
基于缺陷分类和缺陷预测的软件缺陷预防
2013-11-30 05:01:40雷挺
计算机工程与设计 2013年1期
雷 挺
(中国电子科技集团公司第十五研究所,北京100083)
0 引 言
近年来,由于大量的缺陷给软件企业带来了大量维护费用,软件测试技术越来越受到重视,不少企业相继对研发资质进行了提升,引入能力成熟度模型集成(capability maturity model integration,CMMI),研发缺陷管理和跟踪系统,将缺陷分析和预测的功能逐步融入到缺陷管理系统中,缺陷预防也开始受到关注,现有的缺陷预防方法有FMEA(故障模式和效果分析)、FTA(故障树分析)、防御性编程、软件易测试性设计等,但是目前还没有一个能够综合缺陷分析和缺陷预测的成熟技术,针对不同的生命周期进行有效的分析和提前预防,为了解决以上问题,本文将缺陷预测技术与改进的正交缺陷分类方法相结合,提出了一套缺陷预防流程,并用实际项目进行对比实验,验证该流程的有效性。
1 缺陷预防的概念及意义
缺陷预防(defect prevention)是在软件缺陷没有出现时,就采取积极有效的预防措施,把缺陷消灭在萌芽状态的一种技术[1]。
美国质量保证研究所对软件测试的研究结果表明,在开发过程后期发现问题的成本是非常高的。补救成本会随着开发周期的进展而大幅上升,这是因为需要修改设计与编码,需要重新进行测试以及考虑对其他相关模块的影响[2]。行业研究已经表明,如果在设计时修正一个缺陷的成本是1x,那么在软件发布之后进行修正的成本将是100x[3]。
为了避免质量低下所带来的巨大成本,最佳选择是在缺陷预防方面进行投入。如果开发团队能够在上游阶段预防缺陷,而不是在后期发现和修正缺陷,那么设计人员、开发人员和其他相关人员等都将从中受益[4]。
2 常用的缺陷预测方法
缺陷预测是预防的基础,准确预测才能集中有限的资源对缺陷进行针对性预防。按照预测技术的不同,缺陷预测方法可以分为类比法、Delphi估算法、数学预测模型法三大类方法,但是因为前两种方法有着无法克服的局限性,目前软件缺陷预测领域的研究工作大部分是集中在数学预测模型法方面。
常见数学预测模型方法有:线性判别分析(linear discriminant analysis,LDA),布尔判别函数(boolean discriminant function,BDF),贝叶斯网络(bayesian network,BN),分 类 回 归 树(classification and regression tree,CART),优化集精简(optimized set reduce,OSR),聚类分析(clustering analysis,CA),支持向量机(support vector machine,SVM),人工神经网络(artificial neural network,ANN),平均单一相关评估器(average one-dependence estimators,AODE)[5]等。各种预测方法有着不同的适应面,可以解决不同的问题,也有各自的局限[6]。它们的详细比较结果见表1。

表1 缺陷预测方法的比较
迄今为止,国内外有100多种缺陷预测模型发表在各种专业刊物和学术会议上,但大多数模型并没有得到充分的项目数据的支撑和验证,其有效性和准确性得不到有力地证明,因而未能广泛应用。
3 缺陷预测模型的优化
作者所在的组织多年来致力于缺陷预测的研究,积累了大量缺陷数据,在此基础上建立了multi-AODE缺陷预测模型。
假设F(Xi)表示包含属性Xj的样本数,属性Xj、Y均依赖于属性Xi,m表示m-估计量,AODE方法的原理可用下列公式表达[7]
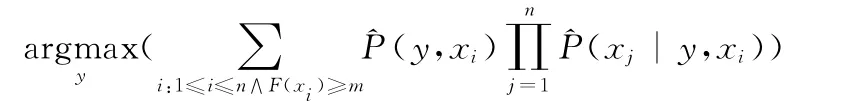
通过一对多方法可以实现multi-AODE分类器,即组合多个AODE二值分类器来实现多值分类。使用multi-AODE预测模型进行缺陷预测的过程如图1所示。
向该模型输入软件生命周期中的各个阶段的度量数据,应用离散化、再抽样等数据预处理技术,并通过multi-AODE分类器进行预测运算,输出各阶段注入和遗留缺陷密度等级的预测值。如果预测出的注入和遗留缺陷密度值较小,则意味着质量的前景是乐观的;反之,则意味着需要改进过程,增加对质量控制的关注。
按照覆盖域尽可能广的原则,从历史项目中挑选了83个软件项目(其中包括36个大型项目,47个中小型项目),使用不同模型进行缺陷预测,结果见表2。
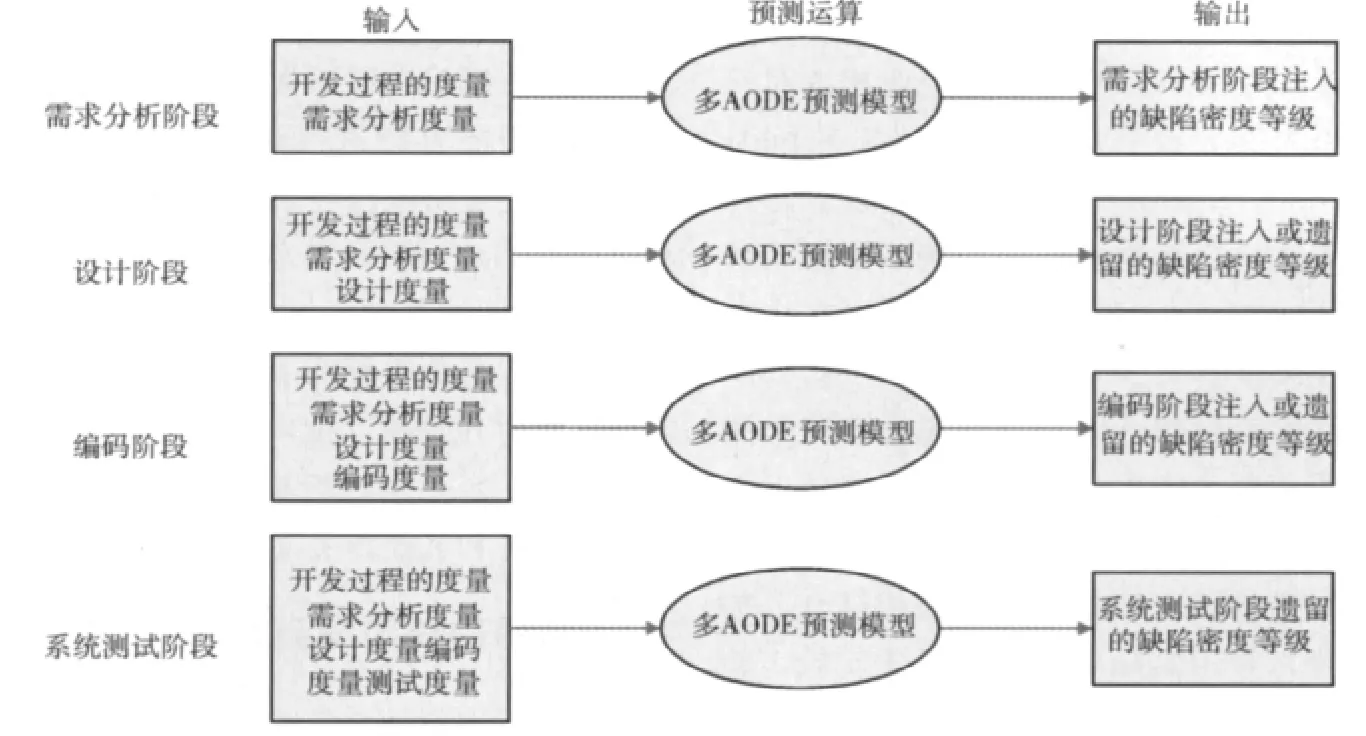
图1 使用multi-AODE预测模型进行缺陷预测的过程
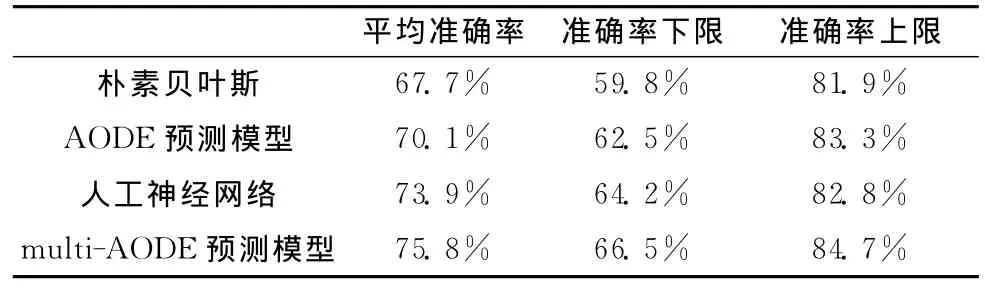
表2 不同缺陷预测模型的预测结果比较
从表2不难看出,同其他预测模型相比,multi-AODE预测模型有着更好的预测结果,但仍有较大的提升空间,为进一步提高其预测的准确性,作者根据多年项目经验,对该模型做了如下优化。
(1)增加度量元个数:遵循度量元可理解、易估计、与缺陷相关度高的原则,将原预测模型的度量元个数从21个增加至28个(去掉其中的10个并新增17个),同时细化度量标准,将度量元取值从3至6级扩展至9级,以提高预测的准确性。约定度量元分级如下:A、B、C、D、E分别取1、3、5、7、9级,介于A、B、C、D、E的中间值分别取2、4、6、8级。需要说明的是:
1)提取所有相关度量元并不能提高预测的准确性,甚至会适得其反。应从度量目标出发,确定适当的度量元。
2)“开发过程的度量元”是指在生命周期的每个阶段都会影响软件质量的度量元,由于每个阶段都可能采取预防措施,所以下一个阶段数据采集时应当更新 “开发过程的度量元”的取值,并且其权重高于另外3个阶段的度量元。
(2)控制度量数据的采集:将软件生命周期中的各个阶段的度量数据采集环节集成到了本组织的Gems项目管理工具中,该工具根据项目进度及时提醒相关人员及时填写各个阶段度量数据,若忘记填写,工具将给出提示信息,这一设计保证数据采集的及时性和有效性,避免了 “垃圾进,垃圾出”的度量。
(3)调整1类/2类错误率:1类错误是指将低风险模块错误地预测为高风险模块。2类错误是指将高风险模块错误地预测为低风险模块。毋庸置疑,这两类错误会带来不同的损失,通过调整度量元的数目、权重、度量标准和取值范围,实现对可能带来风险的度量值的放大,牺牲1类错误率来保证较低的2类错误率,以满足军工及科研领域的特殊需要[8]。
使用优化后的预测模型对相同的83个历史项目进行预测,实验结果见表3。
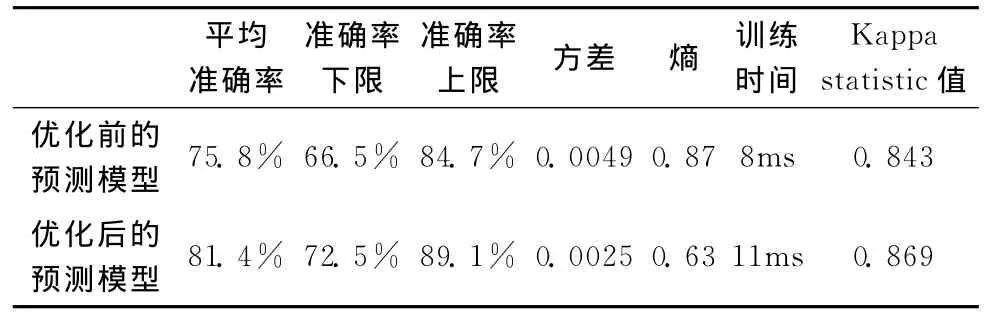
表3 模型改进前后的预测结果比较
分析表3可知,尽管优化后的训练时间略有增加,但是预测值的准确性(平均、最好、最坏)和一致性(Kappa statistic统计值)都有了较大的提高。以每个项目预测值的准确率作为数据样本,计算方差和熵,更小的方差和熵意味着优化后的预测模型有着更好的稳定性和更小的不确定性,此外,优化后的预测模型在1类/2类错误率的调整上也具有更大的灵活性。
尽管优化后的预测模型在预测效果上有显著的提升,但其预测结果仍不足以具体指导组织或项目进行缺陷预防,为解决这一问题,引入正交缺陷分类(orthogonal defect classification,ODC)方法,并结合组织的实际情况对该方法进行了改进,使用改进的ODC方法对缺陷进行分类,同时分析缺陷原因,通过对大量缺陷数据的分析,找出导致软件缺陷的共性原因,有针对性地进行预防。
4 改进的ODC:基于缺陷分类的定量分析方法
表4比较了两类缺陷原因分析方法,显然,基于缺陷分类的定量分析方法在缺陷预防上有着巨大的优势。
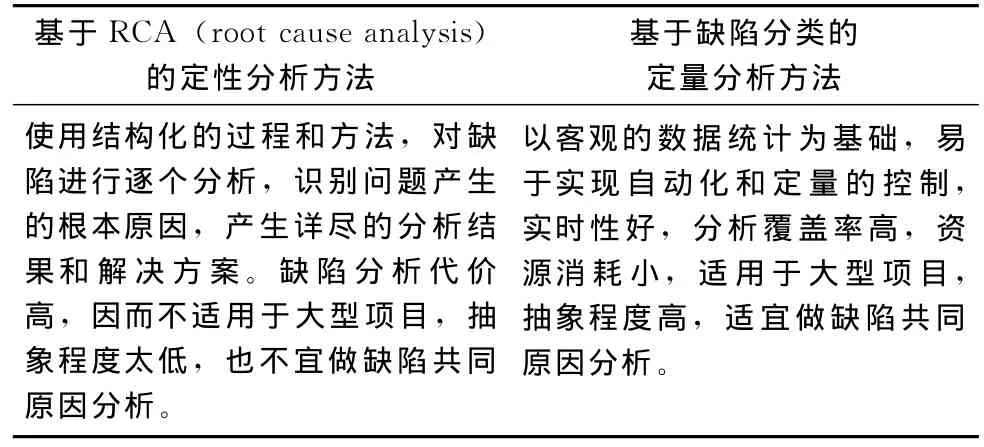
表4 基于RCA的定性分析方法和基于缺陷分类的定量分析方法
正交缺陷分类(orthogonal defect classification,ODC)是IBM公司提出的缺陷分类方法[9]。该分类方法定义了缺陷特征的8个属性,用来描述缺陷特征,这些属性对应着缺陷的发现和修复两类特定活动。当一个测试人员发现并提交一个缺陷时,给这个缺陷分配 “Activity(测试活动)”、 “Trigger(缺陷触发)”、 “Impact(缺陷影响)”属性,称为Opener(发现者属性)。当一个开发人员修复或者回应了一个缺陷时,可以分配 “Age(历史版本)”、“Source(缺陷来源)”、 “Type(缺陷类型)”、 “Qualifier(类型进一步限定)”以及 “Target(缺陷载体)”,这些属性被称为解决者属性(Closer)。
在打开和关闭软件缺陷时运用ODC方法记录缺陷的相应属性值,分析这些信息可以确定缺陷原因,进行错误跟踪,追溯到缺陷的引入阶段,反映出软件的设计、代码质量等各方面的问题,提供改进线索。此外,还可以从缺陷记录中获取大量有价值的语义信息,作为量化评估依据,并为缺陷预防提供数据支持。
结合缺陷预防的要求,对ODC方法的改进如下:在已有的8个属性的基础上,扩展 “Target”、 “Type”属性的取值,仍保持其正交性,同时增加 “Defect Cause(缺陷原因)”和 “Measure(预防措施)”两个属性。改进的ODC方法如图2所示。
使用改进的ODC方法对历史数据进行缺陷原因分析的流程如下。
(1)发现并提交一个缺陷时,在正交化分类的缺陷数据集(defect data set,以下简称缺陷数据集)中记录 “Activity”、“Trigger”、“Impact”这3个属性值;
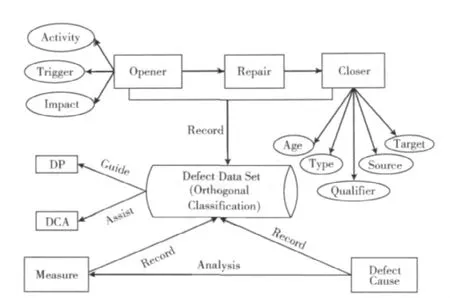
图2 改进的ODC方法
(2)修复或者回应一个缺陷时,在缺陷数据集中记录“Age”、 “Source”、 “Qualifier”、 “Type”以及 “Target”5个属性值,同时记录修复缺陷所采取的纠正措施、修复效果;
(3)结合(1)、(2)进行缺陷跟踪,追溯到缺陷的引入阶段,分析并确定可能的缺陷原因,并结合修复措施和修复效果以及专家经验(如果有相关记录的话)进行缺陷预防的措施分析,同时记录 “Defect Cause”和 “Measure”属性;
(4)对大量缺陷数据重复上述步骤,得到一个相对全面的缺陷数据集,它记录了大量缺陷的可能原因及相应预防措施,从中找出导致软件缺陷的共性原因和相应的预防措施,按需求、设计、编码3个阶段进行分类。将该数据集应用于新的项目中,可以在项目的需求、设计、编码阶段辅助进行缺陷原因分析(Assist DCA)并指导缺陷预防(Guide DP)。
仍以前述83个历史项目为分析对象,用改进的ODC方法队83个项目中的缺陷逐个进行缺陷原因分析,得到一个相对完备的缺陷数据集,下文简称 《缺陷属性数据集》。实践证明,该数据集能够为未来新项目提供有力的数据支持。
5 基于缺陷分类和缺陷预测的缺陷预防流程
将缺陷预测与改进的正交缺陷分类方法结合起来,形成了一套完整的软件缺陷预防流程。
(1)通过改进后的multi-AODE预测模型,将生命周期某个阶段的度量信息及开发过程的度量信息输入预测模型,计算出该阶段的缺陷密度等级。若预测的缺陷密度等级较低,意味着质量的前景很乐观,本阶段无需额外增加缺陷预防投入,可以将资源投入到生命周期的下一个阶段的缺陷预防上,实现资源的合理配置;反之,意味着应额外进行质量控制,并增加在该阶段缺陷预防方面的投入。
(2)查找 《缺陷属性数据集》,获取该阶段引入缺陷的共性原因及对应的预防措施;
(3)根据项目质量要求,使用改进的ODC方法分析风险等级高的度量元,例如分析取值在5级以上的度量元,进一步补充缺陷原因和预防措施。
(4)结合项目实际情况,对缺陷原因及相应预防措施进行补充和筛选,针对性地进行缺陷预防,降低缺陷密度。
基于改进的AODE预测模型及改进ODC方法的缺陷预防流程如图3所示(注:缺陷预防不必考虑系统测试阶段,图1中预测的是注入或遗留的缺陷,故需要考虑系统测试阶段)
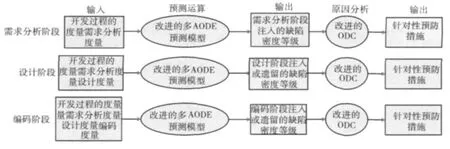
图3 基于改进的AODE预测模型及改进ODC方法的缺陷预防流程
使用该流程应注意以下几点。
(1)对于有特殊要求的项目,可以通过调整改进的multi-AODE预测模型的度量元的数目、权重、度量标准和取值范围,实现对可能带来风险的度量值的放大,牺牲1类错误率来保证较低的2类错误率;
(2)运用改进ODC分析可能的缺陷原因并获取预防措施时,不能局限于缺陷数据集中现有的经验数据,需重视对度量元的分析,并且充分考虑项目的实际情况,实现对缺陷原因和获取预防措施进行筛选和补充,以增加预防的针对性,节省项目成本;
6 实验验证与分析
选择某项目中业务逻辑和软件规模相似的两个子系统:A系统和B系统作对比实验,说明如何使用改进的AODE预测模型及改进ODC方法进行缺陷预防,以验上述缺陷预防流程的效果。
其中B系统作为实验组,按图3所示流程进行缺陷预防;A系统作为对照组,不采取预防措施,按原有流程进行开发。
(1)对B系统的设计阶段进行预测,“开发过程度量”、“需求度量”、“设计度量”的数据采集结果如下。
1)开发过程度量
@attribute CMMI{3} %项目过程能力成熟度
@attribute qualityControl{4} %质量控制的有效性
@attribute attitude{6} %人员工作热情及态度
@attribute communication{4} %人员交流沟通有效性
@attribute complexity{3} %产品业务逻辑的复杂性
@attribute experience{3} %开发团队的经验水平
@attribute staffStability{1} %人员的连续性
2)需求度量
@attribute requirementBreakdown{3} %需求分解的正确性
@attribute requirementReview{3} %需求评审的充分度
@attribute requirementStability{5} %需求稳定性
@attribute requirementDetailed Degree{2} %需求粒度
@attribute userParticipation{3} %用户的参与程度
@attribute userExpressiveness{4} %用户对需求的表达能力
@attribute domainKnowledge{4} %用户的应用领域经验
3)设计度量
@attribute designStandardability{7} %设计过程的规范性
@attribute designerParticipation{6} %设计人员在早期的参与程度
@attribute requirementAcknowledge{4} %设计人员对需求的理解
@attribute codeKnowledge{5} %设计人员对编码技术的了解
@attribute moduleComplexity{3} %软件模块的复杂度
@attribute designDetailed Degree{3} %设计粒度
@attribute designReview{5} %设计评审
输入上述度量数据,使用预测模型进行运算,输出@attribute requirementDefect{[1.05,1.125)},预测结果表明设计阶段的缺陷密度等级较高,可采取针对性预防措施,以降低缺陷密度。
(2)从 《缺陷属性数据集》中获取设计阶段引入缺陷的共性原因及对应的预防措施;
(3)使用改进的ODC方法分析取值在5级以上的度量元,进一步补充缺陷原因和预防措施。
(4)对缺陷原因及相应预防措施进行补充和筛选,分析项目实际情况,去掉预防措施。
1)重视工作效率,避免过度加班;
2)明确设计标准与规范;
3)防范内部攻击;
考虑到本项目涉及到装备管理方面的业务知识和相关规则,增加预防措施。
(1)对设计人员进行业务知识及业务规则培训;
(2)加强编码人员和设计人员间的沟通,使他们对控制/逻辑流程的设计思路有更好的理解;
若实践证明有效,应及时将这两个预防措施加入缺陷数据集中,并作正交化分类,丰富和完善缺陷数据集。
综合上述3个方面,得到设计阶段应采取的缺陷预防措施如下。
(1)规范流程、加强管理;
(2)培养员工的良好的工作态度及责任意识
(3)培养良好的工作氛围;
(4)加强风险分析;
(5)控制需求文档版本,避免频繁变更;
(6)加强设计分析人员内部的沟通以及与需求人员间的沟通,让设计人员及早参与到项目中;
(7)严格的设计评审;
(8)充分考虑软件运行平台和软件的可移植性;
(9)考虑软件内部模块间的兼容及前后版本间的兼容;
(10)记录系统日志便于问题的分析跟踪;
(11)考虑安全性与易用性或功能的折中;
(12)事先考虑可能发生的异常,做好相应的安全处理;
(13)对设计人员进行业务知识及业务规则培训;
(14)加强编码人员和设计人员间的沟通,使他们对控制/逻辑流程的设计思路有更好的理解。
由于需求分析阶段、编码阶段的缺陷预防流程与上述过程相似,限于篇幅,这里不一一列举。实验组B系统和对照组A系统各阶段检测出的缺陷数对比如图4所示。
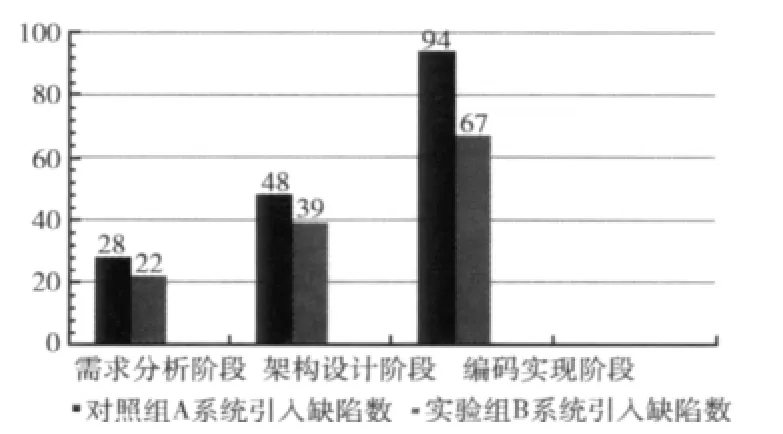
图4 实验组B系统和对照组A系统各阶段检测出的缺陷数对比
从图4可以看出,由于采用了缺陷预防措施,相比A系统,B系统各个阶段引入的缺陷数均大为减少:需求分析阶段的缺陷减少了21%,架构设计阶段的缺陷减少了18%,编码实现阶段的缺陷减少了29%。此外,由于在上游阶段减少了大量缺陷,实验组的开发周期比对照组缩短了23%。这一结果证明本文所提出的软件缺陷预防流程的可行性和有效性。
7 结束语
本文提出了一套完整的软件缺陷预防流程:将生命周期某个阶段的度量信息及开发过程的度量信息输入预测模型,计算出该阶段的缺陷密度等级,根据缺陷密度等级确定在缺陷预防上的投入力度,并使用改进的ODC方法分析该阶段引入或遗留缺陷的根本原因,针对根本原因分析可行预防措施,从而有针对性地进行缺陷预防,在减少软件缺陷的同时还能够节省成本、缩短项目周期[11]。
本文在解决实际项目问题的同时,也是将缺陷预测和改进ODC方法运用在缺陷预防领域的一次尝试。虽然经过了实际项目的验证,本文提出的软件缺陷预防流程仍需在实际运用中不断收集反馈意见,并加以改进完善。下一步将对缺陷预测模型做更深入的研究,根据项目特征,对不同的项目采用不同的预测模型,实现预测准确性的最优化。此外,继续收集各种类型的项目缺陷数据,获得更加全面的缺陷数据集以提高缺陷预防的有效性和准确性。可以预见,随着本文提出的缺陷预防流程在实际项目中的不断应用与改进,缺陷数据集与预测模型会日益丰富与完善,预防效果也会越来越好。
[1]Chang Ching-Pao,Chu Pchih-Ping.Defect prevention in software processes:an action-based approach[J].Journal of Systems and Software,2007,80(4):1-27.
[2]James McCurley,Dennis R Goldenson.Performance effects of measurement and analysis:perspectives from CMMI high maturity organizations and appraisers[M].Software Engineering Measurement and Analysis,2010:45-55.
[3]Lee Shufang,Bai Xiaoying,Chen Yinong.Automatic mutation testing and simulation on OWL-S specified web services[C]//IEEE Computer Society 41st Annual Simulation Symposium,2008:149-156.
[4]Marc McDonald,Robert Musson,RossSmith.The practical guide to defect prevention[M].Microsoft Press,2007:1-78.
[5]WANG Qing,WU Shujian,LI Mingshu.Software defect prediction[J].Journal of Software,2008,19(7):1566-1577(in Chinese).[王青,伍书剑,李明树.软件缺陷预测技术[J].软件学报,2008,19(7):1566-1577.]
[6]Fenton NE,Martin N,William M,et al.Project data incorpora-ting qualitative facts for improved software defect prediction[C]//Proc of the 3rd Int'l Workshop on Predictor Models in Software Engineering.Washington,DC:IEEE Computer Society,2007:11-20.
[7]ZHOU Feng,MA Li.Software defect prediction model based on AODE and resampling[J].Computer Engineering and Design,2011,32(1):210-212(in Chinese).[周丰,马力.基于AODE和再抽样的软件缺陷预测模型[J].计算机工程与设计,2011,32(1):210-212]
[8]Van der Walt C,Etienne Barnard.Data characteristics that determine classifier performance[J].SAIEE Africa Research Journal,2007,98(3):87-93.
[9]YIN Xiangle,MA li,GUAN Xin.Research of software defects classification[J].Computer Engineering and Design,2008,29(19):4910-4912(in Chinese)[尹相乐,马力,关昕.软件缺陷分类的研究[J].计算机工程与设计,2008,29(19):4910-4912]
[10]Robert W Stoddard II,Dennis R.Goldenson.Approaches to process performance modeling:A summary from the sei series of workshops on CMMI high maturity measurement and analysis[M].Software Engineering Institute,Carnegie Mellon University,2010:15-42.
[11]Dennis R Goldenson,James McCurley,Robert W Stoddard II.Use and organizational effects of measurement and analysis in high maturity organizations:Results from the 2008SEI state of measurement and analysis practice surveys[M].Software Engineering Institute,Carnegie Mellon University,2009:23-61.
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
今日农业(2022年4期)2022-11-16 19:42:02
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
河北果树(2020年2期)2020-01-09 11:15:07
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
建材发展导向(2019年5期)2019-09-09 09:21:46
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
