
Hibernate的缓存机制及其应用的研究
2013-11-26 09:01董黎刚
杭州电子科技大学学报(自然科学版) 2013年5期
曹 伟,应 君,董黎刚
(浙江工商大学信息与电子工程学院,浙江杭州310018)
0 引言
在软件系统开发中,数据库操作是影响软件系统整体性能的一个关键因素,如何获得更加高效的数据读写是个一直被人们反复研究、探索的问题。在Hibernate诞生前,开发人员使用JDBC来实现与数据库的交互,然而这种解决方案封装性差,开发难度大[1]。Hibernate的诞生为面向对象的编程推波助澜。国外一些开发人员已经对Hibernate进行了详尽的剖析,其中文献1提到Hibernate为数据库操作优化带来的巨大改进。但开发中Hibernate的运行效率又被认为不如JDBC[2]。其中缓存机制没有得到合理应用是一个不可忽视的原因。本文将剖析如何利用Hibernate的缓存机制来提高数据读写效率,从而提升软件性能。
1 缓存概念
缓存是介于应用程序和物理数据源之间,其作用是为了降低应用程序对物理数据源访问的频次,从而提高了应用的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
Hibernate的缓存结构如图1所示,可分为一级缓存、二级缓存和查询缓存[3]。
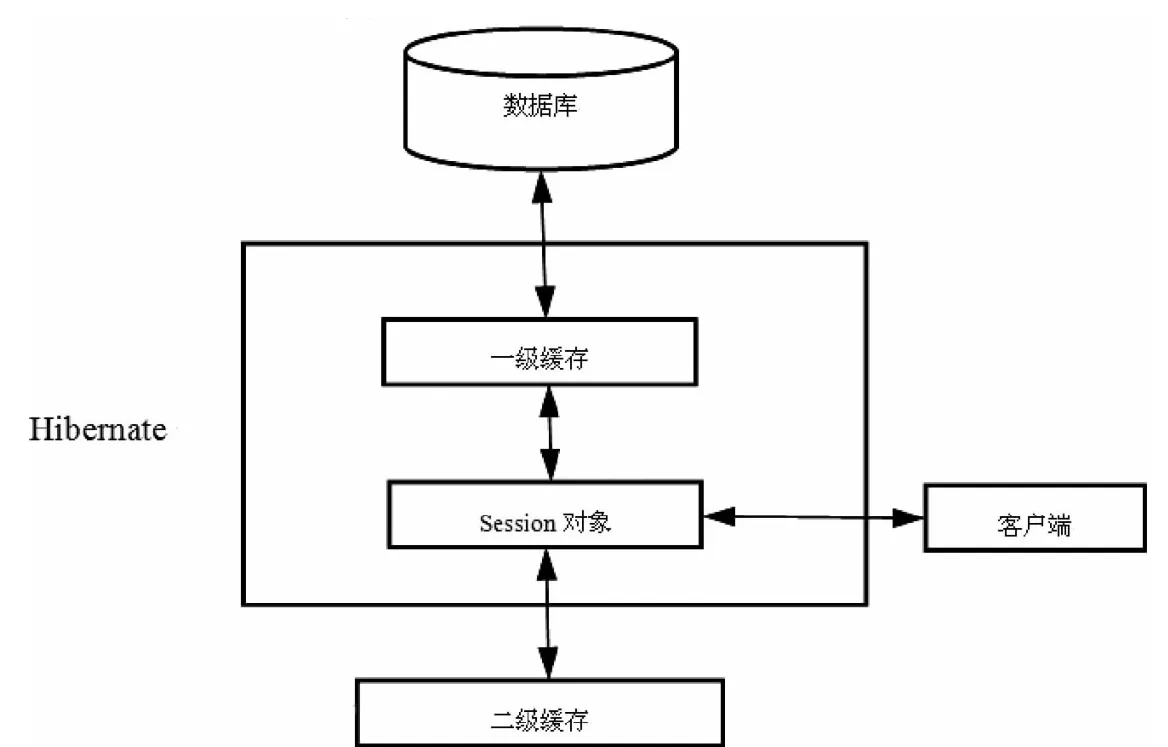
图1 Hibernate缓存结构
1.1 一级缓存
一级缓存是Session内部的缓存,不能被卸载或者删除,它随着Session的产生而产生,也随着Session的灭亡而消失。在一级缓存中,持久化类的每个实例都具有唯一的OID。当一个Session对象中对某一个数据对象进行save()、update()、save Or Update()等操作时都会将该对象存储在Session的内部缓存中。当再次请求同一个数据对象时会首先在一级缓存中查询。如此便可有效解决频繁提交数据库操作的问题。
然而,Hibernate的Session生命周期非常短暂,且Session内的缓存不能被其他Session访问,而实际应用中又有这样的需求,此时可利用Hibernate的二级缓存来解决这个问题。
1.2 二级缓存
在Hibernate中,所有的Session都由同一个Session Factory实例来产生[4]。而二级缓存就是Session-Factory级别的缓存,可在不同Session对象间共享,它属于进程范围或群集范围的缓存。二级缓存可进行配置和更改,并且可以动态加载和卸载[5]。
当Hibernate根据ID访问数据对象的时候,使用二级缓存的数据查询操作如图2所示。
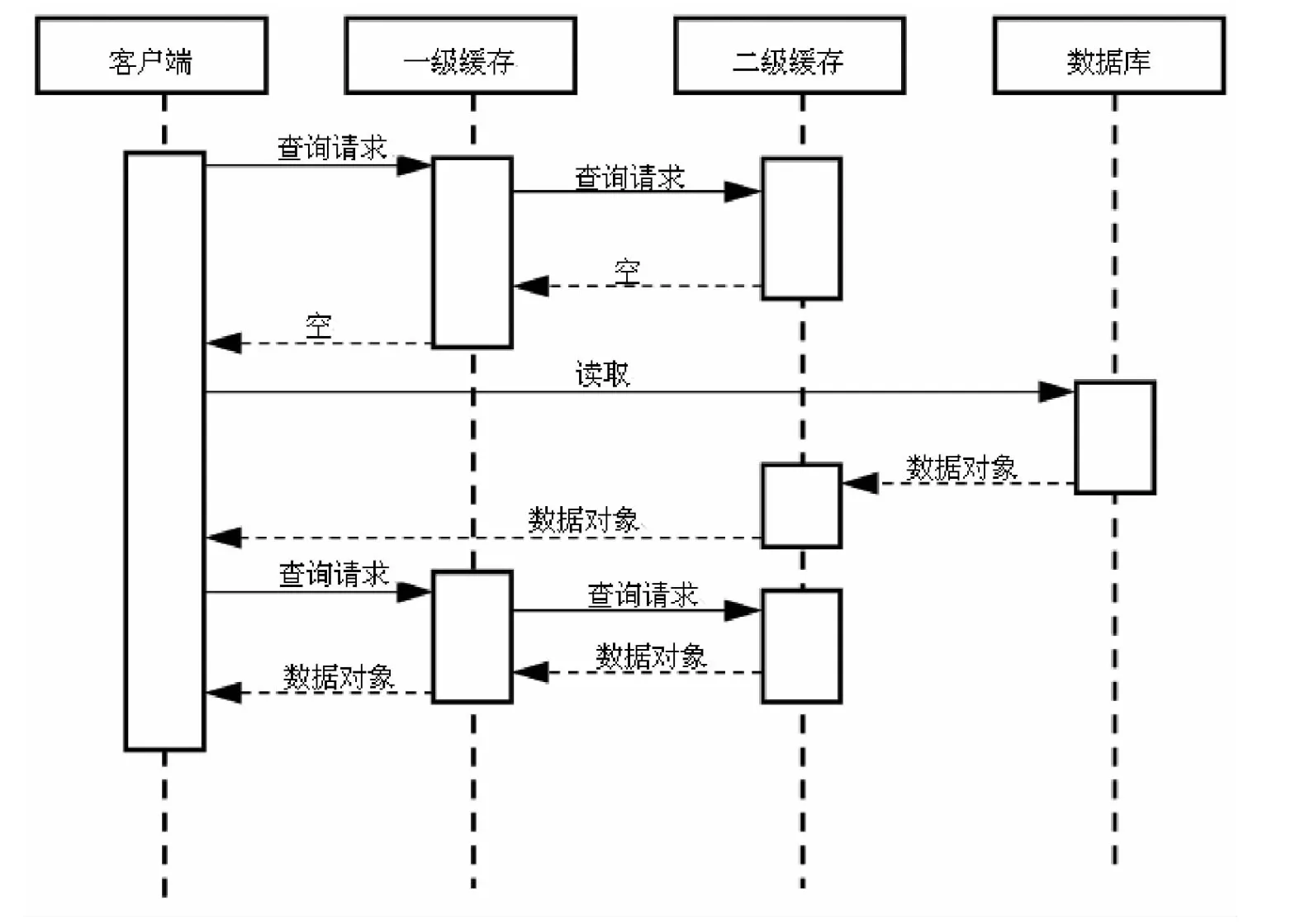
图2 时序图
当Hibernate发现二级缓存中已经有了该条数据,就会直接拿来用,而不必去数据库查询,当二级缓存中没有找到时才会到数据库中取。
试想,当有N个客户端请求同一个数据对象时如图3所示,如果系统开启了二级缓存,那么至少可以减少N-1条数据库通信消息,尤其当这个数据对象经常被访问的时候,二级缓存的优势将十分明显。

图3 多客户端访问
但是,二级缓存都基于ID来识别对象的[6],如果希望使用条件查询那么二级缓存就无用武之地了。为了解决这个问题,Hibernate在设计中就构造了一个查询缓存也称之为三级缓存。
1.3 查询缓存
所谓查询缓存(Query Cache)就是针对条件查询而分配的缓存,它依赖于二级缓存。当使用同样的查询条件时,Hibernate会从查询缓存中直接取出结果。Query Cache用来缓存查询语句,及查询结果集中对象的Identifier与Type.当再次使用已缓存的Query时,就可以通过对象的Identifier与Type在二级缓存中查找实际的对象[7]。查询缓存的应用范围非常有限,因为它对查询条件非常敏感,查询命中率低。比如第一条hql取1 20条数据,第二条hql取1 10条数据,Hibernate会认为这是两个完全不同的查询条件,无法利用查询缓存,会直接向数据库发起查询。
2 Hibernate缓存机制的应用
一个站点的首页经常被用户访问,且每次访问时前台都需要去后台读取数据,当站点的访问量较大时后台会很容易出现卡顿、瘫痪等现象。此时如果采用Hibernate缓存机制可以有效减少数据库操作,大大提高后台的承压能力。以EhCache为例模拟10万用户访问站点的情形,并演示Hibernate缓存机制是如何优化服务器性能的。
2.1 开启Hibernate缓存
在Hibernate的配置文件中进行如下配置:

针对使用二级缓存的类进行注解:

该类在二级缓存中并发策略为Read-write即可读写。
2.2 配置自定义缓存策略
这里采用EhCache默认的缓存策略即可。
2.3 选择最优策略
当决定将一个数据加载到二级缓存中时,需要考虑该数据是否经常被访问,是否经常被更改,是否会被第三方修改等因素。并非所有的数据都适合载入缓存,这里用户访问站点首页的模块信息不会频繁更改,数据量小,非常适合加载到二级缓存中。
2.4 模拟10万用户访问站点

2.5 测试结果
当开启了Hibernate缓存后,模拟10万用户去访问数据,只有第一个用户发出了SQL语句,并且取出数据放入缓存中,之后访问的用户直接去缓存中取,大大提高了效率。总共用时17 585ms。
当关闭Hibernate缓存后,模拟10万用户去访问数据库,服务器迟迟没有响应,基本上处于瘫痪状态。可见Hibernate缓存机制在这里起到了非常重要的作用。
3 结束语
缓存技术在软件系统中是把双刃剑,利用得当将大幅度提升系统性能,利用不当反而会降低系统的响应速度。在数据量较小的软件系统中它并不能发挥太大的作用,但是在数据量庞大的系统中,巧妙地配置缓存能够实现非常显著性能优化作用。
[1] Dipti Phutela.Hibernate Vs JDBC[EB/OL].http://www.mindfiresolutions.com/mindfire/Java_Hibernate_JDBC.pdf,2011-06-17.
[2] Jihuanliang.jdbc与 hibernate性能比较总结[EB/OL].http://blog.csdn.net/jihuanliang/article/details/7965278,2012-09-11.
[3] tutorialspoint.Hibernate Caching[EB/OL].http://www.tutorialspoint.com/hibernate/hibernate_caching.htm,2013-01-20.
[4] 杨帆.设计模式从入门到精通[M].北京:电子工业出版社,2010:21-42.
[5] 付京周.精通 Hibernate 3.0——Java数据库持久层开发实践[M].北京:人民邮电大学出版社,2007:307-312.
[6] joyimp.hibernate二级缓存的管理[EB/OL].http://hi.baidu.com/webkiss/item/71e07789ebb16f55850fab0c,2011-05-09.
[7] goncha.关于 Hibernate Cache[EB/OL].http://www.iteye.com/topic/6593,2004-08-02.
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
电脑报(2019年12期)2019-09-10
中国计算机报(2018年30期)2018-11-12
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
浙江大学学报(工学版)(2015年2期)2015-05-30
土木建筑工程信息技术(2013年4期)2013-10-17
