
SVM 算法在Web服务蜜罐日志分析中的应用
2013-11-12 06:53张晓明
沈阳大学学报(自然科学版) 2013年1期
张晓明,付 强
(沈阳工业大学 信息科学与工程学院,辽宁 沈阳 110870)
对Web服务蜜罐的日志分析主要通过数据挖掘技术来实现.目前主流的技术有Apriori算法及其改进算法、KNN 算法、SVM 算法.Apriori算法的基本思想是:首先找出事务中所有的频集,这些频集出现的频繁性需要大于或等于预先设定的最小支持度;随后由频集产生强关联规则,这些规则必须大于最小支持度和最小可信度;使用递推的方法生成所有频集.其主要缺点是:①可能产生大量的候选集,没有排除不应该参与组合的元素.②需要重复扫描数据库.S-Apriori算法在Apriori算法的基础上作了改进,采用新的数据结构,只需要扫描一次数据库,连接时无须重复判断即可快速找到更高阶的频繁项目集,算法的效率也得到了提高[1].KNN 算法的思路是如果一个样本在特征空间中的k 个最相似的样本中的大多数属于某一类别则该样本也属于这个类别,该算法广泛应用于文本分类.
支持向量机(SVM)是目前广泛应用于各个领域分类方法,其基本思想是在样本空间或特征空间,构造出最优超平面使超平面与不同类样本集之间的距离最大,从而达到最大的泛化能力.SVM 根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折衷,以期获得最好的推广能力[2].
在本文中,分析判断蜜罐日志中的记录是否是一个攻击,重点是分类的准确率,因此采用了另外一种分类方法SVM 算法.在本实验中,使用Web Server蜜罐(WS蜜罐)作为Web服务的应用程序,监视、接收SOAP 消息并记录其所有活动,进而使用机器学习技术对其进行分析,可以大大简化分析任务.
1 SVM 分类原理
SVM 是当前数据挖掘领域中比较流行的机器学习方法,其结构风险最小,泛化能力优异,能解决高维度、非线性等问题.对于本文所要解决的问题,SVM 算法可描述为将输入空间中的样本通过一种非线性函数关系映射到一个高维特征空间中,使样本在该高维特征空间中线性可分,并找到样本在该维特征空间中的最优线性分类超平面.

式中,k(x,xi)表示核函数.
在SVM 中,常用的核函数有线性核函数、多项式核函数、径向基核函数和Sigmoid核函数,其中基于径向基核函数的SVM 性能要优于其他核函数[3],因此,本文采用径向基核函数作为SVM核函数,
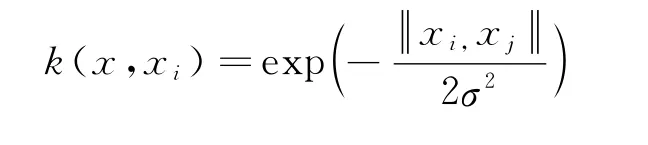
即因此,基于SVM 算法的分类器为

式中,σ 表示核函数宽度;αi表示拉格朗日乘子.
2 SVM 算法的应用
2.1 建立模型
首先建立一个高交互的WS蜜罐,它提供真正的Web服务,与攻击者进行真实互动.蜜罐将收集到的信息存放在日志文件中,该日志文件主要记录攻击者的动机以及攻击中所使用的技术和手段,以便人类专家更好地采用更有针对性的方法来保护系统[4].但是日志文件也存在缺陷,它收集到的大量信息必须通过人类专家来分析.由于收集到的大部分信息是系统的正常行为,与攻击没有任何关系,因此,在分析这些信息的时候,人类的专家将被淹没在大量数据审计中,并有可能漏掉真正的攻击.因此,使用机器学习技术对收集到的信息进行分析,该技术可以分析并学习蜜罐正常行为的信息,当蜜罐检测到重大的偏差行为时,将该行为提交给人类专家决定.
在部署WS蜜罐之前,它必须首先经历一个训练阶段,这是蜜罐在一个安全的环境下模拟学习Web服务的正常行为[5].在这个训练阶段里要创建一个包含有关蜜罐的各种合法活动和分类信息的数据集.这个阶段后,WS蜜罐可以进行部署并开始吸引攻击者.然后,用户对蜜罐上进行的活动进行初始数据集分类,如果有错误的分类(异常活动),该活动将被传递给人类专家,以检查它是否是一个攻击.如果它是以前没有见过的正常活动,初始数据集将增加一个有关此活动的新条目,以避免类似错误分类的发生.此外,蜜罐已检测并确认的攻击将被归类在其他数据集,从而减少人类专家的工作量.
2.2 架构
WS蜜罐的作用是模拟一个Web 服务的行为并且捕获和分析用户的活动.其系统架构如图1所示.

图1 Web服务蜜罐框架Fig.1 Frame of Web server honeypot
(1)模拟Web服务.本模块的目的是利用一个真正的Web服务交互来误导攻击者.为了避免给人一种静态的感觉,通过增加一个WSDL 文件的方法在蜜罐上部署真正的Web服务.
(2)流量捕获.流量记录是一项收集和分类用户活动的重要任务.这个组件包括流量捕获机制和监测工具两部分,主要用来捕获和分析WS蜜罐模拟服务的请求和响应.Web服务请求封装在以HTTP作为传输协议的SOAP 消息里,对攻击的检测就是通过检查这些消息来实现的.
(3)特征提取.通过WS蜜罐从每个SOAP消息提取特征.主要是通过将SOAP消息的内容分为以下几部分来实现的:IP 源、消息长度、请求序列、响应序列、每次请求时的调用操作,以及每个操作的输入参数.
(4)数据分析.在蜜罐中,数据分析是一个非常困难和烦琐的任务,为了简化这个任务,利用机器学习技术来检测蜜罐中的异常活动.
在进行数据分析之前,需要确定哪些属性是有助于发现和理解攻击行为的.对于蜜罐来说,每个时间戳表征了网络连接发生的时间,而IP源表征了攻击的产生源,那么带有时间戳的来自同一个IP 源的网络连接记录集便构成了一个时间序列[6].
在本文中,时间戳是独立于攻击特征的属性,所以并未采用;消息长度与SOAP消息的属性也无直接关系,故也未采用.分析选择的属性包括:IP源、请求序列、响应序列、每次请求时的调用操作、每次操作的输入参数.每一条SOAP 消息可以看做是一个事物Tk,SOAP消息的全体构成了事务数据库D.所有消息中IP源,请求序列,响应序列,每次请求时的调用操作,每个操作的输入参数的属性值构成了全体项的集合I.在这里,即使所有SOAP消息的IP 源属性值相同,由于它们描述的请求和响应序列以及其调用的操作不同,也被认为是不同的项.由于请求序列和响应序列显示了SOAP 消息在蜜罐中的所有行为,因此,该序列对SOAP 消息的分类起着至关重要的作用;对于每次请求调用的操作,由于网络病毒或者黑客采取网络攻击连接对方服务器时,需要调用一系列操作来实现其目的,因此,每次请求调用的操作列为机器学习的一项重要指标;对于每次操作的输入参数,由于网络攻击的攻击方式和手段具有很强的可学习性,并且每次操作的输入参数能够很好地体现攻击者的目的和意图,因此输入参数也列为机器学习的一项指标.这里选取IP源、请求序列、响应序列、每次请求时的调用操作,及每个操作的输入参数作为一个SOAP 消息的特征值,最后对这些属性进行分析和分类.
3 数据分析模块的架构
数据分析是将收到的所有请求,按照其内容进行分类,分类依赖于一个部署在蜜罐中逐步建成的学习数据集[7].如果在分类的时候发现有异常活动,将该活动传递给人类的专家检查其是否是一个攻击.
蜜罐中的数据分析任务是非常困难的,需要人类专家在数据分析方面付出很多努力.为了促进这一任务,使用机器学习技术,其基本思想是捕捉并分析WS蜜罐收到的SOAP 消息,并将异常活动提取出来交由人类专家进行分析.该模块的框架如图2所示.
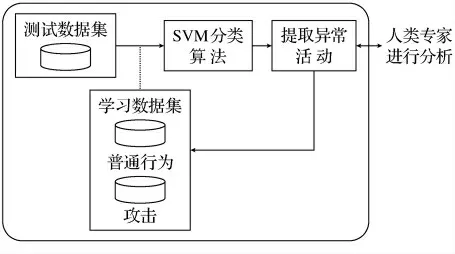
图2 数据分析模块框架Fig.2 Frame of data analysis module
3.1 WS蜜罐中的数据集
要想利用这个蜜罐得出好结果,它必须经过一个训练阶段,在此期间,它必须部署在一个安全的环境中学习该系统的合法活动,从这些合法活动中提取特征.蜜罐所捕获到的信息,将存储在一个标有“学习数据集”的数据集中.
在训练结束后,WS蜜罐可以开始工作,对于蜜罐捕获到的每个SOAP消息,提取的特征将被储存在测试数据集中.然后,这些功能将在学习数据集的基础上进行SVM 分类,如果发现有分类错误,该活动将被递给人类的专家审查其是否是一个攻击.经核实后,无论它是正常活动或者攻击行为,都要将这项活动加入到学习数据集中.
3.2 SVM 分类
SVM 分类的作用是将接收的SOAP信息进行分类,主要是基于SOAP 消息内容的特征提取.该分类找到学习数据集中的每个消息,如果消息中的参数与某些已知分类参数有偏差,将会发生分类错误,该消息会被传递给人类专家处理.
(1)数据源.IP 源、消息长度、请求序列、响应序列、每次请求时的调用操作、每个操作的输入参数.
(2)数据预处理.数据预处理的任务是将每个SOAP 消息的所有特征信息预处理成数量特征.由于每个SOAP 消息中包含很多信息和特征,在这些特征信息中,有一部分属于字符型数据,比如,IP 源,每次请求时的调用操作,每个操作的输入参数等.要将SOAP消息转换成检测模型的输入数据,则需要把各自类型的字符数据进行转换,得到相应的数量特征,然后再进行归一化处理,把大小不一的各种数量统一到小范围内,如0~1之间.这样,SOAP 消息就被初始化成标准的输入矢量,就可以作为检测模型的输入数据了.另外,由于蜜罐模拟一些服务,对SOAP 消息请求某些认为是被攻击的服务时,该消息被自动检测为一个攻击.
一是数据集格式转换.首先应该将SOAP消息进行特征提取,提取到的字符型字段数据转换成矢量数据,即将每一字段可能的取值都用数字来表示,这样就建立起了字符数据和矢量数据之间的一一对应关系.将该关系构造成一张表,称为关键词表.其他如服务类型和攻击类型的关键词表与此类似,不再赘述.
二是归一化处理.当众多的字符数据都经过矢量转换后,它们依次赋予的整数因同字段内相互不重复故使取值范围可能会很大.为了处理方便,将所有数字特征归一化处理到0~1之间.直接对准备好的数据源进行归一化处理,并将处理后的训练数据和测试数据分别存储在硬盘中.
3.3 异常活动提取
在分类过程中,对WS蜜罐中每个活动是根据它们的相似之处进行特征提取.如果由于异常活动出现的分类错误,该活动的详细描述将被传递给人类专家.随后,人类专家根据其具体情况对异常活动进行分析,以确认其是否是一个真正的攻击.
4 结果
为了验证该方法的有效性,首先通过在训练阶段向WS 蜜罐发送合法的SOAP 消息对蜜罐进行本地学习,其次在测试阶段,使用多种技术模拟各种攻击,在本实验中,共发送365 条SOAP消息,其中恶意请求产生53个报警.
表1列出了实验中每种类型攻击检测的详细信息.可以看出,该系统对一些比较常见的攻击方法有一定的效果,并且有很高的准确率,但是其自动检测率还有待提高,其主要原因是前期训练样本不够全面,数据集不够健全;普通行为和攻击行 为有很多相似之处,SVM 算法不能完全识别.

表1 实验中攻击检测的详细信息Table 1 Detailed information of the attack detection in the experiments
5 结 论
通过部署一个WS蜜罐来收集信息,采用基于SVM 算法的机器学习技术来分析处理日志文件.从实验结果可以看出,该系统在大大减少人类专家的工作量的同时有很高的准确率,但是其自动检测数量和漏报数量仍然需要改进.
[1]戴小廷.典型Apriori改进算法的分析与比较[J].微计算机信息,2010,26(9):158-159.(Dai Xiaoting.Analysis and Comparison of Representative Algorithms for Apriori[J].Microcomputer Information,2010,26(9):158-159.)
[2]郭来德,张燕,曹杨,等.机动车车牌识别中SVM的应用[J].计算机与数字工程,2012,40(4):105-106.(Guo Laide,Zhang Yan,Cao Yang,et al.Application of SVM in Motor Vehicle License Plate Recognition[J].Computer &Digital Engineering,2012,40(4):105-106.)
[3]杨世恩,陈春梅.基于SVM的网络攻击检测系统研究[J].长江大学学报:自然科学版,2011,8(8):81-84.(Yang Shi'en,Chen Chunmei,Research on the System of SVM-based Network Attacks Detection[J].Journal of Yangtze University:Natural Science Edition,2011,8(8):81-84.)
[4]王军,李莉.虚拟多入口路由的蜜罐网络构建[J].沈阳大学学报:自然科学版,2012,24(4):52-57.(Wang Jun,Li Li.Construction of Virtual Multi-entry Routes Honeypot Network[J].Journal of Shenyang University:Natural Science,2012,24(4):52-57.)
[5]蔡清体,谭汉松.基于SVM 主动学习的网络入侵检测算法研究[J].计算机与信息技术,2009(12):41-43.(Cai Qingti,Tan Hansong.Intrusion Detection Algorithm based on SVM Active Learning Network[J].Computer &Information Technology,2009(12):41-43.)
[6]金涛.数据挖掘在蜜罐日志分析中的应用研究[D].上海:上海交通大学,2010.(Jin Tao.Research on Application of Data Mining in Honeypot Log Analysis[D].Shanghai:Shanghai Jiao Tong University,2010.)
[7]周洪利.基于SVM的网络信息过滤研究[D].山东:山东师范大学,2008.(Zhou Hongli.Research on the Network Information Filtering Based on SVM[D].Shandong:Shandong Normal University,2008.)
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
通信产业报(2020年43期)2020-01-15
中外文摘(2019年20期)2019-11-13
知识窗(2019年6期)2019-06-26
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
系统管理学报(2018年3期)2018-08-13
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国三峡(2017年4期)2017-06-06
中国卫生(2014年12期)2014-11-12
