
基于评分矩阵预填充的协同过滤算法
2013-09-29 05:20周志彬王国军
计算机工程 2013年1期
彭 石,周志彬,王国军
(中南大学信息科学与工程学院,长沙 410083)
1 概述
随着电子商务的发展,自动推荐商品已经成为提升销售额的重要手段[1]。协同过滤算法是目前应用最广泛的推荐算法之一。协同过滤算法的基本思想是寻找与目标用户或目标项目相似的用户集或项目集,用相似集合的特征预测目标的特征[2]。
随着用户和项目的数量急剧增长,用户-项目评分矩阵变得极其庞大。同时由于个人的兴趣和喜好等个性特征不同,因此用户往往只会使用很少一部分项目,必然导致用户对项目的评分数据稀少,很多系统中评分数据的比例小于 1%。这就是协同过滤推荐系统中存在的用户-项目评分矩阵稀疏性问题[3]。
余弦相似度、调整余弦相似度、皮尔逊相关系数[4]等传统相似度计算方法仅利用评分数据进行计算。在评分矩阵极其稀疏的情况下,2个有相同兴趣的人可能因没有共同评分而不能被发现。为了克服评分矩阵稀疏性问题,很多学者提出了评分矩阵预先填充的算法。
本文在分析传统评分矩阵预先填充算法的基础上,提出一种改进的算法,论述其特点,给出改进的协同过滤算法流程,分析实验策略、实验数据、评价标准和实验结果。
2 相关工作
协同过滤算法可按照比较方式分为2类:基于用户的协同过滤算法和基于项目的协同过滤算法。前者比较用户之间的相似性;后者比较项目之间的相似性。本文在基于用户的协同过滤算法基础上,根据项目相似性对评分矩阵进行预先评分填充,提高矩阵稠密度。
令用户集合 U={U1,U2,…,Un},项目集合 I={I1,I2,…,In},rx,i为用户 Ux对项目 Ii的评分,所有的 rx,i构成一个矩阵,称为用户-项目评分矩阵,如表 1所示,其中,问号表示用户未给对应项目评分。
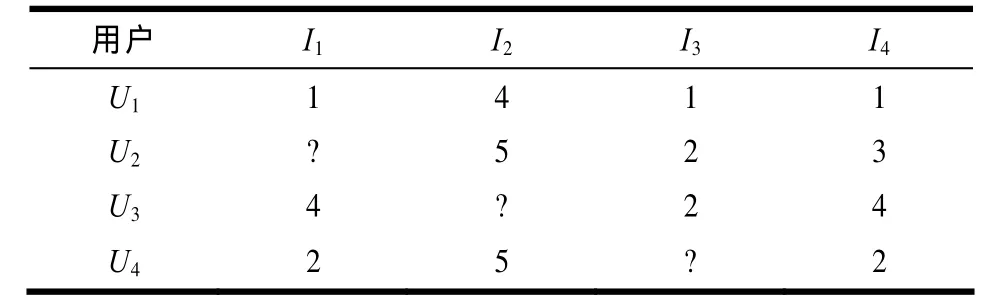
表1 用户-项目矩阵
大部分评分系统中的评价都设为5个等级,分别表示很不满意、不满意、一般、满意、很满意,对应于1~5的分值。数值越大表示评价越好,数值越小表示评价越差,问号则表示用户未给予对应项目评分。
2.1 传统相似度计算方法
传统相似度计算方法主要有以下3种:
(1)皮尔逊相关系数。皮尔逊相关系数表示2组数据的线性相关度,可以描述2组数据的相似性。其计算公式为:
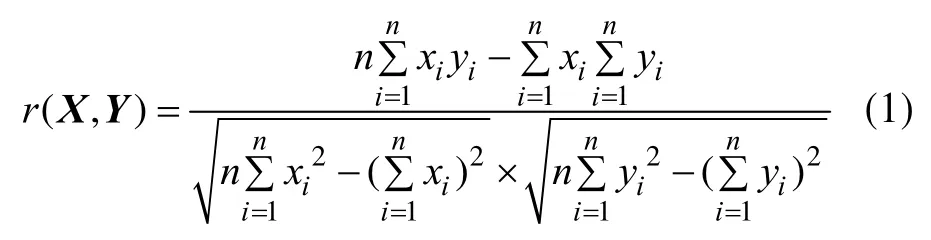
其中,n为样本量;X、Y分别为 2组长度相同的数据。相关系数用r表示,r的绝对值越大表明相关性越强。r>0表示正线性相关,r<0表示负线性相关,r=0表示线性不相关,但可能存在其他曲线方式的相关性。
(2)余弦相似度。余弦相似度用2个向量的夹角余弦值表示相似程度,夹角越小相似度越大:

其中,n是向量的维度;xi、yi分别是X、Y对应的分量。
(3)调整余弦相似度。余弦相似度存在一些缺陷,为了尽量消除这种缺陷,有研究者提出调整余弦相似度计算方法:
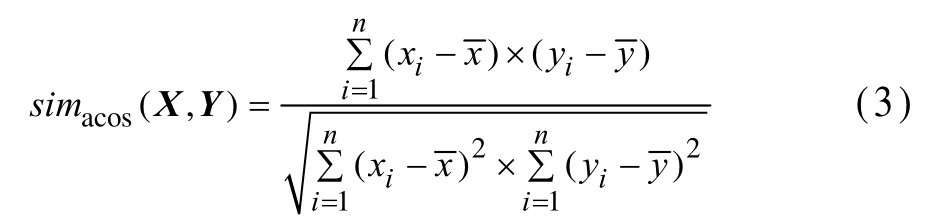
2.2 传统方法存在的问题
传统相似度计算方法基于2个用户的共同评分向量。在极其稀疏的评分矩阵中,2个用户的共同评分项目更少,从而导致传统算法推荐精度不高。
传统相似度计算方法无法识别部分相似的用户。以表1中的数据为例。U2和U3是有相似兴趣的用户,但用户U2没有对项目I1评分,用户U3没有对项目I2评分。传统相似度计算的结果认为它们不相似。但项目I1与I4的评分特征非常相似,可以根据项目之间的相似性推测用户 U2对项目 I1的评分为 3。有了这个预先填充的评分,通过传统相似度计算的结果可以发现U2和U3是相似的。
为了解决用户评分数据的极端稀疏性并更好地挖掘用户的相似性,很多学者提出了预先对用户-项目评分矩阵进行填充的算法。
简单的办法就是将未评分项目设为一个固定的缺省值。通常取用户或项目的评分均值。这种改进方法确实可以提高推荐精度,但效果有限。
文献[5]提出了基于项目评分预测的协同过滤算法,文献[6]提出了基于概率知识的评分填充算法。文献[7]提出了一种信任度传播的评分填充算法。文献[8]提出一种基于云模型的评分填充算法。文献[9]提出了一种基于熵的协同过滤推荐模型。这些方法均有效提高了推荐精度,但没有考虑项目的属性,只考虑了评分。虽然有一定效果,但是还需要进一步改进。推荐项目往往具备多方面的属性,如分类、颜色、价格。同一类型的项目属性通常也有较高的相似性。结合评分相似度和属性相似度能够进一步提高评分填充的精度。文献[10]提出了一种基于项目的协同过滤算法,结合了项目的评分相似度和项目的属性相似度,有较好的推荐效果。
本文受此启发,通过信息熵知识构造项目属性的加权 Jaccard系数相似度,进而设计一种改进的结合项目属性和评分的综合相似度,提出一种依据项目的综合相似度对评分矩阵进行预先填充的协同过滤算法。
3 基于信息熵的属性相似度
3.1 基于属性的相似度
令项目的属性集合为A={a1,a2,…,am}。以电影推荐系统中的电影为例。假设 a1代表动作片,a2代表喜剧片,a3代表恐怖片,a4代表纪录片,a5代表警匪片。一部电影可以同时属于2个类型,见表2。
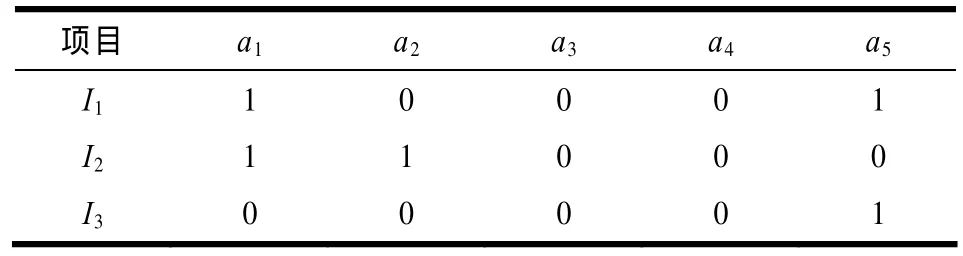
表2 电影属性示例
传统的计算集合的相似度可使用Jaccard系数。A代表 Ii的属性集合,B代表 Ij的属性集合。则Ii和 Ij的属性相似度为:

其中,A∩B表示2个集合中的相同属性个数;A∪B表示 2个属性集合的元素总数。根据定义可知,J(A,B)∈[0,1]。本文认为,不同的属性因为属性值出现的概率不同,具有不同的影响力。为改进 Jaccard系数相似度,本文以属性的信息熵作为属性的加权,构造加权Jaccard系数相似度。
3.2 信息论
信息是抽象概念,信息量在香农提出信息论之前是无法衡量的东西。香农于1948年10月发表的论文《通信的数学理论》从概率统计角度给出了相关的定义。
3.2.1 信息量
自信息 I(x)是指信源中某一信号 x携带的信息量。信源中不同的信号都携带了一定量的信息,自信息根据信号出现的概率表示一个特定信号的信息量:

3.2.2 信息熵
信息熵定义为各信号的信息量的数学期望值,表示整个系统的平均信息量。信息熵从统计学角度描述了信源的特征,表示总体的不确定性程度:
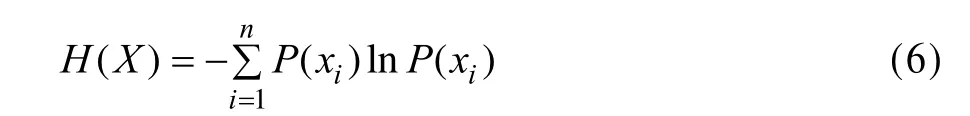
3.3 改进的项目综合相似度
Jaccard系数相似度并没有考虑每个属性的加权。有些属性对商品的区分度大,有些区分度很小。举个例子,如果推荐系统中所有电影的类型都是动作片,那么这个类型的属性就没有参与相似度计算的必要了,因为该属性没有区分能力。如果有一半的电影属于喜剧片,一半的电影不属于喜剧片,则该属性对这个系统中的电影有很强的区分能力。
可以用属性的信息熵来描述每个属性对项目的重要程度,构造一种加权Jaccard系数相似度。
对于一个属性 am,其取值能够构成一个集合V(am)={vm1,vm2,…,vmk}。vm1表示属性m的第k个属性值。部分属性的取值空间可能是连续的实数空间。对于这种情况,可以对取值空间进行离散化,并对每一个子区间命名。例如,价格属性属于这种情况,可简单地离散化为3个价位段:高端价位,中端价位,低端价位。
定义属性值vmk的出现概率如下:

其中,count(vmk)表示系统中属性am的值为vmk的项目总数量;total_count表示所有项目的总数量,进而定义属性值vmk的信息量如下:

进一步可以得到属性am的熵:
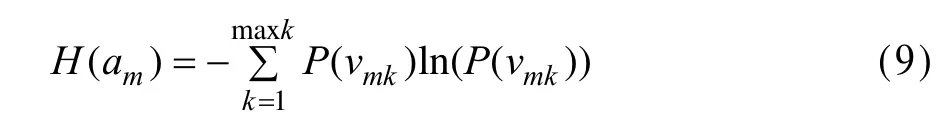
信息熵大的属性对项目有更好的区分度,可以赋予更大的加权。构造项目属性的加权 Jaccard系数相似度如下:
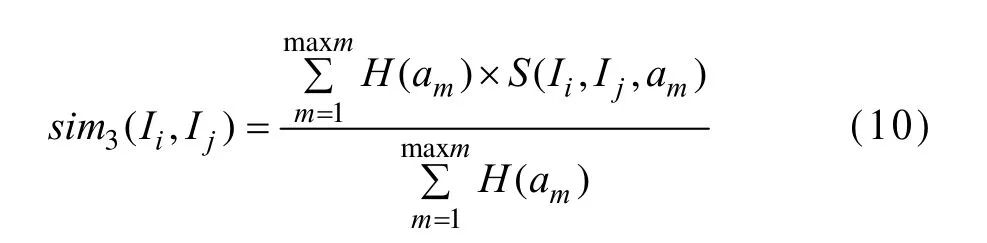
由定义可知,sim3(Ii, Ij)∈[0,1]。其中,maxm是推荐项目拥有的属性数量;S(Ii,Ij, am)的定义如下:
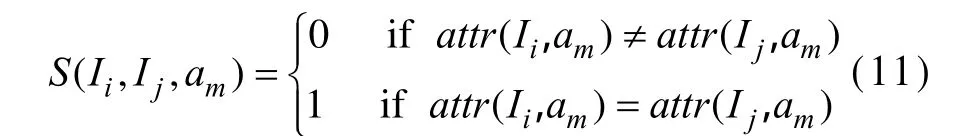
其中,attr(Ii,am)表示项目Ii关于属性am的值;S(Ii,Ij,am)比较项目 Ii和 Ij关于属性 am的值,如果相同,则结果为1,否则,结果为0。
最后,通过线性加权结合基于项目评分的相似度与基于项目属性的加权Jaccard系数相似度,构 造项目的综合相似度计算公式:
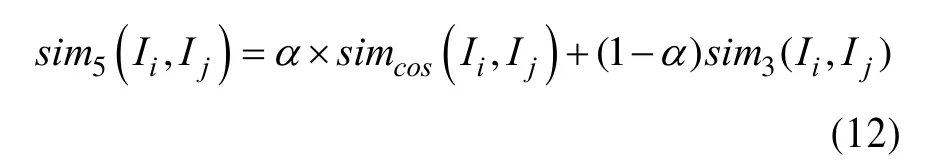
其中,α是一个调节因子,调节项目评分相似度和项目属性相似度的比重,α∈[0,1]。
4 协同过滤算法
本文的改进协同过滤算法在经典的协同过滤算法流程上增加了一个评分矩阵预先填充过程。
算法主要流程如下:
输入 目标用户Ux、用户-项目矩阵
输出 目标用户Ux的推荐项目集合
(1)遍历项目集合。
(2)对每一个项目 Ii,用式(12)计算与其他项目之间的综合相似度,构造各项目的相似项目集合。
(3)基于项目Ii的相似项目集合,用式(13)对Ii的未知评分进行填充。
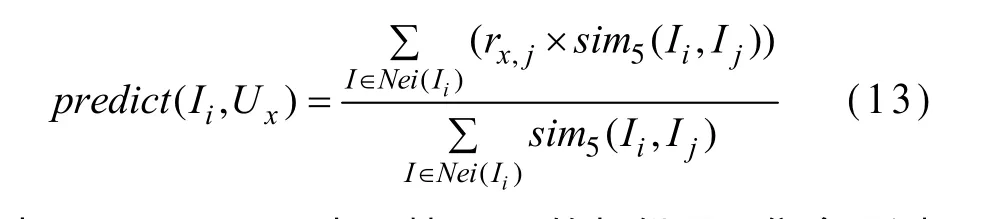
其中,predict(Ii,Ux)表示基于 Ii的相似项目集合预测的用户Ux对项目Ii的评分;Nei(Ii)表示与Ii相似的项目集合。
(4)基于经过填充的评分矩阵,用式(3)计算目标用户与其他用户间的相似度,构造相似邻居集合。
(5)根据目标用户的相似用户集合,用式(14)为目标用户的未知项目预测评分,最后产生推荐:
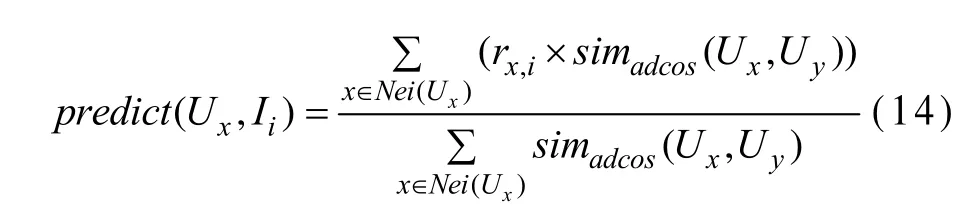
其中,predict(Ux,II)表示基于用户Ux的相似用户集合预测的用户Ux对项目Ii的评分值;Nei(Ux)表示Ux的相似用户集合。
5 实验与结果分析
5.1 实验策略
本文在5种相似用户集合规模(topn){4, 8, 12, 16,20}上,分别对经典的协同过滤算法(Classic Collaborative Filtering, CCF)、基于项目评分相似性进行评分填充的协同过滤(Collaborative Filtering Based on Rating Filling, CFBRF)算法及本文算法进行对比实验。
5.2 测试数据集
本文选用了 grouplens小组提供的测试数据集。grouplens收集了 movielen电影评价网上的大量评分信息,整理成验证数据包。众多的协同过滤算法使用这几个数据包来验证算法的性能和精度。本文选择的数据集包含943个用户对1 682部电影的100 000条评分信息。
5.3 评估标准
首先对数据包进行随机化混洗操作。然后采用5折交叉验证法,将实验数据集平均分成5个互不相交的数据子集,训练集和测试集的数据比例为4:1。每次实验选择其中一个数据子集作为测试集,其余4个数据子集作为训练集。如此循环5次,取每次实验结果的平均值作为最终结果。5折交叉验证法可以有效降低实验误差。
在单次实验中,度量推荐系统的指标主要包括统计精度方法和决策支持精度方法。其中,统计精度方法——平均绝对误差(Mean Absolute Error, MAE)为大多数推荐系统采用。平均绝对误差用系 统预测值与实际用户评分值之间的偏差来反映推荐的精确度。设预测的用户评分值为{p1, p2, …, pn},对应的实际评分值为{q1, q2, …, qn},则MMAE的计算公式如下:
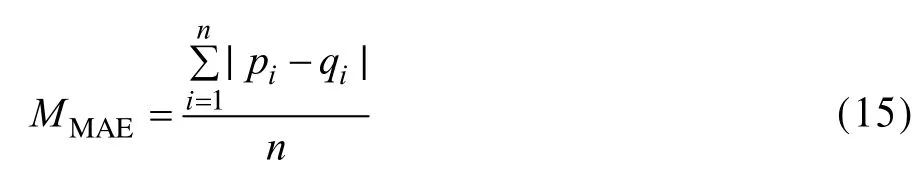
MMAE越小表示预测值与实际值的差异越小,推荐效果越好。
5.4 结果分析
首先分析在相似用户集合为 4、8、12、16、20时,α参数对CFBWJI算法的影响。
图1表明,当α接近0.9时,能够接近最优值。
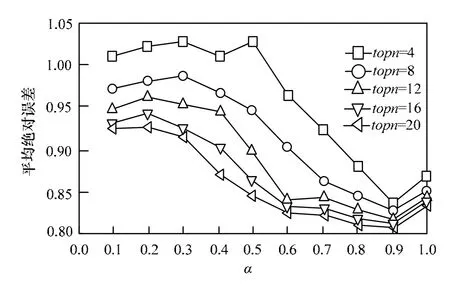
图1 α参数对本文算法的影响
图2表明,经过评分矩阵填充的算法均优于经典算法,本文的CFBWJI算法在优化参数的情况下能够进一步降低MMAE值,提供最精确的预测结果。
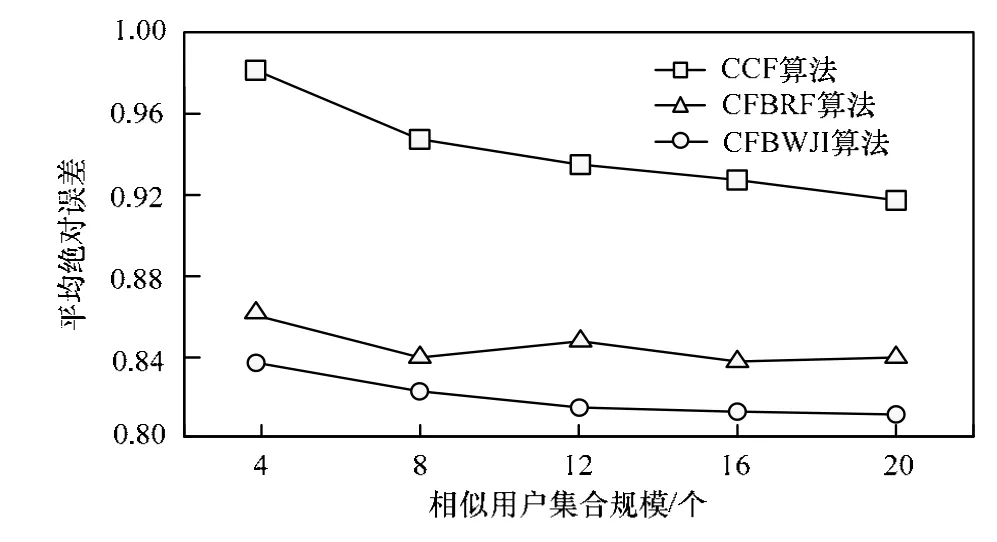
图2 各算法的平均绝对误差
6 结束语
传统协同过滤算法面临用户-项目评分矩阵极其稀疏的问题,导致2个用户的共同评分项目稀缺。传统的相似度计算方法如余弦相似度、皮尔逊相关系数等基于2个用户的共同评分,因此,推荐效果不理想。本文通过属性的信息熵构造加权 Jaccard系数相似度,进而提出了结合项目的属性和评分的综合相似度,依据项目的综合相似度预先对评分矩阵进行填充,能够在一定程度上缓解矩阵稀疏性问题,同时挖掘出更多相似用户。实验结果表明,改进算法相比传统算法有效地提高了推荐精度,用户同样拥有各种属性信息。下一步工作将结合用户的属性等信息进行更精确的相似度计算。
[1]Linden G, Smith B, York J.Amazon.com Recommendations: Item-to-item Collaborative Filtering[J].IEEE Internet Computing, 2003, 7(1): 76-80.
[2]Herlocker J L, Konstan J A, Terveen L G, et al.Evaluating Collaborative Filtering Recommender Systems[J].ACM Transactions on Information Systems, 2004, 22(1): 5-53.
[3]孙小华.协同过滤系统的稀疏性与冷启动问题研究[D].杭州: 浙江大学, 2005.
[4]Sarwar B, Karypis G, Konstan J, et al.Item-based Collaborative Filtering Recommendation Algorithms[C]//Proc.of the 10th International Conference on the World Wide Web.[S.l.]: IEEE Press, 2001: 285-295.
[5]邓爱林, 朱扬勇, 施伯乐.基于项目评分预测的协同过虑推荐算法[J].软件学报, 2003, 14(9): 1621-1628.
[6]周军锋, 汤 显, 郭景峰.一种优化的协同过滤推荐算法[J].计算机研究与发展, 2004, 40(10): 1843-1847.
[7]Massa P, Avesani P.Trust-aware Collaborative Filtering for Recommender Systems[C]//Proc.of Federated International Conference on Move to Meaningful Internet.[S.l.]: IEEE Press, 2004: 492-508.
[8]余志虎, 戚玉峰.一种基于云模型数据填充的算法[J].计算机技术与发展, 2010, 20(12): 35-37.
[9]辛 羽, 黄佳进.基于熵的协同过滤推荐模型[C]//第十届中国Rough集与软计算、第四届中国Web智能、第四届中国粒计算联合会议论文集.重庆: 中国计算机学会, 2010.
[10]Wu Yueping, Zheng Jianguo.A Collaborative Filtering Recommendation Algorithm Based on Improved Similarity Measure Method[C]//Proc.of IEEE International Conference on Progress in Informatics and Computing.[S.l.]: IEEE Press, 2010: 246-249.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
中学数学杂志(高中版)(2016年6期)2017-03-01
中国卫生(2016年5期)2016-11-12
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
池州学院学报(2015年3期)2016-01-05
