
基于小语音库的语音识别技术研究*
2013-11-23 04:18
舰船电子工程 2013年5期
(中国人民解放军63888部队 济源 459000)
1 引言
目前语音通信干扰效果评估系统中,一般是首先建立无线电台通信专向,发方发送语音报文或键报,被试干扰设备进行干扰,收方进行报文抄收;然后将所抄报文与报底校对,计算报文正确率来评估干扰设备的干扰效果,以鉴定设备性能是否达到技术指标要求。这种主观评估方法过程中存在许多人为因素,如抄报人员的抄收水平、精神状态以及对方报文发送的规范与否等因素,都会对评估结果带来一定影响。
随着通信技术不断提高,语音通信干扰效果评估方法在逐步向客观评估转变,本文在介绍客观评估系统的基础上,分析研究了语音识别关键技术,以及基于小语音库的语音识别技术在客观评估系统中的应用,并给出了应用方法。
2 客观评估系统概述
语音通信干扰客观评估系统通过比对受干扰前的原始语音与受干扰后的语音的参数特征,实现干扰效果的客观评估。系统组成包括报文产生及控制终端、发信电台、收信电台、语音处理终端、收端计算机等,系统功能框图如图1所示。
系统工作流程为:发送端计算机将数字报文转换成语音报文(.wav文件),并产生控制信号控制电台(PTT)进行发射,同时将已产生的语音报文通过音频输出系统送入电台音频口,由电台将语音报文自动发送出去;在接收端,将无线电台输出的音频送入计算机,由计算机进行音频采集,基于小语音库范围进行语音识别,最后与发送端的报文比较进行报文判决,给出误码率。
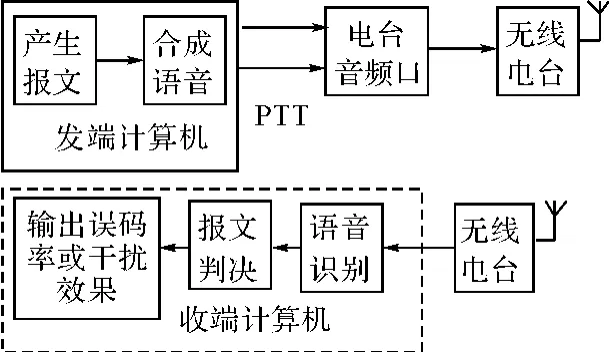
图1 系统功能框图
3 语音识别关键技术
语音识别系统基本构造如图2所示。
系统分为前端处理和后端处理两部分,前端处理部分包括语音的录入、处理、特征值的提取。后端处理是一个跨数据库的搜索过程,分为训练和识别,训练是对所建的模型进行评估、匹配、优化,获得模型参数;识别是一个专用的搜索数据库过程。获取前端数值后,在声学模型、语言模型和字典中进行匹配。声学模型表示一种语言的发音,可以通过训练来识别特定用户的语音模型和发音环境的特征。语言模型是对语料库单词规则化的概率模型。字典列出了大量的单词及发音规则[1]。
总体上说语音识别是一个模式识别、匹配的过程,在这个过程中,计算机首先要根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。然后,在识别过程中,计算机根据语音识别的整体模型,将计算机中已经存有的语音模板与输入语音信号的特征进行比较,并根据一定的搜索和匹配策略找出一系列最优的与输入语音匹配的模板。最后通过查表和判决算法给出识别结果[2]。
模型训练是指按照一定的准则,从大量已知模式中获取表征该模式本质特征的模型参数,而模式匹配则是根据一定准则,使未知模式与模型库中的某一个模型获得最佳匹配。显然,识别结果与语音特征的选择、声学模型和语言模型的好坏、模板是否准确等都有直接的关系[3]。
3.1 语音识别单元的选取
选择识别单元是语音识别研究的第一步,语音识别单元有单词(句)、音节和音素三种,应该根据具体研究的识别系统的特点,选择具体的识别单元。
单词(句)单元广泛应用于中小词汇语音识别系统,但不适合大词汇系统,原因在于模型库太庞大,训练模型任务繁重,模型匹配算法复杂,难以满足实时性要求。
音节单元多见于汉语语音识别,因为汉语是单音节结构的语言,而英语是多音节语言。汉语大约有1300 个音节,如果不考虑声调,约有408个无调音节,数量相对较少。因此,对于中、大词汇量汉语语音识别系统来说,以音节为识别单元基本是可行的。
音素单元以前多见于英语语音识别的研究中,但目前中、大词汇量汉语语音识别系统也在越来越多地被采用。汉语音节仅由声母和韵母构成,而且声、韵母声学特性相差很大。在实际应用中常把声母依后续韵母的不同而构成细化声母,这样虽然增加了模型数目,但提高了易混淆音节的区分能力。
3.2 特征参数提取
语音信号中含有丰富的信息,如何从中提取出对语音识别有用的信息是语音识别的关键。特征提取就是完成这项工作,它对语音信号进行分析处理,去除对语音识别无关紧要的冗余信息,获得影响语音识别的重要信息。对于非特定人语音识别来讲,希望特征参数尽可能多地反映语义信息,尽量减少说话人的个人信息(对特定人语音识别来讲,则相反)。从信息论角度讲,这是信息压缩的过程。
线性预测(LP)分析技术是目前应用比较广泛的特征参数提取技术,许多成功的应用系统都采用基于LP 技术提取的倒谱参数。但线性预测模型是纯数学模型,没有考虑人类听觉系统对语音的处理特点。
Mel参数和基于感知线性预测(PLP)分析提取的感知线性预测倒谱,在一定程度上模拟了人耳对语音的处理特点,应用了人耳听觉感知方面的一些研究成果[4]。实验证明,采用这种技术能使语音识别系统的性能有一定提高。
MFCC 的分析着眼于人耳的听觉特性,因为人耳所听到的声音的高低与声音的频率并不成线性正比关系,而用MEL频率尺度则更符合人耳的听觉特性。MEL 频率与实际频率的具体关系可用公式(1)表示:
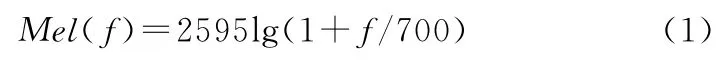
实际频率f的单位是Hz。根据Zwicker的工作,临界频率带宽随着频率的变化而变化,并与Mel频率的增长一致,在1000Hz以下,大致呈线性分布,带宽为100Hz左右,在1000Hz以上呈对数增长[5]。
3.3 语音模型的选择
HMM 模型是语音信号时变特征的有参表示法。它由相互关联的两个随机过程共同描述信号的统计特性。其中一个是隐蔽的(不可观测的)具有有限状态的马尔可夫链,另一个是与马尔可夫链的每一状态相关联的观察矢量的随机过程(可观测的)。隐蔽马尔可夫链的特征要靠可观测到的信号特征揭示。这样,语音等时变信号某一段的特征就由对应状态观察符号的随机过程描述,而信号随时间的变化由隐蔽马尔可夫链的转移概率描述。
HMM 模型在某状态j下对应的观察值可以由一组概率bjk(k=1,2,…,M)来描述,它是M个离散可数的观察值中的一个,因而称为离散HMM[6]。当观察值为一个连续的随机变量X,其在状态j下对应的观察值由一个观察概率密度函数bj(X)表示,这就成了连续的HMM。连续的HMM 用Baum-We1ch算法估计模型参数时,虽然在估计π,A参数时适用,但在估计描述bj(X)的参数时必须对bj(X)加以一定的限制才能成立。目前运用最广泛的是高斯型bj(X)[7],它可以用下面公式表示:

其中,N(X,μjk,∑jk)为多维高斯概率函数,μjk为均值矢量,∑jk为方差矩阵,K为bjk(X)的混合概率个数,Cj(X)为组合系数,且
4 语音识别在评估系统中的应用
4.1 影响语音识别率的几个因素
语音识别的关键技术对语音识别率起着极其重要的作用,要使语音识别技术能够应用于实际评估系统,以下几个影响因素必须考虑:
1)建立语音模板库,也就是语音模型的训练。而且模板的好坏直接影响着识别率的高低,对于非特定人的语音识别系统,需要大量的原始语音数据来训练语音参考模型。
2)提取语音特征参数,对于非特定人语音识别,提取的特征参数应尽量不含有说话人的信息。
3)声学建模是连续语音识别中声学层面解决的关键步骤,语音识别单元的选择是声学建模中的一个基本而重要的问题。
4.2 基于小语音库的语音识别系统
所谓基于小语音库的语音识别系统,就是语音模板库中的语音源限定在一定的数量范围内,是中、大型语音库的简化,基于小语音库的语音识别系统在识别过程中模式匹配需要进行的运算量特别小。
目前语音通信的特点,通信内容主要是话报,只需要能够正确识别出0~9这10个数码及少量固定词语的语音报文,语音识别技术就完全可以应用于语音通信干扰效果评估系统中。
按照报文生成方法,计算机利用报文产生软件生成随机数字报文,数码0~9在语音文件里均匀分布,然后由语音合成软件将数字报文生成语音文件,该语音文件是一串数字语音,包括男声或女声,发音表见表1,数字报文语音文件里四个数字为一组,该语音文件作为评估系统的客观信号源。
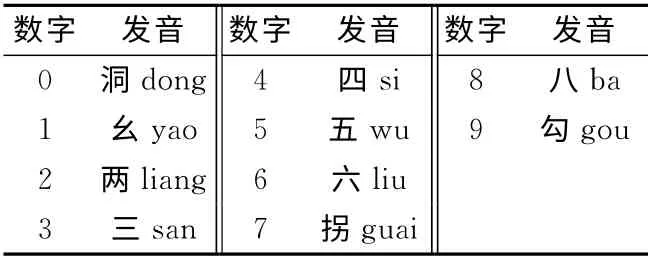
表1 数字报文发音表
建立语音库,即语音模板的训练是语音识别系统中的一个关键过程,它的好坏直接关系到语音识别系统识别率的高低[8]。为了得到一个好的模板,往往需要有大量的原始语音数据来训练语音模型。另外普通大词汇量语音识别系统语音模型库庞大,训练模型任务繁重,匹配算法复杂,难以满足实时性要求[9]。
将语音识别技术应用在特定的语音通信效果评估系统中,只需要建立包含0~9这10个数码合成的语音及其它少量词语的小语音库,即可满足系统需要。基于小语音库的语音识别需要识别的语音源数量特别少,系统运算量小,应用的可行性大大提高。而且小语音库中的语音由计算机通过语音合成技术生成,所有的语音报文具有相同说话人的特定信息,特征参数的提取稳定,大大地提高了识别的正确率。
另外基于小语音库的语音识别系统可以采用适用于小词汇量语音识别单元的单词单元作为语音识别单元。
4.3 应用方法
语音通信干扰效果评估系统功能流程图如图3所示。
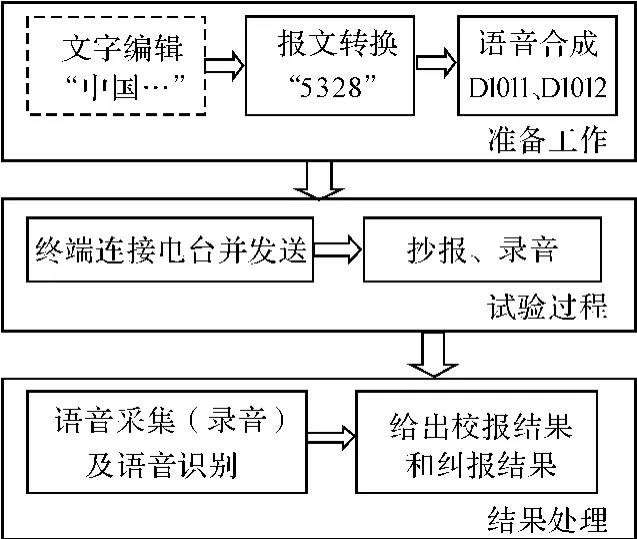
图3 报文生成及录音评估系统功能流程图
系统一般分为准备阶段、试验过程及结果处理阶段。首先在计算机中通过报文生成软件产生数字报文,并合成语音文件,然后将通信终端设备与无线电台相连接,由发送计算机及通信终端控制发端电台按要求(如频率、调制方式、功率要求等)进行发送,接收端进行人工抄报,同时录音采集。结果处理是利用语音识别系统对接收的语音文件在基于小语音库的模板中进行识别,给出识别结果,并统计出错误码子和组数。
基于4.2节中所描述的小语音库的语音识别在语音通信干扰效果评估系统中,利用识别软件对录音存储的客观语音报文进行识别的过程简化如下:
发送端发送的数码报文为在0~9中随机选取的4个数字为一组的组合,收端计算机中预先存有包含数码0~9的小语音库模版,根据模式匹配的方法,对语音进行识别成数码报文,由程序将该数码报文进行错误率统计,最后给出干扰效果评估结果[10]。
这种利用基于小语音库的匹配方法进行语音识别的识别率能够达到很高(应用中正确率大于99%),忽略极少数不能正确识别的数字,认为识别正确率基本接近人工收听的结果。
同时在客观评估的基础上还可以再进行人工校报,将主观评估与客观评估结果综合考虑,给出更加合理的评估结果。
5 结语
本文介绍了语音识别的关键技术,分析了语音模板库仅为特定少量词语的小语音库语音识别评估系统,以及它在特定的语音通信效果评估系统中的应用,介绍了实际应用方法,对于今后建立语音通信客观评估系统上具有一定的指导意义。
目前系统中的数字报文均是任意选取的,没有任何实际语义,评估结果只能根据报文错组率而不能根据实际语义来进行识别评估。但是从阻断通信意图上来说,利用有语义的语音报文进行干扰效果评估更具有一定的现实意义。所以笔者下一步会进行语音通信干扰效果评估系统中基于语义的语音报文识别研究。
[1]吴淑珍,赵朝阳.基于听觉模型的客观音质评估方法研究[J].电子学报,1999(7):92(94).
[2]张璐琳,陈静.国军标(GJB4405A-2007)[J].语音通信干扰效果评定准则,2007.
[3]崔文迪,黄关维.语音识别综述[J].福建电脑,2008(1):28-29.
[4]胡航.语音信号处理[M].哈尔滨:哈尔滨工业大学出版社,2000:73-76.
[5]查普曼.MATLAB[M].北京:科学出版社,1998:46-47.
[6]樊昌信,张甫翊,徐炳祥,等.通信原理[M].北京:国防工业出版社,2001:370-372.
[7]LA Liporace.Maximum Likelihood for Multivariate Observation of MarkovSource.IEEE.Trans.IT[J].1982,28(5):729-734.
[8]徐炜,徐济仁.基于声韵分割的语音信号特征提取技术[J].小型微型计算机系统,2002,23(2):172(175).
[9]王瑛,张知易.一种基于人耳听觉特性的语音客观测度研究[J].通信技术,1999(3):62(68).
[10]谢虹.电子装备作战效能评估[J].航天电子对抗,1998(3):57(59).
[11]王彪.基于Matlab的语音识别系统研究[J].计算机与数字工程,2011,39(12).
[12]刘萍,廖广锐.高噪声背景下的语音识别系统设计[J].计算机与数字工程,2009,37(7).
猜你喜欢
建材发展导向(2022年23期)2022-12-22
汽车电器(2022年9期)2022-11-07
建材发展导向(2022年20期)2022-11-03
建材发展导向(2022年12期)2022-08-19
空间科学学报(2021年6期)2021-03-09
铁道通信信号(2020年4期)2020-09-21
考试与评价·高二版(2020年2期)2020-09-10
阅读(快乐英语高年级)(2019年5期)2019-09-10
中国外汇(2019年11期)2019-08-27
电子制作(2019年14期)2019-08-20
