
支持源代码逆向建模的关系模型设计
2013-10-10 06:42刘彦宇唐运乐
河池学院学报 2013年2期
刘彦宇,唐运乐
(北海艺术设计职业学院 现代教育技术中心,广西 北海 536000)
现有的软件逆向工程分析方法主要有4种:词法分析和语法分析;程序切片;动态分析;图形化方法[1]。在对现有源代码进行分析的过程中,首先想到的便是图形化建模方法,使用Rational Rose、Visio、Rigio、StarUML等,进行逆向建模,即通过对源代码的自动分析,提取出代码各个层次上各类元素的相关信息,分析它们间的相互关系并生成多种类型的模型描述文档[1-4]。但由于程序开发本身的复杂性,以及这些分析工具关注重点所限,分析结果往往和预期相差很远,像Visio逆向生成的类模型文档,只包含了类的描述信息,缺少更多的类结构信息。这就需要开发人员在使用辅助工具的基础上,更多的人为参与代码分析。
为了帮助开发者快速地阅读理解程序源代码,本文针对Java语言,以基于实体关系的C++元模型[5]为基础,扩展了一种支持Java源代码逆向建模的关系模型,按照关系模型设计代码数据库。
1 Java源代码的逆向建模过程
目前,现有逆向建模方法大致为,通过抽取源代码信息,存入设计的表或数据库中,再通过一些辅助工具或数据库应用程序对抽取的信息进行模型描述[2-3,6-7]。这种方法在将抽取信息存入数据库时所要设计的接口程序相对复杂。而基于实体关系的C++元模型可以很好的完成结构化分析及细粒度搜索,同时它还可以平衡粒度尺寸及分析局限。本文在原有模型的基础上进行关系模型设计,扩展了两方面内容。第一,针对业界大量使用的Java语言,扩展了特定语言的元模型。采用Java1.5的特性,通过这些特性可以有效控制元模型的复杂度,同时与Java语言中的文法概念相匹配后,便可以很容易的对抽取信息进行分类处理,简化接口程序。第二,扩展实体类型和关系类型,支持细粒度分析。
整个逆向建模过程如图1所示,分三个步骤:第一,抽取源代码信息,采用Eclipse AST对源代码进行解析;第二,存储到代码数据库;第三,生成模型描述文档、进行代码信息检索。
2 关系模型设计
将代码中的信息抽象为实体、关系,并且将它们与源程序使用的程序设计语言的文法概念相匹配,之后,便很容易对各种信息进行分类处理。
实体可以与源代码中的显式声明一致,例如Class、Interface、Method等,也可以与Array、Primitive这类Java类型一致。解析过程中如果实体类型无法描述,可以使用UNKNOWN代替。表1列出了全部实体类型,这些类型遵循Java语言规范(JLS)中定义的标准含义。

图1 Java源代码逆向建模过程
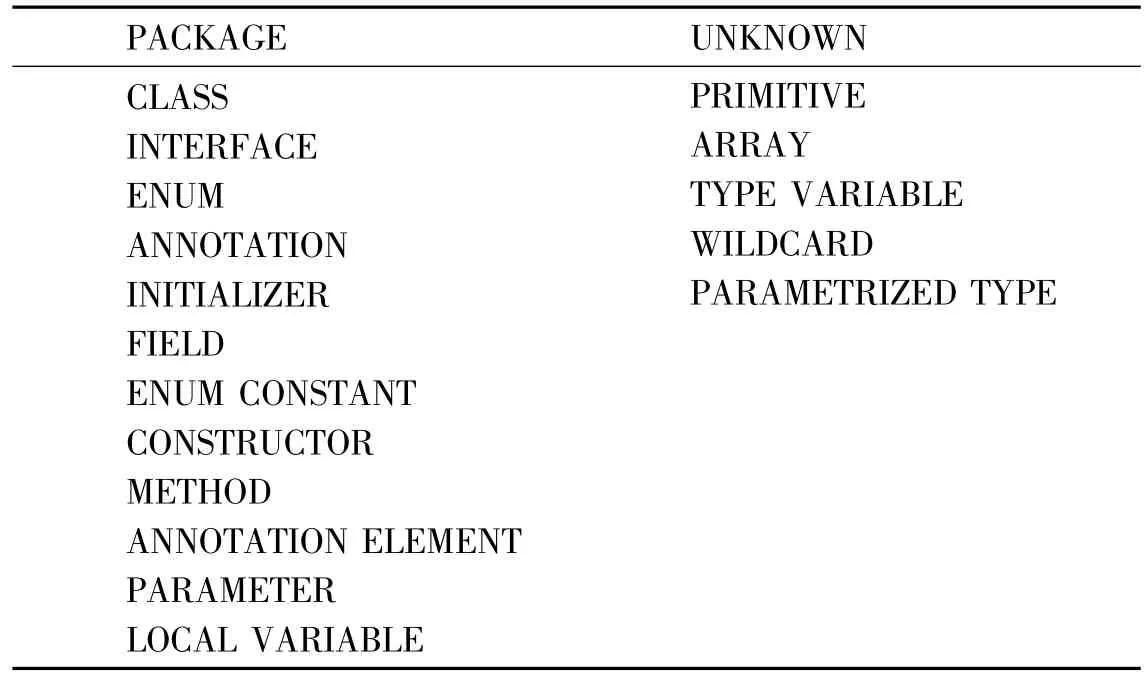
表1 实体类型
关系代表两实体之间的依赖特性,因此所有关系都是从源实体到目标实体的二元关系。程序在检查过程中发现源实体,源实体相对较小并且包含有关系的触发代码。目标实体则不同,它可以是关系涉及的本地实体,也可以是涉及到的Java标准库或者其他外部的JAR。表2列出了完整的关系类型。
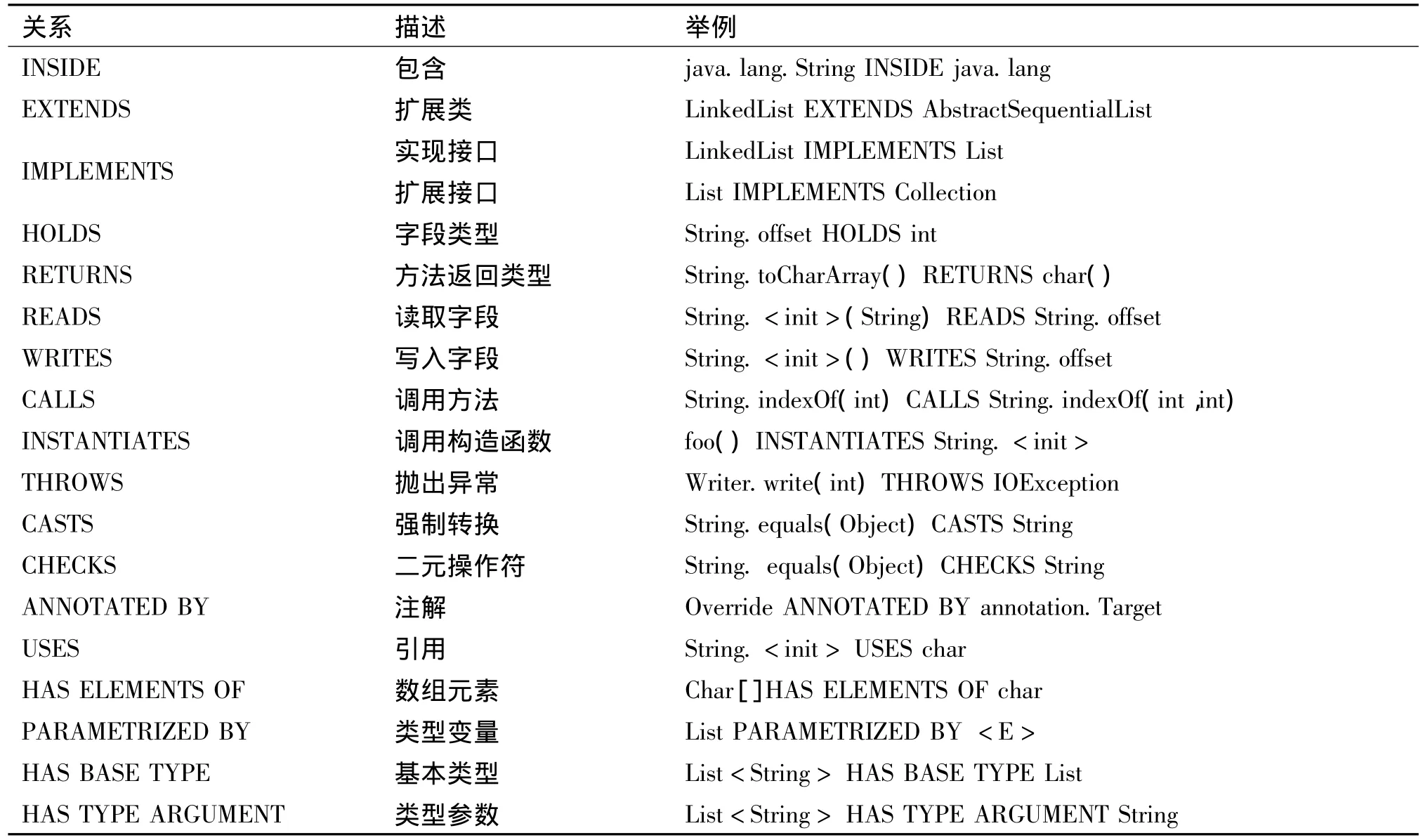
表2 关系类型
扩展后的关系模型如图2所示,由工程(Project)、文件(File)、实体(Entity)、关系(Relation)、注释(Comment)五个部分组成。
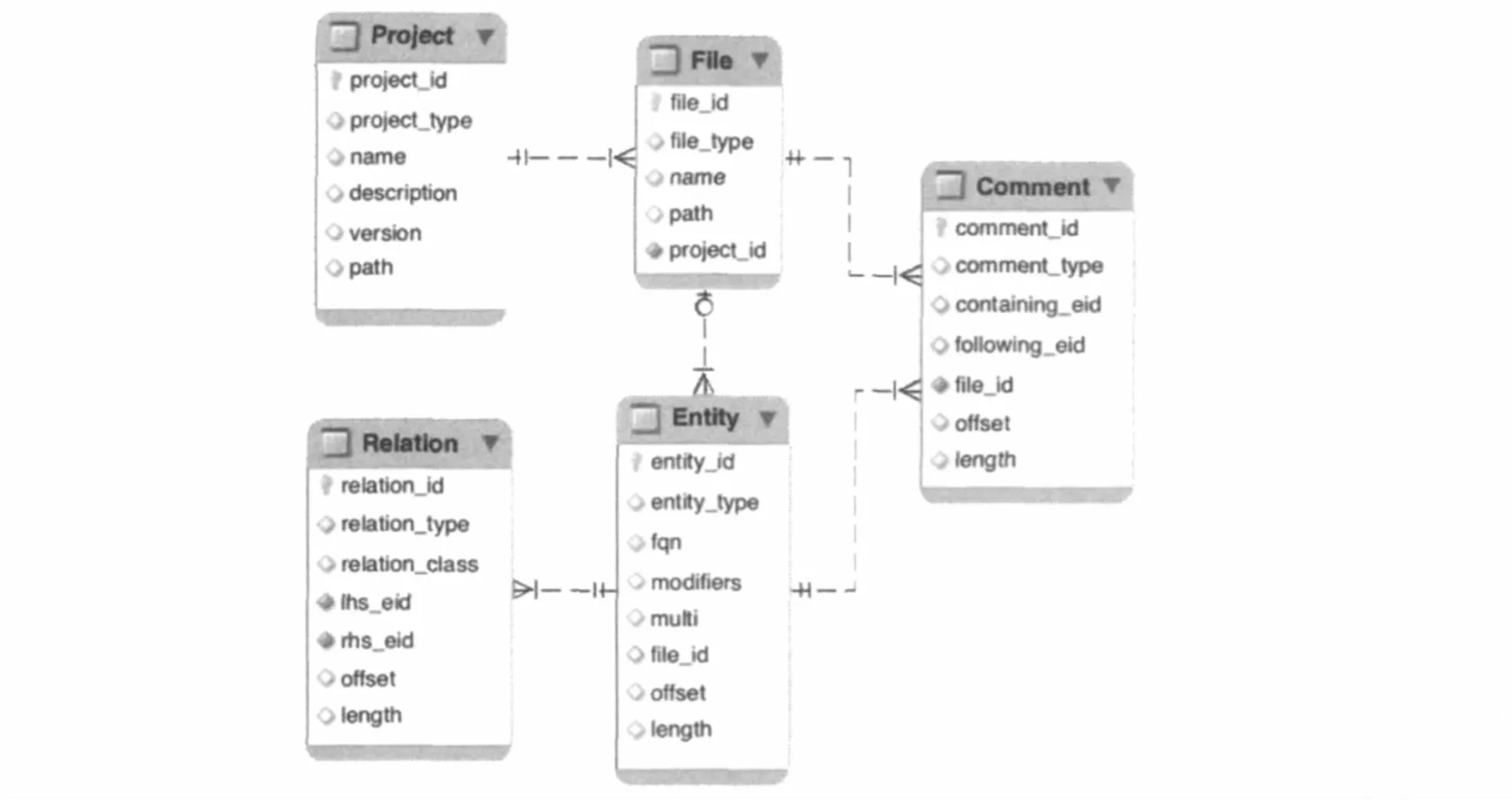
图2 扩展后的关系模型
首先,为每个逆向建模的工程,建立一个Project模型元素。由于每个工程中含有Java源文件、JAR文件、类文件,因此建立File模型元素来代表三种类型文件。源文件及类文件通过它们内部的多个Entity模型元素联系起来,而且在这些源实体及目标实体之间形成Relation模型元素。另一方面,将Java工程打包生成的JAR文件,则包含全部Entity模型元素和Relation模型元素。对扩展后的关系模型元素的详细描述如下。


3 模型描述及信息检索
将抽取的源代码信息存储到代码数据库后,就可以通过数据库查询语句得到程序相关信息。同时,通过开发相应的数据库应用程序,将源代码信息转换为更高层次的抽象视图,以适当的形式生成模型描述文档。
另一方面,由于关系数据库无法对存储在库中字段内容进行检索和分析,因此并未在数据库中存储详细代码数据,而是采用代码数据库+Lucene[7-8]的模式,设计信息检索部分。从代码数据库中读取数据来建立Lucene索引,将Lucene定义的索引文档(document)与数据库中的一个实体记录匹配。Lucene中,文档又是一些域(field)的序列,而域又是一些项(term)的序列,这里项就是最基本的检索单元,是从一个实体的各部分中提取出来的字串。将代码数据库与Lucene结合既实现了全文检索,又可以利用数据库做复杂分析,实现模型描述文档的建立。
4 实验验证与分析
扩展后的关系模型支持源代码的细粒度分析,生成的各层次元素复杂,适合局部源代码建模,基于此开发的逆向建模工具与同类工具相比,具有一定特色。
实验过程中,采用这种方法对开源项目面向对象数据库db4o(for Java,version 8.0)的源代码进行了局部的模型描述,分别对db4o内核的File Header(数据字典加载)、FreeSpace(空闲空间分配)、Internal Ids(分配对象OID)、Get(根据 OID 获取对象数据)、Set(对象存储)[9]等5个方面进行类模型描述。由于缺乏对比逆向建模细粒度分析优劣的基准测试及数据集,这里使用模型描述中获得的实体数量作为评测参数。图3显示了基于扩展关系模型开发的逆向建模工具与Rational Rose、StarUML两款工具在模型描述中获得实体数量的对比。
结果显示,由于分析粒度的不同,加之本文扩展了实体及关系类型(不再只是类、字段、方法等显式实体),在对db4o五个类模型描述中,基于文中方法的工具在细粒度分析上要明显优于其他两款工具。
另一方面,通过代码数据库+Lucene的模式,可以提高源代码分析的速度,同时为简单时序分析提供可能性。图4,5是代码数据库+Lucene,结合人为分析得到的db4o对象存储的序列图。
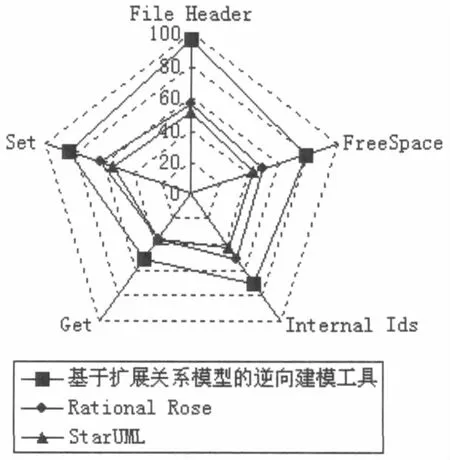
图3 模型中获得的实体数量对比

5 结语
在对实际项目进行源代码分析的过程中,可以采用粗粒度与细粒度分析相结合的方式,利用粗粒度分析项目整体概况,利用细粒度分析局部信息。但由于程序开发本身的复杂性及众多的设计模式,要更有效的表现设计思想及设计逻辑,减少人为参与代码分析,还需要更具体的分析与匹配。
[1]Francoise Balmas,Kostas Kontogiannis.Introduction to the special issue on software analysis,evolution and reengineering[J].Science of Computer Programming,2006,60(2):117 -120.
[2]彭四伟,朱群雄.基于源代码分析的逆向建模[J].计算机应用研究,2006,23(7):52-54.
[3]Alexandru Telea,Heorhiy Byelas,Lucian Voinea.A Framework for Reverse Engineering Large C++Code Bases[J].Electronic Notes in Theoretical Computer Science,2009,233(3):143 -159.
[4]H Byelas,A Telea.Visualization of areas of interest in software architecture diagrams[A].SoftVis’06 Proceedings of the 2006 ACM symposium on Software visualization[C].New York:ACM Press,2006:20 -28.
[5]Yih - Farn Chen,Emden R Gansner,Eleftherios Koutsofios.A C++Data Model Supporting Reachability Analysis and Dead Code Detection[J].IEEE Transactions on Software Engineering,1998,24(9):682 -694.
[6]马恋.基于关系数据库的程序逆向分析架构研究[D].长沙:长沙理工大学,2007.
[7]Erik Linstead,Sushil Bajracharya,Trung Ngo.Sourcerer:mining and searching internet- scale software repositories[J].Data Mining and Knowledge Discovery,2009,18(2):300 -336.
[8]佚名.Lucene web site[CP/DK].http://lucene.apache.org,2012.
[9]佚名.Db4o web site[CP/DK].http://www.db 4o.com,2012.
猜你喜欢
红外技术(2022年11期)2022-11-25
音乐天地(音乐创作版)(2022年1期)2022-04-26
现代信息科技(2021年21期)2021-05-07
高技术通讯(2021年1期)2021-03-29
安阳工学院学报(2020年2期)2020-06-05
中国司法鉴定(2018年4期)2018-07-30
计算机应用(2017年10期)2017-12-14
信息安全研究(2016年3期)2016-12-01
中国房地产业(2016年8期)2016-03-01
应用技术学报(2014年3期)2014-02-28
