
基于数据挖掘技术的现代图书馆系统设计
2013-09-25 07:52吴灿
图书馆学刊 2013年2期
吴 灿
(重庆图书馆,重庆 400037)
吴 灿 男,1977年生。学士,助理馆员。研究方向:图书馆办公信息化、数字图书馆、数字资源共享。
随着图书馆信息化、数字化程度的提高,其职能也发生了较大的改变。数字化、信息化的图书馆除了具有传统图书馆的职能外,还是馆领导做决策的重要依据,成为图书馆发展数据库和知识库的重要组成部分。如何有针对性地为读者在纷繁复杂的信息中选取有效的参考信息,以及对图书馆的各种资源进行科学化管理是现今图书馆工作面临的重要任务。而数据挖掘技术的应用为图书馆的系统升级提供了重要的技术支撑。
著名的图书馆管理博士W·J·Frawley对数据挖掘是这样定义的:数据挖掘就是从大量的、复杂的、不完整的应用数据中提取被人们忽视的但又有很大利用潜能的数据的过程。数据挖掘技术是随着数据库和自动化技能发展而出现的新的信息技术,与数据分析的差别就在于,数据分析是通过分析数据来验证人们已知的假设,而数据挖掘则是从大量人们已知的数据中挖掘出人们未知的信息。
1 数据挖掘对图书馆管理提出新需求
网络信息服务是指专门提供信息服务的机构运用计算机、通讯网络等设备、设施,提供因特网信息服务。信息服务主要有两种,即传统信息服务和现代信息服务。传统信息服务主要包括利用报纸杂志、影视作品、电台广播等提供的服务;而现代信息服务是以计算机提供的网络为核心,以数字化的形式为客户提供信息服务,包括电子书、网页新闻、网络搜索和查询、信息传递等。
信息技术和数字化的发展为图书馆体系的升级提供了重要的前提和条件,数字图书馆便是信息化和数字化的产物。数字图书馆是图书馆提高网络信息服务的重要途径和条件,网络信息服务是数字图书馆建设的根本目标,也是联系数字图书馆和读者之间的重要纽带。
随着图书馆信息化、数字化的发展,图书馆体系的具体任务转变成如何让使用者更加有效地利用图书馆资源,以及如何更好地针对读者需要从纷繁复杂的信息中找出关键的可靠信息。数据挖掘技术的最大优势就在于“意外”性,这便为图书馆的管理工作和服务质量的提升提供了更多可能。
数据挖掘技术可以从杂乱无章的数据中提取出最符合要求的参考信息,而在数据挖掘技术的实现研究中,笔者所要研究的数据主要来源于工作中的现有数据。通过选取读者借阅信息进行聚类分析,了解图书馆的使用率和图书的借阅率,挖掘出隐性的图书馆运行规律,总结出数据挖掘技术在图书馆系统中的应用模型,然后用此模型来指导图书馆的管理和服务工作,进而提高图书馆服务和管理工作的效率。
2 信息化数据挖掘技术
2.1 图书馆信息化聚类
现阶段,信息化数据挖掘技术发展迅速,理论研究不断创新,已经成功研发了各种数据挖掘软件,被广泛应用到不同领域并逐渐得到认可,正是这些领域的成功引起了图书馆的极大关注。在图书馆现代管理系统中能够产生大量不同种类的数据,自动化系统本身也包含很多数据。可以依据这类数据的特点,定向研究适合图书馆应用的数据挖掘软件,并通过运用这类软件挖掘出对图书馆有意义的部分信息,进而了解读者访问图书馆的目的及整体趋势。根据读者的兴趣需求,采取适当措施及时完善服务质量,以优质的服务提高读者的满意度。
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。人类通过聚类研究事物内部规律,由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。聚类分析为进一步分析处理数据提供前提。作为数据挖掘功能,进行聚类分析后,可以整体了解数据分布情况,了解数据所存在的特征,并对其特定部分进行深入分析,识别出数据密集区和稀疏区,纵观全局数据分布模式及其属性关系等。由于大部分现实存在的大量数据库中不可避免地要涉及空缺、孤立点、未知错误数据等,那么只是单纯地按照聚类分析数据可能会直接影响聚类分析结论的准确性。
2.2 图书馆信息化聚类模型建设
事物之间都有自己的特有属性,我们可以假设对象A={ω1,ω2,ω3,…,ωn},其中 ω 为其特有的属性,对象 B={ξ1,ξ2,ξ3,…,ξm},如若A与B之间存在某种相关性K,我们可以认为在该相关性上对象A与B属于同一类,而K为A,B对象在K关系上的函数,可记为K(A,B)。显然关系K是建立在A对象与B对象属性的某一非空子集之上。
两个对象是否在K关系上属于同一类别,可以通过两个对象之间的距离进行表征。因此我们可以建立两个对象变量之间的距离K函数关系:
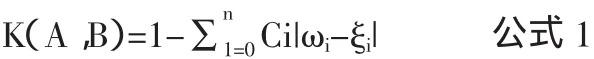
ωi为A的属性结合;
ξi为B的属性结合;
C为第i个属性的控制权重因素,在不同的关系中,权重因素可能不一样,通常情况下权重的取值为1~7。
当两个函数之间的距离越近,这两个对象之间就越紧密,可以认为在K关系上这个值就越大,这两个对象属于同一类,反之,我们可以认为这两个对象不属于同一类型。
从广义上来讲,K 也属于关系集合 ψ={K1,K2,K3,K4,…,Ki}。所以我们可以根据实际需求对关系进行分类。在不同的关系之间建立距离K函数。从而判断某两个对象在该关系上是否聚为一类。
由表4可知,6上105-2工作面开采初期顶板最大下沉量大于800 mm,压架事故频发,严重影响安全生产;实施旧支架升级后,顶板最大下沉量控制在600 mm左右,保证了煤矿安全生产;实施新支架优化选型后,6上109工作面顶板下沉量在300 mm以内,保证了工作面高产高效。
为了方便图书馆数据挖掘管理,根据图书馆日常工作关系,首先建立图书馆关系集合,主要包括读者需求关系、图书采购关系、个性化服务关系。其次建立图书馆进步文献属性表。因为图书馆管理是以文献管理为依托,所以在工作中收集整理文献基本属性参数尤为重要。笔者所采用的文献基本属性有书目类别、图书数量、日借阅量、月借阅量、个人连续借阅量、预约量、出版时间等,其具体描述如表1所示。
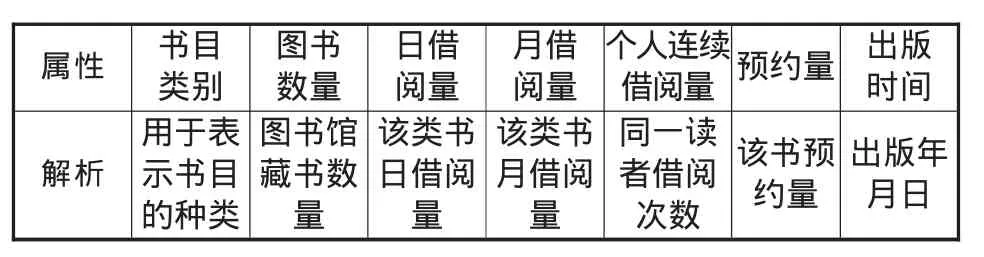
表1 图书对象基本属性
最后,利用公式 K(A,B)=1-∑n1=0Ci|ωi-ξi|进行在关系 K上的聚类分析计算。
如对读者需求关系进行聚类,通过需求聚类分析,可以观察到当前读者需求量较大的书目信息,从而方便图书管理。
①从图书馆后台数据库中读取各书目数据信息,随机抽取某一书作为原始对象。
②由该关系可知,书目预约量、日借阅量为主要考察对象,所以在该比重中,确定属性权重关系相应的设置较大,可设该权重值6,其余权重可设为1。
④设置阈值,将关系值进行分层,处于同一层的书目在读者关系上属于同一类别。通过设置阈值,对关系值进行分层,同一层者为同一类数据。设置的阈值大小应该根据实际情况而定。如图1所示,分配不同的阈值,可以将不同的相关书目聚为一类。
图1 聚类分层
3 数据挖掘在图书馆系统中的应用
3.1 资源建设
在图书馆信息资源系统中,保障图书馆信息资源的重要环节就是文献采集。一般的采购形式是依据出版社、期刊社或者书店新书书目等相关信息,由专人或馆长进行采集。这种文献采集方式不可避免地带有个人主观性。因为图书馆文献购置经费有限,应充分采集各门学科相关的专业信息,使采集经费的价值效益达到最大化。
在该建设过程中,首先确定权重关系,其次通过公式聚类分析计算,有目的地选择当前需要采购的书目。可以了解图书馆在一段时间的借阅流通记录、检索请求,进而统计出文献拒借集及频繁借阅集,明确文献信息采集方向,定向补充并丰富图书馆信息资源。
3.2 读者信息服务
数据挖掘技术有效拓宽了图书信息服务范围,使图书馆信息服务更有针对性,更能从客观上满足读者需求,提高了服务质量。通过对读者信息进行挖掘,得到有效的数据信息资源,并通过对其数据进行整合,进行相应的图书馆管理,为读者提供一个统一的知识文化平台,大大提高了读者的信息服务质量。
3.3 个性化服务
读者是图书馆的宝贵财富,在图书馆管理中,如何为读者提供个性化服务,满足其客观需求,是图书馆的主要工作。
从先前的数据挖掘实例可知,设定不同的关系可以得到不同聚类分析结果,所以在图书馆管理中运用数据挖掘技术,对读者历史借阅信息进行聚类挖掘分析,可以通过数据分析结果得到读者的基本需求。在该关系模型中,读者预定信息与单个客户单本书籍借阅次数应该占有很大权重,通过利用该数据挖掘模型,可以了解读者的研究方向,并以此为依据,向读者推荐相关书籍或者有目的地进行图书采购,从而发展稳定的图书馆读者群。
4 结语
随着科学技术的发展,在原始海量数据中寻找有用信息资源无疑是信息化利用的有力途径。通过数据分析,可以改进图书馆需求方向。但同时在大量的数据中也存在着信息冗余,这也是数据挖掘中需要考虑的问题。然而随着图书馆数据挖掘模型的不断完善,其在读者服务以及图书馆资源建设管理方面将会发挥越来越重要的作用,为图书馆的管理决策提供相应的数据支持。
[1] 杨春,刘树新,楼康华.论数据挖掘在读者关系管理中的应用[J].河北建筑科技学院学报:社科版,2006(3).
[2] 雒凤军.数据挖掘技术与读者个性化服务[J].兰台世界,2008(6).
[3] 骆颖.基于数据挖掘的数字图书馆个性化服务[J].黑龙江科技信息,2009(5).
[4] 王伯秋,等.基于数据挖掘的个性化信息服务[J].医学信息,2010(1).
[5] 黄兰,孙林山,罗日辉.数据挖掘及其在图书馆管理中的应用[J].华南热带农业大学学报,2005(2).
[6] 牛根义.国内图书馆数据挖掘研究[J].现代情报,2009(1).
[7]周军.基于数据挖掘的数字图书馆个性化服务系统的构建[J].图书馆学研究,2007(3).
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
大众投资指南(2021年35期)2021-02-16
中学生数理化·中考版(2020年10期)2020-11-27
中国交通信息化(2020年1期)2020-07-27
铁道通信信号(2019年6期)2019-10-08
意林(2018年3期)2018-03-02
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
