
文本分类中一种基于互信息改进的特征选择方法
2013-10-22 04:23田野,郑伟
河北北方学院学报(自然科学版) 2013年1期
田 野,郑 伟
(河北北方学院理学院,河北 张家口 075000)
1 引 言
文本自动分类的任务就是对未知类别的文档进行自动判断,把它归属到已有类别集中,目前文本自动分类技术已经广泛地应用到信息检索和数字化图书馆等领域,具有很强的应用价值。在基于向量空间模型的文本自动分类系统中,文本分类面临的难题之一是如何从高维的特征空间中选取对文本分类有效的特征,特征选择就是解决上述问题的办法之一。目前常用的特征选择方法有互信息 (MI)、文档频率方法(DF)、信息增益 (IG)、期望交叉熵 (ECE)、χ2统计 (CHI)、文本证据权 (WET)等[1,2]。
互信息是信息论和统计学中一种经典的统计算法,常用来计算样本和类别的相关性,互信息作特征选择方法也广泛地用在特征选择中,但是其在理论上还有一定的不完善性,在实践中,特征选择时特征的提取效果也不是十分理想,尤其在中文文本分类中。本文针对互信息 (MI)特征选择方法在特征提取时分类效果不理想的状况,提出了一种改进的互信息特征选择方法。该方法改进了互信息方法中的不足点,应用在SVM与KNN实验上,极大地提高了分类精度。
2 互信息选择算法
特征选择方法是使用某种特征评估函数对每个特征进行评估打分,按照评估分数的高低进行特征排序,再选取一定预设数目评分高的特征作为文本分类的特征集。词条和类别的互信息 (mutual information,MI)体现了词条与类别的相关程度,词条对于类别的互信息越大,它们之间的共现概率也越大。它作为一种标准被广泛用于关联统计建模。
特征t如果以较高的概率在某个类别ci中出现,而低概率在其它类别中出现,那么称特征t与类别ci的互信息值较高,t可被选取为类别的ci的特征。特征t与类ci的互信息计算公式如下:

其中,P(t|ci)为特征项t出现在类ci中的概率,P(t)定义为t出现的概率,P(ci)定义为类别ci的概率。
如果有m个类别,于是对每个特征项t都有m个类别值,通常取它们的平均互信息。平均值大的特征被选择的可能性大。平均互信息如公式 (2)所示:
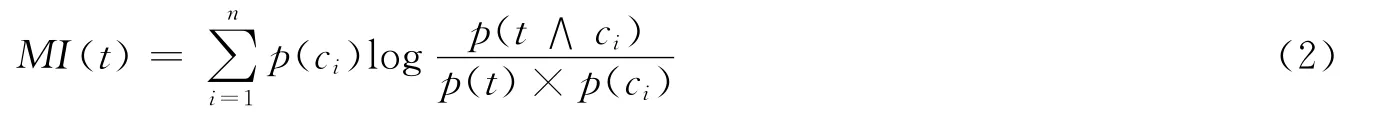
如果一个词条能够带有只代表某一类的丰富类别信息,同时在其他类别中很少出现,那么该词条可选取作为对应类别的类别特征。为了最大效率的选取出能够代表各类类别信息的典型特征,我们可以采用对每个类训练文本集中分别选取代表此类的关键词条作为特征。
3 互信息方法的不足与改进
使用互信息 (MI)方法进行特征选择时,计算所得到的特征互信息值的大小能够直接体现该特征与类别相关性的大小,研究发现公式还具有以下2点不足:
1)MI公式由于互信息没有考虑词频,所以经常会倾向于选择低频词,低频词的作用被放大,甚至是噪音的低频次被选中用于文本表示,因此使用MI的效果并不是很好。
2)在互信息公式中,会出现特征t与类别的互信息为负数的情况,当特征t很少在类别ci文本中出现,但特征t的文档频率又很大,即P(t)很大而P(t|ci)很小,计算后就会出现负数[3]。
为了使特征选择方法能够更有效地提取具有类别信息的特征,结合上述对互信息选择方法的分析,对互信息选择方法进行了改进,用于类内特征的提取,改进后的互信息算法为:
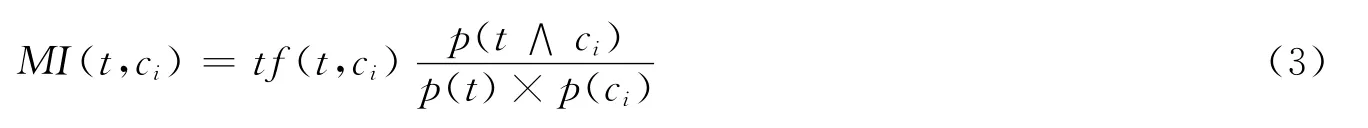
公式 (3)中引入因子tf(t,ci)用来弥补原算法中对低频词的倚重,去掉对数中的log可以避免负互信息值的出现,改进后的方法可用于类别内部特征的选择。
4 实验及其分析
4.1 实验设置
本实验目的是通过分类实验,探讨在SVM和KNN分类算法下测试互信息和改进之后的互信息特征选择方法对应的特征选择效果。
实验采用复旦大学收集的中文语料库,选用其中的5个类别:环境、交通、计算机、教育、医药,其中训练样本694篇,测试样本345篇,每个类别的训练语料与测试语料分布均匀。
4.2 分类器和性能评价
实验采用目前性能最好的分类器SVM和KNN用于分类[4],实验采用宏平均准确率MacroP,宏平均召回率MacroR,宏平均MacroF1值作为评估指标,其中F1测试值综合考虑了文本分类的查准率与查全率,其具体计算公式如下:

4.3 实验结果及分析
图1是在采用复旦大学5个类别的语料下,采用互信息和改进的互信息方法在选择不同数目的类内特征值时,对应分类的F1均值曲线。表1中数据展示了当选择不同的类内特征值时,互信息和改进的互信息方法在SVM和KNN分类器下的F1值比较。
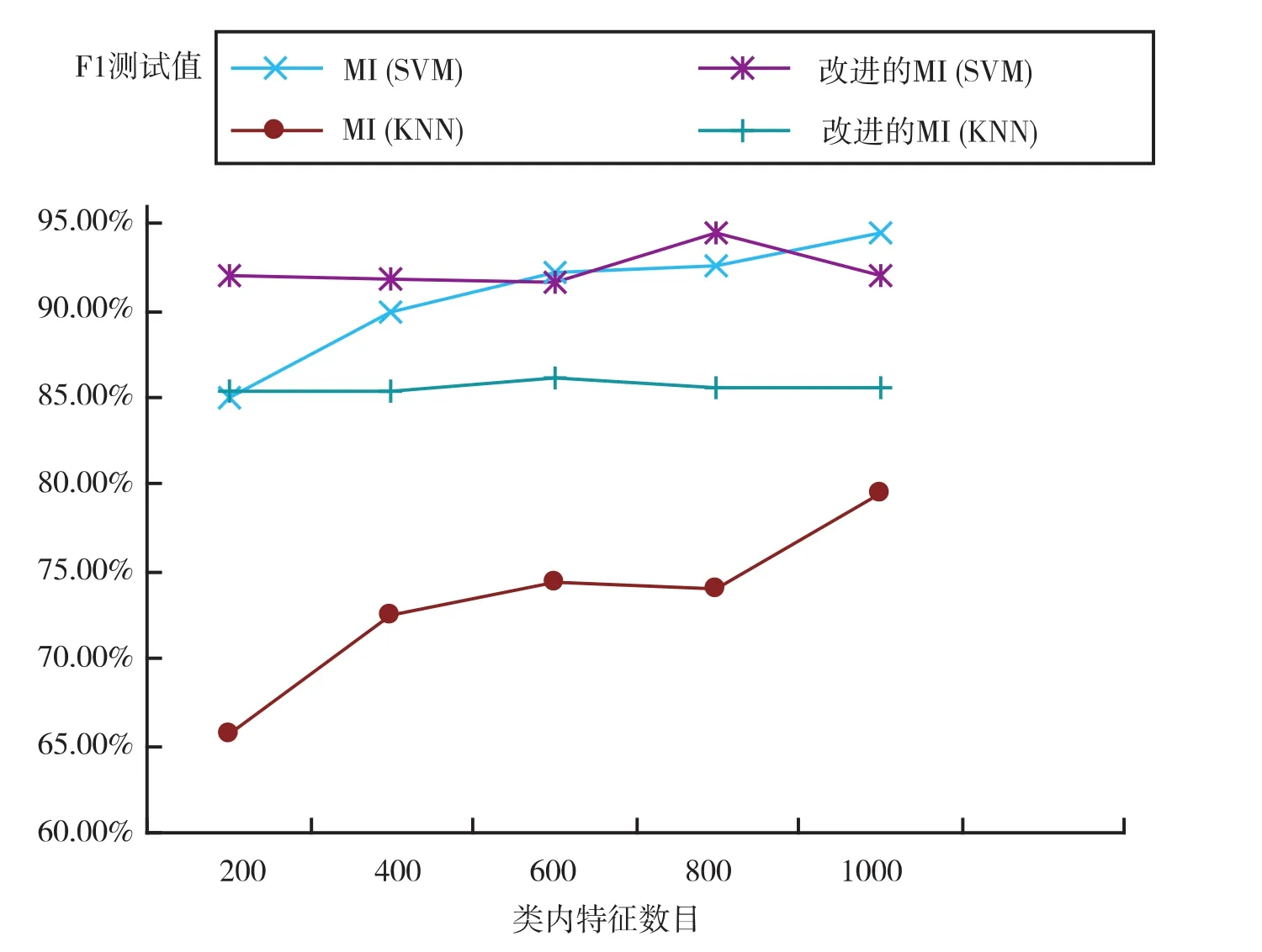
图1 改进后的不同特征选择方法分类结果
从图1曲线可以看出改进后的互信息方法在SVM和KNN分类器下特征提取效果明显好于原互信息方法,在类内特征数目增加时,分类效果均较为稳定,而原互信息方法在两类分类器下对应的分类效果依赖特征数目,F1值会随着特征数目的增加而增加。
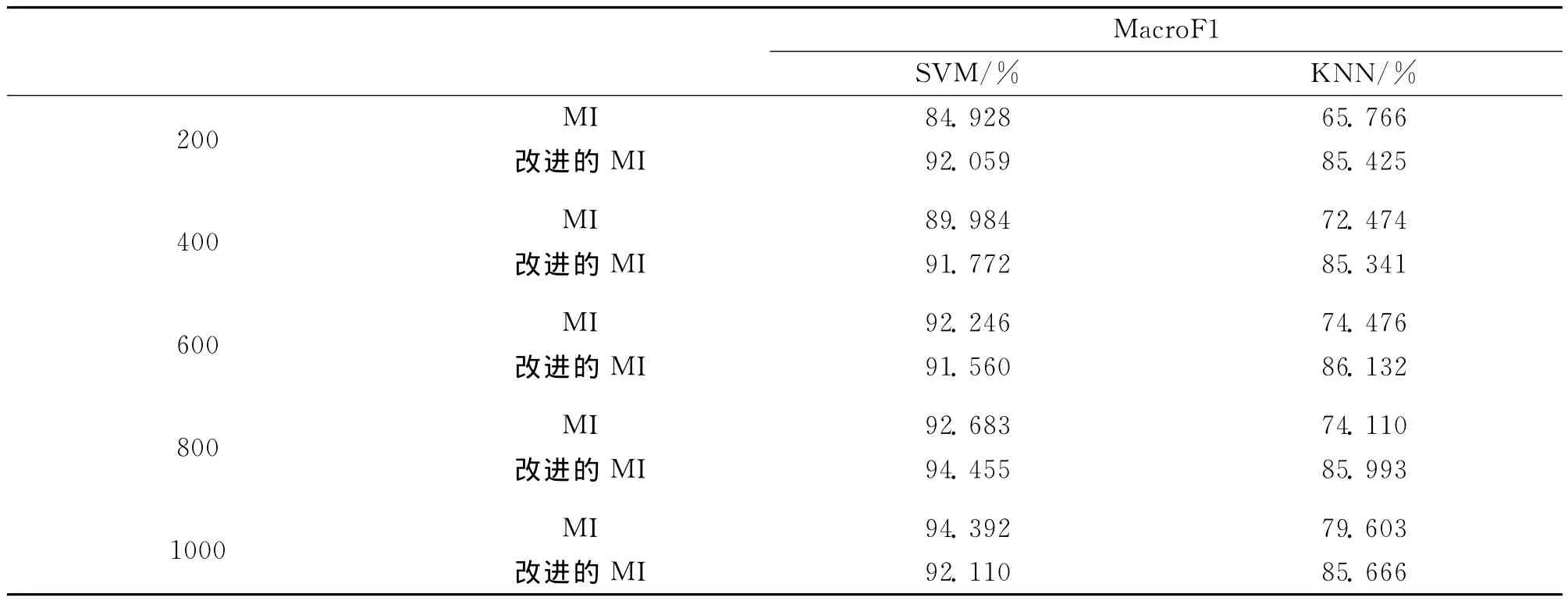
表1 改进后的互信息和互信息方法分类效果对比
从表1中可以看出改进后的互信息法在每类抽取800维特征时,使用SVM分类器分类效果达到最佳值,其F1值为94.455%,分类效果好于互信息在不同数目特征值时的分类F1值;在使用KNN分类器时,改进后的互信息算法对应的分类F1值一直比较稳定,都是在85%左右,并且明显高于原互信息方法的分类F1值。综合看,改进后的互信息算法用在特征选择时能够提高不同分类器的分类准确率。
5 结 论
互信息方法是一种常用的特征选择方法,但还存在理论需进一步完善、实践中特征提 取效果差的不足。本文分析了互信息算法,找出了其存在的不足,对互信息算法进行了改进,提出了一种改进的互信息特征选择方法。实验结果证明,改进后的算法在特征选择效果方面明显优于原算法,用于分类时能够有效地提高分类准确率。下一步的工作将继续研究特征选择方法约束条件,根据约束条件构造出更好的类内特征选择方法。
[1]郑伟,王锐.文本分类中特征提取方法的比较与研究[J].河北北方学院学报:自然科学版,2007,23(06):51-54.
[2]Yang Y,Pederson J O.A comparative study on feature selection in text categorization[A].Proceedings of the 14th International Conference on Machine Learning[C].Nashville:Morgan Kaufmann,1997:412-420.
[3]裴志利,李志刚,王建,等.一种基于改进互信息的文本分类方法[J].内蒙古民族大学学报:自然科学版,2007,22(04):377-380.
[4]Yang Y M,Liu X.A re-examination of text categorization methods[A].Proceedings of ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR)[C].1999:42-49.
猜你喜欢
电子制作(2017年23期)2017-02-02
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
新校长(2016年8期)2016-01-10
智能系统学报(2015年4期)2015-12-27
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
振动工程学报(2014年4期)2014-03-01
