
软件测试用例执行优化研究
2013-11-30 05:29王吉茂张慧颖
计算机工程与设计 2013年12期
王吉茂,尹 平,张慧颖
(北京跟踪与通信技术研究所,北京100094)
0 引 言
测试用例执行优化的研究内容主要分两方面:一是在一组测试用例执行前调整测试用例的执行顺序;二是在测试用例执行过程中动态调整未执行测试用例的顺序。执行前调整测试用例的执行顺序是为了达到一定的测试性能指标,目前测试领域研究的测试性能指标主要包括需求的覆盖能力、代码的覆盖能力、错误探测能力、已发现错误的等级、测试耗费等,然而却缺少对多个测试用例的执行条件和期望结果之间联系的研究,导致测试执行时冗余操作增多;另外,按照测试理论的Pareto原则,80%的软件问题很可能集中在20%的程序模块中,在测试过程中提前执行与存在缺陷的软件模块相关的测试用例能够更加全面、集中地暴露软件问题,但目前缺少度量测试用例之间联系的方法以及基于这种度量的动态调整算法。因此,本文从测试用例执行条件和期望结果的关系入手设计了测试用例执行前优化算法,定义了测试用例距离的概念和计算方法并基于测试用例距离设计了执行中动态调整算法。
1 相关概念及工作
测试用例的执行优化是对已有测试用例按照某种特定的顺序执行,从而达到某些性能指标的调度过程[1],其具体的定义为[2]:对于某些测试套T,PT表示对T中元素所有可能的排列的集合;f表示应用于PT中每种排序的评价函数,输出的是每种排序的判定值,值越高效果越好。测试用例执行优化就是寻找一个T'∈PT,使得对于任意T'∈PT,都有f(T')≥f(T')。
1.1 测试用例执行前的优化算法概述
Rothermel等研究人员首先将测试用例集按照对代码的覆盖能力进行排序[3],然后分别使用排序前后的测试用例进行实际测试,对比测试效果,实验结果证明为测试用例设置优先级并排序能够提高测试中错误检测的速度和效率[4]。
在考虑代码覆盖能力方面,最著名的是基于MC/DC(modified condition/decision coverage)覆盖准则的排序研究。关于MC/DC的定义及基于MC/DC提出的测试用例优先级算法可以参见文献[5]。
对于该方法,Elbaum等认为其只考虑了覆盖因素和出现频率,而忽略了工程实践中的测试耗费问题[6]。在这个基础上,他们提出了综合考虑测试耗费和错误严重程度的测试用例优先级排序方法[7],在之前覆盖率标准上增加了对测试开销的考虑,优先级比较的标准改为单位覆盖消耗比率,同时结合错误严重程度重新评估测试用例的潜在探错能力。
测试用例执行前的排序还可以依据其错误探测能力来排序,可以将错误探测能力定义为发现错误的数量。采用基本贪心算法将测试用例按照错误探测能力从大到小排序,然后依次执行直到所有的错误都被探测出来。额外贪心算法则是在每次取用测试用例的时候,根据剩下的未被探测出来的错误动态更新测试用例的探错能力,再采用贪心策略选用测试用例。之所以要设计额外贪心策略,是由于基本贪心策略会选择到不必要的测试用例,但额外贪心策略容易陷入局部最优。
依据错误探测能力,还可以利用启发式方法来对测试用例进行排序。较典型的有爬山算法。作为深度优先搜索的一种改进,爬山算法利用反馈信息帮助生成解的决策,是一种局部搜索算法。该算法的优点在于不必进行遍历,通过只选择部分节点来提高效率,缺点在于不能全局搜索,容易陷入局部最优。
北京系统工程研究所的杨广华、包阳等人研究了基于需求的测试用例优先级排序算法,包括对首次测试和回归测试的测试用例的优先级排序。
首次测试的优先级排序可以分为根据需求的优先级RP(requirement priority)排序、需求变更情况RM (requirement modify)排序、实现复杂度 (implementation complexity)排序。其中根据需求的优先级排序是由于按这种方式排序可以提高测试的效益,因为据统计,用户经常使用的软件功能只占该软件所有功能的40%左右;按照需求变更情况来排序是由于需求的变更是引入软件缺陷的一个重要原因,而在软件完成之前平均有25%的需求会发生变更;另外,复杂程度较高的软件模块通常存在较多的缺陷,因此重点测试复杂程度较高的软件模块能提高发现软件缺陷的效率。
回归测试用例优先级排序考虑之前测试发现软件缺陷的情况,根据检测到不同缺陷严重性等级对测试用例的错误探测能力进行赋值,然后根据赋值情况提高缺陷探测能力较高的测试用例的优先级。
1.2 测试用例执行中的优化算法概述
除了可以在测试用例执行之前对其进行优化排序,还可以在测试用例执行中对未执行测试用例的执行顺序进行动态调整,以达到在短时间内高效测试的目的。
戴如昕、顾春华研究了通过调整测试用例的执行顺序的测试用例优先级方法[8]。这种方法首先根据测试用例可能暴露的错误类型建立一个关系矩阵R。根据矩阵R,测试用例被其可能暴露的错误类型分成不同的组,然后该方法调用Escalate(提高算法)和Deescalate(降低算法)来调整用例的优先级。在这两种算法中都有一个输入参数a来确定优先级的调整幅度。在实际执行中,如果某个测试用例暴露了软件问题,说明软件在这方面存在隐患,提前执行同组的同类型测试用例,从而有助于更高效地发现此问题的各个方面。
在测试用例执行过程中,根据实时反馈的信息 (主要是未完成的测试目的或未覆盖的测试需求),将剩余的测试用例不断地进行顺序调整。当返回多个反馈信息时,这种调整还可以不是单队列的,而是在并行的情况下进行多个测试用例队列同时调整[9]。并行调整可以增加调整系统对反馈信息的容纳能力,避免了单队列出现反复调整的情况,但多队列增加了算法的复杂度。
2 测试路径控制阵列
为了能够兼顾测试用例执行前和执行中的优化算法,本文首先提出测试用例的组织模型:测试路径控制阵列(test path control array,TPCA)。下面对该模型进行说明
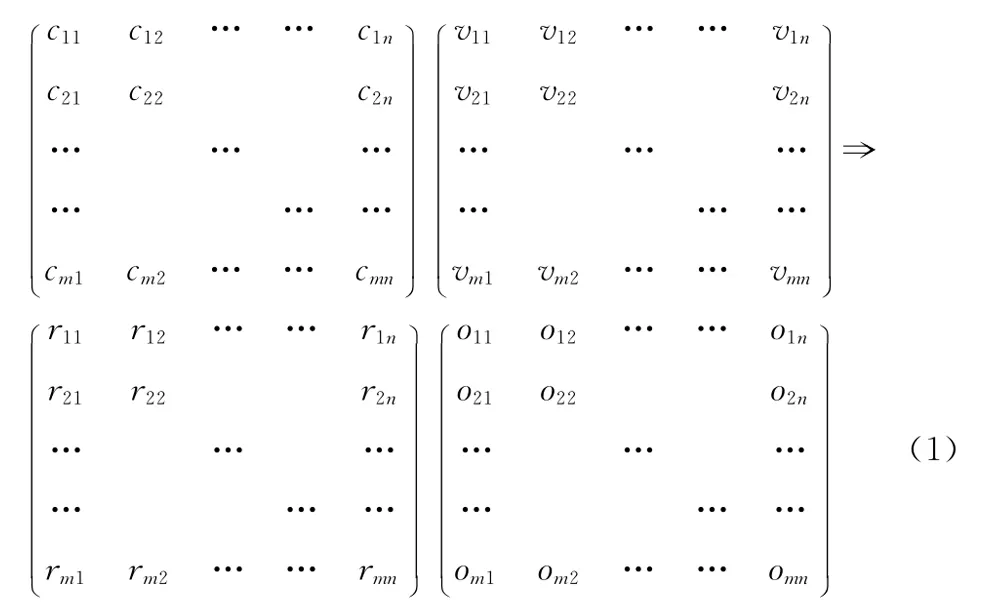
式 (1)可简写为

C、V、R、O均是m×n的阵列 (并非矩阵),表示针对同一个被测功能项的m个测试用例的数据。
C为输入控制阵列,其每一行表示一个测试用例的输入控制量,输入可以包括软件当前状态、将要发生的事件和参数取值。C中的元素cij表示第i个测试用例的第j个输入控制量,取值为0或1。cij取值为0表示V中的输入vij状态值无效、事件不发生或参数取值无效,取值为1表示V中的输入vij状态值有效、事件发生或参数取值有效。
V为输入阵列,其每一行表示一个测试用例的输入值,每个测试用例最多有n个输入值。vij可以表示一个状态值、事件 (0为不发生、1为发生)、输入参数的具体取值。
R为期望结果控制阵列 (或输出控制阵列),其每一行表示一个测试用例的输出控制量,输出可以包括测试用例执行后软件预期状态、预期发生的事件和参数取值。R中的元素rij表示第i个测试用例的第j个输出控制量,取值为0或1。rij取值为0表示O中的输出oij状态值无效、事件不发生或参数值无效,取值为1表示O中的输出oij状态值有效、事件发生或参数取值有效。
O为输出阵列,其每一行表示一个测试用例的输出值,每个测试用例最多有n个输出值。当R中的rij=1且rij表示输出参数控制量时,oij为第i个测试用例的第j个输出参数的取值。vij可以表示一个状态值、事件 (0为不发生、1为发生)、输出参数的具体取值。
3 测试用例执行前优化算法
3.1 算法说明
在执行一个测试用例前通常要对软件的运行环境、状态、参数等进行初始化设置,而测试用例执行结束后会产生执行结果。两个测试用例,其输入条件和输出结果之间可能存在下面定义的情况。
定义1 设A、B为两个测试用例,A.Conditions表示A执行前的输入条件,A.Results表示A执行后的输出和软件状 态的变化,B同理。若存在{A.Results}∩{B.Conditions}≠ ,则称为创造场景条件{A.Results}∩{B.Conditions}而进行的操作为重复操作。
定义2 N{A.Results}∩{B.Conditions}为执行测试用例B所需的输入条件中,测试用例A在执行后能为其产生的、测试人员无须进行重复输入的操作步骤数,称为操作重复度。
操作重复度定量描述了测试用例之间的联系。操作重复度不为零的两个测试用例在执行顺序上应该被安排在相邻的位置。尤其是针对运行状态众多,各状态转换关系复杂的软件,需要设计一种算法来寻找操作重复度之和最大的测试用例执行顺序,该问题建模如下:
设X={Xi|i=1……n}是测试用例的集合,且对于任意测试用例Xi、Xj,二者之间的操作重复度N{Xi.Results}∩{Xj.Conditions}已知,求 X中测试用例的一个排序,该排序满足操作重复度之和最大,即

这个排序问题可以转化为图论中寻找带权有向图G(X,E)遍历所有节点的最大路径问题,其中X中的测试用例是有向图中的节点,E是权值为N{Xi.Results}∩{Xj.Conditions}的边的集合。如果某个测试用例执行条件或期望结果与其他测试用例没有联系,则设其对应边权值为0,但仍认为该边存在。因此G (X,E)可以视为一个有向完全图。
图论中解决有向图节点排序 (即有向图活动规划)的方法有AOV网络和AOE网络。但AOV网络的活动在节点上,拓扑排序仅能确定图中是否有环,不涉及边权值的问题;AOE网络的活动在边上,可以求解出活动节点的关键路径,但并不能做到对节点的完全覆盖[10]。因此两种算法都不适用于测试用例排序。
虽然目前没有现成的解法适用于这个问题。但实际测试中,一个测试用例执行完成只对其他测试用例特定输入条 件 提 供 便 利。例 如,A.Conditions={a,b,c},B.Results={b,c},C.Results={c},当B执行后,执行测试用例A只需要创造条件a即可,此时再执行C不会给A提供任何便利。这说明一个测试用例执行后就会给其他测试用例带来影响,而且影响具体到某一个特定的软件状态,而不仅仅是状态数量的概念。
因此,从减少操作步骤这个目的出发,以贪心策略为指导思想,借鉴AOV网络拓扑排序中逐个取节点的方法,设计出如下有向图节点排序算法:
首先定义数据结构
节点 (代表测试用例):


算法流程如图1所示。

图1 测试用例执行前优化算法
3.2 应用验证
以航天测控系统实时系统软件主副机切换功能的32个测试用例为优化排序的对象。
在经3.1节算法优化前,测试用例按照编号从小到大的顺序执行。经3.1节优化后,测试用例执行顺序为4、16、2、8、14、0、18、24、30、19、25、31、3、9、15、1、7、13、17、23、29、5、11、21、27、10、6、20、12、26、22、28。优化排序使当前测试用例期望结果中软件的状态与下一个测试用例执行所需的输入条件十分接近,冗余操作明显减少。
在假设32个测试用例全部执行通过的情况下,本文统计了所有测试用例的总步骤数、测试用例按0到31顺序执行省去的步骤数以及经优化排序后省去的步骤数,优化效果见表1。

表1 优化效果
4 测试用例执行中动态调整算法
4.1 算法说明
本算法基于测试用例距离,因此首先给出测试用例距离的定义,用以衡量测试用例的相似程度。
定义3 测试用例距离dij

其中,λk表示第k个参数赋值的权重系数,视测试结果对该输入的敏感程度由测试人员来确定。没有赋值操作或者该参数值对测试结果没有影响的测试用例,该值为0。
cij和vij来源于测试路径控制阵列中的C阵列和V阵列;v'ij是通过对输入参数vij归一化得到的,归一化方法为:由于输入参数vij的取值范围可以被划分成若干个等价类,一个等价类的数值范围可能很大,例如,如果在等价类[1,10000]中vij=2或vij=9999时软件的执行结果没有差异,则定义当vij取值来自于同一个有效类的时候,v'ij取值为同一个正整数q;同理,当vij取值来自于同一个无效类的时候,v'ij取值为同一个负整数p;当vij取值为边界值时,v'ij取值为0。
当测试用例i检测到软件问题时,定义测试用例i为目标测试用例。给定测试用例距离d,如果dij<d,则认为测试用例j与i属于相关测试用例,测试用例j应被提前执行。d通常由经验值给出。
对于一个给定的d,可能存在多个测试用例与目标测试用例是相关测试用例,但这些测试用例与目标测试用例的测试用例距离可能不同。相关性较强的测试用例应当优先执行,即按照测试用例距离递增的顺序调整,其具体实现流程如图2所示。
4.2 应用验证
这里仍以实时系统软件的主副机切换功能的测试用例来验证上节的算法对测试用例执行顺序的动态调整效果。
在API请求切换程序模块中设置一个软件缺陷,使API请求不能成功切换主副机。与缺陷有关的测试用例集合为{0,2,4,6,8,16,18,20,22}。

图2 基于距离的动态调整算法流程
按照3.2节优化后的测试用例执行顺序执行32个测试用例。在执行测试用例4时,该测试用例不通过,现象为:在自动模式、主副机均运行的情况下,被测软件不能实现通过API请求将运行机从主机切换到副机。
用基于测试用例距离的动态调整算法对未执行测试用例排序。现在,目标测试用例为测试用例4,按照式 (3)给定测试用例距离阈值d=1.8,自动模式、API请求的权重为3,其他输入的权重为0.25,通过程序寻找与目标测试用例的测试用例距离小于1.8的测试用例。
算法程序找到了10个测试用例{4,8,6,0,2,20,24,22,16,18},虽然多出一个测试用例24,但包含了与缺陷相关的测试用例,并且优化算法把与缺陷相关的测试用例6、20、22提前到前10位执行。
5 结束语
本文在研究现有的测试用例执行优化方法的基础上,首先提出测试路径控制阵列模型来组织测试用例;然后从图论角度出发提出测试用例执行前的优化排序算法;最后提出了测试用例距离的概念和计算方法,并基于测试用例距离提出测试用例执行中动态调整算法。将以上两个算法应用于实时系统软件主副机切换功能的测试用例中,优化结果表明,执行前优化排序算法能够减少一组测试用例的冗余操作,执行中动态调整算法能够找到与软件缺陷相关的测试用例并将其执行顺序提前。
[1]JIANG Shanshan,ZHAO Zhonghua,WANG Qiming,et al.A requirement-based approach to system-level black-box test case prioritization[J].Computer and Digital Engineering,2010,38(5):68-73 (in Chinese).[姜姗姗,赵中华,王启明,等.基于需求的系统级黑盒测试用例优先化方法[J].计算机与数字工程,2010,38 (5):68-73.]
[2]Moisiadis F.Prioritizing test cases and scenarios[C]//37th International Conference on Technology of OO Languages and Systems,2000:108-119.
[3]Wong We,Horgan JR,London S,et al.A study of effective regression testing in practice[C]//Proceedings of the 8th IEEE International Symposium on Software Reliability Engineering.Washington IEEE Computer Society,1997:264-274.
[4]Rothermel G,Untch H R,Chu C,et al.Test case prioritization:An empirical study[C]//Proceedings of the International Conference on Software Maintnance.Washington:IEEE Computer Society,2001:179-188.
[5]LU Dezhong.Research for modified condition/design test case priorty algorithm[J].Science and Engineer,2009,9 (14):4040-4044 (in Chinese).[卢德忠.基于 MC/DC的测试用例优先级 算 法 研 究[J].科 学 技 术 与 工 程,2009,9 (14):4040-4044.]
[6]Elbaum S,Malishevsky G,Rothermel G.Incorporating varying test costs and faults verities into test case prioritization[C]//Proceedings of the International Conference on Software Engineering,2001:329-338.
[7]QU Bo,NIE Changhai,XU Baowen.Survey of test case priori tization for regression testing[J].Journal of Frontiers of Computer Science and Technology,2009,3 (1):225-233 (in Chinese).[屈波,聂长海,徐宝文.回归测试中测试用例优先级技术综述[J].计算机科学与探索,2009,3 (1):225-233.]
[8]DAI Ruxin,GU Chunhua.Advanced test case prioritization for black box testing[J].Computer Engineering and Design,2010,31 (20):4343-4346 (in Chinese).[戴如昕,顾春华.用于黑盒测试的测试用例优先级改进算法[J].计算机工程与设计,2010,31 (20):4343-4346.]
[9]QU Bo,XU Baowen,NIE Changhai.A dynamic prioritization method for supplemental test cases[J].Journal of Shandong University,2009,39 (2):137-140 (in Chinese).[屈波,徐宝文,聂长海.补充生成测试用例的优先级设定与动态调整算法[J].山东大学学报,2009,39 (2):137-140.]
[10]WANG Guiping,WANG Yan,REN Jiachen.Algorithm,implementation and application of graph theories[M].Beijing:Press of Peking University,2011:63-82 (in Chinese).[王桂平,王衍,任嘉辰.图论算法理论、实现及应用[M].北京:北京大学出版社,2011:63-82.]
猜你喜欢
今日农业(2021年14期)2021-11-25
名家名作(2021年4期)2021-05-12
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
意林(2020年10期)2020-06-01
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
证券市场红周刊(2018年5期)2018-05-14
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
时代英语·高三(2014年5期)2014-08-26
