
基于调度器的Hadoop性能优化方法研究
2013-11-30 05:01豆育升
计算机工程与设计 2013年1期
刘 娟,豆育升,何 晨,唐 红
(1.重庆邮电大学 计算机学院,重庆400065;2.重庆邮电大学 高性能计算与应用研究所,重庆400065)
0 引 言
Hadoop是开源的云计算[1]架构,主要由 MapReduce[2]编程模型 和 HDFS(hadoop distributed file system)[3]文件系统组成。目前,对Hadoop性能优化的研究主要有两种方法,一是基于配置文件的性能优化,从配置文件入手,改变配置参数以提高Hadoop集群的性能。主要的配置文件有 Conf下 面 的 Core-site.xml,Hdfs-site.xml和 Mapredsite.xml[4],这种优化方法在一定程度上能优化集群性能,但是也具有一定的局限性。一方面每个集群的硬件配置并不完全相同,每种优化方法并不一定适合所有的集群。另一方面,这种方法只能静态地对集群的配置参数作修改,在任务运行中不能根据需要动态地改变配置文件并使其生效。第二种方法是优化Hadoop调度器。因为调度器一旦在启动,整个任务运行过程将根据需要自适应变化,并且适用于不同硬件平台下的Hadoop集群,所以对Hadoop调度器的研究具有很大的现实意义。目前,Hadoop的调度器有3种,分别是Hadoop默认的FIFO[5]调度器,计算能力调度器[5],公平份额调度器[5]。其中FIFO是所有调度器的基础,然而此调度器按照作业提交先后顺序将作业排序,再根据这一顺序逐一把任务分发给各个节点执行,这就忽略了每个节点的实际负载情况。计算能力调度器能很好地支持内存密集型作业,公平调度器只是尽可能给每个任务分配等同的资源,都不能很好解决灵活性问题。本文即是在Hadoop默认调度器的基础上,提出一种基于CPU占用率作为负载指标的动态调度算法。该算法能有效解决默认FIFO调度器缺乏动态性和灵活性的问题,进而缩短Hadoop集群的任务整体响应时间。
1 Hadoop平台及默认调度器概述
Hadoop由核心组件MapReduce编程模型和HDFS分布式文件系统以及其他一些辅助组件组成。如图1所示,其中,MapReduce编程模型负责Hadoop所有的数据流和控制流,贯穿整个作业执行始末。JobTracker统一调度和分发任务,TaskTracker负责每一个子任务的执行,直到任务运行完毕。MapReduce的设计思想是:一个任务可以拆成多个子任务同时执行,然后将分解的多个任务按要求进行处理,将中间结果归并后统计出最后结果。MapReduce由Map和Reduce两部分组成,其中Map处理一个key/value对生成的中间键值对集合,Reduce接受一个中间key和它对应的值的集合并合并这些值以形成一个较小的值集合。MapReduce数学模型如下:
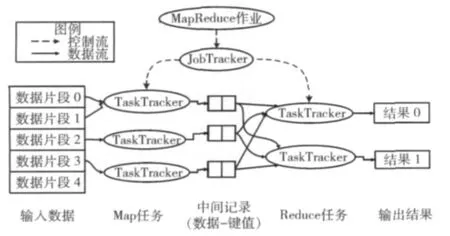
图1 Hadoop数据流和控制流
map:(k1,v1)→(list(k2,v2)[6]
reduce:(k2,list(v2))→(list(k3,v3)[6]
HDFS通过块级数据的分布冗余存储,负责所有临时的或者永久的数据存储工作。它采用主从模型,包含一个NameNode和一系列的DataNode,
NameNode负责管理HDFS文件系统,接受用户的请求,DataNode则用来存储数据文件。Hadoop整合 Map-Reduce和HDFS以及其他辅助层,将 Map-Reduce中的TaskTracker和HDFS中的DataNode部署在同一个计算节点上。
Hadoop默认的是FIFO调度器,用户在Hadoop客户端提交任务,调度器将所有用户的作业提交到一个队列中,JobTracker根据作业提交的先后顺序将作业排序,再根据这一顺序选择将要调度的任务并将任务分发给TaskTracker。TaskTracker接收JobTra-cker分配的任务并执行[7-8]。FIFO调度器使得JobTracker的工作负担较轻,每个Job都公平共享整个集群,但是同时也失去了灵活性和JobTracker动态调度的可能性。JobTracker不能把握每个Task-Tracker的实时负载能力,因为每个TaskTracker别无选择,只能被动地接受JobTracker分发的任务[9]。这样使得繁忙的节点更繁忙,空闲的节点更空闲,造成了系统资源的浪费。
2 Hadoop默认调度流程
Hadoop由JobTracker/TaskTracker主从结构[10]组成,且JobTracker在Hadoop集群中有且只有一个。用户提交任务给JobTracker后,在JobTracker的构造函数中,生成一个TaskScheduler成员变量,即默认的FIFO调度器,进行Job的调度,在JobTracker的OfferService函数中,调用TaskScheduler的Start函数启动FIFO调度器,调度器根据初始化配置和集群情况调度和分配任务。TaskTracker准备就绪后,向JobTracker报告自己当前的状态。而JobTracker返回给TaskTracker的HeartbeatResponse中已经包含了分配好的任务LaunchTaskAction。TaskTracker接收该任务,并根据任务类型(Map任务或者Reduce任务)执行任务。JobTracker/TaskTracker调度简图如图2所示。
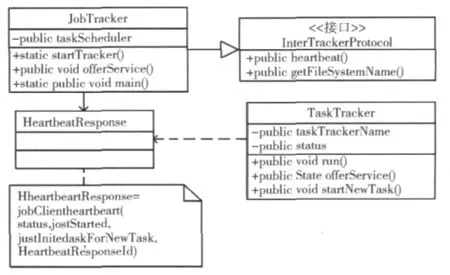
图2 JobTracker/TaskTracker调度简图
3 算法改进
3.1 算法描述
FIFO调度器只能完成简单的任务分发和执行,每个Job公平共享整个集群,但是JobTracker无法根据当前TaskTracker的负载情况实时判断当前节点是否还能继续高效地执行任务。基于此提出一种改进算法:在FIFO调度器的基础上,实时获取每个节点的CPU占用率,根据每个节点当前的CPU占用率判断节点的负载状态,将此占用率放入心跳包(HeartBeat)中,并反馈给JobTracker。当Job-Tracker启动调度器调度任务的时候,取出该值与CPU阈值比较,判断当前节点负载情况,从而决定是否应该继续给当前节点分配任务。调度流程如图3所示。
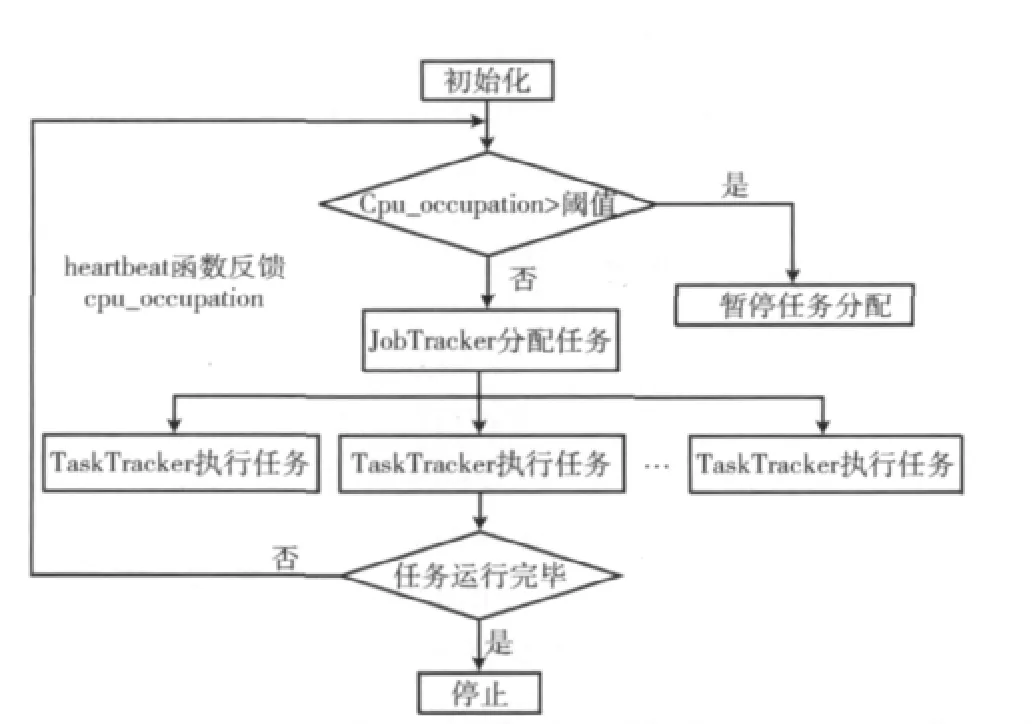
图3 Hadoop改进后的调度流程
该算法在每个TaskTracker中执行一个线程来获取CPU占用率。当JobClient类的SubmitJob函数提交Job后,JobTracker接受该任务,创建并初始化与Job有关的参数和一系列用来管理和调度任务的对象。Job分割成子任务后,由TaskTracker执行任务。即TaskTracker的Run函数一直链接JobTracker,如果链接成功,TaskTracker的OfferService函数会定期与JobTracker通信一次,报告自己任务的执行状态并接受JobTracker指令。TaskTracker还会调用TransmitHeartBeat函数获得HeartbeatResponse信息。然后调用HeartbeatResponse的getActions函数获得JobTracker传过来的指令即TaskTrackerAction数组,再根据数组类型决定应该执行的任务类型。TaskTracker和Job-Tracker的通信是由HeartBeat方法实现的。在原始版本的基础上,添加一个获取CPU占用率的线程,在OfferService函数中每隔一个心跳间隔启动一次该线程更新一次CPU占用率,这样就保证每次获取到的CPU占用率是最新的。将此占用率传递给HeartBeat函数,每次JobTracker和TaskTracker通信的时候,都会向JobTracker报告该CPU占用率,实时地与CPU阈值作比较,JobTracker再根据当前节点的负载情况分配任务。这样就做到了任务分配的实时性和动态性。以某节点为例,作浮点数运算测试,CPU占用率达到峰值0.95(阈值)时,CPU计算性能逐渐下降。可以得知,当实时获取的CPU占用率大于此阈值时,说明当前CPU处于繁忙状态。此时,JobTracker不能再向此节点分配任务,应该将任务分配给处于空闲状态的节点执行。直到当前节点的CPU占用率小于阈值时,Job-Tracker再继续向该节点分配任务,循环直到任务全部执行完成。这样就可以实时动态地调整集群的负载状况,进而使作业整体响应效率提高。
3.2 算法实现
本算法采用Java语言,将新增代码添加到Hadoop工程源代码中,在eclipse平台上重新编译生成jar包。
输入:用户提交的任务
输出:map/reduce计算出的结果
S1/*初始化集群参数 */
double cpu_occupation=-1;/* 默认 CPU 占用率*/
S2/*获取cpu占用率,intime_data是/proc/stat下的时间类*/
class SystemInfo implements Runnable
{public void get_occupy(intime_data o)
{File file=new File("/proc/stat");
BufferedReader br=new BufferedReader(new Input-StreamReader(new FileInputStream(file)));
String str=br.readLine();}
public double call_occupy(intime_data old,
intime_data new)
{return(1-(itime/(ntime-otime)))*100.0;}
}/*itime是空闲时间,(ntime-otime)为获取时间的时间间隔,返回获取的CPU占用率,此函数在SystemInfo线程中调用,SystemInfo将作为一个线程在每个Task-Tracker的offerservice()中启动,一直执行,实时获取CPU占用信息*/
S3/*根据实时获取的CPU占用率分配任务给Task-Tracker,通过Hadoop RPC机制将TaskTracker中的CPU占用率传入JobTracker中,JobTracker再将此占用率传入默认FIFO调度器中,调度器的任务分配函数分析判断后分配任务*/
HeartbeatResponse heartbeatResponse=
jobClient.heartbeat(status,justStarted,justInit-ed,askForNewTask,heartbeatResponseId,cpu _ occupation);/*将获得的cpu_occupation传入heartbeat心跳包中*/
{tasks=taskScheduler.assignTasks(taskTracker,
get(trackerName),cpu_occupation);
List<Task>assignTasks(TaskTracker
taskTracker,double cpu_occupan)
{/*初始化调度参数和环境*/
scheduleMaps:
{/*调度正式开始*/
if(cpu_occupan>=阈值)/*比较CPU占用率和阈值大小*/
{break scheduleMaps;}
else/*否则给TaskTracker分配任务*/
{/*计算可获得的时间槽*/
job.obtainNewLocalMapTask();
/*将任务传递给JVM执行*/}}
}
S4/*任务执行完毕,完成临时数据和状态的清理工作,Hadoop集群完成任务*/
4 实验结果分析
4.1 实验平台
操作系统Cenos5.6,带宽100M,8个节点,Intel双核,硬盘250G,内存2GB,jdk1.6.0-21,Hadoop源代码版本 hadoop-0.21.0。
4.2 测试与分析
本文基于Hadoop-0.21.0版本实现改进算法。将改进的源代码在eclipse上编译成jar包,分别是hadoopcore.jar,hadoop-mapred.jar,hadoop-hdfs.jar,将 3 个jar包分别部署在Hadoop集群的每个节点上并重启集群使其生效。实验采用Hadoop系统自带的terasort(计算集中型)基准测试程序。该程序实现数据排序的功能,是典型的CPU密集型程序,适用于本改进算法。实验分别对1百万字节,2百万字节,4百万字节和5百万字节的数据排序,在原始版本和改进版本上分别测试。为了减小测试结果的随机性,实验分别测试了10组数据取其平均值作为最终测试结果。实验结果如表1,2,3,4所示。表中记录了四组数据原始版和改进版的任务整体响应时间。可以得出,运行于改进版的四组数据的任务整体响应效率都有不同程度的提高,分别提高了2.1秒,3.8秒,5.4秒,7.8秒。直观对比如图4所示。
计算得出,改进版比原始版的作业整体响应效率(任务提高的时间/原始版本任务执行时间)至少提高了6%,如图6所示。并且,随着任务数据量的不断增加,任务的整体响应效率有快速提高的趋势,这将更利于长作业的运行。虽然实验测试数据呈倍数增长,但是任务执行效率的提升并没有按照倍数增长。这是因为,一方面,任何CPU的运算能力是有上限的,默认版本的CPU计算能力已经达到或者超过了CPU运算性能的最佳运算状态,本算法只改进了CPU的过载运算部分,使得在不影响CPU计算能力的情况下,最快地完成任务。另一方面,改进算法启动一个线程实时获取CPU占用率,此线程在实时获取CPU占用率的同时也耗费了一部分CPU计算资源。
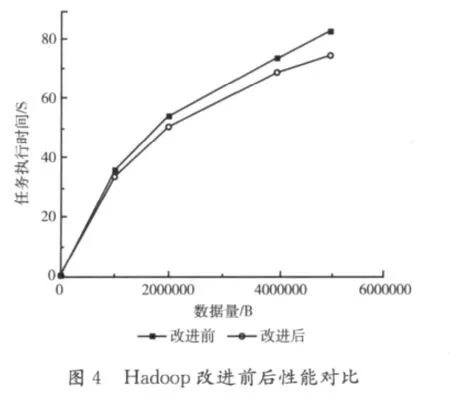
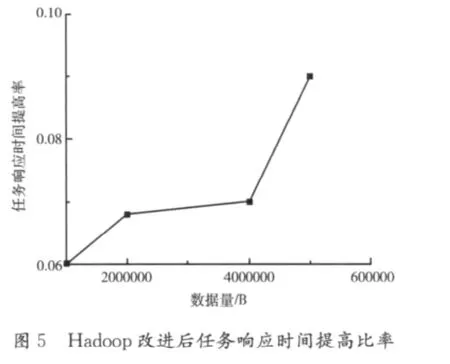

表1 1000000B数据测试结果

表2 2000000B数据测试结果

表3 4000000B数据测试结果

表4 5000000B数据测试结果
5 结束语
本文深入分析并改进了Hadoop默认任务调度模型,提出的以CPU占用率作为负载指标,在循环分配任务时根据反馈的负载指标判断节点负载情况的算法,确实提高了Hadoop的任务执行性能,最终缩短了任务整体响应时间解决了默认调度器缺乏动态性和灵活性的问题。经过Hadoop-0.21.0版本算法改进前后的实验对比分析可知,本算法在百万数量级上,至少提高了Hadoop集群6%的任务整体响应效率。本算法的最大缺点是没有考虑内存耗费情况,只是用计算集中型应用程序。未来将寻求一种耗费系统资源更少的方法来判断节点的动态性能。此外可以对任务进行排序,采用优先级策略实时响应更紧迫的任务。
[1]LIU Peng.Cloud computing[M].2nd ed.Beijing:Publishing House of Electronics Industry,2011(in Chinese).[刘鹏.云计算[M].2版.北京:电子工业出版社,2011.]
[2]Ger-hard W.Multiagent system:A modem approach to distributed artificial intelligence[M].[S,L]:MITPRE-SS,2007.
[3]LUO Yongjun,SHAO Zhiqing.Progress and prospects of standardization for agent technology[J].Computer Applications and Software,2009,26(3):179-183(in Chinese).[罗勇军,邵志清.Agent技术的标准化进度与前景[J].计算机应用与软件,2009,26(3):179-183.]
[4]LUAN Yajian,HUANG Chongmin,GONG Gaosheng,et al.Research on performance optimization of hadoop platform[J].Computer Engineering,2010,36(14):262-266(in Chinese).[栾亚建,黄翀民,龚高晟,等.Hadoop平台的性能优化研究[J].计算机工程,2010,36(14):262-266.]
[5]ZHAN Kunlin.Hadoop performance optimization[EB/OL].[2011-04-25] .http://wenku.baidu.com/vie/3a86c11118964bcf84b9d 57bce.html(in Chinese).[詹坤林.Hadoop性能优化[EB/OL].http:// wenku.baidu.com/vie/3a86c11118964bcf84b9d57bce.html,2011-04-25.]
[6]Tom White.Hadoop:The definitive guide[M].Beijing:Tsinghua University Press,2011(in Chinese).[Tom White.Hadoop:权威指南[M].北京:清华大学出版社,2011.]
[7]TIAN C,ZHOU H,HE Y,et al.A dynamic mapreduce scheduler for heterogeneous workloads[C]//Proceedings of the Eighth International Conference on Grid and Cooperative Computing.Washington,DC,USA:IEEE Computer Society,2009:218-224.
[8]Polo J,Carrera D,Becerra Y,et al.Performance driven task co-scheduling for mapreduce environment[C]//Network Operations and Management Symposium IEEE,2010:373-380.
[9]WANG Feng.The Hadoop algorithm of cluster Job scheduling[J].Programmer,2009(12):119-121(in Chinese).[王峰.Hadoop集群的作业调度算法[J].程序员,2009(12):119-121.]
[10]SUN Zhaoyu,YUAN Zhiping,HUANG Yuguang.The application of hadoop on the data-intensive computing[C]//The High Performance Computing Conference,2008:441-443(in Chinese).[孙兆玉,袁志平,黄字光.面向数据密集型计算Hadoop及其应用研究[C]//2008年全国高性能计算学术年会论文集,2008:44l-443.]
猜你喜欢
计算机工程与设计(2022年3期)2022-03-22
山西电子技术(2021年3期)2021-06-28
企业文化(2020年8期)2020-06-03
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
军事运筹与系统工程(2019年4期)2019-09-11
魅力中国(2019年6期)2019-07-21
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
