
基于OpenMP的多线程负载均衡调度策略
2013-10-15 07:38范会敏李滋田
计算机与现代化 2013年12期
范会敏,李滋田
(西安工业大学计算机科学与工程学院,陕西 西安 710032)
0 引言
2005年4月,Intel公司推出双核处理器,率先揭开了多核时代的帷幕。时至今日,多核处理器已经成为处理器领域的主流。多核处理器通过划分任务,使线程应用能够充分利用多个执行内核,可在特定的时间内执行更多任务,从而提高性能。
研究多核技术的一个重要问题是负载平衡。如果能通过调度策略将并行程序中的并行任务合理地划分并分配到各个处理器上,尽量减少处理器间的负载不平衡性,那么在软件方面就能有效地提高程序的运行效率,在硬件方面也能发挥多核的优势。本文对OpenMP环境下的负载均衡算法进行深入研究,并针对这些算法的缺陷,提出一种改进调度方案。
1 相关工作
1.1 OpenMP 概述[1]
OpenMP[2]是共享存储体系结构上的编程模型,是一种能够被用于显式指导多线程、共享内存并行的应用程序编程接口;支持多平台,具有良好的可移植性,支持Fortran/C/C++等多种编程语言。
OpenMP使用Fork-Join并行执行模型[3]。当程序开始执行的时候只有一个叫做主线程存在,如图1所示。主线程会一直串行地执行,直到遇见第一个并行域(Parallel Region)才开始并行执行。当遇到需要进行并行运算时,主线程创建一队并行的线程,并行域中的代码在不同的线程队中并行执行;当派生出的线程在并行域中执行完之后,它们退出或者挂起,最后只有主线程在执行。
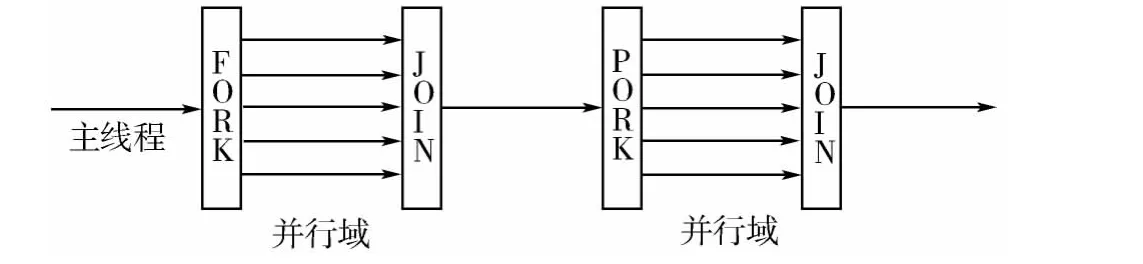
图1 Fork-Join并行执行模型
1.2 OpenMP中的负载均衡策略
负载均衡是影响OpenMP多线程程序运行性能的重要因素[4],为了实现较好的负载平衡从而取得更好的性能,就必须对循环进行调度和分块。本文主要是针对for循环调度进行研究。
在OpenMP中针对for循环的调度,主要有4种调度方式[3]:Static静态调度、Dynamic动态调度、Guided指数调度和Runtime运行时调度。Runtime调度实际上是根据OpenMP中的环境变量OMP_SCHEDULED来选择前3种的某一种类型,所以本文不做讨论。
1.2.1 Static 静态调度
静态调度的原理非常简单,就是将循环的迭代以近乎平均的方式分布到各个线程上。如果有1000次迭代,线程组中有4个线程,那么每个线程将分配250次迭代。当不能整除时,将余数次的迭代依次分配给最后一个线程。
静态调度具有最小的调度开销,然而,由于静态调度是按循环次数平均划分,没有考虑到每次任务的大小可能不一样,所以,静态调度不能获得较好的负载平衡。
1.2.2 Dynamic 动态调度
与静态调度不同,动态调度不是按顺序将各个(或各组)迭代分配到各个线程,而是在程序执行过程中,某个线程完成了一个(或一组)迭代后,动态申请下一个(或下一组)迭代进行执行。
动态调度可以分为指定chunksize参数和没有指定chunksize参数。当没有使用chunksize参数时,线程在完成上一任务后动态申请一个循环迭代并执行;当指定chunksize参数时,可以认为每次分配给线程的迭代次数为指定的chunksize值。
各线程动态地申请任务,因此较快的线程可能申请更多次数,而较慢的线程申请任务次数可能较少,因此,动态调度可以在一定程度上避免前面提到的按循环次数划分引起的负载不平衡问题。
1.2.3 Guided 指数调度
Guided调度是一种采用指导性的启发式自调度方法,它的调度规则是将迭代空间划分为子块,并按动态调度的方法调度各个子块的执行,子块的大小按指数递减。在开始时线程将会分配到较大的迭代块,之后分配到的迭代块会逐渐递减,直至指定的chunksize大小。
让chunksize的值由大到小指数型递减,从一定程度上缓解chunksize值不好指定的问题,因此,指数调度可以视作动态调度在调度开销和负载平衡上的折中。然而,如果循环结构极不规则[5],那么在开始时分配的任务块可能过大以至于后续分配的任务块没有足够的任务量来缓和所引起的负载不均衡性。
1.3 其它相关调度策略
在循环调度方面,学术界提出了很多循环调度的算法。除了PSS调度(类似于无参数的Dynamic调度)、CSS调度(类似于有参数的Dynamic调度)、GSS调度(类似于Guided调度)外,针对不同的研究重点还提出了各种不同的调度方案。
new-guided调度[6]是一种启发式的a调度策略,它将静态调度和指数调度相结合。a是一个比率值,对于前面a的循环迭代,采用静态调度;对于后面1-a的循环迭代,采用传统的指数调度。参数a的取值不是一成不变的,随着应用程序的不同和测试环境的不同,参数a的最优值也会变化。TSS策略[7]不是采用改变指数调度循环块指数递减的方式,而是采用算法使每次调度时循环块线性减少。TSS调度通过线程数、循环体的类型和大小以及运行时的环境状态等因素确定线性减少比率,而后每次调用循环体大小按比率减少。
另外,文献[8]提出了FSS(Factoring Self-Scheduling)调度。该方案将循环迭代分成若干段,每段内部采用Dynamic调度。这种调度能够有效缓解Guided调度不适合极不规则的循环调度的缺点。文献[9]提出一种反馈型Guided调度,在处理小规模的循环数据时能够有效减少调度开销。文献[10]则针对TSS调度提出了一种改进方案,根据处理单元的可用量分配循环块,对于解决TSS处理不规则循环时的问题起到了一定的作用。
2 几种调度策略比较分析
通过循环数和计算量之间的关系可以将for循环结构分为两大类:规则循环结构和非规则循环结构。规则循环结构是指随着循环变量的增加(或减少),每次循环的工作量没有变化。非规则循环结构又分为递增循环结构、递减循环结构和随机循环结构。递增循环结构是指随着循环变量的增加(或减少),每次循环的工作量也随着增加(或减少);递减循环结构是指随着循环变量的增加(或减少),每次循环的工作量随着减少(或增加);随机循环结构是指每次循环的工作量的变化与循环变量的变化没有直接的联系。
本文通过一个实验来具体比较几种调度策略的性能。实验是在Linux系统下进行,使用的是OMPi编译器,版本是OMPi-1.2.0。通过使用 gettimeofday()函数可以获得UNIX到现在的是时间,单位可以精确到微秒。通过在每个for循环结构的开始位置与结束位置分别插入gettimeofday()[11]函数,计算出时间差即为该运行循环结构的时间,这个时间将随着循环结构和调度策略的更改而变化,从而反应出每个调度策略的特点。
在本次试验中,将分别对4种循环结构进行试验,以取得更加全面的实验结果。本文采用经典的CP(Compute Pots)程序、AC(Adjoint Convolution)程序、MM(Matrix Multiplication)程序和 MS(Mandelbrot Set)程序进行测试。其中,CP程序属于递增循环结构,用于计算三维空间中的3000个点的某种场势;AC属于递减循环结构,用于计算向量卷积,循环规模是200×200;MM程序属于规则循环结构,用于计算浮点矩阵乘法,循环规模是250×250;MS程序属于随机循环结构,用于计算复平面上的曼德布洛特集合,循环规模是500×500。
测试结果(单位为毫秒)如表1至表4所示。
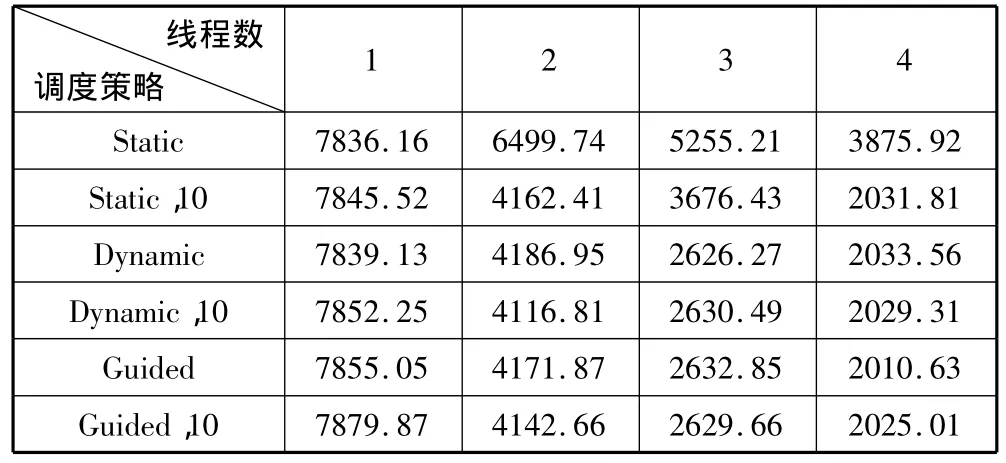
表1 CP测试结果
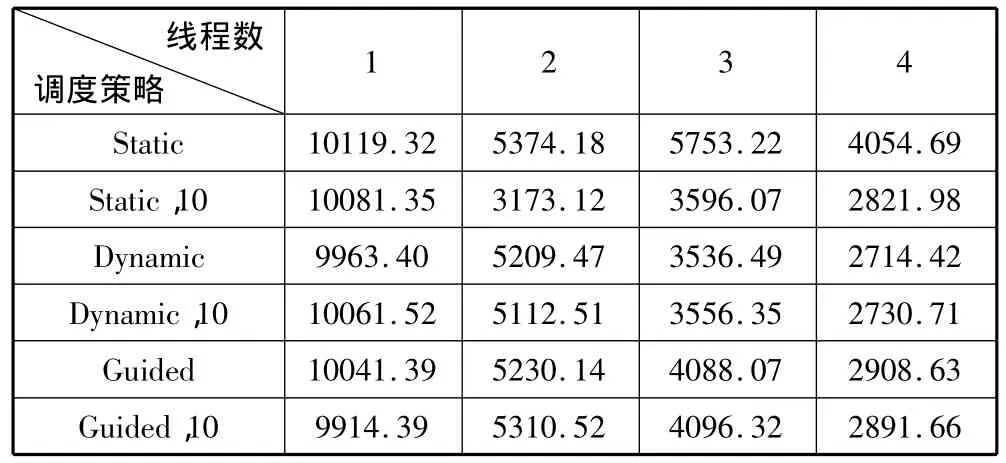
表2 AC测试结果
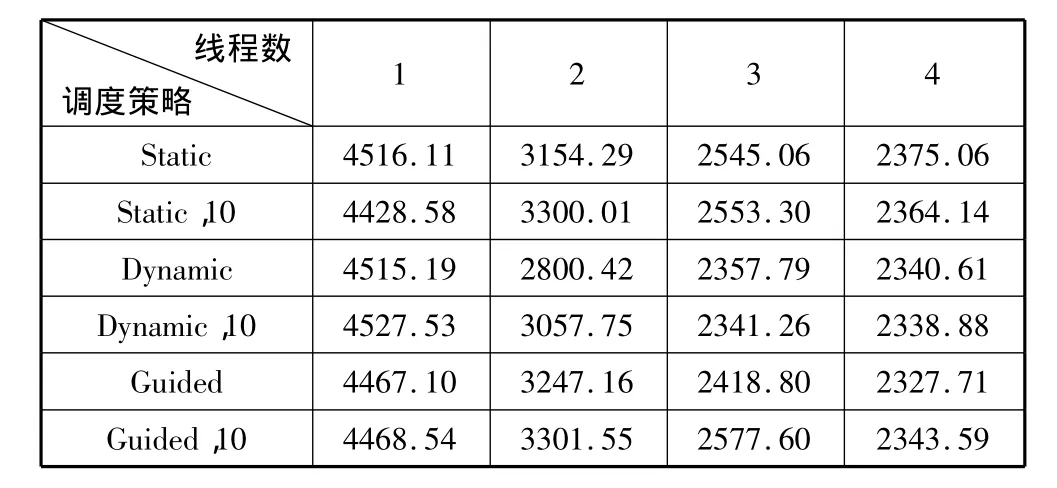
表3 MM测试结果
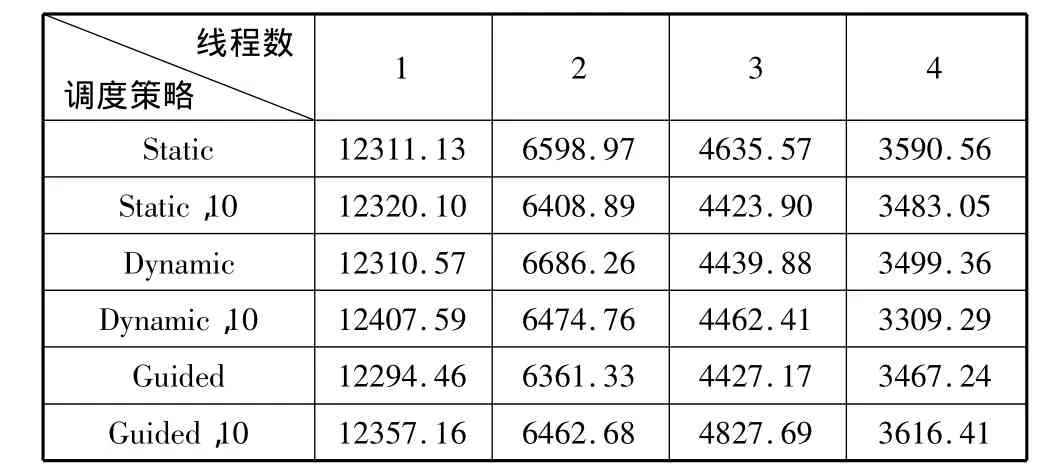
表4 MS测试结果
从上述实验结果可以看出,在3种循环调度中,static调度在各种调度中表现最差,dynamic调度由于其较好的灵活性,在每次循环的工作量不确定的随机循环调度中获得较好的性能;guided调度在递减循环结构和随机循环结构中,由于其开始时分配的循环块过大,引起了负载极不平衡,从而性能较差。
3 一种新的调度策略
3.1 新调度策略的提出
影响OpenMP中调度策略性能的关键因素[12]是调度开销和负载平衡,从最初简单的静态调度到现在的TSS调度和New-guided调度,都是在调度开销和负载平衡之间的不断权衡。在保证较低调度开销的同时保证各任务负载平衡一直是研究者研究的主要问题。调度开销和负载平衡与size值息息相关,从图2各种调度算法的发展历程图中可以看出,size值是变化还是不变化、以线性的变化还是非线性的变化,贯穿了所有调度策略的始终,所以较好地对size值的控制是优化和改进调度策略的关键。

图2 调度算法的发展历程图
负载均衡调度策略的发展历程在一定程度上就是调度开销和负载平衡之间的相互妥协,而多数改进策略也是围绕这一点展开研究。文献[6]提出的New-guided调度对于Guided调度的一个最大的优点是解决了Guided调度在递减循环结构中由于开始循环块过大而可能导致的负载不平衡。然而,Newguided调度并不是完美的,由于它是结合了静态调度和Guided调度的一种策略,所以必然也继承了静态调度负载不平衡的缺点。针对这个问题,本文提出利用Dynamic调度替换静态调度,即将Dynamic调度和Guided结合的一种启发式的新的调度策略。这种策略前a部分用 Dynamic调度,后面1-a部分应用Guided调度,本文称为Dynamic-guided调度,其中比例因子a代表一个百分比值。
3.2 算法描述与流程
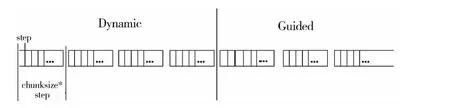
图3 算法原理图
如图3所示,Dynamic-guided调度算法将所有待处理的for循环分为两部分。对于前一部分for循环,首先,编译器根据参数chunksize和step的大小计算第一个循环块的大小,其中step指循环步长,即每线程每次执行for循环代码的最小单位,在多数情况下循环步长step为1,chunksize是由用户指定的参数;然后,已经由编译器编号的各线程将调用并执行循环块,每个线程每次调用一个循环块,除最后一个循环块外其余循环块的大小相等。各个线程的调用并不是依次执行,而是按需进行,即当一个线程空闲时就调用下一个循环块,而不是事先将所有的调度都分配好,这样可以更加有效地利用处理器资源。对于后一部分for循环,与前面一样,编译器会根据剩余的未调度的循环迭代数Last_chunksize与线程个数Num_thread等参数确定第一块循环块的大小,之后各个线程将调用循环块,第一块循环之后的所有循环块的大小都是按照该算法确定。循环块大小按指数递减,直到减至用户指定的chunksize大小,剩余小于chunksize的迭代由一个线程一次调用完成。
令Fchunksize表示for循环中前一部分的剩余迭代数,Lchunksiz表示后一部分的剩余迭代数,它们的初始值可分别由总的迭代总数乘以百分比值a或1-a得出,算法流程图如图4所示。
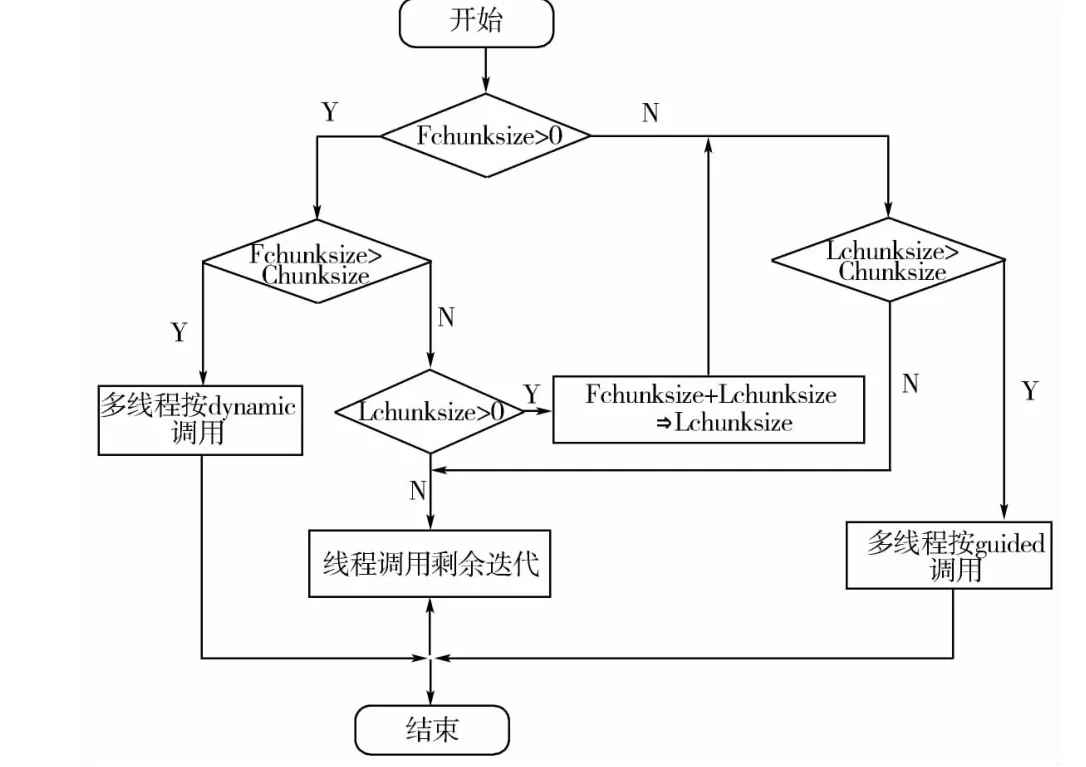
图4 算法流程
Dynamic-guided调度是一种结合了动态调度和指数调度的混合型调度策略,可以通过控制百分比a的值来适应不同的环境,具有较好的灵活性。一方面,它能够很好地继承动态调度和指数调度的优点,相比静态调度,能够更有效地利用线程资源,缓解出现由各线程处理速度不同和各个迭代计算量的不同所引起的负载不平衡。另一方面,算法前一部分采用动态调度,所以在极不规则循环结构中也比单纯使用指数调度更具优势,后一部分迭代采用guided调度,能有效解决单纯使用动态调度时chunksize值不好指定的问题,也能够缓解指数调度开始分配循环块过大可能引起极大负载不平衡的缺陷。
4 结束语
本文首先通过实验对OpenMP中的3种调度策略深入地分析研究,提出改进的关键因素是对调度块大小size值的控制,在此基础上提出一种结合动态调度和指数调度的新调度策略。下一步将利用现有的支持多核处理器的软硬件资源,通过大量的实验来验证比例因子a在不同环境中的最佳取值,另外,动态调度部分和指数调度部分的两个chunksize参数的取值问题将是进一步研究的重点。
[1]Haoqiang Jin,Dennis Jespersen,Piyush Mehrotra,et al.High performance computing using MPI and OpenMP on multi-core parallel systems[J].Parallel Computing,2011,37(9):562-575.
[2]王亭亭.基于OpenMP和MPI的并行算法研究[D].长春:吉林大学,2011.
[3]罗秋明,明仲,刘刚,等.OpenMP编译原理及实现技术[M].北京:清华大学出版社,2012.
[4]Da Gao,Thomas E Schwartzentruber.Optimizations and OpenMP implementation for the direct simulation Monte Carlo method[J].Computers & Fluids,2011,42(1):73-81.
[5]张延红,史永昌,朱晓珺.非规则循环的OpenMP调度算法[J].计算机工程,2011,37(6):68-70.
[6]刘胜飞,张云泉,孙相征.一种改进的OpenMP指导调度策略研究[J].计算机研究与发展,2010,47(4):687-694.
[7]Tzen T H,Ni L M.Trapezoid self-scheduling:A practical scheduling scheme for parallel compilers[J].IEEE Transactions on Parallel and Distributed Systems,1993,4(1):87-98.
[8]Hummel S F,Schonberg E,Flynn L E.Factoring:A method for scheme scheduling parallel loops[J].Communications of the ACM,1992,35(8):90-101.
[9]Tabirca T,Freeman L,Tabirca S,et al.Feedback guided dynamic loop scheduling:A theoretical approach[C]//International Conference on Parallel Processing Workshops,2001.2001:115-121.
[10]Chronipoulos A T,Penmatsa S,Xu Jianhua,et al.Distributed loop-scheduling schemes for heterogeneous computer systems:Research articles[J].Concurrency and Computation:Practice & Experience,2006,18(7):771-785.
[11]GitHub,Inc.OMPi/runtime/ort_ws.c[DB/OL].https://github.com/tonyseek/OMPi/blob/master/runtime/ort_ws.c,2013-10-01.
[12]任小西,唐玲,李仁发.OPenMP多线程负载均衡调度策略研究与实现[J].计算机科学,2010,37(11):148-151,183.
[13]赖建新,胡长军,赵宇迪,等.OpenMP任务调度开销及负载均衡分析[J].计算机工程,2006,32(18):58-60.
[14]陈永健.OpenMP编译与优化技术研究[D].北京:清华大学,2004.
[15]刘轶,张昕,李鹤,等.一种面向多核处理器并行系统的启发式任务分配算法[J].计算机研究与发展,2009,46(6):1058-1064.
[16]余荣祖.并行进化算法及其在组合优化中的应用[D].西安:西安电子科技大学,2007.
猜你喜欢
云南画报(2021年8期)2021-11-13
环球市场(2017年36期)2017-03-09
电子设计工程(2015年15期)2015-02-27
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
计算机与网络(2014年6期)2014-05-25
上海金属(2013年6期)2013-12-20
计算机工程与科学(2013年2期)2013-06-07
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08
电子设计应用(2004年7期)2004-09-02
