
高层结构方案设计的K-Means 聚类分析法
2013-11-12 07:04:56张世海张世忠段慧杰
土木建筑工程信息技术 2013年2期
张世海 张世忠 段慧杰
(南阳理工学院,南阳 473004)
1 引言
实际工程中大部分高层建筑的结构方案设计都是在已有相似工程实例结构方案基础上的整合和改进,若干相似实例的快速获取是高质与高效进行结构方案设计的基础和关键。聚类是一种按照对象间相似性进行无监督分类(或分簇)的过程[1],而非监督的聚类是根据实际数据的特征,按照以某种度量为标准的数据之间的相似性,把一组没有划分类的对象集划分成一系列有意义的不同的类,把特征属性相似的归为一类,不相似的作为另一类,使同一类之间相似性最小化,不同类之间相似性最大化,即聚类具有分组数未知、没有关于聚类的任何先验性知识、不需要用训练样本进行学习和训练、聚类结果动态、不同相似性度量和不同的目的要求将产生不同的聚类结果等特征。而工程实例的结构方案千变万化,很难对其结构方案进行确切的分类,显然,利用聚类分析的方法可以帮助设计者从大量没有结构方案分类的工程实例库中快速获取若干相似实例,据此即可进行当前结构的方案设计。聚类分析的算法较多,而k-means 算法是一种应用最广泛的方法[2-4],为此,本文将探索利用基于k-means 的聚类方法,来进行高层建筑结构智能方案设计。
2 k-means 算法
2.1 k-均值算法的基本思想
k-均值算法以最终分类个数k 为参数,把n 个数据对象{xj}n分为k 个聚类{ci}k,以使聚类内有较高的相似度,相似度根据一个聚类中数据对象的平均值(被看做聚类的重心)来进行计算。
2.2 k-均值算法的流程
首先从n 个数据对象中随机地选择k 个对象,作为初始的聚类中心,对剩余的每个对象,根据其与各个聚类中心的距离或相似度,分别将它们赋予与它们最近或最相似的聚类;然后,重新计算每个聚类的平均值作为新的类心并调整各样本的类别;不断重复上述过程,直到各样本到其判属类心的距离平方之和最小或评价函数(或目标函数、准则函数、标准测度函数)收敛为止。
2.3 k-均值算法的准则函数JW
准则函数JW定义为各聚类内所有对象的平均误差之和,即计算类内的每个点到它所属类中心的距离平方和。设有待分类样本集x={x1,x2,…,xn},在某种相似性测度基础上被分划为c 类{xi(j);j=1,2,…,c;i=1,2,…,nj},其中上角标j 表示类别,下角标i 表示类内模式的序号,Σnj=n,类内距离准则函数Jw定义为:

式中,mj表示ωj类的中心或模式均值向量,按下式确定。
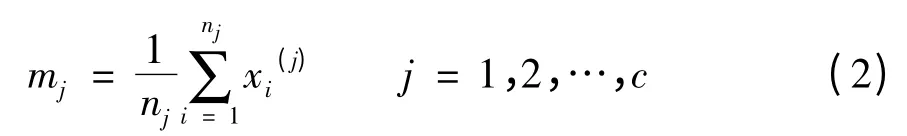
公式(1)表征了各样本到其所属类中心距离的平方和。聚类的目标是使Jw取最小,即Jw→min,因Jw值越大,说明某些样本没有就近分类,在此意义上聚类效果不好,应重新调整分划。这种准则也称为误差平方和准则。
显然,Jw是各样本xi(i ∈[1,n])和类心mj(j∈[1,c])的函数,在样本集{xi}n 给定条件下,Jw的值取决于类心集{mj}c 的选取,类心集的确定相应于样本类别的分划。该准则适用于同类样本比较密集,且各类别样本分布区域体积差别不大的情况,否则采用上述准则可能是不适宜的。例如,当某一类样本数目较多而另一类样本较少,两类样本所占空间大小明显不同,两类间的距离又不足够大时,样本较多的那一类中一些边缘处的样本可能距离另一类的类心更近一些。
2.4 k-均值算法步骤描述
输入:包含n 个对象的数据库D=X={xj}n及期望聚类的簇数目k。
输出:k 个簇,使平方误差准则最小。
k-均值算法:
(1)assign initial value for means m1s,m2s,…,mks;//随机选择k 个对象作为初始的聚类中心:m1s,m2s,…,mks,置迭代步数s=0
(2)repeat
(3)For j=1 to n Do assign each xjto the cluster which has the closest center(mean);//将待分类的每个对象xj∈{xj}n按最小距离原则赋给k 个初始的聚类中心中的某一类,或根据聚类中数值对象的平均值,将每个数据对象重新赋给最相似的簇。即如果djl(s)=min[dji(s)],j=1,2,…,n,则判xj∈cl(s+1)。其中,dji(s)表示xj和类ci(s)的中心mi(s)间的距离。于是产生了新的聚类ci(s+1)(i=1,2,…,k)。
(4)For i=1 to k Do calculate new center for each cluster;//按公式3 计算重新分类后每个聚类中数据对象的平均值或类中心,更新聚类平均值。其中,ni(s +1)为ci(s +1)类中所含样本数。
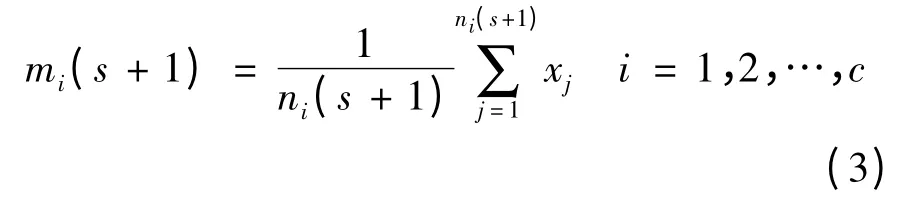
因该步采用了平均的方法计算调整后k 个聚类的中心,故称该方法为k-均值法。
(5)Compute JW;// 按公式4 计算评价函数JW。
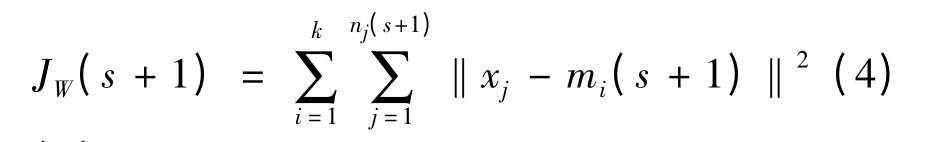
(6)UNTIL convergence criteria is met//平均误差JW≤ε 或者JW不在明显地变化或者mi(s +1)=mi(s)(i=1,2,…,c)则结束,否则,s=s+1,转3)。
3 基于k-means 聚类分析的高层结构智能方案设计
在高层建筑结构方案设计的聚类分析过程中,存在多种类型的数据,而k-means 算法能有效地对数值属性进行聚类分析,因此,可利用k-means 算法的这一特征,通过对工程实例的结构高度、长宽比、高宽比、场地类别、设防烈度等数值型属性信息的聚类分析,来进行高层建筑结构方案设计。以下给出基于k-means 算法聚类的高层结构方案设计实例检索方法和工程实例。
3.1 输入样本与聚类数确定
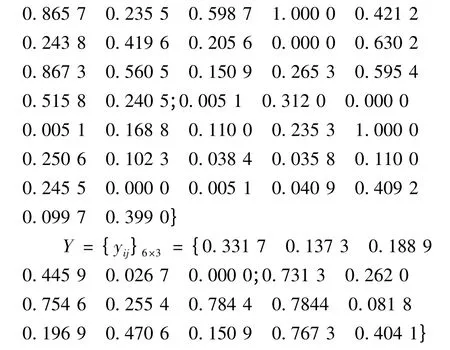
采用表1 中给出的26 个工程实例数据中的高度、高宽比、长宽比3 个数值型属性为聚类和实例检索依据,其中,利用前20 个数据进行聚类,利用后6个数据进行实例检索,确定的聚类数目k=4。为解决属性间的不可公度性,需对各属性进行标准化或归一化处理,通过标准化处理后将各个属性值转化为[0,1]区间上的数值[5]。标准化处理后的样本输入矩阵为X,聚类后的待检索输入样本矩阵为Y。

3.2 样本分类原则与评价函数确定
按最小距离原则将每个数据样本赋给最相似的簇,按公式(4)给出的平均误差公式计算评价函数JW值。
3.3 聚类过程与结果
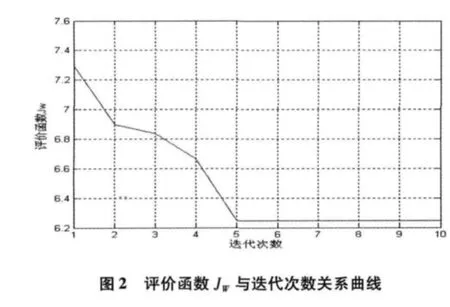
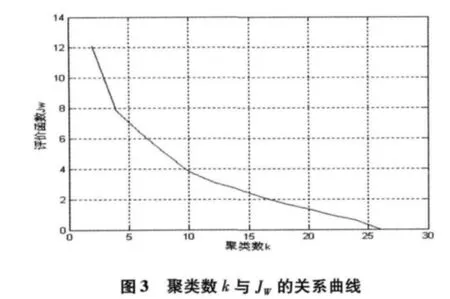
按前述k-均值算法步骤进行聚类分析,聚类结果见表2。图2 给出了第1-6 步聚类结果,图3 给出了评价函数JW随迭代次数增加的变化曲线,图4给出了聚类数k 由2 变化到10 时JW随k 单调减小变化曲线,显然,当k=4 时JW的曲率变化最大,此时的分类数是比较接近从样本几何分布上看最优的类数。
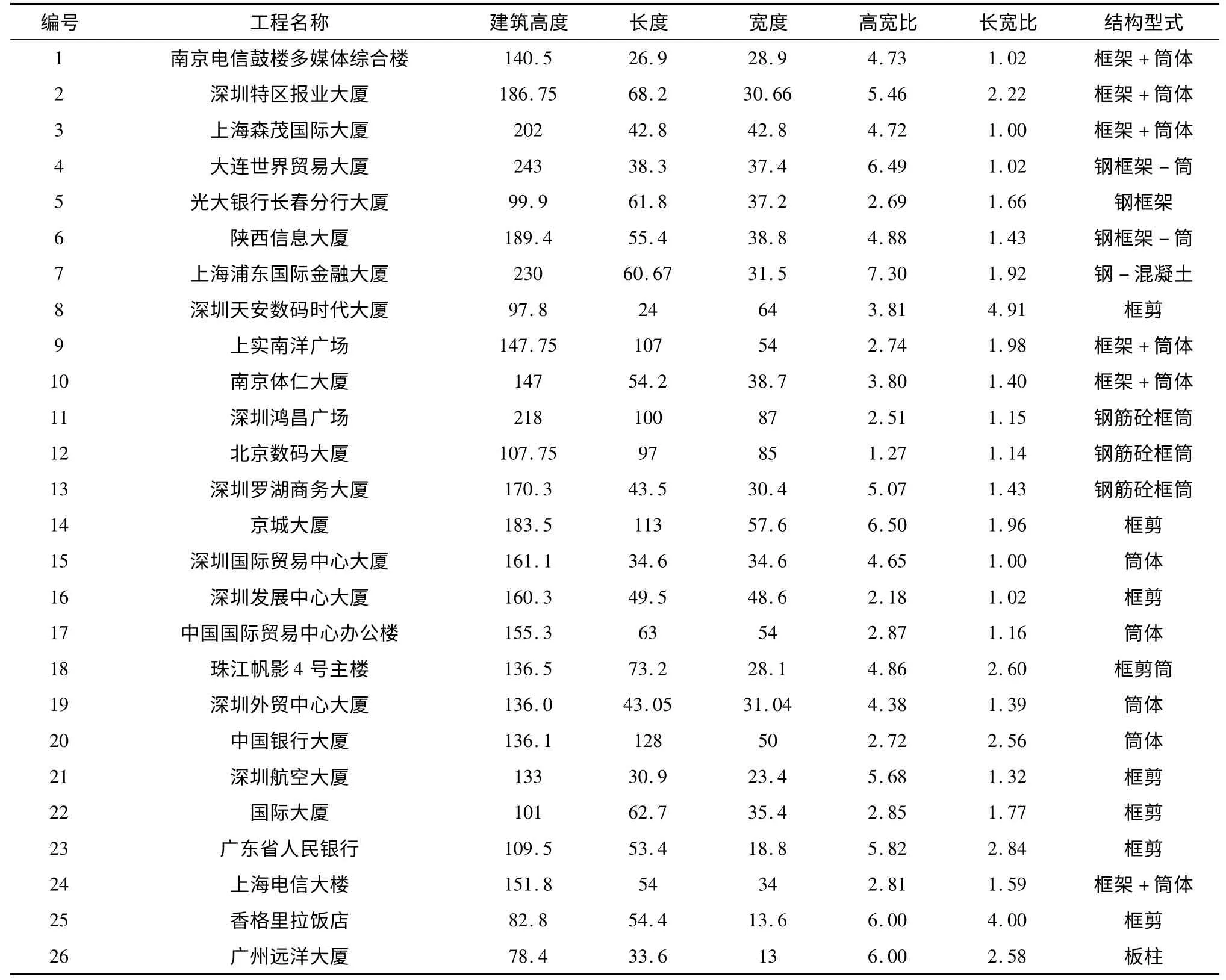
表1 高层建筑工程实例属性信息(部分)
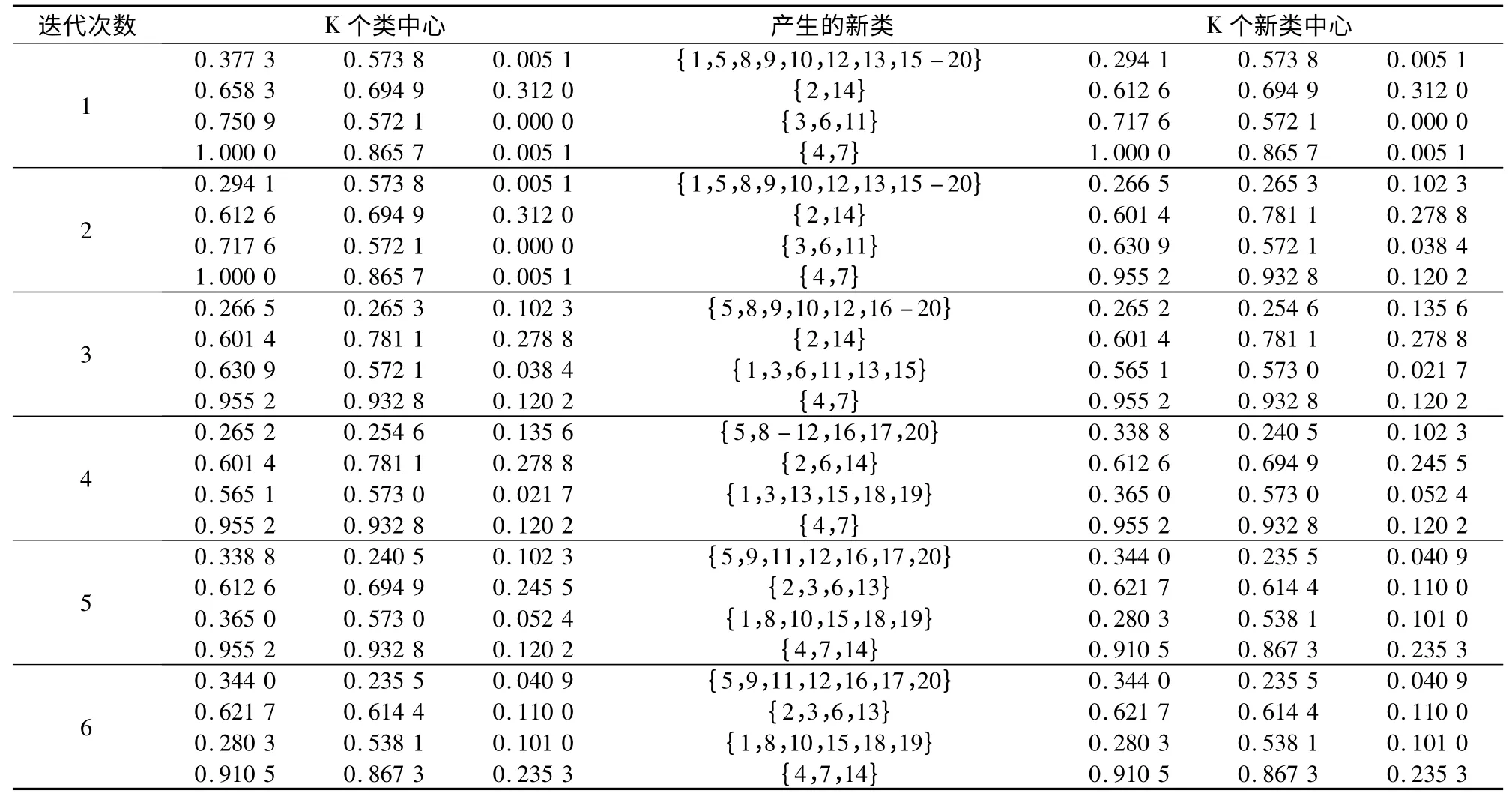
表2 k-均值算法聚类结果
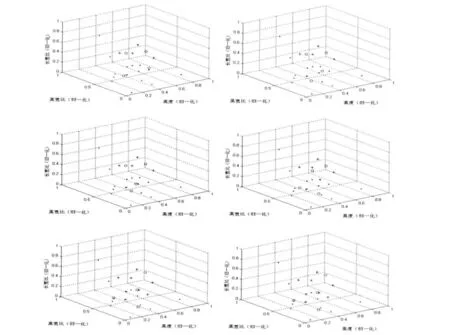
图1 k-means 聚类结果(4 类,第1-6 步)
3.4 聚类结果检验
根据4 个中心及其相应的聚类结果,即可利用待输入样本矩阵Y 进行其相似实例聚类,以确定与当前方案相似的工程实例,据此就能确定结构型式及其结构方案。首先,可确定样本矩阵中每个待输入样本与各个聚类中心的距离;然后,根据最小距离原则确定其所属的类别及其相似的工程实例;最后,再根据相似工程实例方案的类别或相似实例中出现频次最高的结构方案类别作为当前的结构方案设计依据[6]。下式给出了6 个待输入样本与4 个聚类中心间的距离矩阵D,其中,dij为样本yi与聚类中心cj之间的距离。

由上述距离矩阵,根据最小距离原则可确定6 个待输入实例所属的类别分别为:2、1、2、3、2、2,各类的相似实例见表2,由此即可根据所属类中的相似实例的结构方案进行当前结构方案的设计与创新。
4 结论
在给出了k-均值算法的基本思想、准则函数、步骤流程等基础上,将具有无导师学习特征的聚类分析理论和方法引入高层结构智能方案设计,建立了基于K-Means 聚类分析方法的高层结构智能方案设计实例获取方法,给出了工程应用实例:以表1 中的26 个工程实例数据为依据,对前20 个工程实例数据进行了聚类分析,并给出了聚类结果及聚类过程的空间分布图、评价函数JW随迭代次数增加的变化曲线、聚类数k 由2 变化到10 时JW随k 单调减小变化曲线,并对后6 个实例数据进行了实例聚类,给出了相似实例,为高层建筑结构方案智能设计开拓了崭新的途径和方法。
[1]Jain A,Murty M,Flynn P.Data clustering:A review.ACM Computing Surveys (CSUR),1999,31 (3):264-323.
[2]Macqueen J.Some methods for classification and analysis of multivariate observations.In:Proceedings of the 5thBerkely Symposium on Mathematical Statistics and Probability,Berkely,CA,1967,vol.1,281-297.
[3]Huang J Z,Ng M K,Rong H-Q,Li Z-C.Automated variable Weighting in k-Means Type Clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(5):657-668.
[4]Wagstaff K,Cardie C,Rogers S.Constrained k-means cluserring with background knowledge.In:Proceedings of the 8thInternational Conference on Machine Learning,Morgan,Kaufmann,2001:577-584.
[5]张世海.高层建筑结构智能方案设计方法研究,哈尔滨工业大学博士后研究工作报告,2009.
[6]Shihai Zhang,Changyong Wang Shujun Liu.Intelligent scheme design of high-rise structure for K-means-based case retrieval.Proceedings of the 2010 Second WRI Global Congress on Intelligent Systems(GCIS’2010).Sponsored by Wuhan University of Technology and World Research Institutes.Los Almitos,California Washington·Tokyo GCIS’2010(vol.3):241-244.
猜你喜欢
智能制造(2021年4期)2021-11-04 08:54:28
建材发展导向(2021年6期)2021-06-09 05:57:14
装备制造技术(2020年9期)2021-01-26 00:15:30
初中生世界·九年级(2017年8期)2017-09-06 09:40:36
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
