Pui Cheong Gabriel Fung,Fred Morstatter,Huan Liu.Feature selection strategy in text classification[C]//Shenzhen:The 15th Pacific-Asia Conference on Knowledge Discovery and Data Mining,2011.
[10]Scott Olsson J,Douglas W Oard.Combining feature selectors for text classification[C]//Virginia:Proceedings of the 15th ACM International Conference on Information and Knowledge Management,2006.
[11]Robert Neumayer,Rudolf Mayer,KjetilCombination of feature selection methods for text categorization[C]//Berlin,Heidelberg:Proceedings of the 33rd European Conference on Advances in Information Retrieval,2011.
[12]YANG Ming,YIN Junmei,JI Genlin.Classification methods on imbalanced data:A survey[J].Journal of Nanjing Normal University(Engineering and Technology Edition),2008,8(4):7-12(in Chinese).[杨明,尹军梅,吉根林.不平衡数据分类方法综述[J].南京师范大学学报(工程技术版),2008,8(4):7-12.]
猜你喜欢
客联(2022年3期)2022-05-31
小猕猴智力画刊(2021年6期)2021-08-05
中国新闻周刊(2021年26期)2021-07-27
自动化学报(2017年5期)2017-05-14
电脑爱好者(2017年7期)2017-05-06
电子制作(2017年23期)2017-02-02
中国民族医药杂志(2016年5期)2016-05-09
作文大王·低年级(2016年3期)2016-03-11
智能系统学报(2015年4期)2015-12-27
