
基于网络计算的心电仿真计算研究
2013-11-30 05:02:02沈文枫郑衍衡徐炜民
计算机工程与设计 2013年1期
李 波,沈文枫,郑衍衡,徐炜民
(上海大学 计算机工程和科学学院,上海200072)
0 引 言
心电仿真计算需要高性能计算环境,心电计算机仿真计算是心脏生物电现象研究中的一个重要课题[1],随着计算机计算能力的提高,心电活动的计算机仿真也随着迅速发展。但是对于心脏模型的仿真计算,要求在空间上达到高分辨率、在计算上达到高精度,需要巨大的计算量,必须采用并行计算[2]。到目前为止,绝大部分的这类计算是在高性能计算机系统中采用(message passing interface,MPI)。GPU用于高性能计算,使得在高校和研究机构内部大量的PC机在计算性能上有很大的提高。利用这些PC机的空闲时间进行计算,可以代替昂贵的高性能计算机,廉价的、快速的实现心电仿真计算。
本文提出采用由PC机中的CPU和GPU组成异构网络计算的方案,利用空闲的PC资源,实现心电仿真计算,并且提出了面向短的响应时间要求的调度算法,取得了很好的效果。
1 相关工作
Tusscher等进行心室传导系统的模拟模型,采用C++和MPI,是在由10台Dell650Precision服务器,每台服务器用双核Intel Xeon 2.66GHz CPU组成的Beowolf集群式系统上运行的[3]。Reumann et al。在配置有512、1024、2048、4096个节点的IBM Blue Gene/L上,进行了大规模的心脏模拟[4],这两篇文章表明心电仿真主要在昂贵的高性能计算机系统上进行,在器件上都没有采用GPU。本文研究在由CPU和GPU组成的网络计算系统上运行心电仿真。Wenfeng Shen et al.研究了在多核和GPU上进行心电仿真的并行计算[1,5],是在多核CPU和GPU组成的单机系统中的并行处理。本文研究的是CPU和GPU在多机系统中的并行处理。
在本文所采用的网络计算系统的体系结构上,和著名的Bonic系统是相近的,但是有两个不同点:①本文所研究的系统对于响应时间方面的要求比较高,这是和Bonic系统的主要差别。Bonic系统的调度程序以高吞吐率为出发点,追求公平性和高效率,在Bonic系统中,如果引入短的响应时间的要求,会影响公平性和高效率[6]。我们研究的心电仿真计算的要求是较短的响应时间,因此对于调度算法提出了不同的要求。②计算规模比较小,主要应用在高校和研究单位内部,对于提交的作业采取先提交先服务的策略,在运行时,独占全部可用资源,要求每一个作业的运行时间尽量短,可以减少作业的平均等待时间,相当于提高了系统的计算速度[7-8]。同时,计算资源来自部门内部,可以获得各个处理器的计算性能,为设计面向较短的响应时间的调度程序提供了条件。
2 心电仿真计算原理及其算法
心脏的计算机模型一般是通过对心脏断面图像离散化并进行空间插补,本论文所采用实验模型为日本魏氏全心脏模型[9-10],该模型是由一个56*56*90的斜交坐标系构成。模型上部为心房,下部为心室,模型细胞在空间上是等距的,直径为1.5ms。模型的实际细胞数据为5万个,通过使模型细胞具有方向性和具有和实际细胞相近的电生理特性,在解剖学和电生理学两个方面对模型作进一步的修饰使得模型更加接近实际的心脏。
2.1 心电仿真算法
心电计算机仿真的核心便是心脏兴奋序列的计算机仿真,所用算法是其关键所在,直接决定了计算的速度和仿真的效果,并影响到模型的实用性和仿真结果。在心电兴奋传播的过程中,算法的目标是在每一个计算过程中确定未兴奋的心肌细胞时候接受临近的已兴奋心肌细胞的兴奋传播而开始其自身的兴奋过程。
心电计算的仿真算法主要分为三步:第一步是以惠更斯原理模型为基础,仿真心电兴奋传播的过程。第二步是根据传播过程中记录的偶极子数目,计算心电图的容积导体和体表电势。第三步是保存计算结果。其中第二步计算容积导体和体表电势占用了整个计算机仿真过程的绝大部分时间。在体表躯干表面,心内膜和心外膜等四边边界大约3800三角形元素的电势计算,产生大概50000个电偶极子源。容积导体中每个三角元素是异势的。根据特定方程,从当前偶极子源采用边界元方法计算的体表电位,心外膜和心内膜。如图1所示。
电势计算方程如下
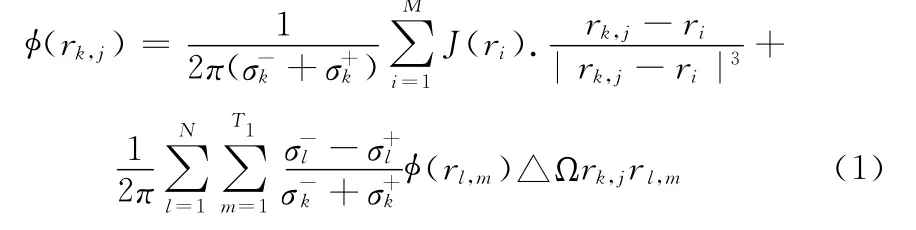
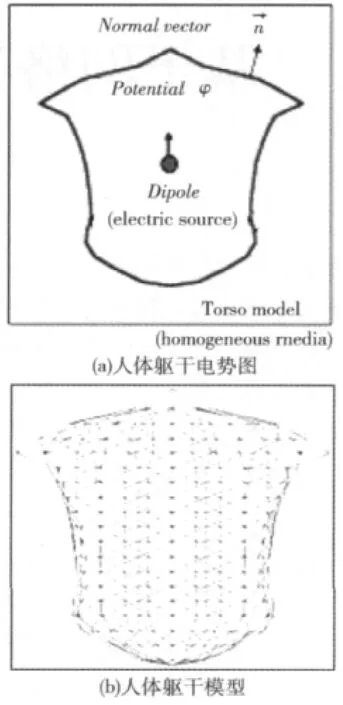
图1 人体躯干
式中:(rk,j)——在第k个表面上的第j个三角的体表电势值,rk,j——中央位置向量。-号和+号分别代表内部和外部信号。M则代表细胞模型的当前偶极子数目,J代表偶极子源。在整个容积导体中体表、体外膜表面、右心内膜表面和左心内膜表面分别被划分为344,1002,307,278个节点和684,2002,610,552个三角形。心电仿真计算主要是对方程(1)进行计算机分解计算,求得计算结果。
2.2 心电仿真计算流程图
心电仿真计算流程如图2所示。
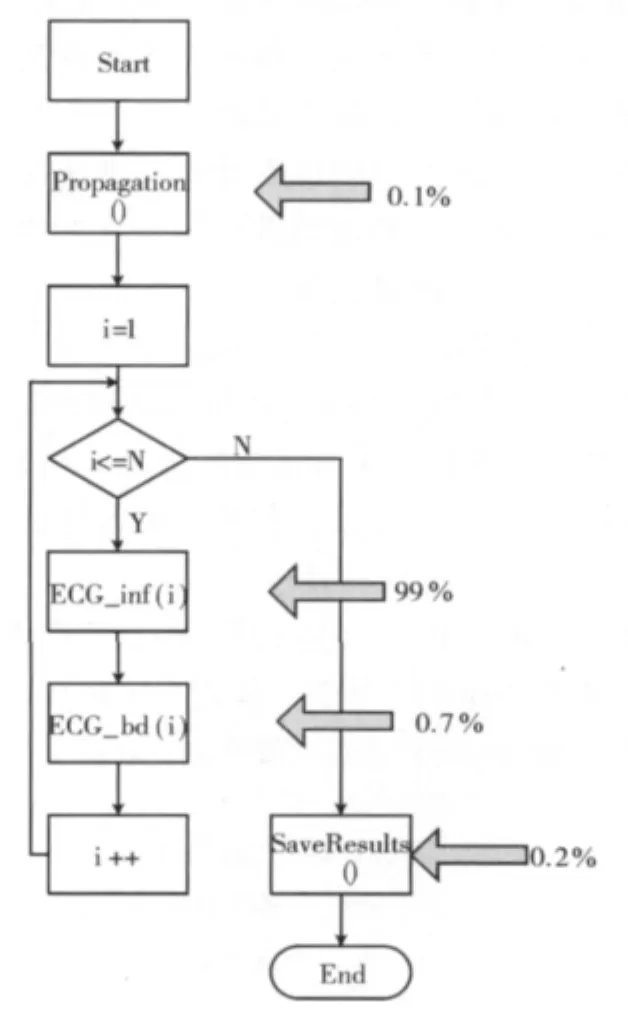
图2 心电仿真计算流程
通过实验验证,对算法中每一步计算作时间分析,得到如下结果:在第一步的传播过程中,所占时间为整个计算机仿真过程的0.1%,第二步的电势计算占总仿真时间的99.7%,保存结果大概占总时间的0.2%。因此主要从第二步计算电势来考虑,寻求最优并行化。第二步是根据传播过程中记录的偶极子数目,计算心电图的容积导体和体表电位。由于心电计算的特殊性质,在每3ms的时间周期内所计算的偶极子数目不尽相同。每个周期的电势计算只和这个周期产生的偶极子数目相关,一般情况下产生的偶极子数目越多,电势计算所花费时间就越多。而偶极子数目在第一阶段的兴奋性传播过程中便可以统计出来,通过合理的分析可以预测计算负载,为调度算法创造了条件。
3 异构网络计算的结构
3.1 心电仿真计算在计算结构上的特点分析
心电仿真计算在计算结构上有以下的特点:高度并行,占总仿真时间99.7%的计算是高度并行的,计算模块之间的相互通信量非常少,各个模块完全可以独立计算。非常适合利用网络计算。各个模块的计算量是可以预测的。为在网络计算中实现定量调度提供了条件。
3.2 异构网络结构介绍
异构网络结构如图3所示。
图3 异构网络结构
整个网络由多台的四核处理器、八核处理器、GPU处理器组成。这个网络环境在高校的实验室和研究所的研究室还是有比较大的代表性。
4 调度算法
调度算法的目标是达到按照各个服务器处理速度的比例分配任务,达到这个目标的方案很多,最简单的方案是依照处理器的计算能力按比例进行分配,但是GPU用作高性能计算时,它的性能是随着被处理的程序的并行程度变化的,因此在调度程序中要尽量使得计算量大(并行度高)的模块分配给GPU计算。图4是Geforce440GPU的处理速度随着处理模块的偶极子数量变化曲线。
调度算法的执行步骤如下:
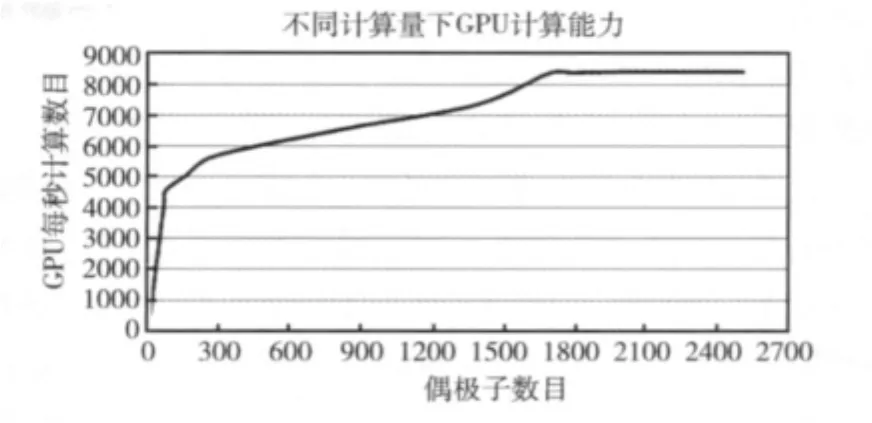
图4 Geforce440GPU的处理速度与处理模块偶极子数量的关系
设不带有GPU的处理器有m台,带有GPU的处理器有n台。
(1)把总计算量按照CPU和GPU的计算能力分二大类,以保证异构系统中GPU的能力得到充分发挥。然后,在分类内部按照处理器能力分配计算量。步骤如下:
1)求出需要计算偶极子的总量,用Q总计算量表示。
2)对于各个CPU和GPU种类,用实验方法获得每类的计算能力(单位时间内可以计算的偶极子数量),CPUi计算能力和GPUi计算能力 表示分别表示第i个CPU和GPU的计算能力。按照降序排序,i=1,表示计算能力最强。
3)把异构系统中的计算机处理能力,按照CPU和GPU分为两类,对两类处理器能力分别进行统计,CPU总计算能力和GPU总计算能力分别代表CPU处理器和GPU处理器总的计算能力。
4)把计算总量为Q总计算量分配给CPU处理器和GPU处理器,用CPU总计算量和GPU总计算量表示CPU处理器和GPU处理器所承担的总计算量。则GPU总计算量:CPU总计算量=GPU总计算能力:CPU总计算能力,GPU总计算量+CPU总计算量=Q总计算量
5)按照计算能力的大小计算每个处理器所分配的计算量,用CPUi计算量表示分配给第i类CPUi的计算量,i=1,2…m。GPUi计算量表示分配给第i类GPUi的计算量,i=1,2…n。则CPUi计算量=CPU总计算量*CPUi计算能力/CPU总计算能力。同样,GPUi计算量=GPU总计算量*GPUi计算能力/GPU总计算量。
6)对偶极子计算任务按照计算量进行降序排序,并且划分成Q1,Q2…QN,其中N=n(GPU处理器数)+m(CPU处理器数)。使得 Qi=GPUi计算量,i=1,2…n,Qn+I=CPUi计算量,I=1,2…m。
(2)对于GPU1处理器,按照偶极子计算量的降序逐个模块提交,对于CPUm处理器,按照偶极子计算量的升序逐个模块提交。对于其它的GPUi处理器(i=2,3…n)和CPUi处理器(i=1,2…m-1)按照偶极子计算量的中间优先,逐步向二边交叉延伸。这样的提交次序,便于在计算的最后阶段,把剩余计算的任务向邻居节点转移。
(3)网络计算的特点之一,是在运行过程中会发生增加或者减少处理器的情况,此时,按照以下步骤进行:
1)计算出还没有提交的任务(包括在减少的处理机中被中断并且取消的任务)的剩余总计算量,设定为Q剩余总计算量。并且按照新的系统配置情况计算出到全部任务执行完成还需要多少时间,设定为T剩余总计算时间。
2)计算出正在正常运行的各个处理器i当前的任务结束还需要多少时间,设定为T i剩余计算时间,修改处理器i的计算能力为CPUi新计算能力=CPUi计算能力×(1-T i剩余计算时间/T剩余总计算时间),对于GPU处理器也同样处理。
3)按照新的系统配置情况,使用调度程序计算各个处理器需要承担的任务。由于各个处理器的剩余计算量是不同的,因此各个处理器的新计算能力也是各不相同的,原有的分类将取消,每个处理器都单独成为一个类。
(4)当某一处理器k结束自身计算任务,同时k-1或者k+1处理器还有多个任务等待,可以把相应的计算任务迁移到处理器k上。直至整个系统计算任务结束为止。
(5)在开始计算过程以后,需要密切注意GPUn计算速度,如果发现GPUn速度低于期望值很多时,则表示在GPUn中,计算了大量的小任务,使得GPU计算速度下降。从我们分析偶极子计算量的分布情况来看,70-80%的偶极子模块计算时,GPU处理器的计算速度基本上保持着最佳状态,也就是说,只要在网络计算系统中,CPU处理器的计算量超过20%,我们所提出的调度算法是可以获得最佳结果的。我们认为在高性能计算中,这种情况是有典型性的。当然如果在极端情况下,计算任务中包含了大量的小任务,迫使GPU处理器承担了很多小任务,由于我们的调度算法在分配GPU处理器和CPU处理器承担的计算量时,是按照GPU处理器在处理大任务情况下的性能。当GPU处理器需要处理大量小任务时,完成所分配的任务需要的时间将会超过预定时间,适当把分配给GPU处理器的任务迁移到CPU处理器。在迁移的过程中,可以参照步骤(3)的方法。
5 实验结果
实验环境:
CPU处理器:Intel(R)Core(TM)i7CPU 920@2.67GHz双核。
GPU处理器:NVIDIA GeForce 9800GT。
实验内容:
(1)采用3种不同配置,如下:
配置1:CPU处理器10台,GPU处理器30台。
配置2:CPU处理器20台,GPU处理器20台。
配置3:CPU处理器30台,GPU处理器10台。
(2)在每个配置上,采用二种不同算法,如下:
算法1:本调度算法。
算法2:先到先服务算法,有多个空闲处理器时,选用性能最高的处理器。
(3)输入负荷:室上性心动过速心电仿真的4.8s偶极子数。
实验结果:
如图5所示,对于三证不同的配置平台,分别使用算法1和算法2。
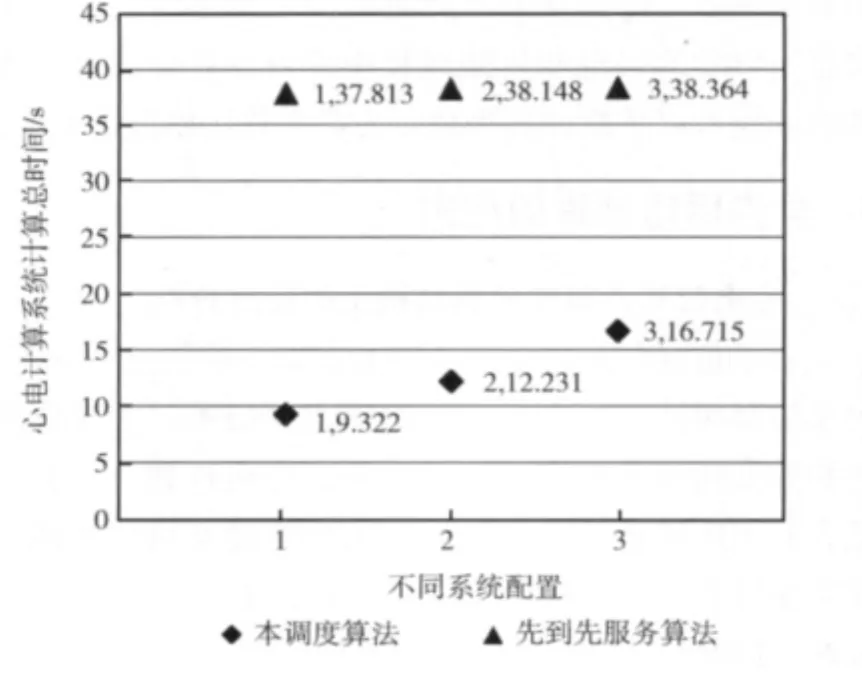
图5 不同配置下的实验结果
6 结束语
本论文在分析了心电仿真计算特点的基础上,提出了在网络计算系统中的一个新的调度算法,在系统的响应时间方面取得了很好的效果。
在本文心电仿真计算中,除了在并行性方面适合网络计算的要求以外,其中的主要前提是计算工作量的可预测性,这个要求在高性能计算方面还是有一定的可行性的,例如,本调度算法可以应用到N-Body问题Fmm算法中,因为在每个分块中近距离粒子作用力的计算量和粒子数的平方成正比,它的计算量也是可以预测的。
进一步工作,将在总结其它类型的高性能计算的算法特点的基础上,研究动态调度算法。
[1]Shen W,Wei D,Xu W,et al.Parallelized computation for computer simulation of electrocardiograms using personal computers with multi-core CPU and general-purpose GPU[J].Computer Methods and Programs in Biomedicine,2010,100(1):87-96.
[2]McFarlane R,Biktasheva I V.High performance computing for the simulation of cardiac electrophysiology[C]//Sliema:Proceedings of the Third International Conference on Software Engineering Advances,2008:13-18.
[3]Tusscher K,Panfilov A.Modelling of the ventricular conduction system[J].Progress in Biophysics and Molecular Biology,2008,96(1-3):152-170.
[4]Reumann M,Fitch BG,Rayshubskiy A,et al.Large scale cardiac modeling on the Blue Gene supercomputer[C]//Vancouver,BC:Proceedings of IEEE Engineering in Medicine and Biology Society,2008:577-580.
[5]Reumann M,Fitch B G,Rayshubskiy A,et al.Strong scaling and speedup to 16,384processors in cardiac electro-mechanical simulations[C]//Minneapolis,MN:Annual International Conference of the IEEE Engineering in Medicine and Biology Society,2009:2795-2798.
[6]Donassolo B,Legrand A,Geyer C.Non-cooperative scheduling considered harmful in collaborative volunteer computing environments cluster,cloud and grid computing(CCGrid)[C]//Newport Beach,CA:11th IEEE/ACM International Symposium on,2011:144-153.
[7]Sato D,Xie Y,Weiss J N,et al.Acceleration of cardiac tissue simulation with graphic processing units[J].Medical and Biological Engineering and Computing,2009,47(9):1011-1015.
[8]Zhu H,Sun Y,Rajagopal G,et al.Facilitating arrhythmia simulation:The method of quantitative cellular automata modeling and parallel running[OL].Biomedical Engineering Online,2004-03-29.
[9]Zhu Xin,Wei Daming,Wang Hui.Simulation of intracardial potentials with anisotropic computer heart models[C]//Shanghai:Proceedings of the IEEE Engineering in Medicine and Biology,2005:1071-1074.
[10]Zhu Xin,Wei Daming.Computer simulation of intracardiac potential with whole-heart model[J].International Journal of Bioinformatics Research and Applications,2007,3(1):100-122.
猜你喜欢
昆明医科大学学报(2021年4期)2021-07-23 01:22:00
化工管理(2021年7期)2021-05-13 00:46:12
防爆电机(2020年4期)2020-12-14 03:11:02
电子制作(2019年19期)2019-11-23 08:41:40
中国生物医学工程学报(2019年6期)2019-07-16 07:52:38
成都信息工程大学学报(2019年5期)2019-05-21 00:46:14
心电与循环(2019年2期)2019-02-19 13:40:02
电视技术(2014年19期)2014-03-11 15:38:15
新高考·高一物理(2012年5期)2012-04-29 20:27:57
电气电子教学学报(2010年6期)2010-08-16 01:15:18
