
特征保持的基于紧支径向基函数的点云简化
2013-11-30 05:01王先泽李忠科张晓娟吕培军
计算机工程与设计 2013年1期
王先泽,李忠科,张晓娟,吕培军,王 勇
(1.第二炮兵工程大学401教研室,陕西 西安710025;2.北京大学 口腔医学院,北京100871)
0 引 言
对点云数据进行简化是数据预处理中一个非常重要的技术,它有助于提高数据的存储、传输、计算以及显示的效率。点云的简化大体上可以分为基于网格的简化和基于点的简化。基于网格的简化方法需要先将点云网格化且在简化的过程中需要维持拓扑的一致性,因此比较复杂。而基于点的简化方法则不需要维护这些拓扑信息,相对来说更有优势。Pauly等[1]首次将几种基于网格的聚类简化方法应用到点集曲面上,该方法速度很快,但是产生的误差较大,且不能像基于网格的简化方法那样预先用一个全局误差来控制简化过程,Brodsky[2]等提出的聚类简化法也有类似问题。邹万红[3]等提出了一种大规模点云模型的简化算法,该算法可以分为两步:首先根据几何近似原理将点模型分割成与平面近似的多个分片,然后在分片的基础上进行层次空间聚类简化,该方法的效果比较好,但是复杂度较高。王仁芳等[4]提出了一种基于相似性的曲率自适应点模型简化算法,将点模型划分为强边性和非强边性两部分,首先对非强边性部分进行表面区域几何特征相似性聚类,然后对各类簇分别进行划分和简化,该算法有效地保持了特征边界部分和曲面的细节,且能够生成高质量的简化点集曲面。
由于隐式曲面表示在曲面造型和和三维可视化中的良好特性[5],径向基函数[6]在点云简化之中已经得到广泛应用,但是它的计算效率非常低,只能处理小的点云数据。而紧支径向基函数(CSRBF)[7-9]能够用于大量点云数据的重构且在隐式表示方面有和径向基函数相似的特性,本文在此基础上,提出一种特征保持的基于紧支径向基函数的点云简化方法。该方法通过建立与点曲率和支撑半径相关的评估函数来评价点的重要性,评估函数值会随着支撑半径内点的数量而变化,然后迭代地更新并删除函数值最小的点。实验结果表明,该方法能够很好地控制简化后点云的数量,产生的误差较小,且能够很好的保持点云的特征。
1 紧支径向基函数
1.1 概 念
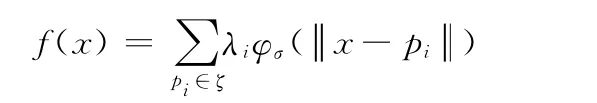
式 中:λi——第i点影响的权重,φσ(r)=φ(r/σ),φσ(r)——紧支径向基函数。σ——支撑半径,也就是点pi所能影响点的范围,这是一个与采样密度相关的参数。
1.2 确定支撑半径
采用CSRBF进行点云简化时,支撑半径的大小决定了落在某确定散乱点作用范围内的点的数量,直接影响点云简化以及后续曲面重建的效果。对于稀疏的点云,如果支撑半径σ选取得太小,则散乱点之间的相互作用减小,达不到点云简化的目的;对于密集的点云,如果支撑半径σ选取得太大,则在支撑半径中的点的数量会增加,这就会增加算法的求解时间;另外,对于一些密度不规则的点云,支撑半径的选取会直接影响到重建模型的质量。
本文参考文献[10]中的方法来确定算法中紧支径向基函数的支撑半径大小,大体上可以分为三步:①使用基于八叉树的方法对点云p的包围盒进行分割;②计算叶子的平均对角线长度diagonal;③设置σ值为diagonal的3/4,即σ=0.75×diagonal。
1.3 紧支径向基函数选择
紧支径向基函数应用非常广泛,迄今为止,为了解决不同问题以及不同的连续性划分,人们提出了许多种类的基函数。Wendland为了解决径向基函数的最小度的对称正定问题,提出的紧支径向基函数都有如下形式
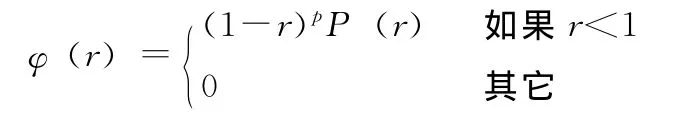
针对不同的维数d以及不同的连续性Ck,Wendland提出了一些紧支径向基函数,表1列出了三维情况下的几个函数。
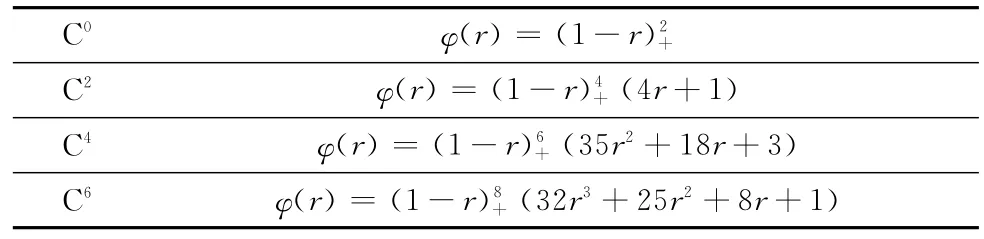
表1 Wendland提出的紧支径向基函数
文献[10]中用上述4种紧支径向基函数对不同采样密度的一些模型进行了重构,并且将重构后的模型与原始点云进行了误差分析。实验结果表明使用C2连续的紧支径向基函数进行重构得到的曲面质量比其它3种所得到的更好。因此,在本章中,我们使用Wendland的C2连续的紧支径向基函数作为算法中使用的函数。
2 特征保持的点云简化算法
本文提出了一种基于紧支径向基函数的特征保持的三维散乱点云简化算法,算法基本步骤描述如下:
步骤1 假设点p为点云中任意一点,则根据改进的k_近邻算法求点云中距离点p中最近的k个顶点即求点p的k邻域;
步骤2 采用移动最小二乘法(moving least squares,MLS)在局部坐标系内拟合点p的邻域,然后通过拟合得到的局部曲面拟合多项式计算该点的高斯曲率;
步骤3 根据2.3节的描述选择合适的紧支径向基函数,并在此基础上建立评估函数Eva(i),用以评估顶点的重要性,然后将步骤2中求得的高斯曲率值代入,计算得到评估函数Eva(i)的值;
步骤4 重复步骤1到步骤3,直到所有点的高斯曲率与评估函数值都求出,然后将Eva(i)值最小的点删除;
步骤5 判断删除后点的数目是否达到预先的要求,如果达到,则执行步骤7,否则,更新与删除点相关的点的评估函数值,然后删除所有函数值中值最小的点;
步骤6 迭代执行步骤5;
步骤7 算法结束。
2.1 改进的k_近邻算法
当点云为非均匀采样时,传统的k_近邻算法来具有一定的局限性。如图1(a)所示,传统的k_近邻算法求得的k邻域只包含了该点周围一半的环境,不能充分描述周围的形势,从而可能使求得的曲率发生偏差。基于此,本文提出一种改进的k_近邻算法,该算法通过设置一个最大角限制条件来保证点p的k邻域围绕着该点是球形分布的,从而在最大程度上保证所求得的k邻域能够反应点所处的环境。
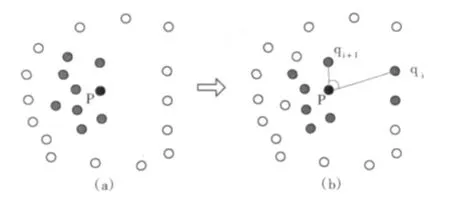
图1 选择点P的邻域所需的角度限制
使用改进的k_近邻算法计算输入点p的k邻域NNp,大体上可以分为三步:①找到k个邻域点加入NNp中,通常8≤k≤18在大多数情况下能满足需要;②将这k个邻域点映射到一个合适的局部支撑平面H上,该平面可以通过求局部法向量来确定;③确保映射到支撑平面H上的两个相邻邻域点与中心点之间形成的角度不大于预先设定的门限值,如果不满足条件,则继续增加邻域点到NNp中,直到找到满足条件的替代邻域点为止。
首先是使用传统的k_近邻算法计算点p的k邻域,并加入到NNp中。为了估计以cNNp为中心的邻域点的局部法向量,可以先计算如式(1)所示的半正定权重协方差矩阵C={cvw}∈R3×3
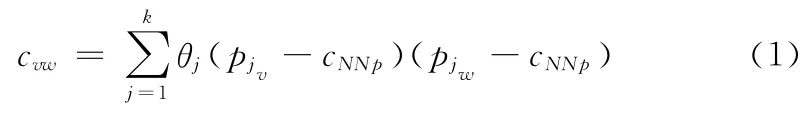
式中:θj——以si为中心的二次B样条B(t):θj=,d——欧式距离,r——支撑半径,表示以sisi为中心的包围球的半径,包围球包含对输入点pj使用k_近邻算法求得的邻域点;k、cNNp——邻域点的个数、中心,k=|NNp|。
求得协方差矩阵C后,对C进行特征分析可以得到k邻域NNp的主成分,假设λ1,λ2,λ3分别为C的3个实特征值,且有λ1≤λ2≤λ3,而v1,v2,v3分别为它们所对应的一组正交特征向量,则特征值λ1对应的特征向量v1就是局部法向量。估计出局部法向量就可以求得局部支撑平面H,它是一个垂直于局部法向量且过点p的平面,然后把k邻域NNp中的点映射到平面上。
将NNp中的点映射到局部支撑平面上之后,下一步是确保映射到支撑平面H上的两个相邻邻域点与中心点之间形成的角度不大于预先设定的门限值max_angle。在支撑平面上,对于点p,我们考虑它所有的邻点qi以及按逆时针方向搜索的qi的相邻点qi+1,需要它们形成的角∠qipqi+1不大于max_angle,比如π/2,如图1(b)所示。如果在这些邻域点和中心点p之间形成的角度中没有大于门限值的,则这些邻域点就是使用改进的k_近邻算法求得的该点的k邻域NNp,算法结束;否则,就需要增大搜索的包围球半径radii,从而增加邻域,然后直接映射到支撑平面上,继续判断角度,更新NNp,直到都满足门限条件的替代邻域点被找到。
2.2 高斯曲率计算
使用改进的k_近邻算法得到点的k邻域后,就可以通过MLS方法拟合pi点的k邻域NNp(pi)={pj},j=0,…,k中的点,得到pi点的局部拟合多项式gi,然后计算pi点的曲率。计算局部曲面拟合多项式可以分为两步:①寻找支撑平面,建立局部坐标系;②计算多项式。
首先,建立NNp(pi)的协方差矩阵,B=其 中,是NNp(pi)的重心,B是一个半正定的3×3的对称矩阵。同2.1节中的方法类似,对矩阵B进行特征分析,v2,v3,oi共同定义逼近NNp(pi)的支撑平面Hi,v1即为oi的法向,记为ni。在Hi平面上建立局部坐标系(oi,u,v,ni),oi为原点,ni为Z轴。然后在(oi,u,v,ni)坐标系内用二次多项式gi拟合NNp(pi),使pj点与其在拟合曲面上投影点的距离平方和最小。设gi表达式为
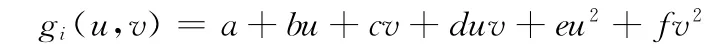
则通过对多项式的各个系数求一阶导数可以得到6个线性方程,然后利用高斯消元法计算得到gi的各个系数。求得gi的表达式后,参照文献[11]中的方法,可得曲面的高斯曲率kg为
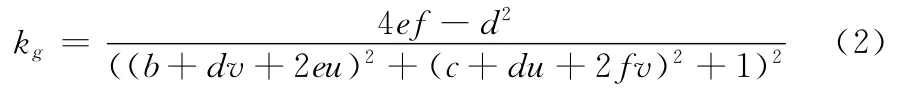
Dragon和Armadillo模型的高斯曲率如图2所示。其中深色部分为曲率较大的区域,浅色部分则为曲率较小的区域。
2.3 建立评估函数
本文提出的简化算法的核心思想就是建立一个判断点云中的点重要性的标准,通过这个标准来计算点的重要性,而简化就是迭代地删除最不重要的点的过程。反映一个点在点云中的重要性有两个方面:一是该点的曲率,高曲率区域是特征区域,能够反映模型的特征;二是该点周围点的分布情况,分布密度越大,表示反映该区域特征的点越多,则该点的重要性就会降低,反之亦然。因此,我们建立评估函数就从这两个方面考虑。点的曲率用上节中的高斯曲率来表示,而点的分布情况则可以通过紧支径向基函数反映出来。

图2 Dragon和Armadillo模型的高斯曲率
假设p=为输入点集,我们定义评估函数为
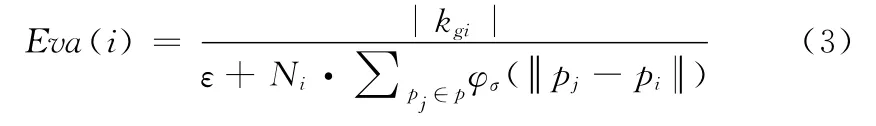
其中,φσ(r)=φ(r/σ),φ(r)=(1-r)4+(4r+1)为前面介绍的紧支径向基函数。σ为支撑半径,可以通过点云p的密度估计出来;Ni表示pi对邻域贡献的权重;kgi表示式(2)中计算得原始点云中pi点的高斯曲率,由于曲率值可能为负,所以在这里取它绝对值|kgi|;ε>0为一个小的正实数,用来避免式(3)中分母为0。由于使用Eva是来评估点的重要性,所以ε的绝对取值并不影响比较的结果。在我们的实验中,选取ε=1,当某点的σ半径内不包含邻点时,Eva值由曲率决定。
当删除一个点后,所有支撑半径σ内包含被删除点的点的σ半径内的点的个数就会减少,则也会减小,而高斯曲率|kgi|值不变,从而导致这些点的Eva(i)值增加。更新了评估函数Eva(i)的值之后,再一起比较,迭代删除值最小的点,直到达到预先的简化要求为止。
2.4 算法实现
本文所提简化算法的伪代码如下所示:


3 算法试验及分析
由于在评估函数中涉及到点的曲率,而曲率计算与k_近邻的个数的选取密切相关。如果k邻近的个数选取过大,不能保证单凹或者单凸,曲率估算就会出现误差;如果k邻近的个数取得过小,则不能被二次曲面逼近,且容易受噪声影响,同样不能正确估算误差。在本算法中,取k=10取得了不错的效果。
为了验证本文算法的有效性,在Windows平台上(CPU主频2.0G,内存1G),基于VC++2008和OpenGL实现了本文算法,并将实验结果与文献[2]中所提方法的结果进行了比较,Armadillo模型的部分效果对比如图3所示。由于本文算法使用迭代删除最不重要的点的方法,能够很好地控制简化后点的数目,从而可以保证在相同简化率的条件下与其它算法进行比较。从图3中可以看出,本文算法在一些特征点较多的部位保留了较多的点,而在其它一些部位则保留点比较少,相对于文献[2]中方法来说,能够更好地保持模型的特征。另外,本文也使用尖峰信噪比PSNR[10](peak signal to noise ratio)进行误差分析,PSNR的定义如下:PSNR[dB]=其中,peak为模型包围盒的对角线长度,d为点到模型的距离。表2中描述了一些模型的误差与运行时间对比。从表2中可以看出,本文算法运行效率比较低,但是尖峰信噪比高,简化之后重构出来的模型质量好。
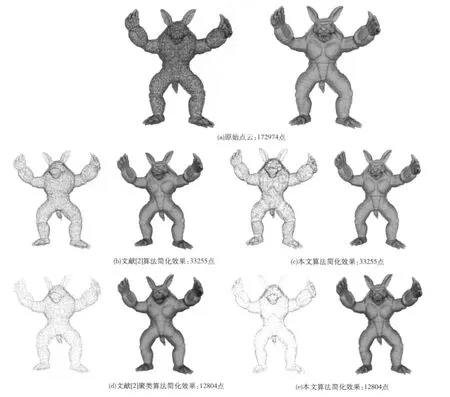
图3 对于Armadillo模型本文算法和文献[2]算法简化效果比较
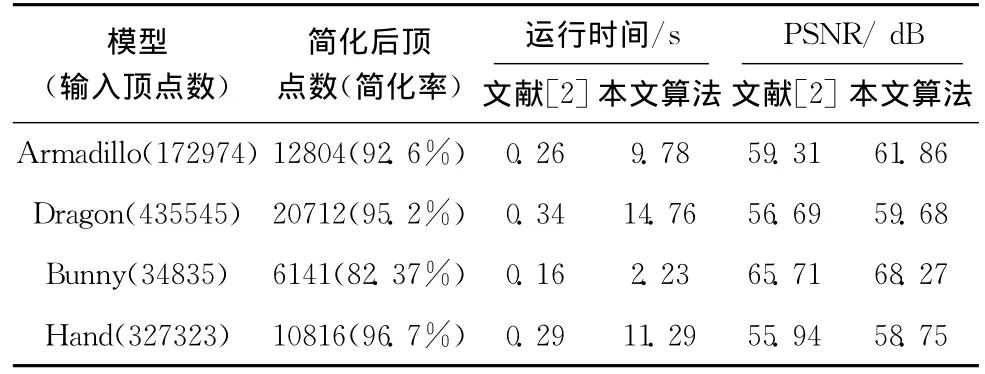
表2 简化后PSNR与运行时间对比
4 结束语
本文主要解决散乱点云数据的简化问题,主要思想是采用迭代简化的策略,通过建立一个与点的曲率和基函数支撑半径内点云密度相关的评估函数来评估点的重要性,然后更新并迭代删除评估函数值最小的点。实验结果表明,该方法能够精确地控制简化后点云的数量,产生的误差比较小,且能够较好地保持点云的特征,适合对简化后质量要求高的点云。
[1]Pauly M,Gross M,Kobbelt L P.Efficient simplification of point-sampled surfaces[C]//Boston:Proceedings of IEEE Visualization,2002:163-170.
[2]Brodsky D,Watson B.Model simplification through refinement[C]//Montreal:Proceedings of Graphics Interface,2000:221-228.
[3]ZOU Wanhong.Techniques for shape modeling from large scale point clouds[D].Zhejiang:Zhejiang University,2007(in Chinese).[邹万红.大规模点云模型几何造型技术研究[D].浙江:浙江大学,2007.]
[4]WANG Renfang,ZHANG Sanyuan,YE Xiuzi.Similaritybased simplification of point-sampled surfaces[J].Journal of Zhejiang University,2009,43(3):448-454(in Chinese).[王仁芳,张三元,叶修梓.基于相似性的点模型简化算法[J].浙江大学学报,2009,43(3):448-454.]
[5]Craig Schroeder,Wen Zheng,Ronald Fedkiw.Implicits sur-face tension formulation with a Lagrangian surface mesh on an Eulerian simulation grid[J].Journal of Computational Physics,2011(1):1-27.
[6]Bjorn Andersson,Stefan Jakobsson,Andreas Mark,et al.Modeling surface tension in SPH by interface reconstruction using radial basis functions[C]//Manchester:The 5th International SPHERIC Workshop,2010.
[7]TAN Yehao,JIANG Zhifang,DU Xiaoliang,et al.Visualization of multi-dimensional data with interpolation based on compactly supported radial basis functions[J].Computer Engineering and Applications,2010,46(9):220-223(in Chinese).[谭业浩,蒋志方,杜晓亮,等.紧支径向基函数插值实现多维数据可视化[J].计算机工程与应用,2010,46(9):220-223.]
[8]Wu Jinming,Lai Yisheng,Zhang Xiaolei.Radial basis functions for shape preserving planar interpolating curves[J].Journal of Information & Computational Science,2010,7(7):1453-1458.
[9]TIAN Jianlei,LIU Xumin,GUAN Yong.Implicit surface algorithm for holding features[J].Computer Engineering and Applications,2011,47(1):208-210(in Chinese).[田建磊,刘旭敏,关永.一种保特征的隐式曲面算法[J].计算机工程与应用,2011,47(1):208-210.]
[10]Masaki Kitago,Gopi M.Efficient and prioritized point subsampling for CSRBF compression[C]//Boston:Eurographics Symposium on Point-Based Graphics,2006:121-128.
[11]PANG Xufang,PANG Mingyong,XIAO Chunxia.An algorithm for extracting and enhancing valley-ridge features from point sets[J].Acta Automatica Sinica,2010,36(8):1073-1083(in Chinese).[庞旭芳,庞明勇,肖春霞.点云模型谷脊特征的提取与增强算法[J].自动化学报,2010,36(8):1073-1083.]
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学年刊A辑(中文版)(2022年1期)2022-08-20
农业工程学报(2022年7期)2022-07-09
数学物理学报(2022年2期)2022-04-26
汽车工程(2021年12期)2021-03-08
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
卷宗(2017年16期)2017-08-30
周口师范学院学报(2016年5期)2016-10-17
浙江大学学报(工学版)(2016年10期)2016-06-05
